CPU 分支预测
去年在安宁庄的时候, 有个同事阐述了一个观点:php中的if else 在执行时考虑到效率的原因,不会按我们的代码的顺序一条一条去试,而是随机找出一个分支,执行,如果不对,再随机找到一个分支
当时由于种种原因,也没过多去想这个问题,最近查了下资料,发现里面的学问还挺大的
php解释器是由c编写的,是个经编译生成的二进制文件, 我们编写的PHP代码相当于这个C程序的参数,只不过这个参数是个一个的文件, 这个C程序要解析这个php文件,产生相应的opcode,再去执行opcode对应的函数,每一部操作都是由C函数来实现
查询opcode含义的利器: http://www.laruence.com/2008/11/20/640.html#ZEND_JMP_.28Opcode_42.29
<?php
if($a == 1){
echo "a is 1";
}else if($a == 2){
echo "a is 2";
}else{
echo "a is x";
}
对于上面的php代码来说,最终执行的opcode是
-------------------------------------------------------------------------------------
2 0 E > IS_EQUAL ~0 !0, 1
1 > JMPZ ~0, ->4
3 2 > ECHO 'a+is+1'
4 3 > JMP ->9
4 > IS_EQUAL ~1 !0, 2
5 > JMPZ ~1, ->8
5 6 > ECHO 'a+is+2'
6 7 > JMP ->9
7 8 > ECHO 'a+is+x'
9 9 > > RETURN 1
可以看到在执行php时, 是一条一条去执行的
1.先判断 $a 是否 等于 1
2.如果不等于1,为false, 就JMPZ 到第4条命令,去比较 $a 是否 等于2
如果等于1, echo "a is 1"; 然后 无条件跳转 JMP 第9行 return 了
3.如果 $a 不等于2 ,即为false, 就JMPZ 到第8条命令, echo "a is x"
如果 $a 等于2,直接echo "a is 2", 然后执行 JMP 第9行 return 了
所以,php编写的程序,对C函数来说,还是要一步的一步去执行的,关于具体php的分支实现,请点击这里
如果这个文件被执行100次,有90次 $a=3, 那么解释器每次都要判断 $a 是否等于1和 $a 是否等于2, 尽管第三个分支是满足条件的,如果是C编写的程序, CPU会针对某种策略挑选一个分支来执行, 对应上面的分支来说,CPU会直接取出第三个分支的指令,然后执行。
从486开始,CPU开始具备流水线这个特性,指令流水线由5,6个不同功能的工作单元组成,将一个x86指令也拆分成5,6个步骤,分别送往不同的工作单元,来达到同时执行多个指令的目的,现在的CPU支持30级的流水线,也就意味着流水线上有30个工作单元,对应的X86指令也拆分成30个步骤。
注:CPU执行的是二进制数据,代码经过汇编编译后,生成一条条二进制指令
例如 int a=1; 对应的汇编是mov $1, %eax; 对应的机器码可能是00011100011
在执行文件时,根据局部性原理,想关的指令都要加载到CPU缓存中,
一般一条指令的完成 分四个步骤:
1.取指令
2.翻译指令 (看是赋值,还是计算,从内存什么地方取数据)
3.执行指令
4.写指令结果 (要么写回内存,要么写到寄存器)
取指令 翻译指令 执行指令 写指令结果
命令1 命令1
命令2
取指令单元取出指令1后,翻译指令单元开始 翻译指令1时,取指令单元可 取出指令2了
如果CPU不这么做,等到指令1完成上面四个步骤后,指令2才开始进行,那效率太低了
流水化中的单元分的更详细, 更多的指令可以并行处理,但速度不见得快,因为有分支的出现,如果没有命中第一个分支,后面的指令将作废, 需要清空后面所有的指令, 然后中载命中地址的指令,再运行
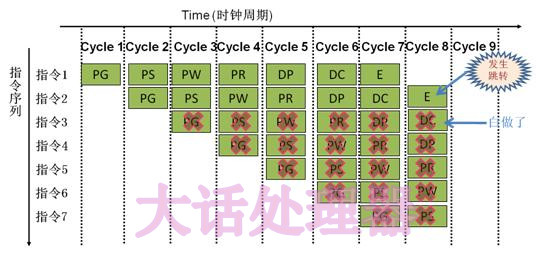
在有5个分支的情况下,若采取随机挑选一个分支 执行的话,每次赌该分支命中的概率只有五分之一, 于是CPU分支预测功能就出现了。
分支预测分静态和动态
静态分支预测:由编译器决定哪个分支可能被CPU命中,一般是第一个分支,即 if 后面的逻辑,而不是后面else的逻辑
动态分支预测:在CPU硬件中开辟一块缓存,专门记录每个分支最近几次的命中情况,然后做出预测,显然这种方法能及时调整策略,有更好的远詹性,但CPU压力会大些,不过还好。
分支地址只有在流水线指令执行阶段才能计算出来,为了避免等待,需要在译码阶段进行预测
Two-Level分支预测方法使用了两种数据结构,一种是BHR(Branch History Register);而另一种是PHT(Pattern History Table)。其中BHR由k位组成(可理解为记录K次某个分支的执行结果),用来记录每一条转移指令的历史状态,而PHT表含有2k个Entry组成,而每一个Entry由两位Saturating Counter组成。BHR和PHT的关系如图3‑10所示。
假设分支预测单元在使用Two-Level分支预测方法时,设置了一个PBHT表(Per-address Branch History Table)存放不同指令所对应的BHR。在PBHT表中所有BHR的初始值为全1,而在PHT表中所有Entry的初始值值为0b11。BHR在PBHT表中的使用方法与替换机制与Cache类似。
当分支预测单元分析预测转移指令B的执行时,将首先从PBHT中获得与转移指令B对应的BHR,此时BHR为全1,因此CPU将从PHT的第11…11个Entry中获得预测结果0b11,即Strongly Taken。转移指令B执行完毕后,将实际执行结果Rc更新到BHR寄存器中,并同时更新PHT中对应的Entry。
当CPU再次预测转移指令B的执行时,仍将根据BHR索引PHT表,并从对应Entry中获得预测结果。而当指令B再次执行完毕后,将继续更新BHR和PHT表中对应的Entry。当转移指令的执行结果具有某种规律(Pattern)时,使用这种方法可以有效提高预测精度。如果转移指令B的实际执行结果为001001001….001,而且k等于4时,CPU将以0010-0100-1001这样的循环访问BHR,因此CPU将分别从PHT表中的第0010、0100和1001个Entry中获得准确的预测结果。
由以上描述可以发现,Two-Level分支预测法具有学习功能,并可以根据转移指令的历史记录产生的模式,在PHT表中查找预测结果。该算法由T.Y. Yeh and Y.N. Patt在1991年提出,并在高性能处理器中得到了大规模应用。
Two-Level分支预测法具有许多变种。目前x86处理器主要使用“Local Branch Prediction”和“Global Branch Prediction”两种算法。
在“Local Branch Prediction”算法中,每一个BHR使用不同的PHT表,Pentium II和Pentium III处理器使用这种算法。该算法的主要问题是当PBHT表的Entry数目增加时,PHT表将以指数速度增长,而且不能利用其它转移指令的历史信息进行分支预测。而在“Global Branch Prediction”算法中,所有BHR共享PHT表,Pentium M、Pentium Core和Core 2处理器使用这种算法。
在高性能处理器中,分支预测单元对一些特殊的分支指令如“Loop”和“Indirect跳转指令”设置了“Loop Prediction”和“Indirect Prediction”部件优化这两种分支指令的预测。此外分支预测单元,还设置了RSB(Return Stack Buffer),当CPU调用一个函数时,RSB将记录该函数的返回地址,当函数返回时,将从RSB中获得返回地址,而不必从堆栈中获得返回地址,从而提高了函数返回的效率。
目前在高性能处理器中,动态分支预测的主要实现机制是CPU通过学习以往历史信息,并进行预测,因而Neural branch predictors机制被引入,并取得了较为理想的效果,本节对这种分支预测技术不做进一步说明。目前指令的动态分支预测技术较为成熟,在高性能计算机中,分支预测的成功概率在95%~98%之间,而且很难进一步提高。
参考:http://blog.sina.com.cn/s/blog_6472c4cc0100qxd2.html
http://tonysuo.blogspot.hk/2013/12/computer-architecture-5.html
http://blog.hesey.net/2013/03/branch-prediction-in-pipeline.html
http://wenku.baidu.com/view/48833667ddccda38376bafa2.html
http://blog.sina.com.cn/s/blog_5a82024e0100e5lm.html
//大话处理器
http://blog.csdn.net/muxiqingyang/article/details/6677425
http://cyukang.com/2012/07/11/branch_prediction.html
http://blog.csdn.net/wahaha_nescafe/article/details/8500094
https://www.zhihu.com/question/23973128
http://blog.sina.com.cn/s/blog_6556314c0100hamf.html
http://blog.sina.com.cn/s/blog_6556314c0100hamt.html
http://blog.sina.com.cn/s/blog_6556314c0100hamj.html
http://blog.sina.com.cn/s/blog_6556314c0100hamh.html
https://www.zhihu.com/question/23973128


CPU 分支预测的更多相关文章
- 从一段 Dubbo 源码到 CPU 分支预测的一次探险之旅
每个时代,都不会亏待会学习的人. 大家好,我是 yes. 这次本来是打算写一篇 RocketMQ 相关文章的,但是被插队了,我也是没想到的. 说来也是巧最近在看 Dubbo 源码,然后发现了一处很奇怪 ...
- 如何在代码层面提供CPU分支预测效率
关于分支预测的基本概念和详细算法可以参考我之前写的知乎回答,基本概念不再阐述了~~ https://www.zhihu.com/question/486239354/answer/2410692045 ...
- CPU分支预测器
两篇结合就ok啦 1.https://www.jianshu.com/p/be389eeba589 2.https://blog.csdn.net/edonlii/article/details/87 ...
- 现代中央处理器(CPU)是怎样进行分支预测的?
人们一直追求CPU分支预测的准确率,论文Simultaneous Subordinate Microthreading (SSMT)中给了一组数据,如果分支预测的准确率是100%,大多数应用的IPC会 ...
- 【操作系统之十二】分支预测、CPU亲和性(affinity)
一.分支预测 当包含流水线技术的处理器处理分支指令时就会遇到一个问题,根据判定条件的真/假的不同,有可能会产生转跳,而这会打断流水线中指令的处理,因为处理器无法确定该指令的下一条指令,直到分支执行完毕 ...
- 【CPU微架构设计】利用Verilog设计基于饱和计数器和BTB的分支预测器
在基于流水线(pipeline)的微处理器中,分支预测单元(Branch Predictor Unit)是一个重要的功能部件,它负责收集和分析分支/跳转指令的执行结果,当处理后续分支/跳转指令时,BP ...
- GCC的分支预测优化__builtin_expect
智能指针笔记 GCC的原子操作函数 将流水线引入cpu,可以提高cpu的效率.更简单的说,让cpu可以预先取出下一条指令,可以提供cpu的效率.如下图所示: 取指令 执行指令 输出结果 取指令 执行 ...
- __builtin_expect — 分支预测优化
1.引言 在很多源码如Linux内核.Glib等,我们都能看到likely()和unlikely()这两个宏,通常这两个宏定义是下面这样的形式. #define likely(x) __builtin ...
- 分支预测(branch prediction)
记录一个在StackOverflow上看到一个十分有趣的问题:问题. 高票答案的优化方法: 首先找到罪魁祸首: if (data[c] >= 128) sum += data[c]; 优化方案使 ...
随机推荐
- linux 硬盘分区攻略
以下的sdX代表硬盘分区(如sda1,sda2,sdb1...等等),如果已有的硬盘分区需要改变大小的话,请参考另一篇文章. /boot:开机用的磁盘空间了,至少78MB,一般给100MB就好了. / ...
- css样式记忆
text-indent: 2em; //开头空两格: display : none; //隐藏元素 background:#CCC; //背景颜色 background: url(imag ...
- hdu -1114(完全背包)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1114 思路:求出存钱罐装全部装满情况下硬币的最小数量,即求出硬币的最小价值.转换为最小背包的问题. # ...
- nvarchar,varchar 区别
char char是定长的,也就是当你输入的字符小于你指定的数目时,char(8),你输入的字符小于8时,它会再后面补空值.当你输入的字符大于指定的数时,它会截取超出的字符. nva ...
- yersinia的DHCP池耗尽断网攻击
http://jingyan.baidu.com/article/0eb457e5045bd703f1a9051d.html yersinia -G
- 16)maven lifecycle
http://maven.apache.org/guides/introduction/introduction-to-the-lifecycle.html http://maven.apache.o ...
- 一种基于Redis的10行代码实现IP频率控制方法
优点:可支持海量访问的频率控制,只需要增加Redis机器,单个Redis节点(只占用一个cpu core)即可支持10万/s以上的处理. 基于IP频率限制是种常见需求,基于Redis可以十分简单实现对 ...
- QGIS Server Quickstart
http://live.osgeo.org/en/quickstart/qgis_mapserver_quickstart.html
- springmvc 孔浩
modelAttribute属性指定该form绑定的是哪个Model,当指定了对应的Model后就可以在form标签内部其 它表单标签上通过为path指定Model属性的名称来绑定Model中的数据了 ...
- mysql的sql性能分析器
MySQL 的SQL性能分析器主要用途是显示SQL执行的整个过程中各项资源的使用情况.分析器可以更好的展示出不良SQL的性能问题所在. mysql sql profile的使用方法 1.开启mysql ...