SAPD:FSAF升级版,合理的损失值加权以及金字塔特征选择 | ECCV 2020
针对anchor-point检测算法的优化问题,论文提出了SAPD方法,对不同位置的anchor point使用不同的损失权重,并且对不同的特征金字塔层进行加权共同训练,去除了大部分人为制定的规则,更加遵循网络本身的权值进行训练
来源:晓飞的算法工程笔记 公众号
论文: Soft Anchor-Point Object Detection

- 论文地址:https://arxiv.org/abs/1911.12448
- 论文代码:https://github.com/xuannianz/SAPD not official
Introduction
Anchor-free检测方法分为anchor-point类别和key-point类别两种,相对于key-point类别,anchor-point类别有以下有点:1) 更简单的网络结构 2) 更快的训练和推理速度 3) 更好地利用特征金字塔 4) 更灵活的特征金字塔选择,但anchor-point类别的准确率一般比key-point类别要低,所以论文着力于研究阻碍anchor-point类别准确率的因素,提出了SAPD(Soft Anchor-Point Detecto),主要有以下两个亮点:
- Soft-weighted anchor points。anchor-point算法在训练时一般将满足几何关系的点设置为正样本点,其损失值权重均为1,这造成定位较不准确的点偶尔分类置信度更高。实际上,不同位置的点的回归难度是不一样的,越靠近目标边缘的点的损失值权重应该越低,让网络集中于优质anchor point的学习。
- Soft-selectedpyramid levels。anchor-point算法每轮训练会选择特征金字塔的其中一层特征进行训练,其它层均忽略,这在一定程度上造成了浪费。因为其他层虽然响应不如被选择的层强,但其特征分布应该与被选择层是类似的,所以可以赋予多层不同权重同时训练。
Detection Formulation with Anchor Points
论文首先介绍了大致的anchor point目标检测方法的网络结构以及训练方法。
Network architecture
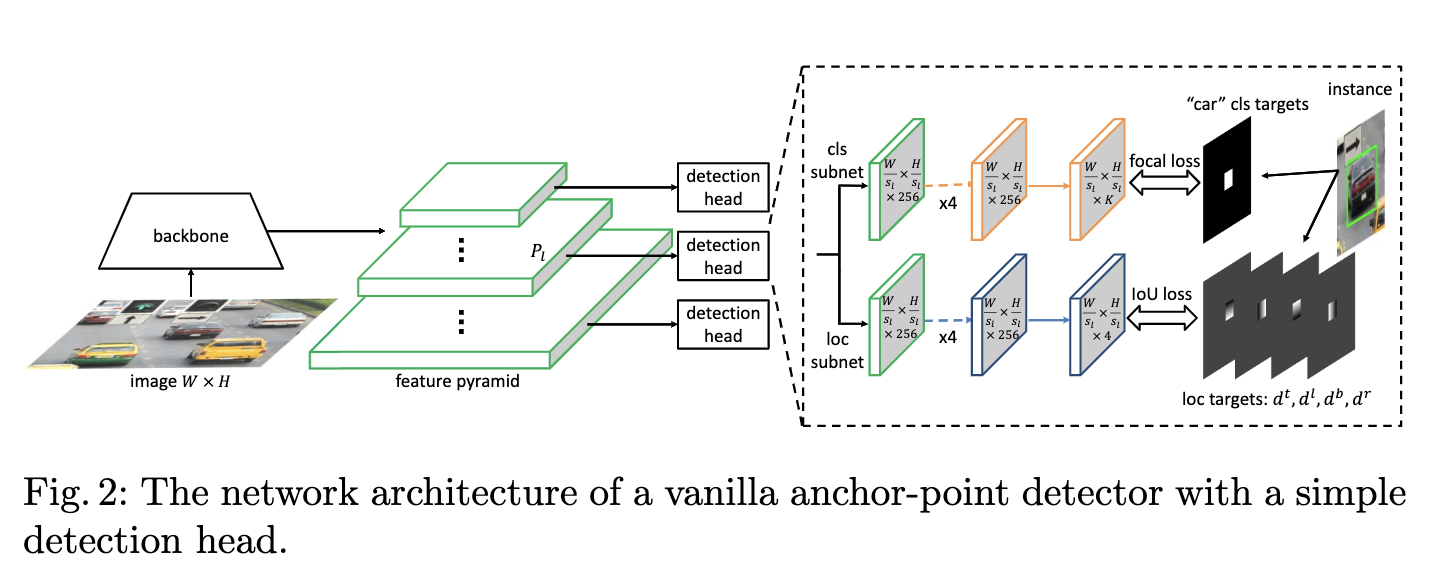
网络包含主干网络以及特征金字塔,特征金字塔每层包含一个detection head,特征金字塔层标记为\(P_l\),\(l\)为层数,层的特征图大小为输入\(W\times H\)的\(1/s_l\)倍,\(s_l=2^l\)为stride。一般,\(l\)的范围为3到7,detection head包含分类子网和回归子网,子网均以5个\(3\times 3\)卷积层开头,然后每个位置分别预测\(K\)个分类置信度以及4个偏移值,偏移值分别为当前位置到目标边界的距离。
Supervision targets
对于目标\(B=(c, x, y, w, h)\),中心区域为\(B_v=(c, x, y, \epsilon w, \epsilon h)\),\(\epsilon\)为缩放因子。当目标\(B\)被赋予金字塔层\(P_l\)且anchor point \(p_{lij}\)位于\(B_v\)内时,则认为\(p_{lij}\)是正样本点,分类目标为\(c\),回归目标为归一化的距离\(d=(d^l, d^t, d^r, d^b)\),分别为当前位置到目标四个边界的距离:
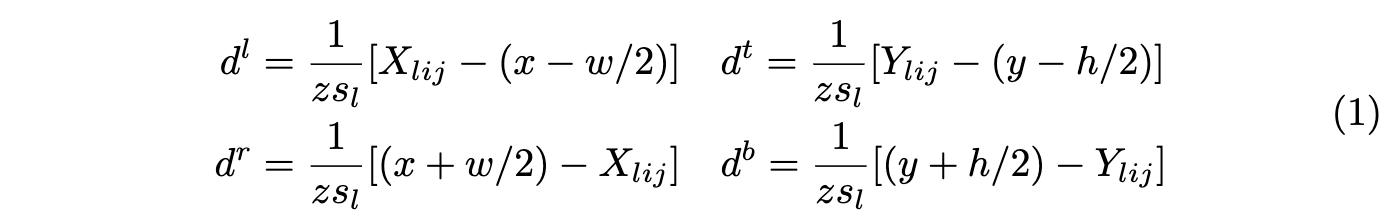
\(z\)为归一化因子。对于负样本点,分类目标为背景(\(c=0\)),定位目标为null,不需要学习。
Loss functions
网络输出每个点\(p_{lij}\)的\(K\)维分类输出\(\hat{c}_{lij}\)以及4维位置回归输出\(\hat{d}_{lij}\),分别使用focal loss和IoU loss进行学习:
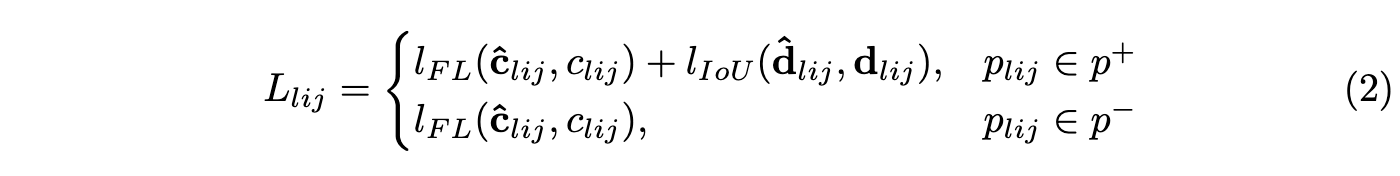
网络整体损失为正负样本点之和除以正样本点数:
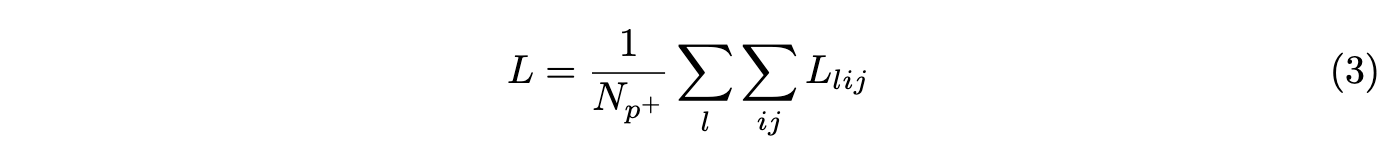
Soft Anchor-Point Detector
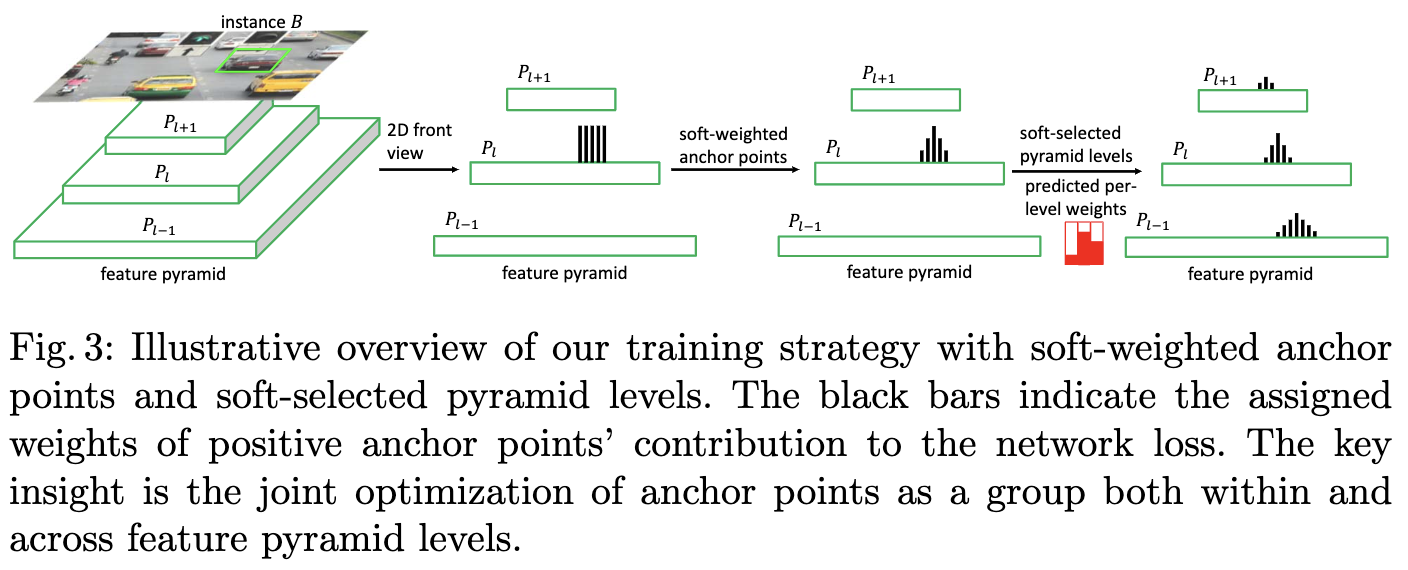
SAPD的核心如图3所示,分别为Soft-Weighted Anchor Points以及Soft-Selected Pyramid Levels,用于调整anchor point权重以及使用特征金字塔的多层进行训练。
Soft-Weighted Anchor Points
False attention

基于传统的训练策略,论文观察到部分anchor point输出的定位准确率较差,但是其分类置信度很高,如图4a所示,这会造成NMS过后没有保留定位最准确的预测结果。可能的原因在于,训练策略平等地对待中心区域\(B_v\)内的anchor point。实际上,离目标边界越近的点,越难回归准确的目标位置,所以应该根据位置对不同的anchor point进行损失值的加权,让网络集中于优质的anchor point的学习,而不是勉强网络将那些较难回归的点也学习好。
Our solution
为了解决上面提到的问题,论文提出soft-weighting的概念,为每个anchor point的损失值\(L_{lij}\)增加一个权重\(w_{lij}\),权重由点位置和目标的边界决定,负样本点不参与位置回归的计算,所以直接设为1,完整的权值计算为:
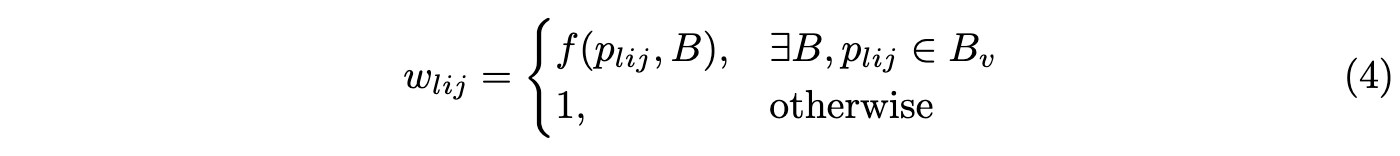
\(f\)为反映点\(p_{lij}\)与目标\(B\)边界远近的函数,论文设置\(f\)为centerness函数\(f(p_{lij}, B)=[\frac{min(d^l_{lij}, d^r_{lij})min(d^t_{lij}, d^b_{lij})}{max(d^l_{lij}, d^r_{lij})max(d^t_{lij}, d^b_{lij})}]^{\eta}\)
\(\eta\)为降低的幅度,具体的效果可以看图3,经过Soft-Weighted后,anchor point的权值变成了山峰状。
Soft-Selected Pyramid Levels
Feature selection

anchor-free方法在每轮一般都会选择特征金字塔的其中一层进行训练,选择不同的层的效果完全不同。而论文通过可视化发现,不同层的激活区域实际上是类似的,如图5所示,这意味着不同层的特征可以协作预测。基于上面的发现,论文认为选择合适的金字塔层有两条准则:
选择需基于特征值,而非人工制定的规则。
允许使用多层特征对每个目标进行训练,每层需对预测结果有显著的贡献。
Our solution
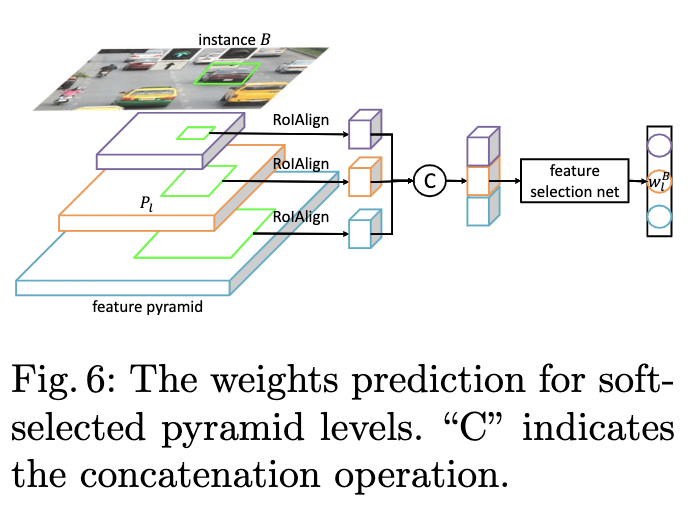
为了满足上面两条准则,论文提出使用特征选择网络来预测每层对于目标的权重,整体流程如图6所示,使用RoIAlign提取每层对应区域的特征,合并后输入到特征选择网络,然后输出权重向量。效果可看图3,金字塔每层的权值的山峰形状相似,但高度不同。需要注意,特征选择网络仅在训练阶段使用。
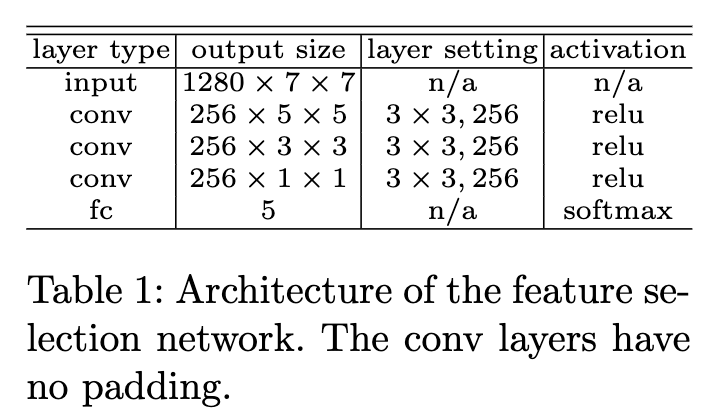
特征选择网络的结构十分简单,如表1,与检测器一起训练,GT为one-hot向量,数值根据FSAF的最小损失值方法指定,具体可以看看之前发的关于FSAF文章。至此,目标\(B\)通过权重\(w^B_l\)与金字塔的每层进行了关联,结合前面的soft-weighting,anchor point的权值为:
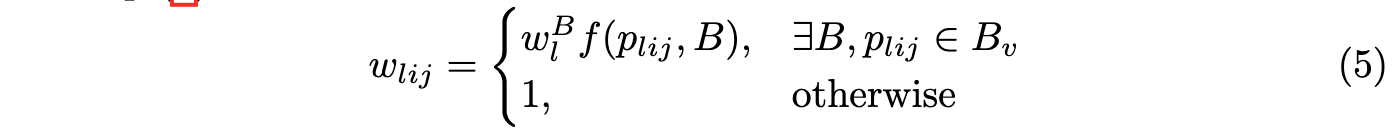
完整的模型的损失为加权的anchor point损失加上特征选择网络的损失:
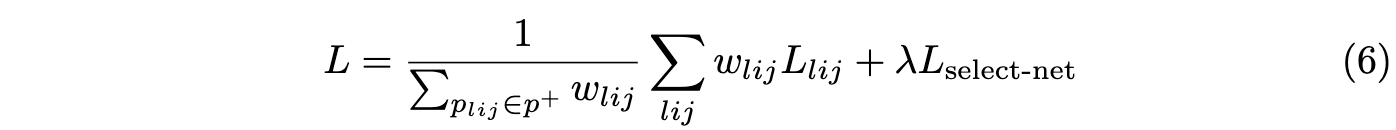
Experiment
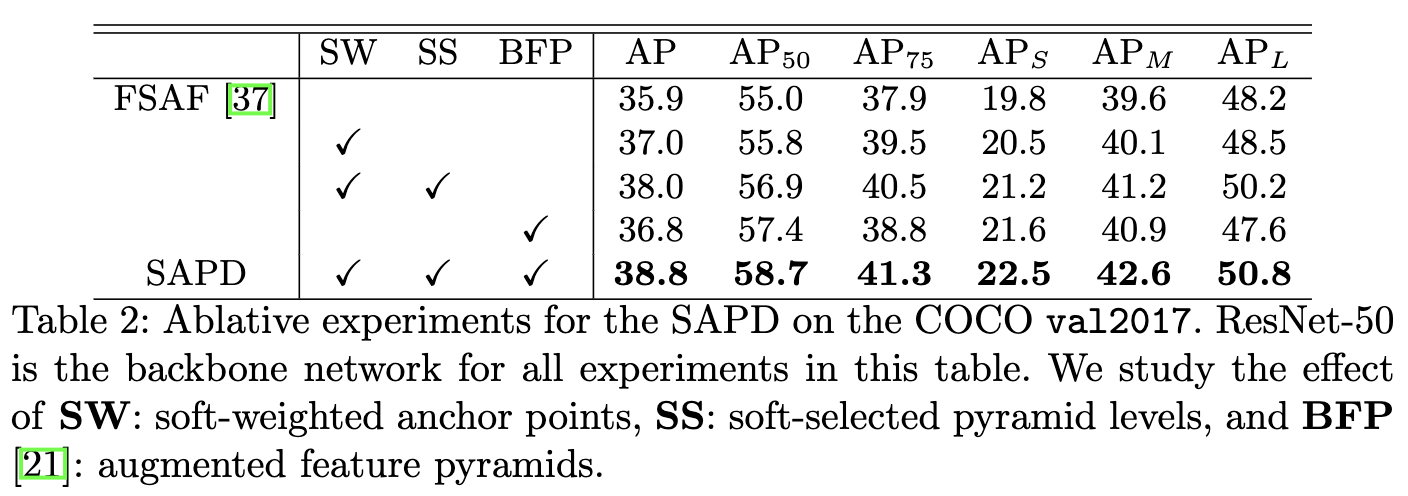
各模块的对比实验。
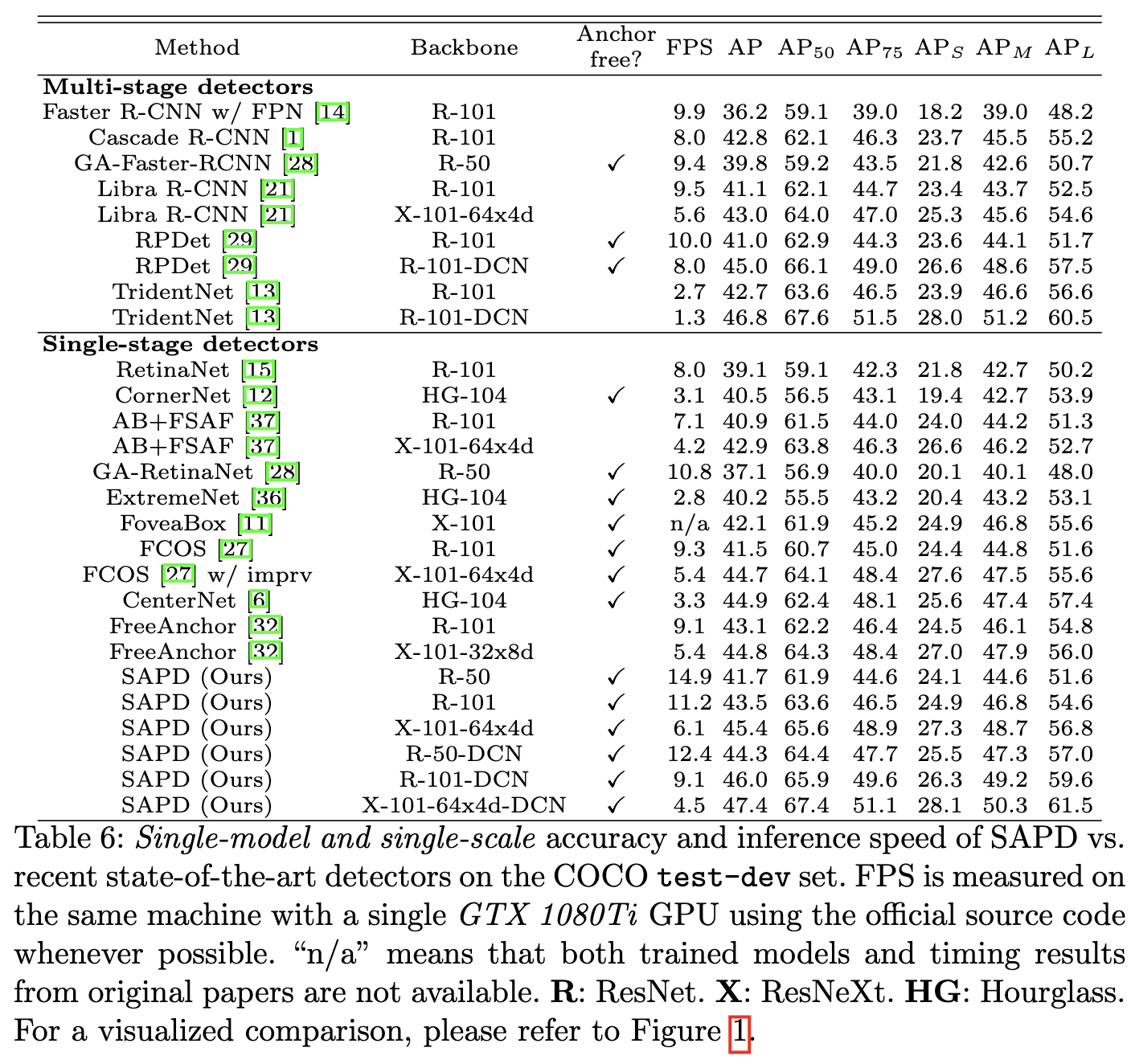
与SOTA算法进行对比。
Conclusion
针对anchor-point检测算法的优化问题,论文提出了SAPD方法,对不同位置的anchor point使用不同的损失权重,并且对不同的特征金字塔层进行加权共同训练,去除了大部分人为制定的规则,更加遵循网络本身的权值进行训练。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

SAPD:FSAF升级版,合理的损失值加权以及金字塔特征选择 | ECCV 2020的更多相关文章
- 深度学习原理与框架-Tensorflow基本操作-mnist数据集的逻辑回归 1.tf.matmul(点乘操作) 2.tf.equal(对应位置是否相等) 3.tf.cast(将布尔类型转换为数值类型) 4.tf.argmax(返回最大值的索引) 5.tf.nn.softmax(计算softmax概率值) 6.tf.train.GradientDescentOptimizer(损失值梯度下降器)
1. tf.matmul(X, w) # 进行点乘操作 参数说明:X,w都表示输入的数据, 2.tf.equal(x, y) # 比较两个数据对应位置的数是否相等,返回值为True,或者False 参 ...
- 深度学习中损失值(loss值)为nan(以tensorflow为例)
我做的是一个识别验证码的深度学习模型,识别的图片如下 验证码图片识别4个数字,数字间是有顺序的,设立标签时设计了四个onehot向量链接起来,成了一个长度为40的向量,然后模型的输入也是40维向量用s ...
- 局部加权回归、欠拟合、过拟合(Locally Weighted Linear Regression、Underfitting、Overfitting)
欠拟合.过拟合 如下图中三个拟合模型.第一个是一个线性模型,对训练数据拟合不够好,损失函数取值较大.如图中第二个模型,如果我们在线性模型上加一个新特征项,拟合结果就会好一些.图中第三个是一个包含5阶多 ...
- FSAF:嵌入anchor-free分支来指导acnhor-based算法训练 | CVPR2019
FSAF深入地分析FPN层在训练时的选择问题,以超简单的anchor-free分支形式嵌入原网络,几乎对速度没有影响,可更准确的选择最优的FPN层,带来不错的精度提升 来源:晓飞的算法工程笔记 公 ...
- 深度学习实践-强化学习-bird游戏 1.np.stack(表示进行拼接操作) 2.cv2.resize(进行图像的压缩操作) 3.cv2.cvtColor(进行图片颜色的转换) 4.cv2.threshold(进行图片的二值化操作) 5.random.sample(样本的随机抽取)
1. np.stack((x_t, x_t, x_t, x_t), axis=2) 将图片进行串接的操作,使得图片的维度为[80, 80, 4] 参数说明: (x_t, x_t, x_t, x_t) ...
- 深度学习实践-物体检测-faster-RCNN(原理和部分代码说明) 1.tf.image.resize_and_crop(根据比例取出特征层,进行维度变化) 2.tf.slice(数据切片) 3.x.argsort()(对数据进行排列,返回索引值) 4.np.empty(生成空矩阵) 5.np.meshgrid(生成二维数据) 6.np.where(符合条件的索引) 7.tf.gather取值
1. tf.image.resize_and_crop(net, bbox, 256, [14, 14], name) # 根据bbox的y1,x1,y2,x2获得net中的位置,将其转换为14*1 ...
- 机器学习入门03 - 降低损失 (Reducing Loss)
原文链接:https://developers.google.com/machine-learning/crash-course/reducing-loss/ 为了训练模型,需要一种可降低模型损失的好 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-cifar10图片分类(代码) 1.tf.nn.lrn(局部响应归一化操作) 2.random.sample(在列表中随机选值) 3.tf.one_hot(对标签进行one_hot编码)
1.tf.nn.lrn(pool_h1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75) # 局部响应归一化,使用相同位置的前后的filter进行响应归一化操作 参数 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-卷积神经网络mnist分类 1.tf.nn.conv2d(卷积操作) 2.tf.nn.max_pool(最大池化操作) 3.tf.nn.dropout(执行dropout操作) 4.tf.nn.softmax_cross_entropy_with_logits(交叉熵损失) 5.tf.truncated_normal(两个标准差内的正态分布)
1. tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') # 对数据进行卷积操作 参数说明:x表示输入数据,w表示卷积核, stride ...
随机推荐
- Git refusing to merge unrelated histories (拒绝合并不相关仓库)
感谢原文作者:lindexi_gd 原文链接:https://blog.csdn.net/lindexi_gd/article/details/52554159 本文讲的是把git在最新2.9.2,合 ...
- Java 数组存储机制
数组是一种引用类型. 数组用来存储类型相同的一组数据,一旦初始化完成,其所占的空间也确定下来了,即使清除某个元素,其所占用的空间仍然存在,即,数组的长度不能被改变,且数组只有在分配空间后才能使用. 数 ...
- list和tuple的用法区别
1.list中是可变的,tuple不可变 所以tuple没有insert, pop,append方法 2.定义只有一个元素的tuple的时候,必须加逗号,否则不会被认为是tuple,而被识别为括号 ...
- Python—经典练手题目汇总
Python-经典练手题目汇总 # 1.有1020个西瓜,第一天卖掉总数的一半后又多卖出两个,以后每天卖剩下的一半多两# 个,问几天以后能卖完? day=0 xg=1020 for i in rang ...
- MHA高可用配置及故障切换
MHA高可用配置及故障切换 目录 MHA高可用配置及故障切换 一.案例概述 二.案例前置知识点 1. MHA概述 2. MHA的组成 (1)MHA Manager(管理节点) (2)MHA Node( ...
- python——虚拟环境管理大合集
个人常用:pipenv 安装 pip3 install pipenv 创建虚拟环境 # 默认安装在~/.local/virtualenv下 mkdir project cd project pipen ...
- 泛型、Junit
一. 泛型 1.泛型的好处 **1)编译时,检查添加元素的类型,提高了安全2)减少了类西较换的次数,提高效率 不使用泛型Dog -> Object -> Dog //放入到ArrayLis ...
- Kubernetes 集群日志 和 EFK 架构日志方案
目录 第一部分:Kubernetes 日志 Kubernetes Logging 是如何工作的 Kubernetes Pod 日志存储位置 Kubelet Logs Kubernetes 容器日志格式 ...
- PL/SQL批量执行SQL脚本文件
1.选择File > New > Command Windows(命令窗口) 2.输入 @ 符号,之后敲击回车键.从本地选择执行的 SQL脚本 等待批量命令全部执行成功,关闭页面即可 新增 ...
- Solution -「CF 1586F」Defender of Childhood Dreams
\(\mathcal{Description}\) Link. 定义有向图 \(G=(V,E)\),\(|V|=n\),\(\lang u,v\rang \in E \Leftrightarr ...