《CNN Image Retrieval in PyTorch: Training and evaluati-ng CNNs for Image Retrieval in PyTorch》代码思路解读
这是一个基于微调卷积神经网络的图像检索的代码实现,这里我就基于代码做一个实现思路的个人解读,如果有不对的地方或者不够详细的地方,欢迎大家指出。
代码的GitHub地址:filipradenovic/cnnimageretrieval-pytorch (Commit c340540)
相关论文地址:
Fine-tuning CNN Image Retrieval with No Human Annotation, Radenović F., Tolias G., Chum O., TPAMI 2018 [arXiv]
CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples, Radenović F., Tolias G., Chum O., ECCV 2016 [arXiv]
写在前面
我是在2020年的4月份,为了我的本科毕设,研读学习这份代码。但到现在才有空闲来把我学习的成果整理到博客上,时间上是有些延迟的。作者在2020年12月份又更新了代码,发布了新的版本(V1.2),添加了亿点点细节。但这不影响我发表这篇博客,因为这个代码的整体思路还是不变的,这也是这篇博客的重点。如果这篇博客涉及到了代码的细节,那就是基于它V1.1的版本,更准确地说,是基于Commit c340540的版本。
关于我为什么是基于代码的解读,而不是基于论文的解读。原因是我做本科的毕设时,阅读论文的水平有限,把握不住实现的思路与过程。求助导师时,他说:可以阅读代码,阅读代码比阅读论文更容易。在此,也感谢导师的指导。
再次说明:对于数据集的一些更精妙的设计,以及对图像的白化处理等,这里由于水平的限制,都避开不谈。想要了解的同学,可以深入阅读论文,这篇博客并没有对这些内容进行解读。这篇博客只是梳理了非常基本的代码思路。
温馨提示:这篇博客有点长,点击右下角魔法阵上的【显示目录】,可以更方便导航。
前置知识
想要了解这个检索实现的思路,需要先了解一些相关的知识,有助于后续整体思路的把握。由于篇幅的关系,这个章节只会对这些知识做简要的介绍。如果已经了解,可跳过这一章节。这些前置知识有:孪生网络,Contrastive Loss,Triple Loss
孪生网络
简单来说,孪生网络可用来衡量两个输入的相似度。孪生网络的结构如下图所示,两个输入经过完全一样的神经网络,输出为各自的高维向量表征。得到输入的向量特征后,可以通过余弦相似度计算两个输入的相似度,也可以计算特征间的距离,如欧氏距离,通过loss计算,来评价模型的特征表示效果。
既然提到loss方程,接下来就要介绍两个ranking loss,用于学习相对距离,相关关系,常被用于孪生网络中。

图1 孪生网络结构
Contrastive Loss
中文称为【对比损失函数】,表达式如下所示。其中,d表示两个向量的距离,例如一般是欧氏距离;y表示两个输入是否相似,如果相似则为1,如果不相似为0;margin是设定好的阈值,当两个样本的向量距离超过一定值,也就是margin,就表示这两个样本不相似了。
$ L=\frac{1}{2 N} \sum_{n=1}^{N} y d^{2}+(1-y) \max (\operatorname{margin}-d, 0)^{2}$
从式子上我们可以发现,如果两个输入相似(即y=1),则式中只剩下 $ d^{2} $。这符合我们的直观感受:如果两个输入相似,向量的距离越大,则损失越大。如果两个输入不相似(即y=0),则式中只剩下 $ \max (\operatorname{margin}-d, 0)^{2} $。这里应该理解为:当两个输入不相似时,若向量的距离大于margin,则损失为0;若向量的距离小于margin,且距离越小,损失越大。于是优化的方向为让相似样本的向量特征距离变小,让不相似样本的向量特征距离超过阈值。
这里有张经典的图,如下图所示,红色虚线为相似时的曲线,蓝色实线为不相似情况的曲线,横坐标为样本间的特征距离,横坐标上有个特殊的点是margin值,纵坐标是损失值。从图上我们也发现,相似情况下(即红色曲线)损失值随距离的增大而增大;不相似的情况下(即蓝色曲线)损失值随距离的缩小而减小,且距离大于等于margin时,损失为0。(这两个曲线圈起来,后面要考的)
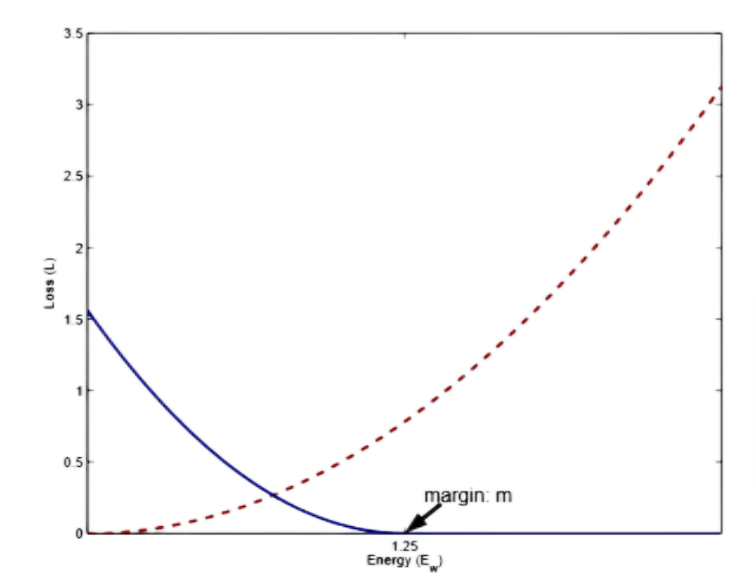
图2 Contrastive Loss 损失与距离的关系图
Triple Loss
中文称为【三元损失函数】,顾名思义,计算一次loss要同时输入三元:锚点样本(anchor),正样本(positive),负样本(negative),分别用$a,p,n$表示,损失函数的表达式如下所示。其中,$r_{a}, r_{p}, r_{n}$分别表示锚点样本,正样本,负样本的高维向量表征。而$\mathrm{d}(r_{a}, r_{p}), \mathrm{d}(r_{a}, r_{n}) $表示$<a,p>$之间的距离和$<a,n>$之间的距离。同样的,这里的m也是margin,是设定好的阈值,表示希望的$\mathrm{d}(r_{a}, r_{n})$ 与 $\mathrm{d}(r_{a}, r_{p}) $的差距。
$ L\left(r_{a}, r_{p}, r_{n}\right)=\max \left(0, m+\mathrm{d}\left(r_{a}, r_{p}\right)-\mathrm{d}\left(r_{a}, r_{n}\right)\right) $
从上面的式子中我们可以发现,当$\mathrm{d}(r_{a}, r_{n}) $比$\mathrm{d}(r_{a}, r_{p})$大,损失就小;且差距越大,损失越小;直到差值大于margin,损失为0。相反,如果差距越小,损失越大;甚至$\mathrm{d}(r_{a}, r_{p})$比$\mathrm{d}(r_{a}, r_{n}) $还大时,损失值就很大了。
整体思路
训练过程
了解了前面介绍的前置知识之后,再看图像检索的训练过程,就会理解他的用意。
下图是作者在GitHub和论文中都展示的图片,很好地表示了其核心思想。这里我对图中的文字做了本土化,如果想看原本的表达,再次指路GitHub或者论文。示意图中的$ \overline{\mathbf{f}}( ) $表示图像的高维特征向量。该图中的上半部分描述了原始图像转化为高维向量特征的过程:图像经过卷积层(也即卷积神经网络,如ResNet等去掉最后一层【全连接层】),再经过池化层和$\ell_{2}$归一化操作(即向量单位化),最终形成一个图像的固定维度的向量表示。示意图的下半部分描述了训练时,使用对比损失函数的情况。示意图中的两条Loss-dist曲线就是图2中的拆分。
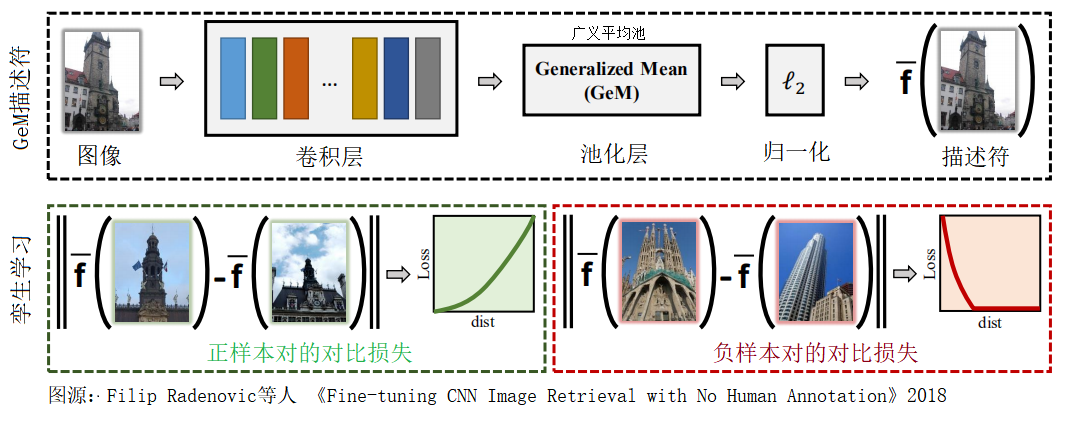
图3 图像检索训练示意图
检索过程
对于检索的过程,我自己画了如下图所示的示意图。检索过程如下:
- 图片池里的图片转换为列向量特征,多个列向量特征再拼在一起组成矩阵;
- 将查询对象转换为列向量特征,如果有多个查询对象同时查询,则将它们的列向量特征拼成矩阵。
- 将图片池的特征矩阵转置后与查询对象的向量特征(即计算余弦相似度)得到相似度的结果。这个结果中第i行,第j列元素表示的是第i个图片池中的图片与第j个查询对象的相似度
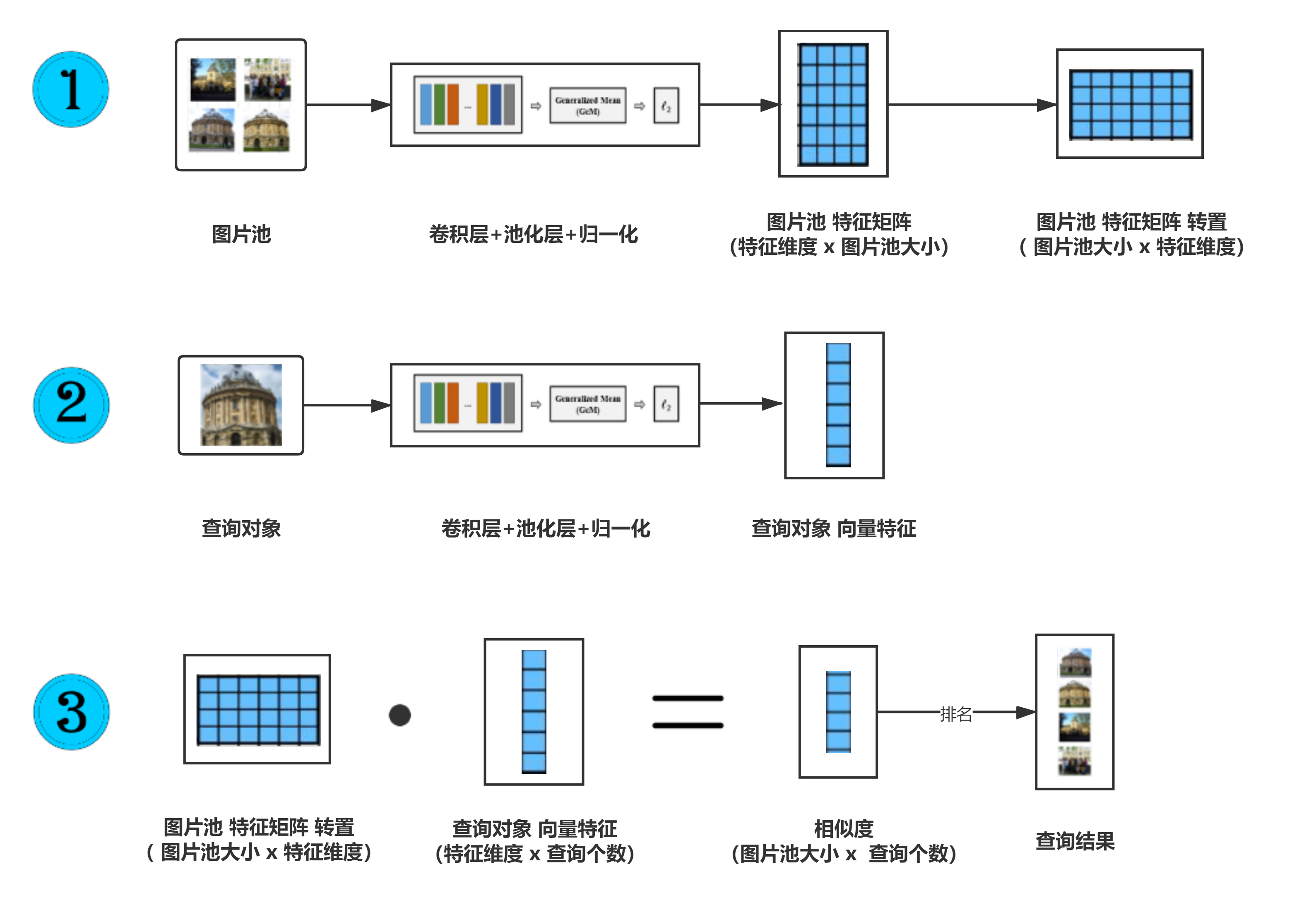
图4 图像检索过程示意图
欧氏距离与余弦相似度
看到这里,不知道大家有没有疑问:训练过程,loss方程用的是Contrastive Loss或者Triple Loss 本质都是让相似样本的距离更近,不相似样本的距离更远。这里的距离用的是欧氏距离。但实际检索时,不是用样本间的欧氏距离排名,而是用余弦相似度排名。诚然,余弦相似度计算更简单,只要矩阵乘法运算,不需要像欧氏距离一样计算平方。但是,从理论上来说,这样是可行的吗?难道向量间的欧氏距离越近,余弦相似度越高?如果没有这个疑问的小伙伴就跳过这part吧!
回到我们的疑问:难道向量间的欧氏距离越近,余弦相似度越高?这当然不是绝对的,我们可以很轻松举出反例。那难度作者错了吗?并没有,这个结论在一定条件下是可以成立的,那就是当向量的模长一定时,这个结论是成立的!而作者早在图3中,就保证了这关键的一步,是的,就是$\ell_{2}$归一化操作(即向量单位化)。这些向量特征都是单位向量!
下面是以上结论的一个证明:其实,向量间的欧氏距离和余弦相似度由余弦公式建立联系的,设两个向量分别为 $\boldsymbol{a}$, $\boldsymbol{b}$ ,则有以下的关系。其中,$ d_{<\boldsymbol{a}, \boldsymbol{b}>} $ 表示两个向量间的欧氏距离。由这个公式我们可以得知,两个向量模长一定时,欧氏距离越近,余弦相似度越高。
$ d_{<\boldsymbol{a}, \boldsymbol{b}>}^{2} = \left |\boldsymbol{a} \right |^{2} + \left |\boldsymbol{b} \right |^{2} - 2\boldsymbol{a}\cdot \boldsymbol{b} $
数据集介绍
作者使用了 retrieval-SfM-120k 作为训练集和验证集。使用Oxford5k,Paris6k,ROxford5k,RParis6k作为测试集。接下来对这几个数据集做个介绍,会涉及到具体的文件细节。
retrieval-SfM-120k
retrieval-SfM-120k是若干张建筑物的图片,它们已经分好了簇,相似图片在一个簇里,不同簇的图片即为不相似。还有若干对q-p图片,q表示查询,p表示相似的图片。
文档结构
retrieval-SfM-120k 下载解压后目录结构包含ims文件夹,retrieval-SfM-120k.pkl 和retrieval-SfM-120k-whiten.pkl。其中 ims 文件夹 存放图片 。 retrieval-SfM-120k.pkl 存 放 图 片相关信息。retrieval-SfM-120k-whiten.pkl 的内容还不了解,这里不做解释,不影响代码整体的理解。
ims 下还有三级目录。其中图片的文件名(代码中称为 cid)的逆序的前六位决定了图片的路径,如某图的 cid 逆序前六位为 123456,则其路径为./ims/12/34/56。
retrieval-SfM-120k.pkl 包含了这个 database 的相关信息。其字典结构图如图 5 所示。其中按mode分为train和val。train和val又是两个字典,分别包含cids,cluster,qidxs, pidxs这四个关键字,这四个key对应的value都是列表。其中 cids 是所有图片的文件名列表;cluster 是由 cids 中对应图片的 clusterID 组成的列表;qidxs 和 pidxs 是一一对应的,组成一对对 q-p对,其中 q 表示查询对象在 cids 中的下标,p 表示与查询对象匹配的图像在 cids的下标。而图中的数字为该列表的元素个数。

图5 retrieval-SfM-120k.pkl字典结构
Oxford5k, Paris6k,ROxford5k,RParis6k
Oxford5k 由 5062 张已被人工标注的图片组成,其中有 55 张是查询对象,是11 个地标的五种不同拍摄条件下的图片。类似地,Paris6k 数据集由 6412 个图像和 55 个查询组成。而ROxford5k和RParis6k是Radenovi 等人,重新整理了Oxford5k,Paris6k这两个数据集而成的。所做的改动如下:每个数据集新增了 15 个查询;修改标注错误和数据集大小;还根据答案集的不同,设置了挑战级别:Easy,Medium,Hard。
文档结构
代码中会自动下载对应的测试集,这四个数据集下载后的文档结构比较像,以Oxford5k为例,有一个名为jpg的文件夹和一个gnd_oxford5k.pkl的文件。
其中,jpg的文件夹里面存放的就是图片,gnd_oxford5k.pkl文件存放的是图片的检索信息。
接下来具体介绍各个gnd_xxx.pkl文件,其中xxx是对应的数据集名称,如oxford5k,paris6k等。这些gnd_xxx.pkl文件存放一个了dict,其字典结构如图6所示。其中,imlist 和 qimlist 都是列表,保存着每张图片或查询对象的文件名,下面的数字是列表长度。而 gnd 也是列表,和 qimlist 列表是一一对应的,保存了对应的查询图像的检索信息。而每个gnd元素都是字典,都包含若干项关键字,包含的关键字如图6所示。其中 bbx 内有 4 个元素,为int类型:x1,y1,x2,y2, 表示了查询图片的具体查询区域。而ok,junk是与查询对象匹配与不匹配的图片在 imlist 的索引列表,easy,hard,junk也是针对查询对象的匹配程度分出来的图片在 imlist 的索引列表,根据这三个列表,可以把检索分为三个难度:Easy,Medium,Hard。

图6 gnd_xxx.pkl 字典结构
正负集划分
如果是 Oxford5k 和 Paris6k,正类就是ok列表,负类就是junk列表。而对于 ROxford5k 和 RParis6k,会分成三个难度:Easy(E),Medium(M),Hard(H),这三个难度下的正负类划分不太一样,具体见表 1。
| E | M | H | |
| 正类 | easy | easy, hard | hard |
| 负类 | hard, junk | junk | junk, easy |
具体实现细节
这一章节会涉及到具体的实现细节。这一章节提到的过程,都是默认参数下的过程,减少了许多可选操作的说明,如白化操作等。
- 模型 AlexNet,Vgg16,ResNet101等经典模型去掉全连接层作为卷积层,再加上一层池化操作和$\ell_{2}$正则化操作。其中池化可以是最大值池化,平均值池化和广义平均值池化(数学上,广义平均值也就是p次幂平均)。
- 数据库的选择 训练集:retrieval-SfM-120k['train'],验证集:retrieval-SfM-120k['val'],测试集:Oxford5k, Paris6k, ROxford5k, RParis6k。
- 训练时模型的输入 训练集中的图片通过模型变成特征向量。从中选取qsize(q-p对的个数)个元组。每个元组共有(1+1+nnum)个特征向量,分别是查询对象q,正类p和nnum个负类n1,n2....查询和正类是由q-p对直接给出。负类是q由当前模型的在图片池中的查询结果,按照查询顺序从上到下依次选取nnum个与q在不同簇的图片,且这nnum个图片也在不同的簇中。(注:这些元组在不同的epoch就会更新一次,因为模型更新了。)这里呼应了论文标题中的No Human Annotation(不需要人工标注)。
- 训练时模型的输出 每个元组经过模型的向量特征组成的矩阵(矩阵维度:特征维度*(1+1+nnum) )
- 训练的标签 [-1,1,0,0,...,0]。-1代表查询对象,1表示匹配,0表示不匹配。与输入的元组的每个特征向量一一对应。
- 损失函数 如果是Contrastive Loss,每个元组的loss是nnum个负类与查询对象的Contrastive Loss 和 nnum个相同的正类与查询对象的Contrastive Loss 的和;如果是Triple Loss,每个元组的loss是nnum个(查询对象,正类,其中一个负类)的Triple Loss 的和。他们的d都是用向量的欧氏距离定义的。
- 训练的优化 采用Adam算法优化,学习率随着epoch指数衰减,公式为: $ l r=l r_{0} \times \gamma^{\text {epoch }} $
- 测试时模型的输入 测试集中图库的图片和查询对象的图片
- 测试时模型的输出 查询对象的特征矩阵(所有查询对象的特征向量组成的矩阵)和图库图片特征矩阵(图库图片所有的特征向量组成的矩阵)
- 测试的检索排名 图库图片特征矩阵与查询对象特征矩阵的点乘,得到的是scores矩阵(维度:图库图片数量* 查询数量),其中第i行,第j列表示图片池中的第i个图片与第j个查询对象的相似度得分。ranks是scores的按列排序的索引值,即得分高的图片的索引排在前面,是最终的检索结果。
- 检索的评价指标 Oxford5k 和 Paris6k 的检索结果的指标是 mAP(mean Average Precision),AP 是单个查询结果的平均准确率,mAP 是所有查询结果 AP 的平均。ROxford5k 和 RPairs6k 的检索指标比较丰富。除了mAP 用于评价整体的检索质量外,新增了 mP@k,是结果列表中 top-k 检索结果的准确率指标,反映了搜索引擎的质量。匹配的图片排的越前面得分会越高,不匹配的图片越排在匹配的后面得分会越高。
文件目录
代码的文件结构及其说明如下所示。
.
│ LICENSE
│ README.md
│
└─cirtorch
│ __init__.py
│
├─datasets 数据集加载和处理
│ datahelpers.py 图片处理方法
│ genericdataset.py 定义通过文件名列表加载图片的方法
│ testdataset.py 定义生成测试集的方法
│ traindataset.py 定义生成训练集和验证集的方法
│ __init__.py
│
├─examples 包含所有可运行的文件
│ test.py 测试模型(相比e2e版本,增加许多可选操作)
│ test_e2e.py 端到端测试模型
│ train.py 训练模型
│ __init__.py
│
├─layers 定义神经网络里的层操作方法
│ functional.py 定义以下三个文件要用的函数
│ loss.py 定义损失函数
│ normalization.py 定义正则化方法
│ pooling.py 定义池化方法
│ __init__.py
│
├─networks 定义所用的模型
│ imageretrievalnet.py 定义模型,初始化模型,定义通过模型生成特征的方法
│ __init__.py
│
└─utils 包含所有工具文件
download.py 下载各个数据集
download_win.py 未知,没怎么用到
evaluate.py 定义计算检索评价指标的方法
general.py 定义通用的工具方法
whiten.py 定义白化方法
__init__.py
后记
关于训练和测试的代码运行,GitHub上都有相关的指导,这里就不多赘述。这篇文章旨在解读代码,帮助初入门的同学快速掌握基本思想。对于数据集的一些更精妙的设计,以及对图像的白化处理等,这里由于水平的限制,都避开不谈,想要了解的同学,可以深入阅读论文,这篇博客并没有对这些内容进行解读。如果文中有错误的地方,欢迎大家私信或评论。
《CNN Image Retrieval in PyTorch: Training and evaluati-ng CNNs for Image Retrieval in PyTorch》代码思路解读的更多相关文章
- 【PyTorch深度学习60分钟快速入门 】Part1:PyTorch是什么?
0x00 PyTorch是什么? PyTorch是一个基于Python的科学计算工具包,它主要面向两种场景: 用于替代NumPy,可以使用GPU的计算力 一种深度学习研究平台,可以提供最大的灵活性 ...
- 【小白学PyTorch】6 模型的构建访问遍历存储(附代码)
文章转载自微信公众号:机器学习炼丹术.欢迎大家关注,这是我的学习分享公众号,100+原创干货. 文章目录: 目录 1 模型构建函数 1.1 add_module 1.2 ModuleList 1.3 ...
- (原)CNN中的卷积、1x1卷积及在pytorch中的验证
转载请注明处处: http://www.cnblogs.com/darkknightzh/p/9017854.html 参考网址: https://pytorch.org/docs/stable/nn ...
- ubuntu之路——day18 用pytorch完成CNN
本次作业:Andrew Ng的CNN的搭建卷积神经网络模型以及应用(1&2)作业目录参考这位博主的整理:https://blog.csdn.net/u013733326/article/det ...
- (转)Awesome PyTorch List
Awesome-Pytorch-list 2018-08-10 09:25:16 This blog is copied from: https://github.com/Epsilon-Lee/Aw ...
- 使用pytorch构建神经网络的流程以及一些问题
使用PyTorch构建神经网络十分的简单,下面是我总结的PyTorch构建神经网络的一般过程以及我在学习当中遇到的一些问题,期望对你有所帮助. PyTorch构建神经网络的一般过程 下面的程序是PyT ...
- 吐血整理:PyTorch项目代码与资源列表 | 资源下载
http://www.sohu.com/a/164171974_741733 本文收集了大量基于 PyTorch 实现的代码链接,其中有适用于深度学习新手的“入门指导系列”,也有适用于老司机的论文 ...
- Note | PyTorch官方教程学习笔记
目录 1. 快速入门PYTORCH 1.1. 什么是PyTorch 1.1.1. 基础概念 1.1.2. 与NumPy之间的桥梁 1.2. Autograd: Automatic Differenti ...
- 转 Pytorch 教学资料
本文收集了大量PyTorch项目(备查) 转自:https://blog.csdn.net/fuckliuwenl/article/details/80554182 目录: 入门系列教程 入门实例 图 ...
随机推荐
- 容器随Docker启动而启动
在容器开启状态下 docker container update --restart=always 容器名
- idea设置js为ES6
- 修改wordpress版权信息
修改页脚版权信息位置:找到C:\wamp64\www\wordpress\wp-content\themes\travelify\library\structure\footer-extensions ...
- myysql 不能远程访问的解决办法
1.通过navicat或者命令行,将user表中原来host=localhost的改为host=% 命令行方式: mysql> update user set host = '%' where ...
- 狂神说Elasticsearch7.X学习笔记整理
Elasticsearch概述 一.什么是Elasticsearch? Lucene简介 Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供 Lucene提供了一个简 ...
- Handle详解
首先通过一个函数启动一个服务器,只提供一个方法并返回Hello World!,当你在浏览器输入http://127.0.0.1:8080,就会看到Hello World. 对于http.ListenA ...
- JEP 尝鲜系列 3 - 使用虚线程进行同步网络 IO 的不阻塞原理
相关 JEP: JEP 353 Reimplement the Legacy Socket API JEP 373 Reimplement the Legacy DatagramSocket API ...
- golang:TCP总结
在TCP/IP协议中,"IP地址+TCP或UDP端口号"唯一标识网络通讯中的一个进程."IP地址+端口号"就对应一个socket.欲建立连接的两个进程各自有一个 ...
- Scala 关键字
Java关键字 Java 一共有 50 个关键字(keywords),其中有 2 个是保留字,目前还不曾用到:goto 和 const.true.false 和 null 看起来很像关键字,但实际上只 ...
- 使用Tomcat插件控制台中文乱码解决方案(IDEA)(Day_51)
解决方案 1. File -> Settings... 2. 搜索 Runner (运行程序),在 'VM options:' 中添加:-Dfile.encoding=GB2312 注:GB23 ...