(4)ElasticSearch在linux环境中搭建集群
1.概述
一个运行中的Elasticsearch实例称为一个节点(node),而集群是由一个或者多个拥有相同cluster.name配置的节点组成,它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
如一个节点被选举成为主节点时,它将负责管理集群范围内的所有变更,例如增删索引或者节点等。而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。任何节点都可以成为主节点。
用户可以将请求发送到集群中的任何节点,包括主节点。每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。Elasticsearch对这一切的管理都是透明的。
2. 为什么要实现Elasticsearch集群
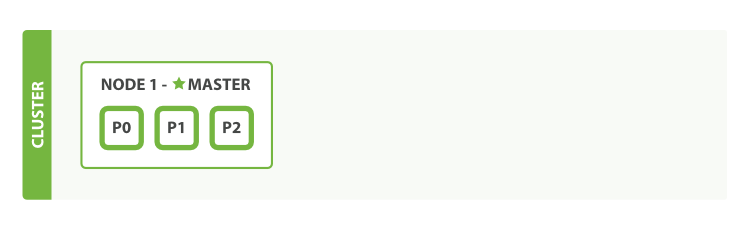
如果是单节点集群,一旦该节点出现故障,无法做到故障转移,那么Elasticsearch就会无法访问,这对系统来说是灾难性的,而部署多节点集群,能够水平扩容,故障转移,实现高可用,解决高并发。
2.1高可用
假设我们部署了三个节点集群(三个主分片P0、P1、P2,分别各对应两个副本分片R0、R1、R2):
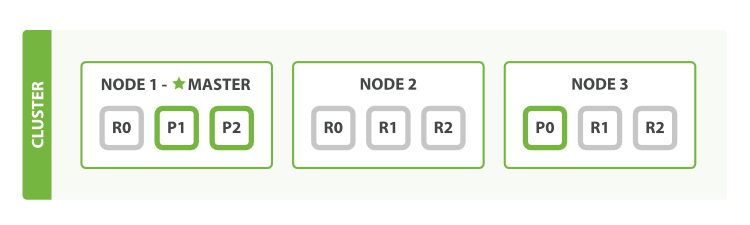
如果主节点Node1故障了,Elasticsearch内部机制会根据节点故障重新选举一个节点作为主节点,而主副分片也会重新调整: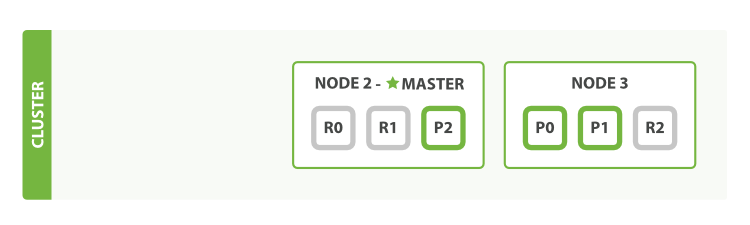
但因为副本分片是主副一比二缘故,此时集群健康状态会是yellow。但当故障节点恢复正常时候,集群健康状态会是green恢复正常。
2.2存储空间
一台服务器存储空间肯定是有限的,当数据量上来时候,这是灾难性的。如果部署多台服务器节点集群,那么就能解决存储空间的问题了。
3.集群搭建
3.1环境准备
|
System |
IP |
Node |
Leader |
|
CentOS-7 |
192.168.142.129 |
node-1 |
master |
|
192.168.142.130 |
node-2 |
replica |
分别往129、130服务器部署两个Elasticsearch节点,安装详情可以参考我第一篇文章。
3.2修改elasticsearch.yml配置
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-ebs
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
network.host: 192.168.142.129
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
discovery.seed_hosts: ["192.168.142.129", "192.168.142.130"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1", "node-2"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
这是node-1修改后的配置,node-2配置相差不大,区别如下:
node.name: node-2
network.host: 192.168.142.130
集群节点外部访问HTTP端口默认都是9200,内部TCP连接端口默认都是9300。如果是同一个服务器不同节点,那么就要配置不同的端口号了。具体配置说明详情可以查看官网。
3.3允许Elasticsearch端口访问
输入如下命令放开防火墙对Elasticsearch端口访问限制:
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --zone=public --add-port=9300/tcp –permanent
重新加载防火墙:
firewall-cmd –reload
3.4启动Elasticsearch集群
如何启动Elasticsearch或者启动过程会遇到什么样问题,不懂的可以查看我第一篇文章,里面基本都有介绍,这里就不一一描述了,因为集群搭建主要是配置文件:
●node1: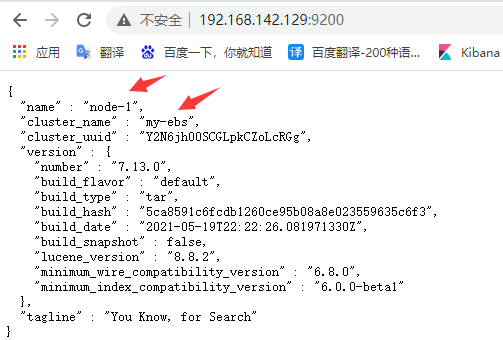
●node2: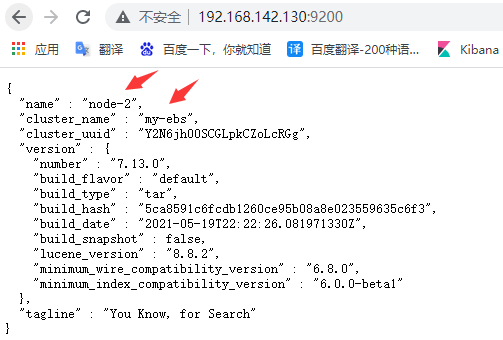
●查看集群节点状况:
http://192.168.142.129:9200/_cat/nodes?pretty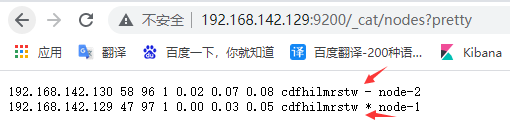
注:*符号表示主节点,-表示副节点。
●查看集群状态:
http://192.168.142.129:9200/_cluster/health
status字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green:所有的主分片和副本分片都正常运行。
yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red:有主分片没能正常运行。
参考文献:
Important Elasticsearch configuration
应对故障
(4)ElasticSearch在linux环境中搭建集群的更多相关文章
- (1)Zookeeper在linux环境中搭建集群
1.简介 ZooKeeper是Apache软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务.同步服务和命名注册.ZooKeeper的架构通过冗余服务实现高可用性.Zookeeper ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- Linux环境下ZooKeeper集群环境搭建关键步骤
ZooKeeper版本:zookeeper-3.4.9 ZooKeeper节点:3个节点 以下为Linux环境下ZooKeeper集群环境搭建关键步骤: 前提条件:已完成在Linux环境中安装JDK并 ...
- Linux环境下SolrCloud集群环境搭建关键步骤
Linux环境下SolrCloud集群环境搭建关键步骤. 前提条件:已经完成ZooKeeper集群环境搭建. 一.下载介质 官网下载地址:http://www.apache.org/dyn/close ...
- Linux环境下HDFS集群环境搭建关键步骤
Linux环境下HDFS集群环境搭建关键步骤记录. 介质版本:hadoop-2.7.3.tar.gz 节点数量:3节点. 一.下载安装介质 官网下载地址:http://hadoop.apache.or ...
- Linux+.NetCore+Nginx搭建集群
本篇和大家分享的是Linux+NetCore+Nginx搭建负载集群,对于netcore2.0发布后,我一直在看官网的文档并学习,关注有哪些新增的东西,我,一个从1.0到2.0的跟随者这里只总结一句话 ...
- (3)ElasticSearch在linux环境中安装与配置head插件
1.简介 ElasticSearch-Head跟Kibana一样也是一个针对ElasticSearch集群操作的API的可视化管理工具,它提供了集群管理.数据可视化.增删改查.查询语句等功能,最重要还 ...
- Linux环境下Redis集群实践
环境:centos 7 一.编译及安装redis源码 源码地址:redis版本发布列表 cd redis-3.2.8 sudo make && make install 二.创建节点 ...
- (2)ElasticSearch在linux环境中集成IK分词器
1.简介 ElasticSearch默认自带的分词器,是标准分词器,对英文分词比较友好,但是对中文,只能把汉字一个个拆分.而elasticsearch-analysis-ik分词器能针对中文词项颗粒度 ...
随机推荐
- GhostScript 沙箱绕过(命令执行)漏洞(CVE-2018-19475)
影响范围 Ghostscript 9.24之前版本 将POC作为图片上传,执行命令,抓包 POST /index.php HTTP/1.1 Host: target Accept-Encoding: ...
- Vue单点登录控件代码分享
这里提供一个Vue单点登录的demo给大家参考,希望对想了解的朋友有一些帮助. 具体的原理大家可以查看我的上篇文章 vue实现单点登录的N种方式 废话不多少直接上代码 这里分两套系统,一是登录系统的主 ...
- vue cli中的env详解
前言 相信使用过 vueCli 开发项目的小伙伴有点郁闷,正常开发时会有三个接口环境(开发,测试,正式),但是 vueCli 只提供了两种 development,production(不包含 tes ...
- 【动态规划】树形DP完全详解!
蒟蒻大佬时隔三个月更新了!!拍手拍手 而且是更新了几篇关于DP的文章(RioTian狂喜) 现在赶紧学习和复习一下树形DP.... 树形DP基础:Here,CF上部分树形DP练习题:Here \[QA ...
- SQL注入:基本查询原理
SQL注入概述 sql注入不需要精通sql的各种命令,只需要了解几个命令并会使用即可. SQL注入:一种针对于数据库的攻击 现在的web网站都需要数据库的支持. SQL部分重要内容: 库:databa ...
- 003 PCI Express体系结构(三)
一.PCI总线的存储器读写总线事务 总线的基本任务是实现数据传送,将一组数据从一个设备传送到另一个设备,当然总线也可以将一个设备的数据广播到多个设备.在处理器系统中,这些数据传送都要依赖一定的规则,P ...
- 轻量级状态管理库Pinia试吃
最近连续看了几个GitHub上的开源项目,里面都用到了 Pinia 这个状态管理库,于是研究了一下,发现确实是个好东西!那么,Pinia 的特点: 轻量化 -- Pinia 体积约1KB,十分轻巧 ...
- NOIP 模拟 $33\; \rm Hunter$
题解 \(by\;zj\varphi\) 结论题. 对于 \(1\) 猎人,他死的期望就是有多少个死在它前面. 那么对于一个猎人,它死在 \(1\) 前的概率就是 \(\frac{w_i}{w_i+w ...
- springboot 和spring cloud 博客分享
spring boot 知识点总结 天狼星 https://www.cnblogs.com/wjqhuaxia/p/9820902.html spring cloud 知识点总结 姿势帝 https: ...
- Redis5.0 配置文件中文参考
Redis 5.0 配置文件#是否在后台执行,yes:后台运行:no:不是后台运行daemonize yes#是否开启保护模式,默认开启.要是配置里没有指定bind和密码.开启该参数后,redis只会 ...