UNIX环境高级编程 第1章 UNIX基础知识
所有操作系统都为运行在它之上的程序提供各种服务,典型的服务包括:执行新程序、打开文件、读写文件、分配存储空间、提供时间等。
UNIX体系结构
严格来说,操作系统是一种软件,它控制计算机硬件资源,提供程序运行环境。这种软件有个专业术语名称:内核。因为它小且位于计算机体系的核心。如下图所示:
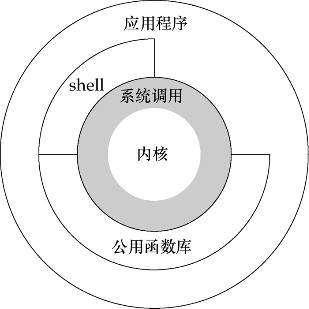
上图中的系统调用包裹在内核的外围,隔离开内核以保护内核。同时,系统调用作为和内核沟通的中间桥梁。
公用函数库通常指的是C/C++的标准库,例如libc、glibc、libstdc++、libc++等标准库,不同的标准库是由于不同的系统平台或编译器厂商造成的差异,但追根究底都是使用了底层系统内核的API接口系统调用。这些公用函数库极大的方便了上层开发者的使用,也是整个计算机软件体系(无论任何编程语言)的基础。
shell也是一个软件,该软件负责人机交互,用户和shell进行“对话”,然后shell理解用户的意图来使计算机按用户的想法工作。比如我们使用ls命令告诉shell我们想查看文件夹,shell接收后使用各种底层功能(包括读写文件系统、IO输入输出等)来完成该工作,当然最终的结果是打印文件夹在我们的屏幕上显示给我们看。
公用函数库只是提供了好用的功能,这些功能最终是要我们自己来使用的,当我们作为软件开发者的时候,可以调用公用函数库来使用某些功能,如果公用函数库提供的功能不好用或者没有提供,我们也可以直接使用系统调用来请求服务。
上图的内核是严格意义上的操作系统软件,广义上来说,操作系统不仅是内核,因为仅有一个内核只能管理硬件,操作系统还要包含一些软件来加以辅助使用计算机,包括shell、公用函数库、系统程序和实用软件。这也是为什么Linux被称作GNU/Linux操作系统的原因,为了简便称其为Linux,实际上Linux之所以能有今天的成绩,并非Linus torvalds的功劳,甚至可以说他被外界过度夸大,因为Linux是从Minix改写而来(1991年,此时内核难度和硬件移植与今天相比不可同日而语),Linux使用了大量的GNU工具组合成了Linux系统,其后Linux的发展壮大也是广大志愿者黑客出力,所以说Linux的成绩并非Linus torvalds的功劳,他被外界过度神话了。
前面说到shell,要提一下C shell的作者,当初C shell被开发出来之后,由于功能多而广泛流传使用,其开发者是Bill Joy。与Linus torvalds相比,Bill Joy才是真正的大神人物,TCP协议实现、Vi编辑器/C shell的开发作者,BSD内核贡献者,Java创始人之一、SUN公司的合伙创办人,曾有人开玩笑说:和Bill Joy见面,一定要三次握手:)
登录
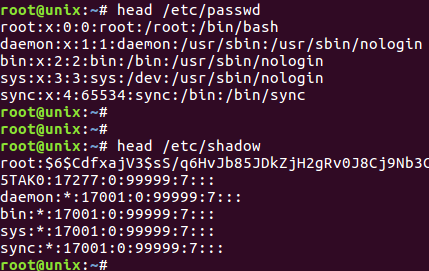
UNIX系统登录涉及到用户名和密码,以及登录后负责交互对话的shell版本,用户名和shell由配置文件/etc/passwd决定,密码由配置文件/etc/shadow决定。
文件系统
UNIX文件系统是一直树形层次结构,有一个根,是最根本的起点,它是“/”。在文件系统中,目录本质上也是一个文件,其内容是目录项的记录。每个目录项都是一个文件名,还包含一些文件属性的说明信息,比如权限、大小、时间等。
创建新目录时文件系统会自动创建两个文件夹:.(点)和 ..(点点), .(点)表示当前目录,比如我需要拷贝/etc目录下的a文件到当前目录,那么就可以这么做:
- cp /etc/a .
上面使用cp命令将/etc/a这个文件拷贝到当前目录下。
..(点点)表示父目录,比如我需要将当前目录下的b文件拷贝到上一层父目录中,则可以这么做:
- cp b ..
上面使用cp命令将当前目录下的b文件拷贝到上一层路径中,而不需要显式给出上层具体路径。
有一个特殊的情况,那就是根目录“/”下的.(点)和 ..(点点)是同一个路径,都是“/”。
由斜线“/”开头的路径都是绝对路径,反之则是相对路径。
下面是一个用C++实现的ls(1)命令小代码:
- #include <dirent.h>
- #include <iostream>
- int main(int argc, char const *argv[])
- {
- if (argc != )
- {
- std::cout << "usage: " << argv[] << " directory" << std::endl;
- return -;
- }
- DIR *dp;
- dirent *dirp;
- if (!(dp = opendir(argv[])))
- {
- std::cout << "can't open " << argv[] << std::endl;
- return -;
- }
- while ((dirp = readdir(dp))) //双层括号,去除编译器认为可能的错误提示
- {
- std::cout << dirp->d_name << std::endl;
- }
- return ;
- }
上面这段代码是一个简单ls(1)命令的实现,在Mac OS平台上是按字母顺序输出结果的,但在Ubuntu上是非字母顺序的。
关于“ls(1)”中“(1)”指的是命令章节是属于第一章之内的,UNIX命令通常都会有一个说明手册,手册中对命令有详细说明,但随着命令功能和说明的增加,说明手册页数越来越多,之后便对命令进行了分门别类,通常是1-8总共8中分类,具体是:
1、Standard commands (标准命令)
2、System calls (系统调用)
3、Library functions (库函数)
4、Special devices (设备说明)
5、File formats (文件格式)
6、Games and toys (游戏和娱乐)
7、Miscellaneous (杂项)
8、Administrative Commands (管理员命令)
默认搜索命令时是从最低编号开始搜索,如果搜索到即停止。有时某个命令存在多个编号说明,那么我们就需要指明章节编号。比如 read 命令,该命令既有编号1的命令说明,又有编号2的说明,如果我们想要编号2,则可以具体指明,如下:
- man read
或者
- man -s2 read
每个进程都有一个工作目录,一般称为当前工作目录,进程可以用chdir来更改其工作目录。在登录那里,shell程序的工作目录设置为home目录,该目录通常从/etc/passwd配置文件中获得。
输入和输出
在UNIX系统中输入和输出是经过抽象的,所有的输入和输出底层系统实现都是通过文件抽象来完成的。当我们要读写时,必须要对“文件”进行,这里的文件是UNIX系统哲学中的“一切皆文件”中的“文件”。当我们读写时,是在对抽象的文件进行读写,而实际上该文件可能管理映射到硬件,也可能是一个socket套节字。
对于文件的抽象,是通过文件描述符实现的,打开一个文件得到一个文件描述符,它通常是非负数的,我们对该文件描述符进行读写。
标准输入、标准输出和标准错误也是三个文件描述符,且一般情况下,它们被shell默认打开并默认被系统映射到硬件设备。我们可以使用“ < "和" >”来重定向这三个文件描述符默认打开的设备。
UNIX系统为我们提供了几个用于文件IO的系统调用:open、read、write、lseek、close,它们都使用文件描述符来操作文件,并且不带缓冲。
利用上述系统调用和重定向功能,我们能够简单的写一个小程序来复制普通文件( regular file ),如下:
- #include <unistd.h>
- #include <iostream>
- int main(int argc, char const *argv[])
- {
- int n;
- char buffer[];
- while ((n = read(STDIN_FILENO, buffer, )) > )
- {
- if (write(STDOUT_FILENO, buffer, n) != n)
- {
- std::cout << "write error" << std::endl;
- }
- }
- if (n < )
- {
- std::cout << "read error" << std::endl;
- }
- return ;
- }
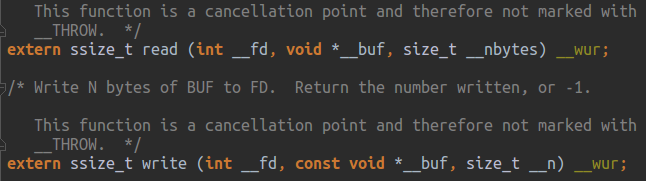
上述代码中,STDIN_FILENO和STDOUT_FILENO是定义在头文件 unistd.h 中的宏,如下图所示:

该头文件还包含了read和write函数的原形说明,如下图所示:
UNIX系统为我们提供的几个IO系统调用是不带缓冲的,我们也可以使用公用函数库提供的封装过的接口来间接调用系统调用,公用函数库提供的接口是带缓冲的,且无需考虑对缓冲区大小的选择。不过公用函数库提供的接口和系统调用API接口有一些差异,其不再对文件使用文件描述符抽象来进行读写,也不再使用固定字节数来读写,取而代之的是使用文件名和一次读写一个/一行字符(串)。
程序和进程
程序是静态的进程,而进程是运行着的程序。程序本质上是一个存在硬盘上的可执行文件。程序被加载到内存中之后就开始执行,此时程序变成一个动态刻画抽象的进程。每一个进程都有一个标识符,称为进程ID,其是一个非负数,且在当前时刻是唯一的。
有3个可以用于控制进程的系统调用:fork、exec和waitpid。其中exec是一系列函数的统称。
线程和线程ID
通常,一个进程只有一个线程。使用多线程能够充分利用多处理器系统的并行能力。一个进程内的所有线程共享当前进程的所有内存空间、文件描述法、栈以及进程相关的属性。由于所有进程共享进程的内存空间,因此在访问共享数据时需要采取同步措施以避免数据的不一致。
同进程类似,线程也有一个ID唯一标识每一个进程,但线程的ID只在进程内部有效,进程外部则无意义。线程也有特意用于控制线程的系统调用,后续学习。
出错处理
当UNIX系统调用API函数出错时,通常会返回一个负值,这个返回值和进程返回给系统的返回值不相同,进程返回给系统的状态值范围是0 ~ 255。系统调用API函数通常会将该错误返回值赋给errno,errno变量看起来像是一个int类型的变量,但实际上并不是,早期的时候,它被简单的用int类型变量实现,但随着多线程出现之后,一个进程的errno变量是被多个线程共享的,当某一个线程因为出错而改变了errno变量之后,其他线程无法根据errno来判断自己当前的状态,造成了混淆,因此现在它通常被实现为一个函数调用,如下:

该定义在头文件 errno.h 中,首先声明了一个函数原型,该函数不接受参数,返回值是一个int * (int指针),errno定义为函数返回值(指针)的解引用。
C语言标准库函数提供了两个函数可以用于转换errno的值到具体的错误信息,如下:
- #include <string.h>
- char* strerror(int errnum);
- #include <stdio.h>
- void perror(const char *msg);
strerror函数将errno变量的值转换为对应的具体错误信息,错误信息存储于字符串中,该字符串通过函数返回值指针指明。
perror函数将先打印msg消息,然后跟上一个冒号和一个空格,接着是errno值对应的可读错误信息,最后换行。
对于上面两个函数的使用示例如下:
- #include <errno.h>
- #include <stdio.h>
- #include <cstring>
- #include <iostream>
- using std::cout;
- using std::endl;
- int main()
- {
- errno = ;
- cout << strerror();
- cout << endl;
- perror("file a");
- return ;
- }
上面的程序中,手动设置了errno变量为2,strerror函数将错误信息通过指针返回,代码使用标准输出打印其具体信息。perror接受一个信息参数,先打印传入的信息,然后是冒号和空格,随后是具体错误信息和换行。代码执行结果如下:

当出错的时候,错误分为两种:致命和非致命的。对于致命错误,无法恢复,只能打印错误信息、写日志,然后退出。而非致命的错误,一般是能恢复的,通常是等待一段时间后再试。
用户标识
用户标识也是通过ID来进行区分的,该ID称为用户ID,它是一个数字。当一个用户创建时,会在/etc/passwd文件中生成唯一的用户ID,用户不能更改这个ID,除非是root用户才允许修改。
ID号码为0的用户是root用户,或者说是超级用户,该用户的用户名默认是root,也可以修改为其他的。如果一个进程拥有超级用户的特权,则大多数文件文件检查步骤都会被忽略。
用户除了用ID来进行区分,也用组来进行划分管理,相应的,其也有组ID,也是一个数字。与用户ID不同,一个用户只能有一个用户ID,多个用户名对应一个ID时,还是一个用户,系统只会根据ID来识别,而不会根据用户名来识别。而用户的组用户ID不唯一,一个用户可以拥有多个组ID,这表明该用户加入了多个小组。组的目的是为了让多个用户共享一个资源。组相关的配置文件是/etc/group。
用户ID和组ID使用数字来表示是历史遗留下来的,因为文件系统中的每个文件都要存储用户的ID和GID信息,使用数字可以只用4个字节即可存储。另外,如果使用字符串作为ID表示,则字符串之间的比较相对于数字更耗时。
可以通过 getuid( ) 和 getgid( )函数来获得相应的用户ID和组ID,如下:
- #include <unistd.h> //getuid()和getgid()头文件
- #include <iostream>
- using std::cout;
- using std::endl;
- int main()
- {
- cout << getuid() << endl;
- cout << getgid() << endl;
- return ;
- }
信号
信号是UNIX系统用于发送通知的一种机制,比如某个进程访问的内存地址超出了它的范围,则系统会发送一条通知至该进程,进程收到信号通知后,有3种应对处理方法:
1.忽略信号。收到之后什么也不做,当做未发生一样。
2.请系统处理。此方式告诉系统在收到信号时按系统的规定来处理。
3.提供一个处理函数。此方式在收到信号之后,用提供的函数来进行处理。
举个例子来说,假设我们现在有一个程序,它可以有三种方式来应对用户通过键盘Ctrl+C发出的中断信号。对于1.忽略信号,程序会忽略Ctrl+C,这将导致用户按Ctrl+C时没有任何反应,好似没有按Ctrl+C一样。对于2.请系统处理,系统会察觉到进程收到了一个信号,然后用默认的规则来处理,对于Ctrl+C发出中断信号,默认是终止程序,则我们的程序会被结束。对于3.提供一个处理函数来说,程序使用提供的函数处理,可以打印一些日志,等待几秒后退出程序,也可以做其他操作。
时间值
UNIX中谈及的时间可能有两种,一种是指当前客观世界的时间是多少,比如现在是几点几分,其表示方法通过自1970年1月1日以来经过了多少秒的形式,其类型为time_t。另一种是进程时间,也称为CPU时间,用来衡量进程执行耗费资源的计量,其类型为clock_t。
UNIX系统会为一个进程维护3个时间值:时钟时间、用户CPU、系统CPU。其中时钟时间指的是一个进程从运行开始到结束总共花去了多久的时间,它与当前系统中运行了多少进程和系统调度策略有关。用户CPU指的是进程用于执行用户指令花去的时间,系统CPU指的是为进程执行内核程序花去的时间。当一个进程执行了系统调用时,进程的CPU状态就会陷入内核,从而在管态下执行指令,这段时间就是系统CPU时间。用户CPU和系统CPU之和被称为CPU时间,也是程序真正执行耗费的时间。
我们可以用time命令来得知一个程序执行所花费的时间:
系统调用和库函数
所有的UNIX系统都提供多种服务的入口点,由此程序可以向内核请求服务。各种UNIX都提供了良好定义、数量有限、直接进入内核的入口点。这些入口点被称为系统调用。
系统调用接口在man手册的第二部分中说明,是使用C语言定义的。
公用函数库接口在man手册的第三部分中说明,也是使用C语言定义的。它们不一定是内核的入口点,部分会间接使用一个或多个内核系统调用,而有些则完全不使用。
从实现角度看,系统调用和公用函数库有着本质区别,一个是伴随内核而产生的,是不可替换的。另一个是编译器厂商根据语言标准而实现的,可以更新和替换。但从用户角度看,它们没有太大区别,显著的区别是公用函数库更好用,功能更加强。
习题
1.1 在系统上验证,除根目录外,目录 . 和 .. 是不同的。
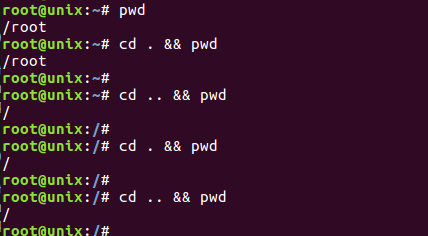
首先使用pwd打印当前目录,然后进入 . 再打印目录,可以看到仍是当前目录,之后进入 .. 再打印目录,可以看到进入了根目录。在根目录下之后,无论进入 . 还是 .. 都是根目录。
1.2 分析图1-6程序的输出,说明进程ID为852和853的进程发生了什么情况?
当前有两个新执行的进程占用了852和853的PID。
1.3 在1.7中perror的参数是用ISO C的属性const定义的,而strerror的整形参数没有用此属性定义,为什么?
对于perror( )和strerror( )的函数声明如下:
- #include <stdio.h>
- extern void perror (const char *__s);
- extern char *strerror (int __errnum) __THROW;
从上面的函数原型可以看到,perror的参数类型是一个指针,通过指针能够解引用从而修改指针所指的对象,通过使用const修饰,可以阻止函数意外改变对象。而strerror的参数是一个普通int类型,而C语言只支持传值调用,因此形参只是实参的拷贝,改变形参这并不会造成什么问题。
1.4 若日历时间存放在带符号的32位整型数中,那么到哪一年它将溢出?可以用什么方法扩展溢出浮点数?采用的策略是否与现有的应用相兼容?
由于时间是存放在带符号的整型数中的,因此该整型数能够用于时间存放的就只有非负数部分,又因为该整型数是32位的,因此最多只有2^(32-1) - 1秒。故而在(2^(32-1) - 1)/60/60/24/365=68年后溢出,这一年是1970+68=2038年。由于日历时间类型为time_t,我们可以将time_t类型用64位整型来表示以防止溢出。要做到完全兼容,这是不可能也是不现实的。
1.5 若进程时间存放在带符号的32位整型数中,而且每秒为100时钟滴答,那么经过多少天后该时间值将会溢出?
由于时间是存放在带符号的整型数中的,因此该整型数能够用于时间存放的就只有非负数部分,又因为该整型数是32位的,因此最多只有2^(32-1) - 1个滴答,而100个滴答才是1秒,因此总计有(2^(32-1) - 1)/100=21474836秒。大约21474836/60/60/24=248天后溢出。
UNIX环境高级编程 第1章 UNIX基础知识的更多相关文章
- UNIX环境高级编程 第2章 UNIX标准及实现
在过去的将近25年时间,人们为了UNIX的标准化做出了种种努力,这使得程序在不同版本的UNIX系统之间的移植相当容易. ISO C 1989年,C语言首个标准得到批准,其为C89.次年,一个带有小改动 ...
- UNIX环境高级编程 第8章 进程控制
本章是UNIX系统中进程控制原语,包括进程创建.执行新程序.进程终止,另外还会对进程的属性加以说明,包括进程ID.实际/有效用户ID. 进程标识 每个进程某一时刻在系统中都是独一无二的,它们之间是用一 ...
- UNIX环境高级编程 第7章 进程环境
本章涉及C/C++程序中main函数是如何被调用的.命令行参数如何传递给main函数.程序的内存空间布局.程序如何使用环境变量.程序如何终止退出. main函数 C程序或C++程序总是从main函数开 ...
- UNIX环境高级编程 第13章 守护进程
守护进程daemon是一种生存周期很长的进程.它们通常在系统引导时启动,在系统关闭时终止.守护进程是没有终端的,它们一直在后台运行. 守护进程的特征 在Linux系统中,可以通过命令 ps -efj ...
- UNIX环境高级编程 第9章 进程关系
在第8章学习了进程的控制原语,通过各种进程原语可以对进程进行控制,包括新建进程.执行新程序.终止进程等.在使用fork( )产生新进程后,就出现了进程父子进程的概念,这是进程间的关系.本章更加详细地说 ...
- UNIX环境高级编程 第6章 系统数据文件和信息
UNIX系统的正常运作需要用到大量与系统有关的数据文件,例如系统用户账号.用户密码.用户组等文件.出于历史原因,这些数据文件都是ASCII文本文件,并且使用标准I/O库函数来读取. 口令文件 /etc ...
- UNIX环境高级编程 第5章 标准I/O库
本章是关于C语言标准I/O库的,之所以在UNIX类系统的编程中会介绍C语言标准库,主要是因为UNIX和C之间具有密不可分的关系.由于UNIX系统存在很多实现,而每个实现都有自己的标准I/O库,为了统一 ...
- UNIX环境高级编程 第16章 网络IPC:套接字
上一章(15章)中介绍了UNIX系统所提供的多种经典进程间通信机制(IPC):管道PIPE.命名管道FIFO.消息队列Message Queue.信号量Semaphore.共享内存Shared Mem ...
- UNIX环境高级编程 第14章 高级I/O
这一章涉及很多概念和函数,包括:非阻塞I/O.记录锁.I/O复用.异步I/O.readv和writev函数以及内存映射. 非阻塞I/O 在Unix中,可以将系统调用分为两种,一种是“低速”系统调用,另 ...
随机推荐
- vector(char*)和vector(string)
vector<char*> ch; vector<string> str; for(int i=0;i<5;i++) { char *c=fun1();//通过这个语句产 ...
- SpringBoot(六)_AOP统一处理请求
什么是AOP AOP 是一种编程范式,与编程语言无关: 将通用逻辑从业务逻辑中分离出来(假如你的业务是一条线,我们不在业务线上写一行代码就能完成附加任务!我们会把代码写在其他的地方): 具体实现 (1 ...
- Dubbo学习(四) dubbo的特点,8种通信协议之对比
一.dubbo的特性 (1) 连通性: 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小 监控中心负责统计各服务调用次数,调用 ...
- 计算机网络【4】—— TCP和UDP的区别
一.TCP/UDP优点和缺点 TCP的优点: 可靠,稳定 TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认.窗口.重传.拥塞控制机制,在数据传完后,还会断开连接 ...
- Python学习---日期时间
在Python里面日期时间的功能主要由几个模块提供:time,calendar,datetime,date等 time主要用到的功能函数: #!/usr/bin/python3 # coding:ut ...
- BZOJ5308 ZJOI2018胖
贝尔福特曼(?)的方式相当于每次将所有与源点直接相连的点的影响区域向两边各扩展一格.显然每个点在过程中最多更新其他点一次且这些点构成一段连续区间.这个东西二分st表查一下就可以了.注意某一轮中两点都更 ...
- 题解 CF1005A 【Tanya and Stairways】
楼上别说这个题水,这个题可能还真有不知道的知识点. 看到这个题,想到刚学的单调栈. 单调栈? 单调栈和单调队列差不多,但是我们只用到它的栈顶. 单调,意思就是一直递增或者递减. 这跟这个题有什么关系? ...
- 查看MySQL最近执行的语句
首先登入MySQL. Reading table information for completion of table and column names You can turn off this ...
- 【spring学习笔记二】Bean
### bean的三种实例化方式: 1.构造 2.静态工厂 3.实例工厂 其中,工厂就是工厂的概念,工厂函数factor-method会返回她生产出来的产品类. 而构造初始化也可以选择初始化方式和销毁 ...
- 【转】关于在vim中的查找和替换
1,查找 在normal模式下按下/即可进入查找模式,输入要查找的字符串并按下回车. Vim会跳转到第一个匹配.按下n查找下一个,按下N查找上一个. Vim查找支持正则表达式,例如/vim$匹配行尾的 ...