Spark-寒假-实验4
1.spark-shell 交互式编程
(1)该系总共有多少学生;
执行命令:
- var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
- var par=tests.map(row=>row.split(",")(0))
- var distinct_par=par.distinct()
- distinct_par.count

结果:

(2)该系共开设来多少门课程;
执行命令:
- var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
- var par=tests.map(row=>row.split(",")(1))
- var distinct_par=par.distinct()
- distinct_par.count
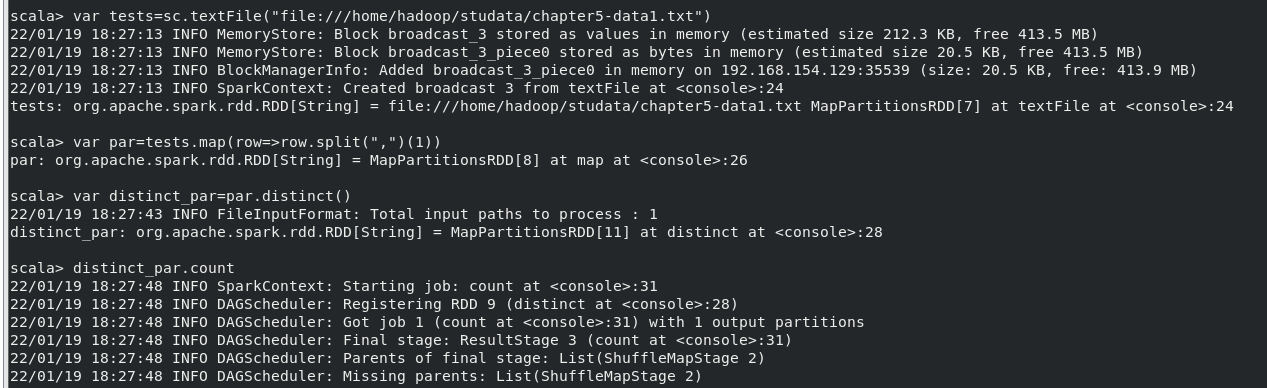
结果:

(3)Tom 同学的总成绩平均分是多少;
执行命令:
- var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
- var pars=tests.filter(row=>row.split(",")(0)=="Tom")
- pars.foreach(println)
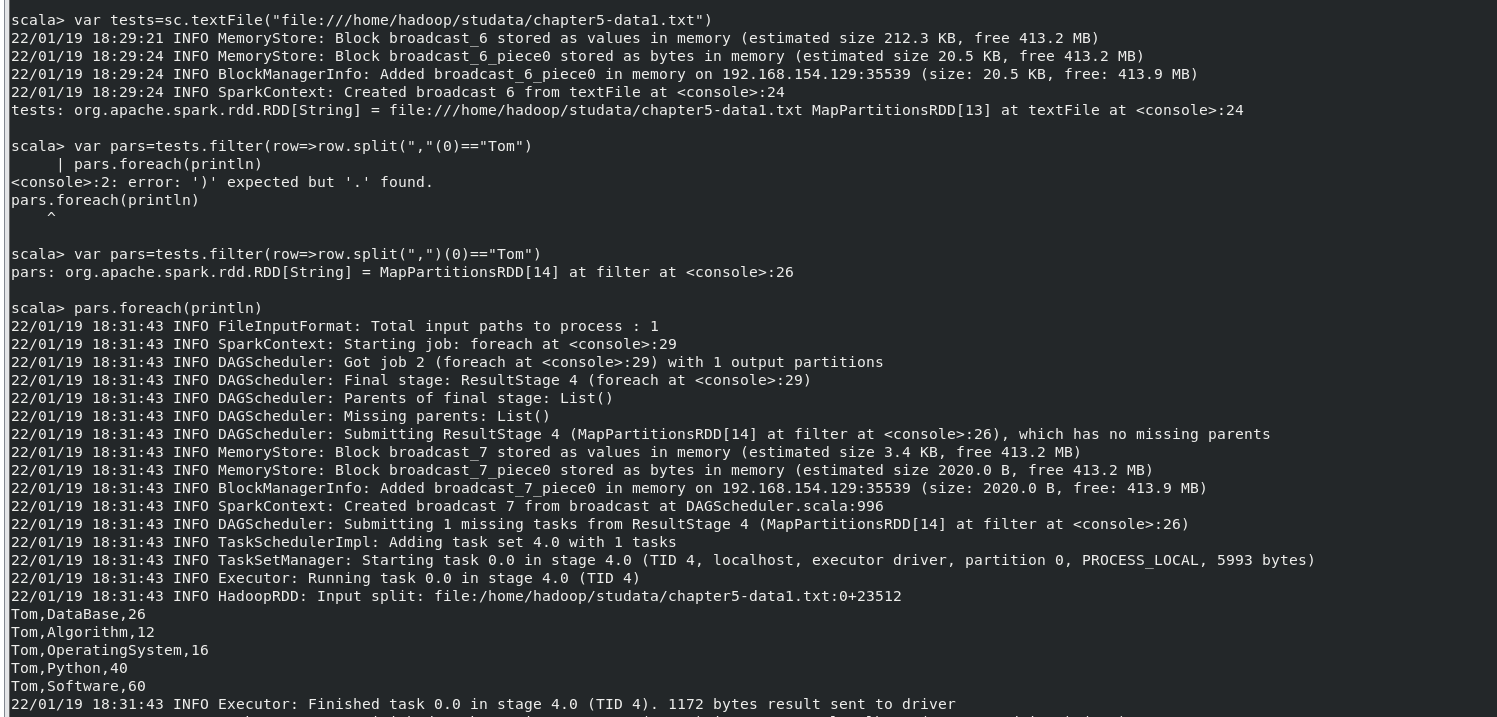
结果:

(4)求每名同学的选修的课程门数;
执行命令:
- var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
- var pars=tests.map(row=>(row.split(",")(0),row.split(",")(1)))
- pars.mapValues(x=>(x,1)).reduceByKey((x,y)=>(" ",x._2+y._2)).mapValues(x=>x._2).foreach(println)
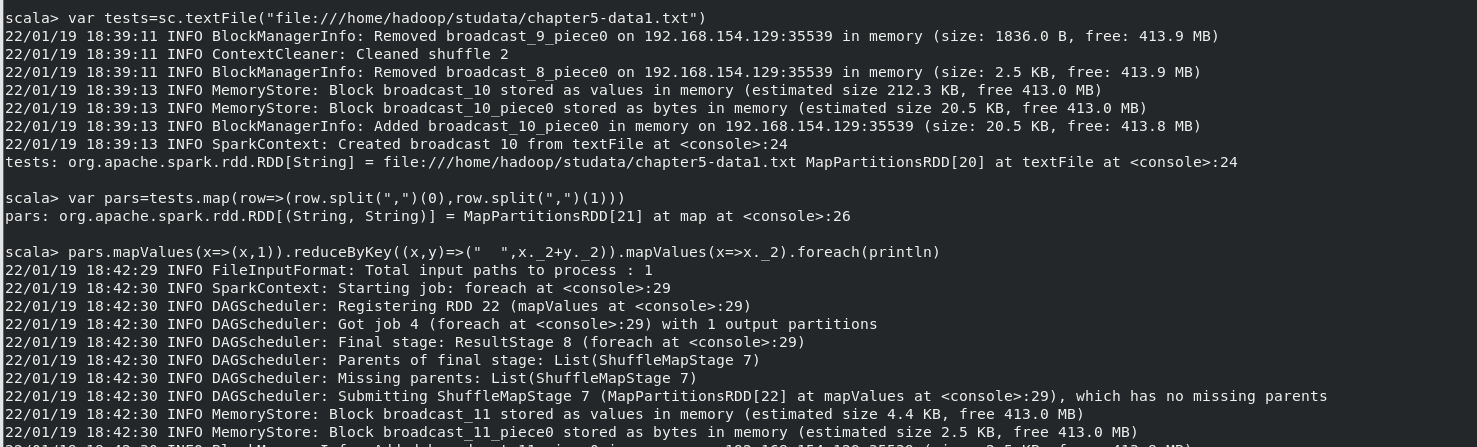
结果(此处仅为部分结果,结果共265项):
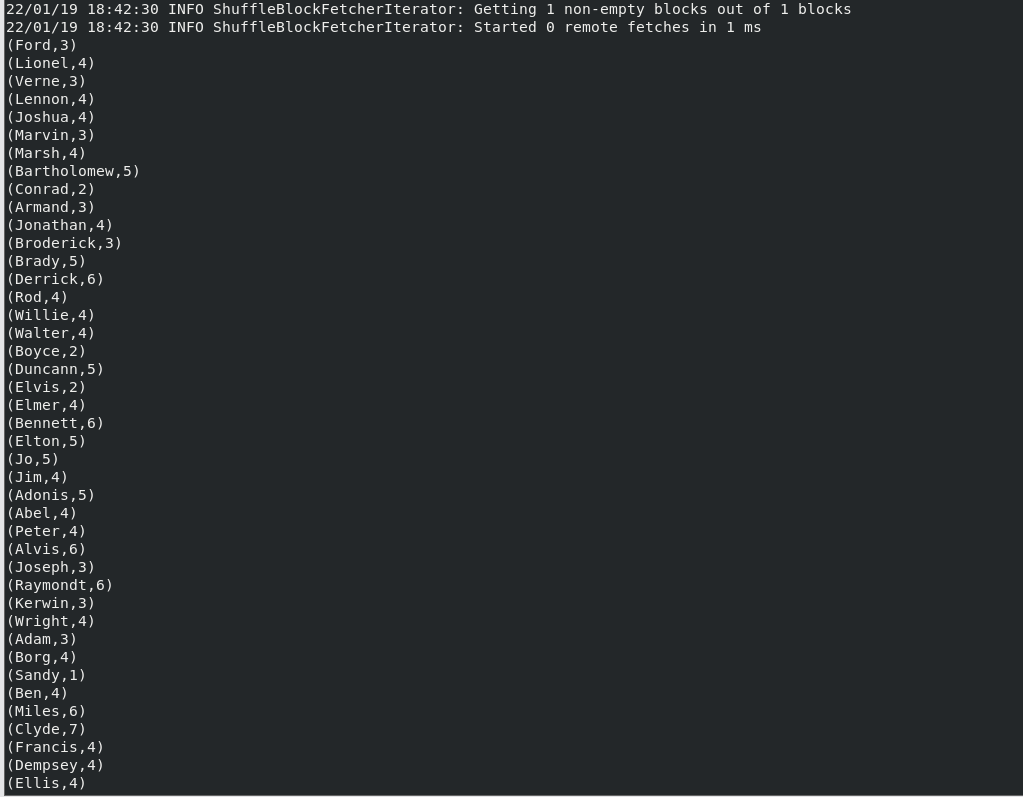
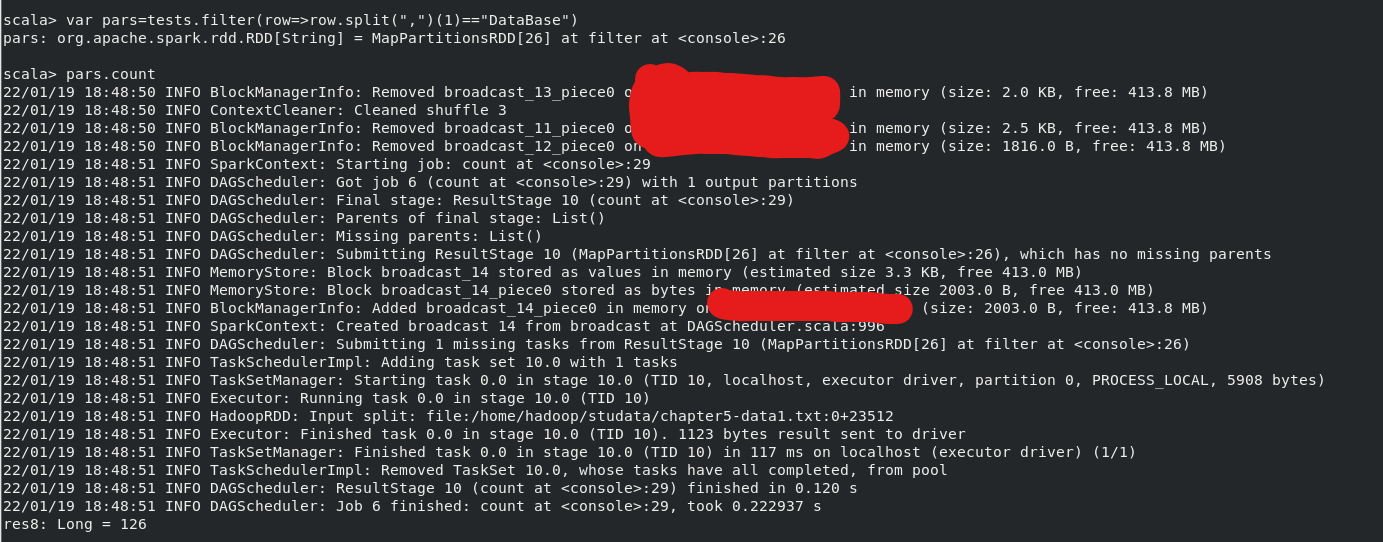
(5)该系 DataBase 课程共有多少人选修;
执行命令(结果最后一行):
- var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
- var pars=tests.filter(row=>(row.split(",")(1)=="Database"))
- pars.count
(6)各门课程的平均分是多少;
执行命令:
- var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
- var pars=tests.map(row=>(row.split(",")(1),row.split(",")(2).toInt))
- pars.mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x=>(x._1/x._2)).collect()

结果:

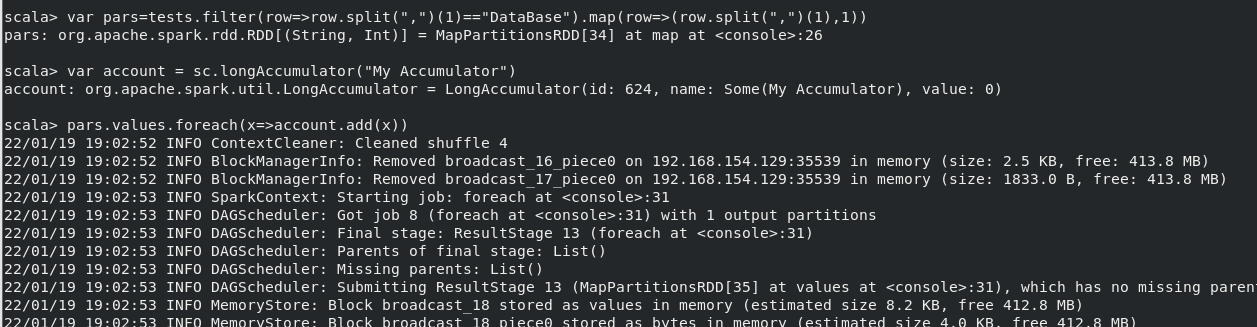
(7)使用累加器计算共有多少人选了 DataBase 这门课。
执行命令:
- var tests=sc.textFile("file:///home/hadoop/studata/chapter5-data1.txt")
- var pars=tests.filter(row=>(row.split(",")(1)=="Database")).map(row=>(row.split(",")(1),1))
- var account=sc.longAccumulator("My Accumulator")
- pars.values.foreach(x=>account.add(x))
结果:

2.编写独立应用程序实现数据去重
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的一个样例,供参考。 输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
创建项目:

remdup.scala
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- import org.apache.spark.HashPartitioner
- object RemDup {
- def main(args: Array[String]) {
- val conf = new SparkConf().setAppName("RemDup")
- val sc = new SparkContext(conf)
- val A = sc.textFile("file:///home/hadoop/studata/A.txt")
- val B = sc.textFile("file:///home/hadoop/studata/B.txt")
- val C = A.union(B).distinct().sortBy(x => x,true)
- C.foreach(println)
- sc.stop()
- }
- }
simple.sbt
- name := "RemDup Project"
- version := "1.0"
- scalaVersion := "2.11.8"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
打包项目(sbt的安装请看Spark-寒假-实验3):
运行jar包:
运行结果:

3.编写独立应用程序实现求平均值问题
创建项目流程同上:
程序代码如下:
average.scala
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- import org.apache.spark.HashPartitioner
- object Average {
- def main(args: Array[String]) {
- val conf = new SparkConf().setAppName("Average")
- val sc = new SparkContext(conf)
- val Algorimm = sc.textFile("file:///home/hadoop/studata/Algorimm.txt")
- val DataBase = sc.textFile("file:///home/hadoop/studata/DataBase.txt")
- val Python = sc.textFile("file:///home/hadoop/studata/Python.txt")
- val allGradeAverage = Algorimm.union(DataBase).union(Python)
- val stuArrayKeyValue = allGradeAverage.map(x=>(x.split(" ")(0),x.split(" ")(1).toDouble)).mapValues(x=>(x,1))
- val totalGrade = stuArrayKeyValue.reduceByKey((x,y) => (x._1+y._1,x._2+y._2))
- val averageGrade = totalGrade.mapValues(x=>(x._1.toDouble/x._2.toDouble).formatted("%.2f")).foreach(println)
- sc.stop()
- }
- }
simple.sbt
- name := "Average Project"
- version := "1.0"
- scalaVersion := "2.11.8"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
打包项目:

运行jar包:
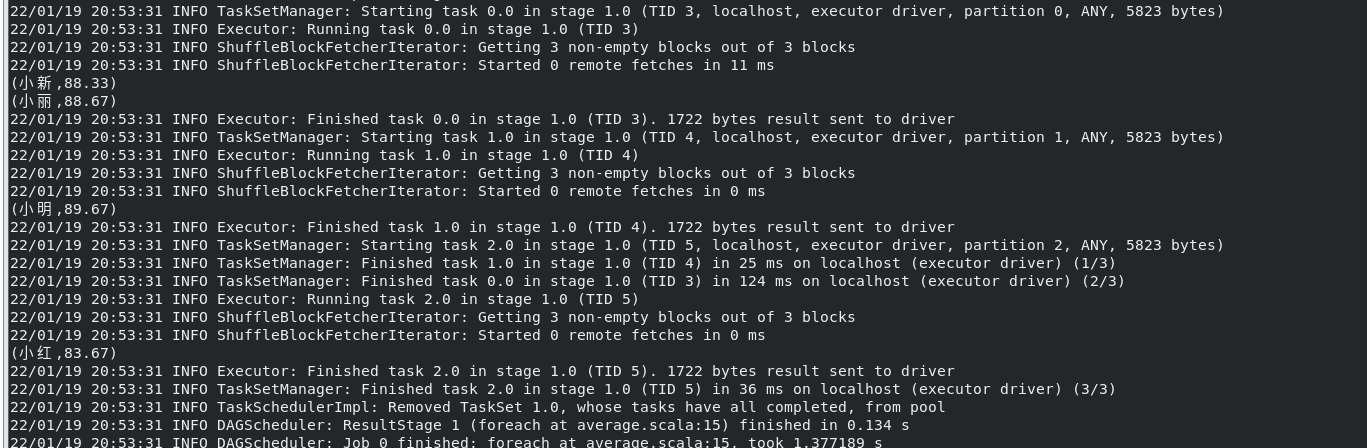
运行结果:
Spark-寒假-实验4的更多相关文章
- Spark基础实验七
今天在做实验七,最开始有许许多多多的错误,最后通过查找.问同学才知道是数据集的格式和存放位置的原因. 就在好不容易解决了上一个错误,下一个错误就立马而来,错误如下: 目前还未找到解决办法,spark实 ...
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- spark学习及环境配置
http://dblab.xmu.edu.cn/blog/spark/ 厦大数据库实验室博客 总结.分享.收获 实验室主页 首页 大数据 数据库 数据挖掘 其他 子雨大数据之Spark入门教程 林子 ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- Spark Streaming和Flume-NG对接实验
Spark Streaming是一个新的实时计算的利器,而且还在快速的发展.它将输入流切分成一个个的DStream转换为RDD,从而可以使用Spark来处理.它直接支持多种数据源:Kafka, Flu ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- 2019寒假训练营第三次作业part2 - 实验题
热身题 服务器正在运转着,也不知道这个技术可不可用,万一服务器被弄崩了,那损失可不小. 所以, 决定在虚拟机上试验一下,不小心弄坏了也没关系.需要在的电脑上装上虚拟机和linux系统 安装虚拟机(可参 ...
- 1.Spark Streaming另类实验与 Spark Streaming本质解析
1 Spark源码定制选择从Spark Streaming入手 我们从第一课就选择Spark子框架中的SparkStreaming. 那么,我们为什么要选择从SparkStreaming入手开始我们 ...
随机推荐
- AT2287 [ARC067B] Walk and Teleport 题解
Content 一条直线上有 \(n\) 个城市,第 \(i\) 个城市的坐标为 \(x_i\).你在某一个城市内,每一次你可以按两种方式之一进行移动: 左右移动,每移动一个单位疲劳值增加 \(a\) ...
- JAVA将Object数组转换为String数组
java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.String; java将Object[ ...
- c++11之日期和时间库
本文主要介绍 std::chrono日期和时间用法. 演示环境: vs2017 0.头文件 1 #include <chrono> 2 #include <thread>// ...
- 【LeetCode】977. Squares of a Sorted Array 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 排序 日期 题目地址:https://leetcod ...
- 【LeetCode】18. 4Sum 四数之和
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 个人公众号:负雪明烛 本文关键词:four sum, 4sum, 四数之和,题解,leet ...
- 【LeetCode】535. Encode and Decode TinyURL 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 解题方法 方法一:数组 方法二:字典 日期 题目地址:https://l ...
- 【LeetCode】915. Partition Array into Disjoint Intervals 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/partitio ...
- 1276 - Very Lucky Numbers
1276 - Very Lucky Numbers PDF (English) Statistics Forum Time Limit: 3 second(s) Memory Limit: 32 ...
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
目录 概 主要内容 positional encoding 额外的细节 代码 Mildenhall B., Srinivasan P. P., Tancik M., Barron J. T., Ram ...
- WHT, SLANT, Haar
目录 基本 酉变换 WALSH-HADAMARD TRANSFORMS sequency-ordered WHT SLANT TRANSFORM Haar Transform Gonzalez R. ...