目标反射回波检测算法及其FPGA实现 之三:平方、积分电路及算法的顶层实现
目标反射回波检测算法及其FPGA实现之三:
平方、积分电路及算法的顶层FPGA实现
前段时间,接触了一个声呐目标反射回波检测的项目。声呐接收机要实现的核心功能是在含有大量噪声的反射回波中,识别出发射机发出的激励信号的回波。我会分几篇文章分享这个基于FPGA的回波识别算法的开发过程和原码,欢迎大家不吝赐教。以下原创内容欢迎网友转载,但请注明出处: https://www.cnblogs.com/helesheng。
在本系列博文的第一篇中,根据仿真结果,我认为采用“反射回波和激励信号互相关”的结果来计算目标距离的方法具有较高性能和计算效率。在本系列的第二篇博文中,我在Cyclone系列的低成本FPGA中采用半并行的“双存储器式的卷积节”结构实现了数据的互相关/卷积/FIR滤波器计算。作为本系列的第三篇博文,我将实现互相关信号的平方和积分计算,并将所有算法在顶层文件中结合为一个整体。

从而通过寻找 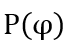 的极值点所在位置来确定目标反射回波出现的时间点。
的极值点所在位置来确定目标反射回波出现的时间点。
(1)式中的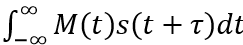 是互相关算法部分,其FPGA实现已在前文中介绍过。根据前文定义的符号,将离散化后的互相关信号记为R[k]。进一步离散化后可将(1)改写为如下FPGA能够实现的形式:
是互相关算法部分,其FPGA实现已在前文中介绍过。根据前文定义的符号,将离散化后的互相关信号记为R[k]。进一步离散化后可将(1)改写为如下FPGA能够实现的形式:

一、平方电路的实现
使用Quartus-II中的MegaWizard配置平方计算电路,其结构如下图所示。

图1 平方电路配置
二、积分电路设计
根据(2)式,要计算目标函数P[n]的值,还需要对历史上的 值求和(积分)。我们当然可以用缓冲器存储历史上的k0个 值,并在每次结果输出之前对缓冲器中的k0个值求和。如果让k0等于激励信号的长度N,则每次输出P[n]之前都需要计算N-1个加法。当N为64时(如前文所述),这几乎是不可完成的任务。我设计了下图所示的电路结构来实现64个历史数据的求和。
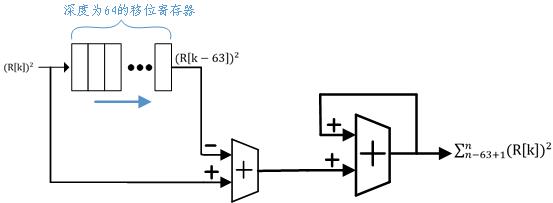
图2 积分器电路结构
其中一位深度为64的移位寄存器的作用是提供64个采样之前的“历史数据”。首先对当前数据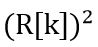 和最老的历史数据
和最老的历史数据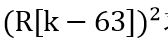 求差(补码),再对差不断求和。这样根据加法交换律,最终求和结果就相当于加入了当前数据,减去了最老的历史数据。只要移位寄存器的初值全为0,在进行了64次操作后,从输出得到的就是64个历史数据的和(积分)了。其中用MegaWizard配置的移位寄存器结构如下图所示。
求差(补码),再对差不断求和。这样根据加法交换律,最终求和结果就相当于加入了当前数据,减去了最老的历史数据。只要移位寄存器的初值全为0,在进行了64次操作后,从输出得到的就是64个历史数据的和(积分)了。其中用MegaWizard配置的移位寄存器结构如下图所示。
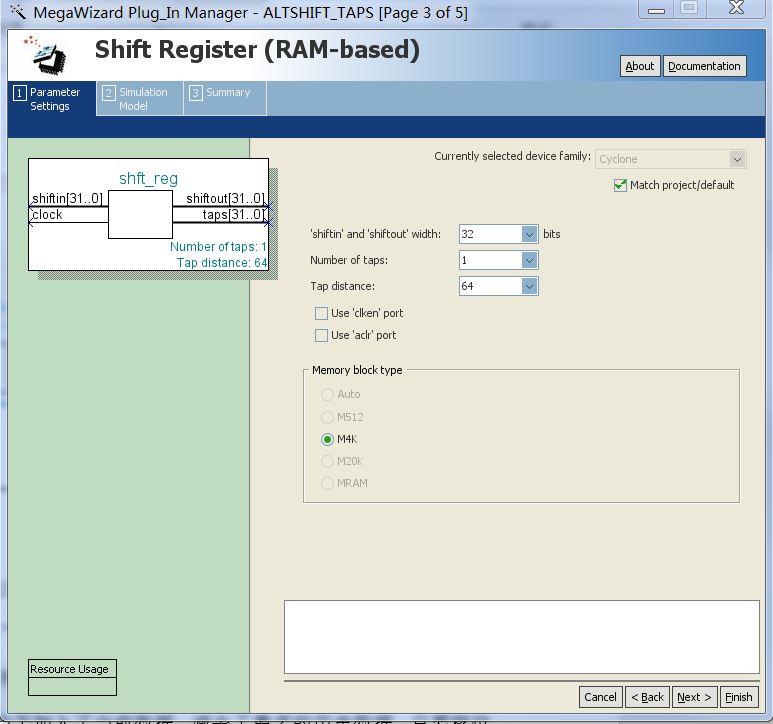
图3 移位寄存器的结构
前级减法器的结构如下图所示。
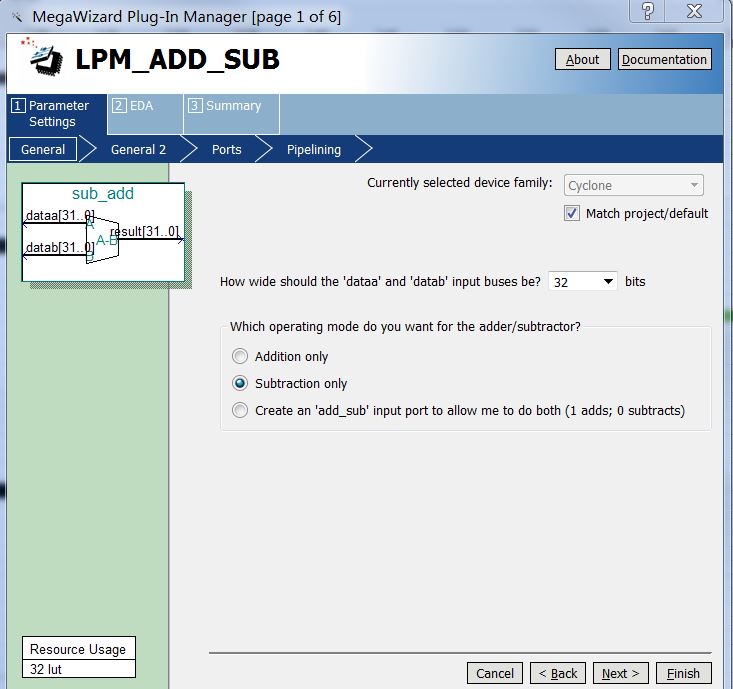
图4 减法器的结构
累加器采用硬件描述语言实现,代码如下。
always @ (posedge start or negedge rst_n)
begin
if(!rst_n)
acc_out[:] <= 'd0;
else begin
acc_out[:] = $signed(acc_out[:]) + $signed(acc_in[:]);
end
end
其中的关键字$signed表示有符号数的加法器。
三、算法的顶层设计
为了将前述的A/D和D/A口控制电路、互相关/卷积/FIR滤波电路、平方和积分电路连接为一个系统,还需要在顶层设计文件中对上述模块电路进行例化和连接。另外顶层设计文件还将对系统的整体工作时序进行控制。我设计的顶层文件如下所示。
module CONV_POW_AD_DA(
///////////顶层模块,负责调用ADC采集数据,卷积,然后用DAC输出卷积/FIR的结果/////////
input rst_n,//低电平复位信号
input iclk20,//外部晶体输入的20MHz
output sck_da,//D/A转换器的SPI时钟
output mosi_da,//D/A转换器的SPI数据信号
output cs_da,//D/A转换器的片选信号
output ld_da,//D/A转换器的双通道数据加载信号
output sck_ad,//A/D转换器的SPI时钟
output mosi_ad,//A/D转换器的SPI数据输出
input miso_ad,////A/D转换器的SPI数据输入
output cs_ad//A/D转换器的SPI口片选信号
);
wire clk;
reg start;
reg[:] cnt;//用于产生总体周期的计时器
reg[:] tst_data;//用于产生测试数据的计数器
parameter CNT_NUM = 'd2000;//100M时钟下,2000分频意味着50KHz溢出率
wire[:] ad_data;//AD转换结果的内部连线
wire[:] data_cha;//A通道数据
wire[:] data_chb;//B通道数据
wire[:] shft_data1;//在卷积的两个节之间传递的数据
wire[:] shft_data2;//在卷积的两个节之间传递的数据
wire[:] shft_data3;//在卷积的两个节之间传递的数据
wire[:] shft_data4;//在卷积的两个节之间传递的数据
wire[:] conv_res1;//第一节的卷积的结果
wire[:] conv_res2;//第2节的卷积的结果
wire[:] conv_res3;//第3节的卷积的结果
wire[:] conv_res4;//第4节的卷积的结果
wire[:] conv_res;//总的卷积的结果
wire[:] acc_sum;//最后计算每一节的累加和的结果
wire[:] shiftout;//移位寄存器的移出数据
wire[:] ac_sig;//去除直流偏置后的交流信号
wire[:] pow_sig;//信号的能量
wire signed[:] acc_in;//求和累加器的输入,也是加法/减法器的输出
reg signed[:] acc_out;//累加器输出的结果
wire signed[:] data_out;//累加结果开方后的输出 //assign data_cha[11:0] = acc_out[25:14];//通道a输出64个点能量累加结果
//assign data_cha[11:0] = shiftout[18:7];//通道a输出的数据
assign data_cha[:] = pow_sig[:];//通道a输出交流信号的平方
//assign data_cha[11:0] = ad_data[11:0];//通道a输出的数据
//assign data_cha[11:0] = shft_data2[11:0];//通道a输出的数据
//assign data_chb[11:0] = conv_res[26:15];//通道b输出的数据
//系数本身是16bit带符号的,由于FIR滤波器的系数之和为1,则16bits带符号的所有系数之和是32768,
//因此需要将滤波结果右移15bit,所以取结果的26:15。但由于DA参考电压为2.048V,小于AD的3.3V因此滤波结果还是略小。
//assign data_chb[11:0] = data_out[14:3];//通道b输出累加结果开方
assign data_chb[:] = acc_out[:];//通道b输出64个点能量累加结果
//assign data_chb[11:0] = pow_sig[20:9];//通道b输出交流信号的平方
//assign data_chb[11:0] = acc_sum[26:15];//通道b输出滤波/卷积结果
//assign data_chb[11:0] = conv_res1[26:15];//通道b输出的数据 /////以下系数配置中用到的连线/////
wire rdy_work;//配置完成信号,高电平表示配置完成
wire[:] wr_blk_addr;//向后级系数blk配置的地址
wire[:] data_bank;//向各级系数blk配置的数据
wire csh0,csh1,csh2,csh3;//每一节配置的系数blk的选通线
PLL20_100 i_pll20_100(//例化PLL产生时钟
.inclk0(iclk20),
.c0(clk)//pll输出的100M工作时钟
); always @ (posedge clk or negedge rdy_work)
begin
if(!rdy_work)
begin
start <= 'd0;
cnt[:] <= 'd0;
tst_data[:] <= 'd0; //用作测试的计数器
end
else begin
//////////维护周期计数器///////////
if(cnt < CNT_NUM-) begin
cnt[:] <= cnt[:] + 'd1;
tst_data[:] <= tst_data[:];
end
else begin
cnt[:] <= 'd0;
tst_data[:] <= tst_data[:] + 'd1; //用作测试的计数器
end ////////产生启动信号/////
if((cnt > )&(cnt <= ))//在第105个clk产生启动信号
start <= 'D1;//启动MCP4822输出状态机
else
start <= 'D0;
end
end init_coe_blk i_init_coe_blk(//例化系数配置模块,起到从系数池中读取系数并向系数blk中配置数据的作用,只在复位后的开始阶段有效,通过ready信号控制后续模块
.clk(clk),
.rst_n(rst_n),//整体复位信号
.ready(rdy_work),//配置完成信号,高电平表示配置完成
.wr_blk_addr(wr_blk_addr),//向后级系数blk配置的地址
.data_bank(data_bank),//向各级系数blk配置的数据
.csh0(csh0),//第一节配置的系数blk的选通线
.csh1(csh1),//第二节配置的系数blk的选通线
.csh2(csh2),//第三节配置的系数blk的选通线
.csh3(csh3)//第四节配置的系数blk的选通线
); CONV_SER16 i_conv_ser16_I(//例化第一个16阶卷积/fir电路
.clk(clk),
.a({'d0,ad_data}),//AD转换结果作为数据输入
//.a({4'd0,tst_data[11:0]}),//AD转换结果作为数据输入
.en(rdy_work),//系数配置完成后才能使能
.coe_data_in16(data_bank),//初始化系数的数据输入端
.wr_coe_addr(~wr_blk_addr[:]),//初始化系数的地址输入端
////!!!特别注意这里,乘加时数据从大地址进入乘加操作,因此地址要求补码,将系数翻转过来。相当于:fliplr();!!!!!//
.wr_coe_clk(clk),//初始化系数写入时钟
.wr_coe_en(csh0),//系数配置的使能端,由初始化模块地址译码产生,方便不同系数blk的选通
.start(start),//输入的启动卷积和fir的控制端
//.shft_out_dp_data(),
.shft_out_dp_data(shft_data1[:]),
//.s_latch(conv_res)
.s_latch(conv_res1[:])
);
CONV_SER16 i_conv_ser16_II(//例化第二个16阶卷积/fir电路
.clk(clk),
.a(shft_data1[:]),//由级联的第一节移出的数据
.en(rdy_work),//系数配置完成后才能使能
.coe_data_in16(data_bank),//初始化系数的数据输入端
.wr_coe_addr(~wr_blk_addr[:]),//初始化系数的地址输入端
////!!!特别注意这里,乘加时数据从大地址进入乘加操作,因此地址要求补码,将系数翻转过来。相当于:fliplr();!!!!!//
.wr_coe_clk(clk),//初始化系数写入时钟
.wr_coe_en(csh1),//系数配置的使能端,由初始化模块地址译码产生,方便不同系数blk的选通
.start(start),//输入的启动卷积和fir的控制端
.shft_out_dp_data(shft_data2[:]),
.s_latch(conv_res2[:])
);
CONV_SER16 i_conv_ser16_III(//例化第3个16阶卷积/fir电路
.clk(clk),
.a(shft_data2[:]),//由级联的第一节移出的数据
.en(rdy_work),//系数配置完成后才能使能
.coe_data_in16(data_bank),//初始化系数的数据输入端
.wr_coe_addr(~wr_blk_addr[:]),//初始化系数的地址输入端
////!!!特别注意这里,乘加时数据从大地址进入乘加操作,因此地址要求补码,将系数翻转过来。相当于:fliplr();!!!!!//
.wr_coe_clk(clk),//初始化系数写入时钟
.wr_coe_en(csh2),//系数配置的使能端,由初始化模块地址译码产生,方便不同系数blk的选通
.start(start),//输入的启动卷积和fir的控制端
.shft_out_dp_data(shft_data3[:]),
.s_latch(conv_res3[:])
);
CONV_SER16 i_conv_ser16_IV(//例化第4个16阶卷积/fir电路
.clk(clk),
.a(shft_data3[:]),//由级联的第一节移出的数据
.en(rdy_work),//系数配置完成后才能使能
.coe_data_in16(data_bank),//初始化系数的数据输入端
.wr_coe_addr(~wr_blk_addr[:]),//初始化系数的地址输入端
////!!!特别注意这里,乘加时数据从大地址进入乘加操作,因此地址要求补码,将系数翻转过来。相当于:fliplr();!!!!!//
.wr_coe_clk(clk),//初始化系数写入时钟
.wr_coe_en(csh3),//系数配置的使能端,由初始化模块地址译码产生,方便不同系数blk的选通
.start(start),//输入的启动卷积和fir的控制端
.shft_out_dp_data(shft_data4[:]),
.s_latch(conv_res4[:])
);
PADD i_PADD (//为了方便DA输出将所有输出偏置为正数
.clock ( start ),
.data0x ( conv_res1[:] ),
.data1x ( conv_res2[:] ),
.data2x ( conv_res3[:] ),
.data3x ( conv_res4[:] ),
.result ( acc_sum[:] )
); MCP4822 i_mcp4822(.clk100m(clk),
.rst_n(rdy_work),
.start(start),
.dac_data_a(data_cha),//通道a输出的数据
//.dac_data_b(dds_data12),//通道b连接DDS内容
//.dac_data_b(product12),//通道b连接乘法的高12位
//.dac_data_b(conv_data12),//通道b连接卷积的结果
.dac_data_b(data_chb),//通道b输出的数据
.cs(cs_da),
.mosi(mosi_da),
.sck(sck_da),
.ld(ld_da)
);
MCP3202 i_mcp3202(
.clk100m(clk),
.rst_n(rdy_work),
.start(start),
.adc_data_a(ad_data),
.cs(cs_ad),
.mosi(mosi_ad),
.miso(miso_ad),
.sck(sck_ad)
); sub_offset i_sub_offset (//这个减法器用于从AD结果中去除直流偏置,结果是16位补码
.dataa ( {'d0,acc_sum[26:15]} ),//卷积结果用于计算
//.dataa ( {4'd0,ad_data[11:0]} ),//AD结果是正整数,只要补零就可以得到16位补码
.datab ( 'h0000 ),//直流偏置认为是1/2满幅度16'h0800,没有直流偏置则为16'h0000
.result ( ac_sig[:] )//去除直流偏置以后的结果,是16bit补码
); pow_cal i_pow_cal (//平方运算计算信号能量
.dataa ( ac_sig[:] ),
.result ( pow_sig[:] )
); shft_reg i_shft_reg (//例化移位寄存器
.clock ( start ),
.shiftin ( pow_sig[:] ),
.shiftout ( shiftout[:] ),
.taps ( )
);
sub_add sub_add_inst (//减法器,用送入累加结果的数减去要从累加结果中拿出的数,结果有可能是负数
//减完后再送入累加器,以实现累加器内容的维护:最近64个数的和
.dataa ( pow_sig[:] ),
.datab ( shiftout[:]),
.result ( acc_in[:] )
);
////////计算最近64个数的和/////////
always @ (posedge start or negedge rst_n)
begin
if(!rst_n)
acc_out[:] <= 'd0;
else begin
acc_out[:] = $signed(acc_out[:]) + $signed(acc_in[:]);
end
end
///////对累加和开方,提高小信号的分辨率
ip_sqrt ip_sqrt_inst (
.radical ( acc_out[:] ),
.q ( data_out[:] ),
.remainder ( )
);
endmodule
上述顶层设计文件中大部分内容是各个功能模块电路的例化和连接语句,由于代码注释很详细,具体细节就不在这里赘述了,我主要介绍以下几点:
1、 其中只有唯一的一个always过程赋值语句,该语句维护了计数器cnt[15:0]的工作。总的同步启动信号start产生在cnt[15:0]为某些具体值的时候,因此cnt[15:0]技术的周期也决定了start信号产生的周期,也就是信号的周期。
2、正如我在本系列的准备篇“用Verilog-HDL状态机控制硬件接口”所介绍的,使用A/D和D/A进行FPGA算法调试的优势在于:可以将算法中各个中间节点上的信号通过D/A转换器呈现出来。代码中对data_cha[11:0]和data_chb[11:0]的赋值操作有大量的可选注释,正是由于这个原因预留的。
3、每个卷积节CONV_SER16的例化代码中,接口wr_coe_addr是系数存储器的初始化写入地址(关于系数存储器初始化部分的内容,请参见本系列博文第二篇“互相关/卷积/FIR电路的实现”中的描述)。但连接时wr_coe_addr却对系数初始化器的输出的地址wr_blk_addr取反,原因是每个卷积节在执行卷积时首先和输入进行乘加的是地址较大的系数存储器中的内容,因此地址应进行翻转。否则存储在系数初始化池中的完整系数序列,将在每个卷积节中发生翻转,从而无法产生正确结果。
四、测试结果
Quartus-II中针对Cyclone-I的FPGA综合的结果如下图所示。

图5 综合、布局和布线的结果
用matlab产生6正弦周期,长度为60个采样点的信号,在前后各补2个0,从而得到长度为64个采样点的正弦信号。之所以采用60个采样点包含6个正弦周期,是为了模拟5KHz的正弦信号@50KSPS的采样率。最后再为64个采样点加上blackman窗以降低泄露的影响。
图6 理想的目标反射回波信号
我将该信号下载到是德科技任意信号发生器33521中,用手动触发方式让33521产生上图所示的波形,以模拟理论回波信号。将其连接到FPGA平台的A/D输入端,将处理结果从FPGA平台的D/A输出。用示波器观测输入和处理结果如下图所示。
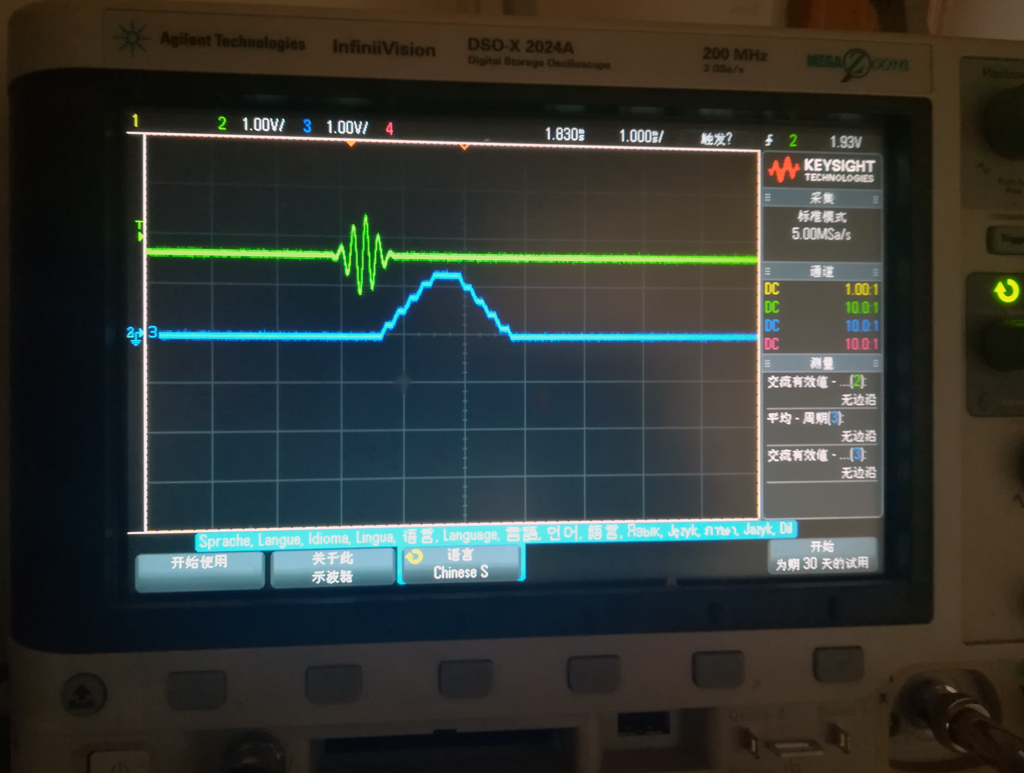
图7 实测处理结果
由上图可知FPGA中的算法实现了本系列博文第一篇中matlab理论仿真的输出波形,能够满足目标反射回波检测算法的要求。蓝色卷积结果的延时是由于FPGA算法的潜伏期造成的,不影响系统的实时性。
当然这里完成的只是一个算法验证性的实验,若要真正使用,还需要将A/D和D/A转换的速度进一步提高。
关于目标回波检测算法原理及实现步骤过程,请从本系列博文的开头开始浏览【目标反射回波检测算法及其FPGA实现 之一:算法概述】。
目标反射回波检测算法及其FPGA实现 之三:平方、积分电路及算法的顶层实现的更多相关文章
- 目标反射回波检测算法及其FPGA实现 之二:互相关/卷积/FIR电路的实现
目标反射回波检测算法及其FPGA实现之二: 互相关/卷积/FIR电路的实现 前段时间,接触了一个声呐目标反射回波检测的项目.声呐接收机要实现的核心功能是在含有大量噪声的反射回波中,识别出发射机发出的激 ...
- 目标反射回波检测算法及其FPGA实现(准备篇): 用Verilog-HDL状态机控制硬件接口
基于FPGA的目标反射回波检测算法及其实现(准备篇) :用Verilog-HDL状态机控制硬件接口 前段时间,开发了一个简单的目标反射回波信号识别算法,我会分几篇文章分享这个基于FPGA的回波识别算法 ...
- 目标反射回波检测算法及其FPGA实现 之一:算法概述
目标反射回波检测算法及其FPGA实现之一:算法概述 前段时间,接触了一个声呐目标反射回波检测的项目.声呐接收机要实现的核心功能是在含有大量噪声的反射回波中,识别出发射机发出的激励信号的回波.我会分几篇 ...
- bresenham算法的FPGA的实现2
在上一篇里http://www.cnblogs.com/sepeng/p/4045593.html <bresenham算法的FPGA的实现1>已经做了一个整体框架的布局,但是那个程序只是 ...
- 基于dsp_builder的算法在FPGA上的实现(转自https://www.cnblogs.com/sunev/archive/2012/11/17/2774836.html)
一.摘要 结合dsp_builder.matlab.modelsim和quartus ii等软件完成算法的FPGA实现. 二.实验平台 硬件平台:DIY_DE2 软件平台:quartus ii9.0 ...
- 基于dsp_builder的算法在FPGA上的实现
基于dsp_builder的算法在FPGA上的实现 一.摘要 结合dsp_builder.matlab.modelsim和quartus ii等软件完成算法的FPGA实现. 二.实验平台 硬件平台 ...
- 大数据DDos检测——DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然! 和一个句子的分词算法CRF没有区别!
DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然!——和一个句子的分词算法CRF没有区别!注:传统DDos检测直接基于IP数据发送流量来识别, ...
- 国密SM4对称算法实现说明(原SMS4无线局域网算法标准)
国密SM4对称算法实现说明(原SMS4无线局域网算法标准) SM4分组密码算法,原名SMS4,国家密码管理局于2012年3月21日发布:http://www.oscca.gov.cn/News/201 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
随机推荐
- CSS 小结笔记之浮动
在css中float是一个非常好用的属性,float最基本用法是用来做文字环绕型的样式的. 基本用法:float:left | right 例如 <!DOCTYPE html> <h ...
- 梯度下降法实现最简单线性回归问题python实现
梯度下降法是非常常见的优化方法,在神经网络的深度学习中更是必会方法,但是直接从深度学习去实现,会比较复杂.本文试图使用梯度下降来优化最简单的LSR线性回归问题,作为进一步学习的基础. import n ...
- font-family:中文字体的英文名称 (宋体 微软雅黑)
宋体 SimSun 黑体 SimHei 微软雅黑 Microsoft YaHei 微软正黑体 Microsoft JhengHei 新宋体 NSimSun 新细明体 PMingLiU 细明体 Ming ...
- Oracle案例13—— OGG-01163 Oracle GoldenGate Delivery for Oracle, reprpt01.prm
由于虚拟机宿主机重启,导致很多虚拟机服务需要重点关注,其中一个DG的从库和另一个report库有OGG同步,所以这里再系统恢复后检查OGG状态的时候,果然目标端的REPLICAT进程处于abend状态 ...
- Redis学习---Redis操作之其他操作
全局有效的其他操作 save 强制将内存/缓存中的key刷到硬盘上 ------------------------------------------------------------------ ...
- 搭建企业级NFS网络文件共享服务[二]
1.1.8 NFS问题总结 1.问:使用showmount -e 127.0.0.1后报clnt_create: RPC: Program not registered错误 答:顺序不对,重启nfs服 ...
- Win10下安装sulley
sulley是一款针对网络协议的fuzz框架,记录下安装过程备忘 1.安装MinGW 下载:https://github.com/develersrl/gccwinbinaries/releases/ ...
- 【websocket-sharp】使用
一 介绍 WebSocket# 提供了实现WebSocket协议客户端和服务器. WebSocket协议是基于TCP的一种新的网络协议.它实现了浏览器与服务器全双工(full-duplex)通信——允 ...
- SQLServer------查询结果为空的列赋默认值
ISNULL(字段,默认值) 如:SELECT ISNULL(name,'无名') FROM [User]
- 【问题记录】centos 开机启动命令未执行
查看日志 /var/log/boot.log 看具体原因,有可能脚本执行有问题, 当你在系统已经启动的时候,脚本执行没问题不代表开机启动能运行