如何使用mysql存储树形关系
最近遇到业务的一个类似文件系统的存储需求,对于如何在mysql中存储一颗树进行了一些讨论,分享一下,看看有没有更优的解决方案。
一、现有情况
首先,先假设有这么一颗树,一共9个节点,1是root节点,一共深3层。(当然实际业务不会这么简单)
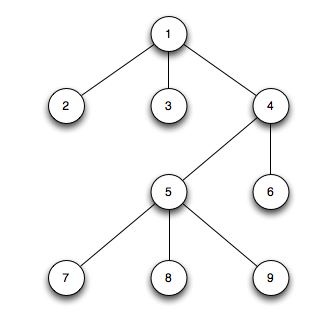
原有的表结构如下:
| id | parents_id | name | full_path |
| 1 | 0 | a | /a |
| 2 | 1 | b | /a/b |
| 3 | 1 | c | /a/c |
| 4 | 1 | d | /a/d |
| 5 | 4 | e | /a/d/e |
| 6 | 4 | f | /a/d/f |
| 7 | 5 | g | /a/d/e/g |
| 8 | 5 | h | /a/d/e/h |
| 9 | 5 | i | /a/d/e/i |
需要满足的几个基本需求为:
1、从上到下逐层展开目录层级
2、知道某一个目录反查其全路径
3、rename某一个路径的名字
4、将某一个目录挪到其他目录下
现有的表结构可以满足以上的需求:
1、select id from table where parents_id=$id;(可以查出所有直接子节点) 2、select full_path from table where id=$id;(通过全路径字段获取) 3、update table set name=$newname where id=$id;(将需要修改的id的name字段修改) 4、update table set parents_id=$new_parents_id,full_path=$new_full_path where id=$id;(修改父子关系到新的关系上)
但是现有的表结构会遇到的问题就是,第3和第4个需求,其并不是只更新一行即可,由于有full_path的存在,所有被修改的节点,其下面的所有节点的full_path都需要修改。这就无形之间增加了很多写操作,如果这颗树比较深,比如有100层,那么修改第3层的数据,那么就意味着其下面97层的所有数据都需要被修改,这个产生的写操作就有些恐怖了。
以列子所示,如果4的name被修改,都会影响4,5,6,7,8,9一共6行数据的更新,这个写逻辑放大的有点厉害。
update table set name=x,full_path='/a/x' where id=4;
update table set full_path='/a/x/e' where id=5;
update table set full_path='/a/x/f' where id=6;
update table set full_path='/a/x/e/g' where id=7;
update table set full_path='/a/x/e/h' where id=8;
update table set full_path='/a/x/e/i' where id=9;
那么如何解决这个问题呢?
二、优化方案
1、去除full_path字段
上面所述问题最严重的就是写逻辑放大的问题,采用去除full_path字段后,6条update就变成1条update的了。
这个优化看起来完美解决写逻辑放大问题,但是引入了另一个问题,那就是需求2的满足费劲了。
原有SQL是:
select full_path from table where id=$id;
但是去除full_path字段之后,变为:
select parents_id from table where id =$id;
select parents_id from table where id = $parents_id;
以示例来说,如果要得到9的全路径,那么就需要如下SQL
select parents_id,name from table where id = 9;
select parents_id,name from table where id = 5;
select parents_id,name from table where id = 4;
select parents_id,name from table where id = 1;
当最后判断到parents_id=0的时候结束,然后将所有name聚合在一起。
如果所有操作都需要前端实现,那么就需要前端和DB交互4次,这期间消耗的链接成本会极大的延长总体的响应时间,基本是不可接收的。
如果要采用这种方案,目前看来只有使用存储过程,将所有计算都在本地完成之后在返回给端,保证一次请求,一次返回,这样才最效率,但是mysql的存储过程个人不太建议使用,风险较大。
2、产品规范
我们的问题会发生在树的层级特别多的情况下,那么可以通过产品规范来进行限制,比如最深只能有4层,这样就将问题遏制在发生之前了。(当然,有些时候这种最有效的优化方案是最不可能实现的,产品不会那么容易妥协)
3、增加cache
问题既然是写逻辑放大,那么如果我们将优化思路从降低写入次数,改为提高写入性能呢?
我们引入redis这种nosql存储,将id和full_path存放在redis中,每次更新数据库之后在更新redis,redis的写入性能远高于mysql,这样问题也可以得到解决。
只不过由于更新不是同步的,采用异步更新之后,数据会最终一致,但是在某一个特殊时间点可能会存在不一致。
并且由于存储架构变化,需要代码方面做出一定的妥协,无论是读操作还是写操作。
4、整体改变存储结构
以上方案都是在不大改现有表结构的基础上做出的,那么有没有可能修改表结构之后情况会不一样呢?
我们对所示例子的存储结构引入层级的概念,去除full_path,看看是否可以解决问题。
新的表结构如下:
id_name(id和name映射关系)
| id | name |
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
| 6 | f |
| 7 | g |
| 8 | h |
| 9 | i |
relation(父子关系)
| id | chailds | depth |
| 1 | 1 | 0 |
| 1 | 2 | 1 |
| 1 | 3 | 1 |
| 1 | 4 | 1 |
| 1 | 5 | 2 |
| 1 | 6 | 2 |
| 1 | 7 | 3 |
| 1 | 8 | 3 |
| 1 | 9 | 3 |
| 2 | 2 | 0 |
| 3 | 3 | 0 |
| 4 | 4 | 0 |
| 4 | 5 | 1 |
| 4 | 7 | 2 |
| 4 | 8 | 2 |
| 4 | 9 | 2 |
| 5 | 5 | 0 |
| 5 | 7 | 1 |
| 5 | 8 | 1 |
| 5 | 9 | 1 |
| 6 | 6 | 0 |
| 7 | 7 | 0 |
| 8 | 8 | 0 |
| 9 | 9 | 0 |
这两张新表第一张不用解释了,第二张id字段存放节点id,chailds字段存放其所有子节点(并不是直接chaild,而是不论层级都存放),depth字段存放其子节点和本节点的层级关系。
我们看下这么设计是否可以满足最初的4个需求:
需求1:逐层展开目录
select id,depth from table2 where id=$id;
select name from table1 where id=$id;
由于每个id都存放了其所有的子节点,所以如果查询4的所有下属目录,直接select id,depth from table2 where id = 4;一条SQL即可获得所有结果,只要前端在处理一下即可。
| id | chailds | depth |
| 4 | 4 | 0 |
| 4 | 5 | 1 |
| 4 | 6 | 1 |
| 4 | 7 | 2 |
| 4 | 8 | 2 |
| 4 | 9 | 2 |
需求2:根据某一个目录获知其全路径
select id,depth from table2 where chailds = $id;
由于每个id都存放了所有子节点,所以反差也是一条sql的事情。比如查询9的全路径,那么select id,depth from table2 where chailds=9;得到的结果应该是
| id | chailds | depth |
| 9 | 9 | 0 |
| 5 | 9 | 1 |
| 4 | 9 | 2 |
| 1 | 9 | 3 |
通过上述结果,前端进行计算处理就可以得到9的全路径了,并且是一条sql获得,不需要前端和db多次交互,也不需要引入存储过程。
需求3:更改目录名称
update table1 set name = $new_name where id = $id ;
这个最简单了,只需要更改映射表即可。
需求4:更改节点的父子关系
select id from table2 where id=$id and depth > 0;
delete from table2 where id = $sql1_id;
select id from table2 where id = $new_father_id;
inset into table2 values ($sql2_id,$id,$depth+1);
这个需求目前看来最麻烦,我们以示例所示,如果将5挪到3下面需要经过哪些操作?
I:先查出来5都属于哪些节点的子节点。
select id from table 2 where id=5 and depth > 0;
|
id |
chailds | depth |
| 1 | 5 | 2 |
| 4 | 5 | 1 |
II:删除这些记录。
delete from table2 where id=1 and chailds=5;
delete from table2 where id=4 and chailds=5;
III:查出新父节点是哪些节点的子节点。
select id,depth from table where chailds=3 and depth > 0 ;
| id | chailds | depth |
| 1 | 3 | 1 |
IIII:
根据III的结果插入新的关系。
insert into table2 values (1,5,2);
由于新父节点只是1的子节点,故只需要在增加5和1个关系既可,同时由于3是5的新父节点,那么5和1的深度关系应该比3的关系“+1”。
而所有5下面的节点都不需要更改,因为这么设计所有节点都是自己子节点的root,所以只要修改5的关系即可。
但是这个解决方案明显可以看出来,需要存储的关系比原有情况多了很多倍,尤其是关系层级深的情况下。
三、总结
方案1:解决写逻辑放大问题,但是引入了读逻辑放大问题,并需要引入存储过程解决。
方案2:产品规范解决,最彻底的解决方法,但需要和PM沟通确认,业务很难妥协。
方案3:引入cache解决写入性能,但是需要代码进行修改,并存在数据不一致的风险。
方案4:解决写逻辑放大问题,也没有引入读逻辑放大问题,仅仅只是在更改目录的时候稍微麻烦一些,但是引入了初始存储容量暴增的问题。
目前看来,并没有什么特别优秀的方案,都需要付出一定的代价。
ps:本文的思路参考了《SQL反模式》,如果有兴趣的读者可以去研读一下。
如何使用mysql存储树形关系的更多相关文章
- Mysql通过Adjacency List(邻接表)存储树形结构
转载自:https://www.jb51.net/article/130222.htm 以下内容给大家介绍了MYSQL通过Adjacency List (邻接表)来存储树形结构的过程介绍和解决办法,并 ...
- Mysql存储引擎之TokuDB以及它的数据结构Fractal tree(分形树)
在目前的Mysql数据库中,使用最广泛的是innodb存储引擎.innodb确实是个很不错的存储引擎,就连高性能Mysql里都说了,如果不是有什么很特别的要求,innodb就是最好的选择.当然,这偏文 ...
- MySQL存储引擎总结
MySQL存储引擎总结 作者:果冻想 字体:[增加 减小] 类型:转载 这篇文章主要介绍了MySQL存储引擎总结,本文讲解了什么是存储引擎.MyISAM.InnoDB.MEMORY.MERGE等内 ...
- Mysql存储引擎__笔记
Mysql存储引擎(表类型): Mysql数据库: 通常意义上,数据库也就是数据的集合,具体到计算机上数据库可以使存储器上一些文件的集合或者一些内存 数据的内存数据的集合. Mysql数据库是开放源代 ...
- MySQL存储引擎:InnoDB和MyISAM的差别/优劣评价/评测/性能测试
InnoDB和MyISAM简介 MyISAM:这个是默认类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的 顺序访问方法) 的缩写 ...
- mysql存储引擎、事务
MySQL存储引擎介绍 文件系统 操作系统组织和存取数据的一种机制. 文件系统是一种软件. 文件系统类型 ext2 ext3 ext4 xfs 数据 不管使用什么文件系统,数据内容不会变化 不同 ...
- mysql存储引擎和索引
正确的创建合适的索引,是提升数据库查询性能的基础. 第一章 mysql之索引 索引的定义:索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构. 我们为什么要使用索引: a.极大的减少存储引 ...
- 7.Mysql存储引擎
7.表类型(存储引擎)的选择7.1 Mysql存储引擎概述 mysql支持插件式存储引擎,即存储引擎以插件形式存在于mysql库中. mysql支持的存储引擎包括:MyISAM.InnoDB.BDB. ...
- Mysql存储之原生语句操作(pymysql)
Mysql存储之原生语句操作(pymysql) 关系型数据库是基于关系模型的数据库,而关系模型是通过二维表时实现的,于是构成了行列的表结构. 表可以看作是某个实体的集合,而实体之间存在联系,这个就需要 ...
随机推荐
- python网络编程-socket发送大数据包问题
一:什么是socket大数据包发送问题 socket服务器端或者客户端在向对方发送的数据大于对方接受的缓存时,会出现第二次接受还接到上次命令发送的结果.这就出现象第一次接受结果不全,第二次接果出现第一 ...
- AngularJs(SPA)单页面SEO以及百度统计应用(上)
只有两种人最具有吸引力,一种是无所不知的人,一种是一无所知的人 问:学生问追一个女孩总是追不上怎么办?回答:女孩不是追来的,是吸引来的,你追的过程是吸引女孩的过程,如果女孩没有看上你,再追都是没有用的 ...
- echart 打开新世界的大门
实时折线图 option = { backgroundColor:'#2B2B2B', tooltip: { trigger: 'axis' }, legend: { data:['频率'], tex ...
- C语言:1孩半问题
题目: 一孩半,又称独女户二胎,即中国大陆部分农村的一项计划生育政策,第一胎是女孩的夫妻可以生育第二个子女.如果第二胎有n%人工性别选择干预(选择男孩),试问男女比例为多少.(10分)题目内容: 一孩 ...
- SIlkTest入门
http://bbs.51testing.com/thread-983434-1-1.html
- 基于 Struts2 的单文件和多文件上传
文件的上传下载是 Web 开发中老生常谈的功能,基于 Struts2 框架对于实现这一功能,更是能够给我们带来很多的便利.Struts2 已经有默认的 upload 拦截器.我们只需要写参数,它就会自 ...
- Codeforces Round #248 (Div. 1) D - Nanami's Power Plant 最小割
D - Nanami's Power Plant 思路:类似与bzoj切糕那道题的模型.. #include<bits/stdc++.h> #define LL long long #de ...
- NET生成缩略图
1.添加一个html <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <hea ...
- kylin加载hive表错误:ERROR [http-bio-7070-exec-10] controller.TableController:189 : org/apache/hadoop/hive/conf/HiveConf java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf 解决办法
一.问题背景 在kylin中加载hive表时,弹出提示框,内容是“oops!org/apache/hadoop/hive/conf/HiveConf”,无法加载hive表,查找kylin的日志时发现, ...
- CSUOJ 1895 Apache is late again
Description Apache is a student of CSU. There is a math class every Sunday morning, but he is a very ...