RandomForest in Spark MLLib
决策树类模型
ml中的classification和regression主要基于以下几类:
- classification:决策树及其相关的集成算法,Logistics回归,多层感知模型;
- regression:决策树及其相关集成算法,线性回归。
主要的模型有两类:线性模型(GLM)和决策树:
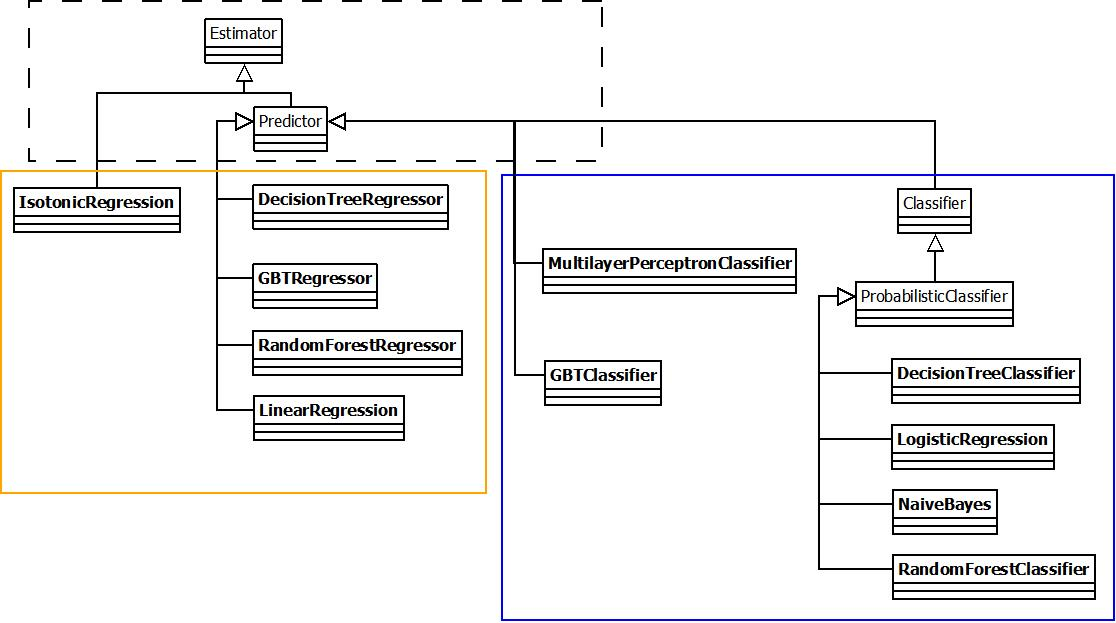
其中决策树的算法都调用了org.apache.spark.ml.tree.impl.RandomForest,没有和mllib中的代码复用,但是代码逻辑几乎一样。
MLlib的决策树训练算法和传统的算法不同点是,传统算法大多使用递归算法(每一个节点的划分需要遍历一次全量数据),MLLib采用迭代算法(层序遍历).最大的优势是可以在遍历一次数据的过程中同时计算多个Node的split,减少了数据遍历、通信的开销。
RandomForest算法可以用于CLassification或Regression,算法中也会涉及到很多可配置的策略,例如impurity计算可以用Gini系数/熵/方差等,这些都被抽象为“策略”——策略模式。
策略对象构造
org.apache.spark.mllib.tree.configuration
@Since("1.0.0")
@Experimental
class Strategy(@Since("1.0.0") @BeanProperty var algo: Algo.Algo,
@Since("1.0.0") @BeanProperty var impurity: Impurity,
@Since("1.0.0") @BeanProperty var maxDepth: Int,
@Since("1.2.0") @BeanProperty var numClasses: Int = 2,
@Since("1.0.0") @BeanProperty var maxBins: Int = 32,
@Since("1.0.0") @BeanProperty var quantileCalculationStrategy: QuantileStrategy.QuantileStrategy = Sort,
@Since("1.0.0") @BeanProperty var categoricalFeaturesInfo: Map[Int, Int] = Map[Int, Int](),
@Since("1.2.0") @BeanProperty var minInstancesPerNode: Int = 1,
@Since("1.2.0") @BeanProperty var minInfoGain: Double = 0.0,
@Since("1.0.0") @BeanProperty var maxMemoryInMB: Int = 256,
@Since("1.2.0") @BeanProperty var subsamplingRate: Double = 1,
@Since("1.2.0") @BeanProperty var useNodeIdCache: Boolean = false,
@Since("1.2.0") @BeanProperty var checkpointInterval: Int = 10)
extends Serializable
:: Experimental :: Stores all the configuration options for tree construction
Parameters:
algo- 分类或回归:Algo.Classification/Regressionimpurity- Criterion used for information gain calculation.- Supported for Classification:
org.apache.spark.mllib.tree.impurity.Gini,org.apache.spark.mllib.tree.impurity.Entropy. - Supported for Regression:
org.apache.spark.mllib.tree.impurity.Variance. maxDepth- Maximum depth of the tree. E.g., depth 0 means 1 leaf node; depth 1 means 1 internal node + 2 leaf nodes.numClasses- Number of classes for classification. (Ignored for regression.) Default value is 2 (binary classification).maxBins- Maximum number of bins used for discretizing continuous features and for choosing how to split on features at each node. More bins give higher granularity.quantileCalculationStrategy- Algorithm for calculating quantiles. Supported:org.apache.spark.mllib.tree.configuration.QuantileStrategy.Sort/MinMax/ApproxHistcategoricalFeaturesInfo- A map storing information about the categorical variables and the number of discrete values they take. For example, an entry (n -> k) implies the feature n is categorical with k categories 0, 1, 2, ... , k-1. It's important to note that features are zero-indexed.// 每个特征的维度minInstancesPerNode- Minimum number of instances each child must have after split. Default value is 1. If a split cause left or right child to have less thanminInstancesPerNode, this split will not be considered as a valid split.minInfoGain- Minimum information gain a split must get. Default value is 0.0. If a split has less information gain than minInfoGain, this split will not be considered as a valid split.maxMemoryInMB- Maximum memory in MB allocated to histogram aggregation. Default value is 256 MB.subsamplingRate- Fraction of the training data used for learning decision tree.useNodeIdCache- If this is true, instead of passing trees to executors, the algorithm will maintain a separate RDD of node Id cache for each row.checkpointInterval- How often to checkpoint when the node Id cache gets updated. E.g. 10 means that the cache will get checkpointed every 10 updates. If the checkpoint directory is not set in org.apache.spark.SparkContext, this setting is ignored.
随机森林RandomForest.run
org.apache.spark.ml.tree.impl.RandomForest
def run(
input: RDD[LabeledPoint],
strategy: OldStrategy,
numTrees: Int,
featureSubsetStrategy: String,
seed: Long,
parentUID: Option[String] = None): Array[DecisionTreeModel]
extends Serializable with Logging
Random Forest learning algorithm for classification and regression. It supports both continuous and categorical features.
featureSubsetStrategy are based on the following references:
- log2: tested in Breiman (2001)
- sqrt: recommended by Breiman manual for random forests
- The defaults of sqrt (classification) and onethird (regression) match the R randomForest package.
see Breiman (2001)
see Breiman manual for random forests
strategy - The configuration parameters for the random forest algorithm which specify the type of algorithm (classification, regression, etc.), feature type (continuous, categorical), depth of the tree, quantile calculation strategy, etc.
numTrees - If 1, then no bootstrapping is used(常常用于训练决策树). If > 1, then bootstrapping is done.
featureSubsetStrategy - Number of features to consider for splits at each node. Supported: "auto", "all", "sqrt", "log2(特征数以2为底的自然对数)", "onethird".
If "auto" is set, this parameter is set based on numTrees:
- if numTrees == 1, set to "all";
- if numTrees > 1 (forest) set
- to "sqrt" for classification and (特征数开根号)
- to "onethird" for regression. (取特征数的1/3)
seed- Random seed for bootstrapping and choosing feature subsets.
以上参数的逻辑判断都在DecisionTreeMetadata.buildMetadata函数中实现。
随机森林练算法流程
The algorithm partitions data by instances (rows).
On each iteration, the algorithm splits a set of nodes. In order to choose the best split for a given node, sufficient statistics are collected from the distributed data.
For each node, the statistics are collected to some worker node, and that worker selects the best split.
算法每轮迭代将生成一组nodes(主要是计算选择决策阈值split信息)。为了给node选择最好的split,分布式地对数据进行统计,然后将统计结果汇总起来再选择最好的split。每次迭代都先定一下本轮需要创建的node是哪些,采用了层序遍历,每次目标创建一层node,即需要优化计算一层node的split。
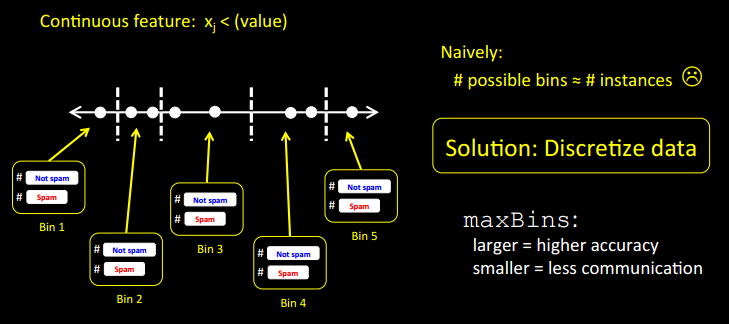
This setup requires discretization of continuous features. This binning is done in the findSplitsBins() method during initialization, after which each continuous feature becomes an ordered discretized feature with at most maxBins possible values.
连续特征值被离散化,每个特征被离散成最多
maxBin个有序离散特征(Strategy中配置该参数),这个过程在初始化过程中完成。
The main loop in the algorithm operates on a queue of nodes (nodeQueue). These nodes lie at the periphery of the tree being trained. If multiple trees are being trained at once, then this queue contains nodes from all of them. Each iteration works roughly as follows:
主循环中对nodeQueue中node处理。这些node都是中间节点,如果RT包含多个tree,这个queue中包含了各个tree的node。
算法采用的是层序遍历来训练tree中的Node。所有nodeQueue中的节点被出的时候它的父节点一定已经被训练出来了。
- On the master node:
- Some number of nodes are pulled off of the queue (based on the amount of memory required for their sufficient statistics).
- For random forests, if
featureSubsetStrategyis not "all," then a subset of candidate features are chosen for each node. See methodselectNodesToSplit().
driver程序中,根据策略计算每个Node需要的内存并由此调整一次迭代会从nodeQueue中pop出来计算的node。
- On worker nodes, via method
findBestSplits(): - The worker makes one pass over its subset of instances.
- For each (tree, node, feature, split) tuple, the worker collects statistics about splitting. Note that the set of (tree, node) pairs is limited to the nodes selected from the queue for this iteration. The set of features considered can also be limited based on
featureSubsetStrategy. - For each node, the statistics for that node are aggregated to a particular worker via
reduceByKey(). The designated worker chooses the best (feature, split) pair, or chooses to stop splitting if the stopping criteria are met.
分布式节点上为每一个tree的node统计每个特征维度、每个bin对应的分类label的权重,该权重将用于计算impurity。
reduceByKey汇总每个node->feature->bin在各个label上的总的权重,然后计算impurity。
- On the master node:
- The master collects all decisions about splitting nodes and updates the model.
- The updated model is passed to the workers on the next iteration. This process continues until the node queue is empty.
回到driver节点上选出各个node的最优的划分split。完成后将node的left和right node添加到nodeQueue中用作下一轮迭代。
Most of the methods in this implementation support the statistics aggregation, which is the heaviest part of the computation. In general, this implementation is bound by either the cost of statistics computation on workers or by communicating the sufficient statistics.
Node
node自身的信息包括id,split(given a new data, split will determine how which child should the data be directed to for further decisions.), stats(记录当前node在训练过程中的纯度)
private[tree] class LearningNode(
var id: Int,
var leftChild: Option[LearningNode],
var rightChild: Option[LearningNode],
var split: Option[Split],
var isLeaf: Boolean,
var stats: ImpurityStats)
Split
split是一个接口,具体在连续特征和离散特征中有具体的实现。例如连续特征的Split会包含一个阈值。
sealed trait Split extends Serializable {
/** Index of feature which this split tests */
def featureIndex: Int
/**
* Return true (split to left) or false (split to right).
* @param features Vector of features (original values, not binned).
*/
private[ml] def shouldGoLeft(features: Vector): Boolean
/**
* Return true (split to left) or false (split to right).
* @param binnedFeature Binned feature value.
* @param splits All splits for the given feature.
*/
private[tree] def shouldGoLeft(binnedFeature: Int, splits: Array[Split]): Boolean
/** Convert to old Split format */
private[tree] def toOld: OldSplit
}
RandomForest.findSplits
protected[tree] def findSplits(
input: RDD[LabeledPoint],
metadata: DecisionTreeMetadata): Array[Array[Split]]
对每个特征维度,构造对应离散特征值。
对全量数据采样,对连续的特征值做离散化,过程中考虑特征值的分布。对无序离散分类特征,将各个特征值进行排列组合,每个组合对应一个bin,有可能组合数会大于设置的max_bins。对有序的离散分类特征,每个特征值对应一个bin。
注解:
Returns splits and bins for decision tree calculation.
Continuous and categorical features are handled differently.
- Continuous features:
For each feature, there are numBins - 1 possible splits representing the possible binary decisions at each node in the tree.
This finds locations (feature values) for splits using a subsample of the data.
对每个连续的特征维度进行离散化,需要选择合适的split划分每个bin的范围。首先对全量数据采样得到一个特征向量数组,在此基础上对每个连续维度进行区间划分。主要函数位于
findSplitsForContinuousFeature。
对每个特征维度,统计该维度下样本中特征值的直方图分布,再根据分布进行划分区间,最终保证每个区间对应的特征数量相当。可以发现区间的长度和该区间特征分布频数成反比。
例如某个特征分布为正态分布,位于分布中心的区域的区间长度更短(如下图)。
算法可以简化实现:按照特征值排序后等间距取值作为split,但是如果特征值重复的情况很多,这个方法无法处理。
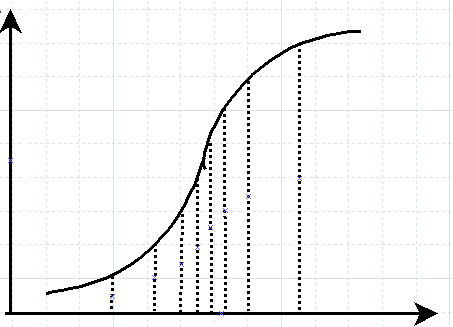
正态分布分布函数,按照概率分布选择区间时,中间部分特征值对应的区间长度更短。
- Categorical features:
For each feature, there is 1 bin per split.
Splits and bins are handled in 2 ways:
(a) "unordered features"
For multiclass classification with a low-arity feature (i.e., ifisMulticlass && isSpaceSufficientForAllCategoricalSplits), the feature is split based on subsets of categories.
此时需要考虑2^(feature.arity - 1) - 1个组合各自形成的bin,所以需要满足2^(feature.arity - 1) - 1<=max_bins,arity<=log(max_bins + 1)+1,例如max_bin=32,则arity<=6.如果实际的特征较多,unordered的分类将需要非常多的bins。
(b) "ordered features"
For regression and binary classification, and for multiclass classification with a high-arity feature, there is one bin per category.
TreePoint.convertToTreeRDD
class TreePoint(val label: Double, val binnedFeatures: Array[Int])
将每个原始数据转为TreePoint,原始每条数据的每个特征值对照bins转为原始特征值对应bin中的index。

BaggedPoint.convertToBaggedRDD
随机森林属于bagging算法,这里将每条数据先map准备好bagging算法所需要的数据。有放回地采样:根据subsamplingRate(采样率,建立Poisson分布的随机数生成器)和numSubsamples(新的training data set个数,也就是森林中的决策树个数)产生BaggedPoint。
convertToBaggedRDDSamplingWithReplacement(
input, subsamplingRate, numSubsamples, seed)
==>
private def convertToBaggedRDDSamplingWithReplacement[Datum] (
input: RDD[Datum],
subsample: Double, // 采样率
numSubsamples: Int, // 生成的新的training set的个数
seed: Long): RDD[BaggedPoint[Datum]] = {
input.mapPartitionsWithIndex {
(partitionIndex, instances)=>
// poisson分布,均值为subsample
val poisson = new PoissonDistribution(subsample)
poisson.reseedRandomGenerator(seed + partitionIndex + 1)
instances.map { instance =>
val subsampleWeights = new Array[Double](numSubsamples)
var subsampleIndex = 0
// 为每个training set都对应地生成一个权重值,形成权重数组
while (subsampleIndex < numSubsamples) {
subsampleWeights(subsampleIndex) = poisson.sample()
subsampleIndex += 1
}
// 返回(datum, [w1, w2, ...])
new BaggedPoint(instance, subsampleWeights)
}
}
}
RandomForest.selectNodesToSplit & DecisionTree.findBestSplits
The main idea here is to perform group-wise training of the decision tree nodes thus reducing the passes over the data from (# nodes) to (# nodes / maxNumberOfNodesPerGroup).
Each data sample is handled by a particular node(tree node) (or it reaches a leaf and is not used in lower levels).
val nodeQueue = new mutable.Queue[(Int, Node)]() // FIFO队列,每个元素是二元组(treeIndex, node),初始化为(i, topNodes(i));
val topNodes: Array[Node] // 每个tree有一个topNode
循环处理直至队列为空:
while (nodeQueue.nonEmpty) {
// Collect some nodes to split, and choose features for each node (if subsampling).
// Each group of nodes may come from one or multiple trees, and at multiple levels.
//从queue中拉出tree nodes,搜集一组将被split的tree nodes。
// 跟踪内存使用,自适应地调整tree nodes数量。
val (nodesForGroup, treeToNodeToIndexInfo) =
RandomForest.selectNodesToSplit(nodeQueue, maxMemoryUsage, metadata, rng)
// Choose node splits, and enqueue new nodes as needed.
DecisionTree.findBestSplits(baggedInput, metadata, topNodes, nodesForGroup,
treeToNodeToIndexInfo, splits, bins, nodeQueue, timer, nodeIdCache = nodeIdCache)
}
RandomForest.selectNodesToSplit
//从queue中拉出tree nodes,搜集一组将被split的tree nodes。
// 跟踪内存使用,自适应地调整tree nodes数量。
/**
* @param nodeQueue Queue of nodes to split.
* @param maxMemoryUsage Bound on size of aggregate statistics.
* @return (nodesForGroup, treeToNodeToIndexInfo).
* nodesForGroup holds the nodes to split:
* treeIndex:Int --> nodes in tree:Array[Node].
*
* treeToNodeToIndexInfo holds indices selected features for each node:
* treeIndex:Int --> (global) node index
* --> (node index in group, feature indices).
* The (global) node index is the index in the tree; the node index in group is the
* index in [0, numNodesInGroup) of the node in this group.
* The feature indices are None if not subsampling features.
*/
private[tree] def selectNodesToSplit(
nodeQueue: mutable.Queue[(Int, Node)], // (treeIndex, Node)
maxMemoryUsage: Long,
metadata: DecisionTreeMetadata,
rng: scala.util.Random):
(Map[Int, Array[Node]], // treeIndex -> Nodes to split!!!!!!!!
Map[Int, Map[Int, NodeIndexInfo]])
group的概念是什么??
决策树采用“层序遍历”决策树,训练的时候是level-by-level地计算每层上的所有node的split。在Random Forest训练时,每个level上会有多个tree的node。
返回 (nodesForGroup, treeToNodeToIndexInfo).
- nodesForGroup holds the nodes to split,基于这些节点做split:
treeIndex:Int --> nodes in tree:Array[Node]. - tree has nodes, each node belongs to one of the set of groups.
特征工程(连续数据离散化)
Find the splits and the corresponding bins (interval between the splits) using a sample of the input data.
val (splits, bins) = DecisionTree.findSplitsBins(retaggedInput, metadata)
metadata.numBins在findSplitsBins函数中被赋值。
注解:
Returns splits and bins for decision tree calculation.
Continuous and categorical features are handled differently.
- Continuous features:
For each feature, there arenumBins - 1possible splits representing the possible binary decisions at each node in the tree.
This finds locations (feature values) for splits using a subsample of the data.
对每个连续的特征维度进行离散化,需要选择合适的split划分每个bin的范围。首先对全量数据采样得到一个特征向量数组,在此基础上对每个连续维度进行区间划分。主要函数位于
findSplitsForContinuousFeature。
对每个特征维度,统计该维度下样本中特征值的直方图分布,再根据分布进行划分区间,最终保证每个区间对应的特征数量相当。可以发现区间的长度和该区间特征分布频数成反比。
例如某个特征分布为正态分布,位于分布中心的区域的区间长度更短。
算法可以简化实现:按照特征值排序后等间距取值作为split,但是如果特征值重复的情况很多,这个方法无法处理。
- Categorical features:
For each feature, there is 1 bin per split.
Splits and bins are handled in 2 ways:
(a) "unordered features"
For multiclass classification with a low-arity feature (i.e., ifisMulticlass && isSpaceSufficientForAllCategoricalSplits), the feature is split based on subsets of categories.
此时需要考虑2^(feature.arity - 1) - 1个组合各自形成的bin,所以需要满足2^(feature.arity - 1) - 1<=max_bins,arity<=log(max_bins + 1)+1,例如max_bin=32,则arity<=6.如果实际的特征较多,unordered的分类将需要非常多的bins。
(b) "ordered features"
For regression and binary classification, and for multiclass classification with a high-arity feature, there is one bin per category.
//@param input Training data: RDD of [[org.apache.spark.mllib.regression.LabeledPoint]]
//@param metadata Learning and dataset metadata
//@return A tuple of (splits, bins).
/** Splits is an Array of [[org.apache.spark.mllib.tree.model.Split]]
of size (numFeatures, numSplits).
Bins is an Array of [[org.apache.spark.mllib.tree.model.Bin]]
of size (numFeatures, numBins).
**/
protected[tree] def findSplitsBins(
input: RDD[LabeledPoint],
metadata: DecisionTreeMetadata): (Array[Array[Split]], Array[Array[Bin]])
RandomForest in Spark MLLib的更多相关文章
- Spark MLlib - Decision Tree源码分析
http://spark.apache.org/docs/latest/mllib-decision-tree.html 以决策树作为开始,因为简单,而且也比较容易用到,当前的boosting或ran ...
- 使用Spark MLlib进行情感分析
使用Spark MLlib进行情感分析 使用Spark MLlib进行情感分析 一.实验说明 在当今这个互联网时代,人们对于各种事情的舆论观点都散布在各种社交网络平台或新闻提要 ...
- spark MLlib Classification and regression 学习
二分类:SVMs,logistic regression,decision trees,random forests,gradient-boosted trees,naive Bayes 多分类: ...
- Spark MLlib 机器学习
本章导读 机器学习(machine learning, ML)是一门涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多领域的交叉学科.ML专注于研究计算机模拟或实现人类的学习行为,以获取新知识.新 ...
- Spark mllib 随机森林算法的简单应用(附代码)
此前用自己实现的随机森林算法,应用在titanic生还者预测的数据集上.事实上,有很多开源的算法包供我们使用.无论是本地的机器学习算法包sklearn 还是分布式的spark mllib,都是非常不错 ...
- Spark MLlib - LFW
val path = "/usr/data/lfw-a/*" val rdd = sc.wholeTextFiles(path) val first = rdd.first pri ...
- 《Spark MLlib机器学习实践》内容简介、目录
http://product.dangdang.com/23829918.html Spark作为新兴的.应用范围最为广泛的大数据处理开源框架引起了广泛的关注,它吸引了大量程序设计和开发人员进行相 ...
- Spark MLlib 之 Basic Statistics
Spark MLlib提供了一些基本的统计学的算法,下面主要说明一下: 1.Summary statistics 对于RDD[Vector]类型,Spark MLlib提供了colStats的统计方法 ...
- Spark MLlib Data Type
MLlib 支持存放在单机上的本地向量和矩阵,也支持通过多个RDD实现的分布式矩阵.因此MLlib的数据类型主要分为两大类:一个是本地单机向量:另一个是分布式矩阵.下面分别介绍一下这两大类都有哪些类型 ...
随机推荐
- myeclipse 10激活,本人已测试过可行
激活步骤: 下载myeclipse 10硬解程序包: ed2k://|file|%5Bmyeclipse.10.0.%E6%9B%B4%E6%96%B0%E5%8F%91%E5%B8%83%28%E7 ...
- P3157 [CQOI2011]动态逆序对
P3157 [CQOI2011]动态逆序对 https://www.luogu.org/problemnew/show/P3157 题目描述 对于序列A,它的逆序对数定义为满足i<j,且Ai&g ...
- WPF之DataGrid控件根据某列的值设置行的前景色(色
一种方法是 使用 datagrid的LoadingRow事件: private void DataGrid_LoadingRow(object sender, DataGridRowEventArgs ...
- linux下常用文件操作命令
1.find命令 按内容查找文件 find /home/vpopmail/domains/best-21ixi.jp/bounce/Maildir/new/ -name "*" | ...
- FSCapture截图软件注册码
企业版序列号: name:bluman serial/序列号/注册码:VPISCJULXUFGDDXYAUYF
- Laravel 中使用原生的 PHPExcel
1.安装 composer require maatwebsite/excel 之后,程序中就可以使用 PHPExcel 了 2.控制器中 public function export(Request ...
- fms +fme 视频直播
1.安装fms 按默认安装即可 2.安装fme 安装完成后启动fme FMS URL是发布到fms的地址默认就可以, 然后点击 Connect 连接成功后左下角会出现connected的提示, 然后点 ...
- 2018.10.14 NOIP训练 圣诞树(简单dp)
传送门 sbDP题. 曾经一直TLE不知道为什么. 这次发现输入有坑233. 代码
- 2018.07.20 洛谷P4178 Tree(点分治)
传送门 又一道点分治. 直接维护子树内到根的所有路径长度,然后排序+双指针统计答案. 代码如下: #include<bits/stdc++.h> #define N 40005 using ...
- 2018.07.06 BZOJ1208: HNOI2004宠物收养所(非旋treap)
1208: [HNOI2004]宠物收养所 Time Limit: 10 Sec Memory Limit: 162 MB Description 最近,阿Q开了一间宠物收养所.收养所提供两种服务:收 ...