MySQL高级查询 & 事务机制
1.基础查询where
高级条件查询Where子句
SELECT empno,ename,sal,hiredate FROM t_tmp
WHERE deptno=10 AND (sal+IFNULL(comm,0)*12)>=15000
AND DATEDIFF(NOW(),hiredate)/365>=20;
Where 中搭配四种运算符
算数运算符:+ - * / %
比较运算符:> >= < <= = != IN IS NULL, IS NOT NULL,BETWEEN AND,LIKE ,REGEXP
逻辑运算符:AND OR NOT XOR
各种子句的执行顺序:FROM→WHERE→SELECT→ORDER BY→LIMIT
发现一个很好的笔记来自欧阳熊猫的慕课手记
# 查询
SELECT * FROM table_name;
SELECT empno, sal*12 AS "income" FROM t_table;
SELECT * FROM runoob_tbl WHERE runoob_author = '菜鸟教程';
SELECT DISTINCT runoob_id FROM table_name; # 返回不同值
SELECT * FROM table ORDER BY DATE DESC LIMIT 1; # 时间最近的一个
SELECT * FROM table ORDER BY DATE DESC LIMIT 0,1; # 时间最近的一个(可能有去重的效果,比如时间相同) 0是起始,1是偏移量
SELECT * FROM table ORDER BY DATE DESC LIMIT 1 OFFSET 2; # 等价于 LIMIT 2,1 即最近的倒数第三个
# 并集操作符UNION 合并两个操作的结果
(SELECT country FROM Websites) UNION ALL (SELECT country FROM apps ORDER BY country); # have duplicated elements
# 关键词 where BETWEEN AND OR IN ()
SELECT prod_name,pro_price FROM products WHERE(vend_id = 1002 OR vend_id = 1003) AND prod_price >=10;
SELECT prod_name,pro_price FROM products WHERE vend_id IN (1002,1003);
SELECT prod_name,pro_price FROM products WHERE vend_id NOT IN (1002,1003);
# 通配符 搭配like % 表示多个字符, _表示单一字符
SELECT prod_name,pro_price FROM products WHERE vend_id like '100_';
SELECT prod_name,pro_price FROM products WHERE prod_name like 'jet%';
# 正则 REGEXP
SELECT prod_name,pro_price FROM products WHERE prod_name REGEXP '1000' ORDER BY prod_name;
SELECT prod_name,pro_price FROM products WHERE prod_name REGEXP '1000|2000' ORDER BY prod_name;
SELECT prod_name,pro_price FROM products WHERE prod_name REGEXP '[123]' ORDER BY prod_name;
# like 和 REGEXP的区别就是 like匹配整个字段,\\ 是转义符
2.高级查询
聚合函数(不能用出现在WHERE子句)
SELECT COUNT(*) FROM t_emp WHERE hiredate >="1985-01-01" AND sal>AVG(sal); 这个无法执行
AVG SUM MAX MIN COUNT()
count(*) 包含空值
SELECT SUM(ename) FROM t_tmp;
分组查询 GROUP BY
默认情况下汇总函数是对全表范围内的数据做统计
GROUP BY 子句通过一定的规则将一个数据集划分若干小的区域,针对每个小区域分别进行数据汇总处理
SELECT deptno,AVG(sal) FROM t_emp GROUP BY deptno;查询语句中若含有GROUP BY子句,那么SELECT子句的字段可以包括聚合函数或GROUP BY子句的分组列,其余内容均不可以出现在SELECT子句中
HAVING子句-过滤分组
WHERE 过滤指定的行,HAVING在数据分组后过滤分组,即运行在分组后
例子:查询部门平均底薪超过2000元的部门编号
错误写法:SELECT deptno FROM t_emp WHERE AVG(sal) GROUP BY deptno
原因:WHERE 在 GROUP BY 前,但是并不知道如何去算 AVG
正确写法:SELECT deptno FROM t_emp GROUP BY deptno HAVING AVG(sal) >=2000
例子2:查询每个部门中,1982年以后入职的员工超过2个人的部门编号
SELECT deptno FROM t_emp WHERE hiredate >="1982-01-01" GROUP BY deptno HAVING COUNT(*) >=2
5.2 多表连接
规定表连接条件
drop table t_dept;
create table t_dept(
deptno int not null primary key,
dname varchar(50),
loc varchar(50));
INSERT INTO t_dept
(deptno,dname,loc) values
(20, "RESEARCH", "DALLAS"),
(30,"SALES","CHICAGO"),
(40,"OPERATIONS","BOSTON");
DROP table t_emp;
create table t_emp(
empno int not null primary key,
ename varchar(50),
job varchar(50),
mgr int,
hiredate DATE not null,
sal FLOAT NOT NULL,
comm FLOAT,
deptno int,
FOREIGN KEY (deptno) REFERENCES t_dept(deptno));
INSERT INTO t_emp
(empno,ename,job,mgr,hiredate,sal,comm,deptno) values
(7369,"SMITH","CLERK",7902,"1980-12-17",800.00,NULL,20),
(7499,"ALLEN","SALESMAN",7689,"1981-02-20",1600,300,30),
(7521,"WARD","SALESMAN",7689,"1981-02-22",1250,500,30),
(7566,"JONES","MANAGER",7839,"1981-04-02",2975,NULL,20),
(7654,"MARTIN","SALESMAN",7698,"1981-09-28",1250,1400,30),
(7698,"BLAKE","MANAGER",7839,"1981-05-01",2850,NULL,30),
(7782,"CLARK","MANAGER",7839,"1981-06-09",2450,NULL,10),
(7788,"SCOTT","ANALYST",7566,"1982-12-09",3000,NULL,20),
(7839,"KING","PRESIDENT",NULL,"1981-11-17",5000,0,30),
(7844,"TURNER","SALESMAN",7698,"1981-09-08",1500,0,30),
(7876,"ADAMS","CLERK",7788,"1983-01-12",1100,NULL,20),
(7900,"JAMES","CLERK",7698,"1981-12-03",950,NULL,30),
(7902,"FORD","ANALYST",7566,"1981-12-03",3000,NULL,20),
(7934,"MILLER","CLERK",7782,"1982-01-23",1300,NULL,10);
CREATE table t_salgrade (
grade INT PRIMARY KEY,
losal DOUBLE,
hisal DOUBLE
);
INSERT INTO t_salgrade (grade,losal,hisal) VALUES
(1,700,1200),
(2,1201,1400),
(3,1401,2000),
(4,2001,3000),
(5,3001,9999);
## 高级查询
#聚合函数
SELECT AVG(sal+IFNULL(comm,0)) as svg FROM t_emp;
SELECT SUM(sal) FROM t_emp WHERE deptno IN (10,20);
SELECT MAX(sal + IFNULL(comm,0)) FROM t_emp WHERE deptno IN(10,20);
SELECT MAX(LENGTH(ename)) FROM t_emp;
SELECT MIN(empno) FROM t_emp;
# 二者有区别
SELECT COUNT(*),COUNT(comm) FROM t_emp;
# 查询10,20部门中底薪超过2000且工龄超过15年的员工人数
SELECT COUNT(*)
FROM t_emp
WHERE deptno IN(10,20) AND sal>=2000 AND DATEDIFF(NOW(),hiredate)/365>=15;
# 查询1985年以后入职的员工,底薪超过公司平均底薪的员工数量?
SELECT COUNT(*) FROM t_emp WHERE hiredate >="1985-01-01" AND sal>AVG(sal)# 这个代码报错,聚合函数不能再WHERE子句中
# 分组查询
SELECT deptno,ROUND(AVG(sal + IFNULL(comm,0)))
FROM t_emp
GROUP BY deptno;
# 逐级分组
#q:查询每个部门,每种职位的人员数量和平均底薪
SELECT deptno,job,COUNT(*),ROUND(AVG(sal))
FROM t_emp
GROUP BY deptno,job
ORDER BY deptno;
# WITH ROLLUP对汇总结果再次做汇总计算
SELECT deptno,COUNT(*),ROUND(AVG(sal))
FROM t_emp
GROUP BY deptno WITH ROLLUP;
# GROUP_CONCAT函数 将分组查询中的某个字段拼接成一个字符串
SELECT deptno,GROUP_CONCAT(ename),COUNT(*)
FROM t_emp WHERE sal>=2000 GROUP BY deptno;
# 子句的执行顺序: FROM ->WHERE ->GROUP BY->SELECT->ORDER BY->LIMIT
# HAVING子句
# 查询部门平均底薪超过2000元的部门编号
SELECT deptno FROM t_emp GROUP BY deptno HAVING AVG(sal) >=2000;
# 查询每个部门中,1982年以后入职的员工超过2个人的部门编号
SELECT deptno
FROM t_emp
WHERE hiredate>="1982-01-01"
GROUP BY deptno HAVING COUNT(*)>=2
ORDER BY deptno;
# 按照数字1分组,MySQL会根据SELECT子句中的列进行分组,HAVING子句也可以正常使用 .BTW:虽然having能够几乎取代WHERE子句,但是WHERE子句 应该做粗筛,HAVING子句在分组后再做细筛
SELECT deptno,COUNT(*)
FROM t_emp
GROUP BY 1 HAVING deptno IN(10,30);
# 表连接查询(一)JOIN
#从多张表中提取数据,必须指定关联的条件,否则就会产生笛卡儿积,交叉连接
# 默认是 内连接,可以用"," 替代join,where替代on
SELECT e.empno,e.ename,d.dname
FROM t_emp e JOIN t_dept d
ON e.deptno=d.deptno;
# 内连接练习1
# 查询每个员工的工号、姓名、部门名称、底薪、职位、工资等级
# 涉及到 三张表,同时t_emp只有工资,而t_salgrade只有对应的工资区间和等级,并没有同名的字段
SELECT empno,ename,dname,sal,job,grade
FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno
JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal
# 内连接的数据表不一定必须有同名字段,只要字段之间符合逻辑关系就可以
# 内连接练习2
# 查询与SCOTT相同部门的员工都有谁
# 低效率方法
SELECT ename
FROM t_emp
WHERE deptno=(SELECT deptno FROM t_emp WHERE ename="SCOTT")
AND ename!="SCOTT";
# 高效率方法 相同的数据表也可以做表连接
SELECT e2.ename
FROM t_emp e1 JOIN t_emp e2 ON e1.deptno=e2.deptno
WHERE e1.ename="SCOTT" AND e2.ename!="SCOTT";
# 内连接练习3
# 查询底薪超过公司平均底薪的员工姓名
SELECT e.empno,e.ename,e.sal
FROM t_emp e JOIN
(SELECT AVG(sal) avg FROM t_emp) t ON e.sal>t.avg; # 报错
# 内连接练习4
# 查询RESEARCH部门的人数、最高底薪、最低底薪,平均底薪、平均工龄
SELECT COUNT(e.ename),MAX(e.sal),MIN(e.sal),AVG(e.sal),FLOOR(AVG(DATEDIFF(NOW(),e.hiredate)/365))
FROM t_emp e JOIN t_dept d on e.deptno=d.deptno
WHERE d.dname="RESEARCH";
#查询每种职业的最高、最低和平均工资、最高、最低工资等级。
SELECT e.job,MAX(e.sal + IFNULL(comm,0)),MIN(e.sal + IFNULL(comm,0)),AVG(e.sal + IFNULL(comm,0)),MAX(s.grade),MIN(s.grade)
FROM t_emp e JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal
GROUP BY e.job
# 查询每个底薪超过部门平均底薪的员工信息
SELECT e.ename
FROM t_emp e JOIN
(SELECT deptno,AVG(sal) as avg FROM t_emp GROUP BY deptno) ad on e.deptno=ad.deptno AND e.sal>=ad.avg;
# 外连接:结果还会保存不符合条件的记录
INSERT INTO t_emp (empno,ename,job,mgr,hiredate,sal,comm,deptno) VALUES (8000,"陈浩","SALESMAN",7698,"1982-07-19",1500.00,NULL,NULL)
# 左外连接保留左表所有的记录,与右表做连接;右表有匹配就连,没有匹配就用null
SELECT e.empno,e.ename,d.dname
FROM t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno;
# 外连接练习1
# 查询每个部门的名称和部门的人数
SELECT dname,count(e.deptno)
FROM t_dept d LEFT JOIN t_emp e ON d.deptno=e.deptno
GROUP BY e.deptno;
# 查询每个部门的名称和部门的人数,如果没有部门的员工,就用null替换
(SELECT dname,count(e.deptno)
FROM t_dept d LEFT JOIN t_emp e ON d.deptno=e.deptno
GROUP BY e.deptno) UNION
(SELECT dname,count(*)
FROM t_dept d RIGHT JOIN t_emp e ON d.deptno=e.deptno
GROUP BY d.deptno)
# 查询每名员工的编号、姓名、部门、月薪、工薪等级和工龄,上司的编号、姓名和部门
SELECT
e.empno,e.ename,d.dname,e.sal+IFNULL(e.comm,0),s.grade,
FLOOR(DATEDIFF(NOW(),e.hiredate)/365),t.empno,t.ename,t.dname
FROM t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno
LEFT JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal
LEFT JOIN
(SELECT e1.empno,e1.ename,d1.dname
FROM t_emp e1 JOIN t_dept d1 ON e1.deptno=d1.deptno) t ON e.mgr=t.empno;
# 子查询:可以写在where,from, select,推荐from子句子查询
# 下面查询底薪超过公司平均底薪的员工的信息用 where 与 from 子查询的比较
SELECT empno,ename,sal FROM t_emp WHERE sal>=(SELECT AVG(sal) FROM t_emp);
SELECT e.empno,e.ename,e.sal,t.avg
FROM t_emp e JOIN (SELECT deptno,AVG(sal) as avg
FROM t_emp GROUP BY deptno) t ON e.deptno=t.deptno AND e.sal>=t.avg;
# 还是 表连接查询最好
# 单行子查询(结果是一行记录)和多行子查询(结果是多行记录),后者只能出现在WHERE子句和FROM子句中
# 问题:用子查询查看FORD和MARTIN的同事
SELECT ename
FROM t_emp WHERE
deptno IN (SELECT deptno FROM t_emp WHERE ename IN ("FORD","MARTIN")) AND ename NOT IN ("FORD","MARTIN");
# WHERE子句中,可以使用IN、All、ANY,EXISTS关键字来处理多行表达式结果集的条件判断
# 查询比FORD 和MARTIN底薪都高的员工信息
SELECT ename
FROM t_emp WHERE
sal > ALL (SELECT sal FROM t_emp WHERE ename IN ("FORD","MARTIN"));
# 批判去学:EXISTS关键词使用:查询工资等级是3级和4级的员工信息;
SELECT ename
FROM t_emp
WHERE EXISTS(
SELECT * FROM t_salgrade
WHERE sal BETWEEN losal AND hisal AND grade IN (3,4)
);
3.查询总结
MySQL语法顺序
- select[distinct]
- from
- join(如left join)
- on
- where
- group by
- having
- union
- order by
- limit
MySQL执行顺序
- from
- on
- join
- where
- group by
- having
- select
- distinct
- union
- order by
4.事务机制
具体内容可以参考《MySQL必知必会》第26章
上述的所有语句都是运行后,与服务器连接并直接就修改了数据库的内容,但是如果突然宕机或者发生错误,就会导致部分修改的情况。为了避免写入直接操作数据文件,引入事务机制。保证要么全部修改,要么全部没修改(回退)。
事务处理是一种机制,用来管理必须成批执行的MySQL操作,以保证数据库不包含不完整的操作结果。利用事务处理,可以保证一组操作不会中途停止,它们或者作为整体执行,或者完全不执行(除非明确指示)。如果没有错误发生,整组语句提交给(写到)数据库表。如果发生错误,则进行回退(撤
销)以恢复数据库到某个已知且安全的状态. 参考《MySQL必知必会》
从MySQL5.0开始引入事务机制
1.undo和redo日志、开启事务(start transaction)、提交事务(commit)、回滚事务(Rollback)
利用日志来实现间接写入
日志文件相当于数据文件的副本,undo日志拷贝数据,redo记录修改,先在redo日志中尝试修改,没有问题再同步数据,有问题,数据库重启后重新同步
RDBMS=SQL语句+事务(ACID)
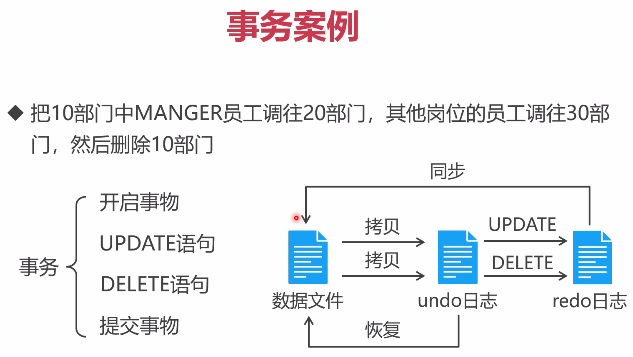
1.手动管理事务
START TRANSACTIN;
任意数量SQL语句;
[COMMIT|ROLLBACK];
2.事物的ACID属性
原子性:一个事务的所有操作要么全部完成,要么全部失败。事务制行后,不允许停留在中间某个状态。
一致性:不管在任何给定的时间,并发事务有多少,事务必须保证运行结果的一致性
隔离性 :隔离性要求事务不受其他并发事物的影响,如同在给定时间内,该事物是数据库唯一运行的事务。默认下A事务只能看到日志中该事物的相关数据
持久性 :事务一旦提交,结果是永久的,即使宕机,依然可以依靠事务日志完成数据持久化
事务并发情况下的隔离级别
不同具体应用场景灵活应用不同隔离级别
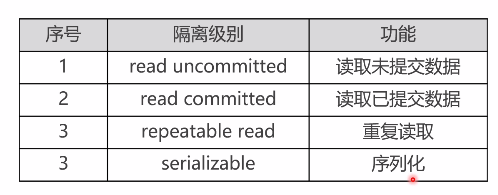
- READ UNCOMMITTED 代表可以当前事务可以读取其他事务未提交的临时数据信息,场景:购火车票
SET SESSION TRANSACTION ISOLATION LEVEL
READ UNCOMMITTED;
READ COMMITTED 场景:转账消费后余额
repeatable read 场景:当前事务不受其他事务提交后的影响,比如电商下单一个价没支付,然后涨价的情况。MySQL默认的就是这个
序列化牺牲了数据库并发性
MySQL高级查询 & 事务机制的更多相关文章
- Mysql高级之事务
原文:Mysql高级之事务 通俗的说事务: 指一组操作,要么都成功执行,要么都不执行.---->原子性 在所有的操作没有执行完毕之前,其他会话不能够看到中间改变的过程-->隔离性 事务发生 ...
- 第四章 MySQL高级查询(二)
第四章 MySQL高级查询(二) 一.EXISTS子查询 在执行create 或drop语句之前,可以使用exists语句判断该数据库对像是否存在,返回值是true或false.除此之外,exists ...
- 第三章 MySQL高级查询(一)
第三章 MySQL高级查询(一) 一.SQL语言的四个分类 1. DML(Data Manipulation Language)(数据操作语言):用来插入,修改和删除表中的数据,如INSE ...
- MySQL 高级查询操作
目录 MySQL 高级查询操作 一.预告 二.简单查询 三.显示筛选 四.存储过程 五.查询语句 1.作为变量 2.函数调用 3.写入数据表 备注 附表一 附表二 相关文献 博客提示 MySQL 高级 ...
- python进阶09 MySQL高级查询
python进阶09 MySQL高级查询 一.筛选条件 # 比较运算符 # 等于:= 不等于:!= 或<> 大于:> 小于:< 大于等于>= 小于等于:<= #空: ...
- MySQL高级查询与编程作业目录 (作业笔记)
MySQL高级查询与编程笔记 • [目录] 第1章 数据库设计原理与实战 >>> 第2章 数据定义和操作 >>> 2.1.4 使用 DDL 语句分别创建仓库表.供应 ...
- MySQL高级查询与编程笔记 • 【目录】
章节 内容 实践练习 MySQL高级查询与编程作业目录(作业笔记) 第1章 MySQL高级查询与编程笔记 • [第1章 数据库设计原理与实战] 第2章 MySQL高级查询与编程笔记 • [第2章 数据 ...
- MySQL高级以及锁机制
MySQL高级 推荐阅读: 锁:https://www.cnblogs.com/zwtblog/tag/锁/ 数据库:https://www.cnblogs.com/zwtblog/tag/数据库/ ...
- Day3 MySql高级查询
DQL高级查询 多表查询(关联查询.连接查询) 1.笛卡尔积 emp表15条记录,dept表4条记录. 连接查询的笛卡尔积为60条记录. 2.内连接 不区分主从表,与连接顺序无关.两张表均满足条件则出 ...
随机推荐
- Redis:银河麒麟arm服务器安装redis5.0.3,配置开机自启
百度网盘下载地址 链接:https://pan.baidu.com/s/1f2ghL2-0brPt0IodjfqOqQ提取码:9al1 解压tar包 #解压tar包 tar -xvf arm-r ...
- ExtJs4学习(十)Grid单元格换色和行换色的方法
Grid单元格换色 { text:'类别', dataIndex:'type', align:'center', renderer:function(value,metaData){ console. ...
- Laravel + Swoole 打造IM简易聊天室
最近在学习Swoole,利用Swoole扩展让PHP生动了不少,本篇就来Swoole开发一款简易的IM聊天室 应用场景:实现简单的即时消息聊天室. (一)扩展安装 pecl install swool ...
- runtime使用总结
runtime这个东西,项目是很少用到的,但面试又避不可少,了解其内部的机制对底层的理解还是很有必要的. 1.动态添加属性 拓展类别属性的简单实现 a.定义字面量指针 static char dyna ...
- Docker 基础备忘录
Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的.可移植的.自给自足的容器.开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机).bare metal. ...
- Python - r'', b'', u'', f'' 的含义
字符串前加 f(重点!敲黑板!) 作用:相当于 format() 函数 name = "帅哥" age = 12 print(f"my name is {name},ag ...
- EXCEL中的多个条件同时成立写法
=IF(AND($B2>0,$C2>0,$D2>0,$E2>0),(($B2*1000/$C2/60/$D2)*$E2),0)点击F2,粘贴上边的公式选择F2到f200ctrl ...
- 【深度学习】在linux和windows下anaconda+pycharm+tensorflow+cuda的配置
在linux和windows下anaconda+pycharm+tensorflow+cuda的配置 在linux和windows下anaconda+pycharm+tensorflow+cuda的配 ...
- Python+Requests+Xpath实现动态参数获取实战
1.古诗文网直接登录时,用浏览器F12抓取登录接口的入参,我们可以看到框起来的key对应的value是动态参数生成的,需获取到: 2.登录接口入参的值一般是登录接口返回的原数据值,若刷新后接口与对应源 ...
- CentOS 7安装Python3 笔记
当前系统为阿里云的CentOS7.3 64位操作系统. 为了能让后续安装的软件(django,uwsgi,nginx等)尽量减少出现bug的几率,先把可能的依赖包都安装上. 一.安装依赖包 yum - ...