MNIST手写数字识别:卷积神经网络
代码
import torch
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
from torchvision import transforms #从torchvision中引入图像转换
#采用随机批量梯度下降,batch_size设为64
batch_size = 64
#用Compose串联多个“图片变换操作”(此处将ToTensor和Normalize组合)
transform = transforms.Compose([
#ToTensor()将shape为(H, W, C)de numpy.darray或者img转为shape为(C, H, W)的tensor,其将每一个数值归一化到(0,1)
transforms.ToTensor(),
#标准化:使用公式" (x - mean) / std ",将每一个元素分布到(-1, 1)
transforms.Normalize(mean = (0.1307,), std = (0.3081,)) #由于mnist数据集的图片均为灰度图片(单通道),所以mean和std各自值输入了一个值
])
# 获取训练集
train_dataset = datasets.MNIST(
#指定保存路径
root = "./mnist",
#获取的是训练集
train = True,
#若在指定路径下找不到目标文件则会自动下载
download = True,
#对所获取的数据集执行上述的transform处理
transform = transform
)
# 获取测试集
test_dataset = datasets.MNIST(
root = "./mnist",
train = False,
download = True,
transform = transform
)
# 定义数据加载器
train_loader = DataLoader(train_dataset, shuffle = True, batch_size = batch_size)
test_loader = DataLoader(test_dataset, shuffle = False, batch_size = batch_size)
# 定义网络模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一层卷积层采用Conv2d模块:输入1维,输出10维,卷积核尺寸5x5(此处输入输出的维度表示的是通道数),不扩充(padding),不设偏置
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5, padding=0, bias=False)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
# 池化层采用MaxPool2d模块:kernel_size=2表示池化窗口大小为2x2
self.pooling = torch.nn.MaxPool2d(kernel_size=2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
#定义batch的大小是数据张量的第0个维度的数据,也就是每次传入的批量大小
batch_size = x.size(0)
#先做卷积再做池化,然后激活
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
# 改变x的形状,为了匹配FC层的输入(传入fc层的需为二维矩阵)
x = x.view(batch_size, -1)
#送入全连接层
x = self.fc(x)
return x
# 实例化模型
model = Model()
# 构造多分类交叉熵损失函数
criterion = torch.nn.CrossEntropyLoss()
# 构造优化器:优化模型中的所有参数,学习率=0.01, 加入一个冲量0.5
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01, momentum=0.5)
# 定义训练过程
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if(batch_idx+1) % 300 ==0:
print(f' [Epoch:{epoch+1},Btach_idx:{batch_idx+1}],loss:{running_loss / 300:.3f} ')
running_loss = 0
# 定义测试过程
def test():
# 已经预测结束且预测正确的样本数(初始化为0 )
correct = 0
# 已经预测结束的样本数(初始化为0)
total = 0
with torch.no_grad(): #测试过程不需要梯度优化
for data in test_loader:
images, labels = data
outputs = model(images)
# model最后输出的是一个10维的矩阵(1行10列),返回‘预测最大值predicted’和‘预测最大值下标’_
_, predicted = torch.max(outputs.data, dim = 1)
#更新已预测结束的样本数
total += labels.size(0)
# 更新已预测结束且预测正确的样本数
correct += (predicted == labels).sum().item()
print(f' Accuracy on testdatset:{100 * (correct/total):.2f}% ') #输出准确率
# 开始运行
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运行效果
[Epoch:1,Btach_idx:300],loss:0.627
[Epoch:1,Btach_idx:600],loss:0.190
[Epoch:1,Btach_idx:900],loss:0.143
Accuracy on testdataset:96.71%
[Epoch:2,Btach_idx:300],loss:0.115
[Epoch:2,Btach_idx:600],loss:0.097
[Epoch:2,Btach_idx:900],loss:0.086
Accuracy on testdataset:97.69%
[Epoch:3,Btach_idx:300],loss:0.080
[Epoch:3,Btach_idx:600],loss:0.073
[Epoch:3,Btach_idx:900],loss:0.069
Accuracy on testdataset:97.86%
[Epoch:4,Btach_idx:300],loss:0.062
[Epoch:4,Btach_idx:600],loss:0.064
[Epoch:4,Btach_idx:900],loss:0.061
Accuracy on testdataset:98.44%
[Epoch:5,Btach_idx:300],loss:0.052
[Epoch:5,Btach_idx:600],loss:0.051
[Epoch:5,Btach_idx:900],loss:0.059
Accuracy on testdataset:98.50%
[Epoch:6,Btach_idx:300],loss:0.049
[Epoch:6,Btach_idx:600],loss:0.048
[Epoch:6,Btach_idx:900],loss:0.050
Accuracy on testdataset:98.45%
[Epoch:7,Btach_idx:300],loss:0.047
[Epoch:7,Btach_idx:600],loss:0.041
[Epoch:7,Btach_idx:900],loss:0.045
Accuracy on testdataset:98.36%
[Epoch:8,Btach_idx:300],loss:0.040
[Epoch:8,Btach_idx:600],loss:0.042
[Epoch:8,Btach_idx:900],loss:0.041
Accuracy on testdataset:98.73%
[Epoch:9,Btach_idx:300],loss:0.032
[Epoch:9,Btach_idx:600],loss:0.041
[Epoch:9,Btach_idx:900],loss:0.038
Accuracy on testdataset:98.57%
[Epoch:10,Btach_idx:300],loss:0.033
[Epoch:10,Btach_idx:600],loss:0.035
[Epoch:10,Btach_idx:900],loss:0.036
Accuracy on testdataset:98.59%
补充
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一层卷积层采用Conv2d模块:输入1维,输出10维,卷积核尺寸5x5(此处输入输出的维度表示的是通道数),不扩充(padding),不设偏置
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5, padding=0, bias=False)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
# 池化层采用MaxPool2d模块:kernel_size=2表示池化窗口大小为2x2
self.pooling = torch.nn.MaxPool2d(kernel_size=2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
#定义batch的大小是数据张量的第0个维度的数据,也就是每次传入的批量大小
batch_size = x.size(0)
#先做卷积再做池化,然后激活
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
# 改变x的形状,为了匹配FC层的输入(传入fc层的需为二维矩阵)
x = x.view(batch_size, -1)
#送入全连接层
x = self.fc(x)
return x
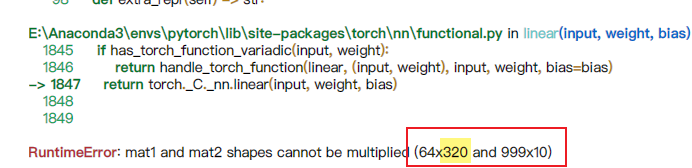
Q:self.fc = torch.nn.Linear(320, 10)中的320在不通过手算推理的前提下如何得知?
A:随便填一个数字,运行代码,通过查看报错信息获取FC层的真实输入维数

MNIST手写数字识别:卷积神经网络的更多相关文章
- 手写数字识别 卷积神经网络 Pytorch框架实现
MNIST 手写数字识别 卷积神经网络 Pytorch框架 谨此纪念刚入门的我在卷积神经网络上面的摸爬滚打 说明 下面代码是使用pytorch来实现的LeNet,可以正常运行测试,自己添加了一些注释, ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 第三节,CNN案例-mnist手写数字识别
卷积:神经网络不再是对每个像素做处理,而是对一小块区域的处理,这种做法加强了图像信息的连续性,使得神经网络看到的是一个图像,而非一个点,同时也加深了神经网络对图像的理解,卷积神经网络有一个批量过滤器, ...
- 基于TensorFlow的MNIST手写数字识别-初级
一:MNIST数据集 下载地址 MNIST是一个包含很多手写数字图片的数据集,一共4个二进制压缩文件 分别是test set images,test set labels,training se ...
- Tensorflow实现MNIST手写数字识别
之前我们讲了神经网络的起源.单层神经网络.多层神经网络的搭建过程.搭建时要注意到的具体问题.以及解决这些问题的具体方法.本文将通过一个经典的案例:MNIST手写数字识别,以代码的形式来为大家梳理一遍神 ...
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
- Pytorch入门——手把手教你MNIST手写数字识别
MNIST手写数字识别教程 要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下 [!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料 目录 MNI ...
- 手写数字识别 ----卷积神经网络模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----卷积神经网络模型 import os import tensorflow as tf #部分注释来源于 # http://www.cnblogs.com/rgvb178/p/ ...
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
随机推荐
- SQL 练习16
按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩 SELECT * from SC LEFT JOIN (SELECT sid,AVG(score) 平均成绩 from SC GROUP B ...
- reduce使用技巧
一.使用reduce同时执行map(循环)和filter(过滤) 例如,将数组中的项的值加倍,然后只选择那些大于50的项 const numbers = [10, 20, 30, 40]; const ...
- C# 如何在编译时将 dll 复制到 bin\Release 目录下
下面假设 Project 名为 Gamma4RTD,需要调用的 dll 文件为 rtddll.dll.IDE 是 Visual Studio 2015 打开 Visual Studio 2015 -& ...
- Spring整合Quartz轻松完成定时任务
一.背景 上次我们介绍了如何使用Spring Task进行完成定时任务的编写,这次我们使用Spring整合Quartz的方式来再一次实现定时任务的开发,以下奉上开发步骤及注意事项等. 二.开发环境及必 ...
- 多线程编程<四>
1 /** 2 * 守护线程daemon['diːmən] 3 * @author Administrator 4 * 5 */ 6 public class DaemonDemo { 7 publi ...
- webpack编译后的代码如何在浏览器执行
浏览器是无法直接使用模块之间的commonjs或es6,webpack在打包时做了什么处理,才能让浏览器能够执行呢,往下看吧. 使用commonjs语法 先看下写的代码, app.js minus.j ...
- 修改python import模块中的变量
可以直接通过 模块名.变量名=xx 的方式修改模块中的全局变量,测试代码如下 模块:test_model.py x = 111 def inc_x(): global x x = x + 1 测试脚本 ...
- SSE图像算法优化系列三十一:Base64编码和解码算法的指令集优化。
一.基础原理 Base64是一种用64个Ascii字符来表示任意二进制数据的方法.主要用于将不可打印的字符转换成可打印字符,或者简单的说是将二进制数据编码成Ascii字符.Base64也是网络 ...
- Springboot_Email注解爆红
应该是更新后的版本,不会自动导入pom依赖 <!--新版本需要validation启动器 --> <dependency> <groupId>org.springf ...
- 理解ASP.NET Core - [03] Dependency Injection
注:本文隶属于<理解ASP.NET Core>系列文章,请查看置顶博客或点击此处查看全文目录 依赖注入 什么是依赖注入 简单说,就是将对象的创建和销毁工作交给DI容器来进行,调用方只需要接 ...