EF基础知识小记七(拆分实体到多个表以及拆分表到多个实体)
一、拆分实体到多个表
1、在日常开发中,会经常碰到一些老系统,当客户提出一些新的需求,这些需求需要在原来的表的基础上加一些字段,大多数人会选择通过给原表添加字段的方式来完成这些需求,方法,虽然可行,但是如果架构不合理的系统,就会牵一发而动全身.所以处理这种需求比较合理的方式是:建一张新表来存放新的字段.
通过叫做合并两张及以上的表到一个单独的实体,也叫分拆一个实体到多个表,我们把每个组成部分当成一个逻辑实体.这个过程叫做逻辑分拆.
缺点:每当获取实体时,框架都需要额外的Join联结.
2、示例
下面通过一个示例简单介绍下逻辑分拆
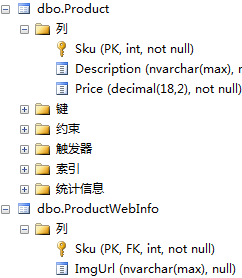
(1)、数据库表设计图

(2)、编写代码
i、确认目标项目导入了EF的相关程序集
ii、创建Product实体,代码如下:
public class Product
{
[Key]
[DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int SKU { get; set; } public string Description { get; set; }
public decimal Price { get; set; }
public string ImgUrl { get; set; }
}
iii、创建数据上下文对象,该对象必须继承DbContext,代码如下:
public class EF6RecipesContext:DbContext
{
public DbSet<Product> Products { get; set; } public EF6RecipesContext():base("name=EF6RecipeEntities")
{
} protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.Entity<Product>()
.Map(m => {
m.Properties(p => new { p.Sku, p.Description, p.Price });
m.ToTable("Product", "dbo");
})
.Map(m => {
m.Properties(p => new { p.Sku, p.ImgUrl });
m.ToTable("ProductWebInfo", "dbo");
});
}
}
iiii、编写测试代码:
using (var context = new EF6RecipesContext())
{
var product = new Product
{
Sku = ,
Description = "啦啦啦",
Price = 1M,
ImgUrl = "1.jpg"
};
context.Products.Add(product);
product = new Product
{
Sku = ,
Description = "哈哈哈",
Price = 2M,
ImgUrl = "2.jpg"
};
context.Products.Add(product);
product = new Product
{
Sku = ,
Description = "呵呵呵",
Price = 3M,
ImgUrl = "3.jp"
};
context.Products.Add(product);
context.SaveChanges();
}
using (var context = new EF6RecipesContext())
{
foreach (var p in context.Products)
{
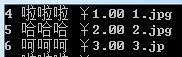
Console.WriteLine("{0} {1} {2} {3}", p.Sku, p.Description,p.Price.ToString("C"), p.ImgUrl);
}
}
Console.ReadKey();
二、拆分一张表到多个实体
假设数据库中有一张表,里面包含一些常用的字段,但是也包含一些不常用的大字段。为了提供系统的性能,需要避免每个查询都去加载这些字段.这个时候我们就需要将表拆分成两个或者更多的实体.
EF基础知识小记七(拆分实体到多个表以及拆分表到多个实体)的更多相关文章
- EF基础知识小记四(数据库=>模型设计器)
EF基础知识小记三(设计器=>数据库)介绍了如何创建一个空设计器模型,并如何将模型同步到数据库的表中,本文则主要介绍如何将一个存在的数据库同步到模型设计器中.为了能快速的模拟这个过程,给出一下建 ...
- EF基础知识小记五(一对多、多对多处理)
本文主要讲EF一对多关系和多对多关系的建立 一.模型设计器 1.一对多关系 右键设计器新增关联 导航属性和外键属性可修改 2.多对多关系 右键设计器新增关联 模型设计完毕之后,根据右键设计器根据模型生 ...
- EF基础知识小记二
1.EF的常用使用场景 (1).维护一个已经存在的数据库,VS提供了工具帮助我们把数据库中的表和视图等对象导入到实体框架. [数据库=>模型(Database First)] (2 ...
- EF基础知识小记一
1.EF等ORM解决方案出现的原因 因为软件开发中分析和解决问题的方法已经接近成熟,然后关系型数据库却没有,很多年来,数据依然是保存在表行列这样的模式里,所以,在面相对象和高度标准化的数据库中产生了一 ...
- EF基础知识小记六(使用Code First建模自引用关系,常用于系统菜单、文件目录等有层级之分的实体)
日常开发中,经常会碰到一些自引用的实体,比如系统菜单.目录实体,这类实体往往自己引用自己,所以我们必须学会使用Code First来建立这一类的模型. 以下是自引用表的数据库关系图: ok,下面开始介 ...
- EF基础知识小记三(设计器=>数据库)
本文主要介绍通过EF的设计器来同步数据库和对应的实体类.并使用生成的实体上下文,来进行简单的增删查该操作 1.通过EF设计器创建一个简单模型 (1).右键目标项目添加新建项 (2).选择ADO.Net ...
- Linq基础知识小记四之操作EF
1.EF简介 EF之于Linq,EF是一种包含Linq功能对象关系映射技术.EF对数据库架构和我们查询的类型进行更好的解耦,使用EF,我们查询的对象不再是C#类,而是更高层的抽象:Entity Dat ...
- Linux基础知识第七讲,用户权限以及用户操作命令
目录 Linux基础知识第七讲,用户权限以及用户操作命令 一丶简介linux用户,用户权限,组的概念. 1.1 基本概念 1.2 组 1.3 ls命令查看权限. 二丶用户权限修改命令 1.chmod ...
- IM开发基础知识补课(七):主流移动端账号登录方式的原理及设计思路
1.引言 在即时通讯网经常能看到各种高大上的高并发.分布式.高性能架构设计方面的文章,平时大家参加的众多开发者大会,主题也都是各种高大上的话题——什么5G啦.AI人工智能啦.什么阿里双11分分钟多少万 ...
随机推荐
- C程序之修改Windows的控制台大小
//change the console size #include <stdio.h> #include<stdlib.h> //必须有 int main(int argc, ...
- hibernate的一级缓存问题
1.证明一级缓存的问题 输出结果: 只发出一条查询语句 第二条查询语句没有执行 因为第一条查询语句缓存的存在 2. 移除缓存: 输出结果: 3.一级缓存的快照 就是对一级缓存的数据备份 保证数据库的 ...
- (最小生成树) Building a Space Station -- POJ -- 2031
链接: http://poj.org/problem?id=2031 Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 6011 ...
- noip第8课作业
1. 计算书费 [问题描述]下面是一个图书的单价表: 计算概论 28.9 元/本 数据结构与算法 32.7 元/本 数字逻辑 45.6元/本 C++程序设计教程 78 元/本 人工智能 35 ...
- hdu 4996 1~n排列LIS值为k个数
http://acm.hdu.edu.cn/showproblem.php?pid=4996 直接贴bc题解 按数字1-N的顺序依次枚举添加的数字,用2N的状态保存在那个min数组中的数字,每次新添加 ...
- js 面向对象 继承机制
根据w3cschool上的描述:共有3种继承方法(对象冒充,原型链,混合) 1.对象冒充:构造函数ClassA使用this关键字给所有属性和方法赋值,使ClassA构造函数成为ClassB的方法,调用 ...
- What is Pay Me to Learn——Google Summer of Code 2013
原文链接:http://zhchbin.github.io/2013/10/17/what-is-pay-me-to-learn/ 背景 今天早上才想起来,自己还欠着一件事情没有做完.很久在人人上之前 ...
- 【转】【译】在 Windows 10 应用程序中注册任意依赖属性的改变
原文地址:http://visuallylocated.com/post/2015/04/01/Registering-to-any-DependencyProperty-changing-in-Wi ...
- Thread in depth 4:Synchronous primitives
There are some synchronization primitives in .NET used to achieve thread synchronization Monitor c# ...
- SQL Server Extended Events 进阶 3:使用Extended Events UI
开始采用Extended Events 最大的阻碍之一是需要使用Xquery和XML知识用来分析数据.创建和运行会话可以用T-SQL完成,但是无论使用什么目标,数据都会被转换为XML.这个限制在SQL ...