mariadb审计日志通过 logstash导入 hive
我们使用的 mariadb, 用的这个审计工具 https://mariadb.com/kb/en/library/mariadb-audit-plugin/
这个工具一点都不考虑后期对数据的处理, 因为他的日志是这样的
20180727 11:40:17,aaa-main-mariadb-bjc-001,user,10.1.111.11,3125928,6493942844,QUERY,account,'select
id, company_id, user_id, department, title, role, create_time, update_time, status,
is_del, receive_email, contact
from company
WHERE ( user_id = 101
and is_del = 0 )',0
所以需要上 logstash 格式化一下
input {
file {
path => ["/data/logs/mariadb/server_audit.log"]
start_position => "end"
codec => multiline {
charset => "ISO-8859-1"
pattern => "^[0-9]{8}"
negate => true
what => "previous"
}
}
}
filter {
if "quartz" in [message] { drop {} }
mutate {
gsub => [
"message", "\s", " ",
"message", "\s+", " "
]
}
dissect {
mapping => {
"message" => "%{ts} %{+ts},%{hostname},%{user},%{dbhost},%{connid},%{queryid},%{operate},%{db},%{object}"
}
}
mutate {
replace => { "message" => "%{ts} %{hostname} %{user} %{dbhost} %{operate} %{db} %{object}" }
}
}
output {
file {
path => "/data/logs/mariadb/%{host}_%{+YYYY-MM-dd_HH}.gz"
gzip => true
codec => line { format => "%{message}" }
}
}
注意 !!!
replace 那个地方各个字段之间我用的 tab 隔开的, 如果用 vim 一定不能写\t, 这在hive中不识别的, 要在 vim 中先按 ctrl+v, 再按 tab
在 vim 中 set list 如下显示才对

mariadb 的审计日志不能按小时切割,上面 logstash 我把日志按小时生成 gz 文件了,后面就是推到 hdfs 中了, 期间试了各种方法
logstash的 output [webhdfs] 效率不行还丢数据
syslog-ng
rsyslog
统统不好用,最终直接使用 hdfs cli简直完美
我把 logstash 的配置和推送到 hdfs 的命令都打到 rpm 里,下面贴一下 rpm SPEC 文件 也记录一下吧
Name: logstash
Version: 1.0.
Release: %{?dist}
Summary: specialize to mysql audit log collection
License: GPL
AutoReqProv: no %define __os_install_post %{nil} %description %prep %build %install
rm -rf $RPM_BUILD_ROOT
mkdir -p %{buildroot}/{apps,etc,usr,var/lib/logstash,var/log/logstash}
cp -r %{_builddir}/etc/* %{buildroot}/etc/
cp -r %{_builddir}/usr/* %{buildroot}/usr/
cp -r %{_builddir}/apps/* %{buildroot}/apps/ %post
chown -R root:root /usr/share/logstash
chown -R root /var/log/logstash
chown -R root:root /var/lib/logstash
chown -R root:root /apps/hadoop-2.6.0
/usr/share/logstash/bin/system-install /etc/logstash/startup.options
cat >> /etc/hosts <<EOF
# for logstash push msyql audit to HDFS
这里填上 hdfs namenode和 datanode 的 hosts
EOF echo "$(shuf -i 3-15 -n 1) * * * *" 'source /etc/profile;/apps/hadoop-2.6.0/bin/hdfs dfs -copyFromLocal /data/logs/mariadb/${HOSTNAME}_$(date -u +"\%Y-\%m-\%d_\%H" -d "last hour").gz hdfs://active_namenode/mysql_audit/$(date -u +"\%Y-\%m-\%d")/ && rm -f /data/logs/mariadb/${HOSTNAME}_$(date -u +"\%Y-\%m-\%d_\%H" -d "last hour").gz' >> /var/spool/cron/root initctl start logstash %files
%defattr(-,root,root)
/apps/hadoop-2.6.0
/etc/logstash
/usr/share/logstash
/var/lib/logstash
/var/log/logstash %preun
if [ $1 -eq 0 ]; then
# Upstart
if [ -r "/etc/init/logstash.conf" ]; then
if [ -f "/sbin/stop" ]; then
/sbin/stop logstash >/dev/null 2>&1 || true
else
/sbin/service logstash stop >/dev/null 2>&1 || true
fi
if [ -f "/etc/init/logstash.conf" ]; then
rm /etc/init/logstash.conf
fi
# SYSV
elif [ -r "/etc/init.d/logstash" ]; then
/sbin/chkconfig --del logstash
if [ -f "/etc/init.d/logstash" ]; then
rm /etc/init.d/logstash
fi
# systemd
else
systemctl stop logstash >/dev/null 2>&1 || true
if [ -f "/etc/systemd/system/logstash-prestart.sh" ]; then
rm /etc/systemd/system/logstash-prestart.sh
fi if [ -f "/etc/systemd/system/logstash.service" ]; then
rm /etc/systemd/system/logstash.service
fi
fi
if getent passwd logstash >/dev/null ; then
userdel logstash
fi if getent group logstash > /dev/null ; then
groupdel logstash
fi
fi %postun %clean
rm -rf $RPM_BUILD_ROOT
我把 hadoop 的程序也放进去了,方便
安装完 rpm 自动启动 logstash 省劲
现在日志已经按天写到 hdfs 中,下面再导入 hive 中
先创建 hive 表
create table mysql_audit(datetime string,hostname string,username string,dbhost string,operation string,db string,object string) partitioned by (dt int,hour smallint,module string) row format delimited fields terminated by '\t';
分了3个 partition
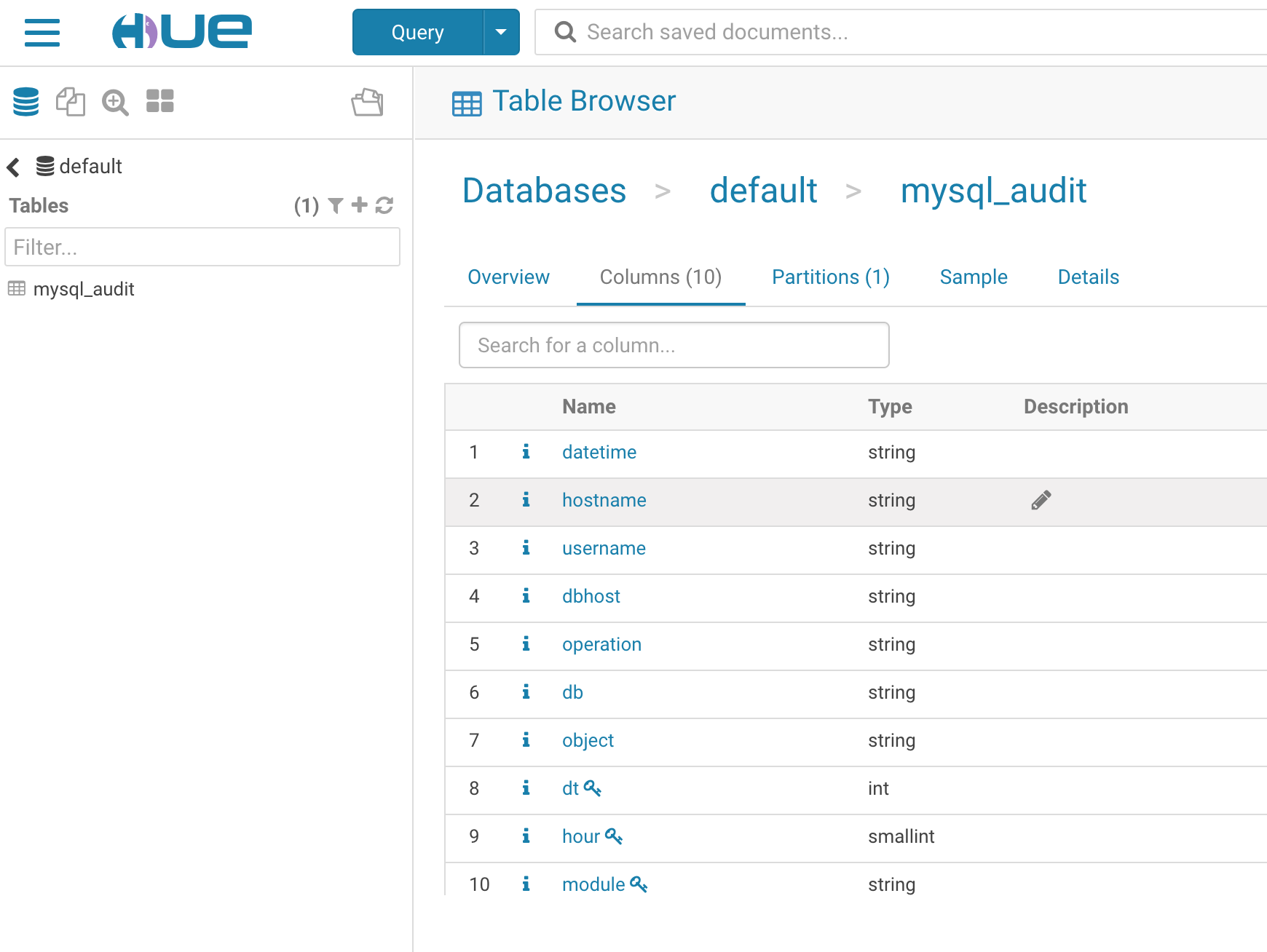
load hdfs to hive
#!/bin/bash
# Description: load hdfs mysql audit gz to hive
# Author : quke
# Date : -- source /root/.bash_profile cur_date=$(date -u +"%Y-%m-%d" -d "last hour")
cur_date_short=$(date -u +"%Y%m%d" -d "last hour")
cur_hour=$(date -u +"%H" -d "last hour") for fn in $(hdfs dfs -ls /mysql_audit/${cur_date}/*_${cur_hour}.gz|awk '{print $NF}');do
host_name=$(echo $fn|awk -F [/_] '{print $(NF-2)}')
module=${host_name%-bjc*}
echo "load data inpath 'hdfs://ossmondb${fn}' into table mysql_audit partition(dt=${cur_date_short},hour=${cur_hour},module='${module}');" >> hive.sql
done hive -f hive.sql && rm -f hive.sql
有任何疑问欢迎交流
mariadb审计日志通过 logstash导入 hive的更多相关文章
- 使用mapreduce清洗简单日志文件并导入hive数据库
Result文件数据说明: Ip:106.39.41.166,(城市) Date:10/Nov/2016:00:01:02 +0800,(日期) Day:10,(天数) Traffic: 54 ,(流 ...
- MariaDB开启日志审计功能
对于MySQL.Percona.MariaDB三家都有自己的审计插件,但是MySQL的审计插件是只有企业版才有的,同时也有很多第三方的的MySQL的审计插件,而Percona和MariaDB都是GPL ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入hive
安装hive 1.下载hive-2.1.1(搭配hadoop版本为2.7.3) 2.解压到文件夹下 /wdcloud/app/hive-2.1.1 3.配置环境变量 4.在mysql上创建元数据库hi ...
- hive-hbase-handler方式导入hive表数据到hbase表中
Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler.jar工具类 : hive-hbase-handler.jar在 ...
- 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
虚拟机: hadoop:3.2.0 hive:3.1.2 win10: eclipse 两阶段数据清洗: (1)第一阶段:把需要的信息从原始日志中提取出来 ip: 199.30.25.88 ti ...
- Atlas2.2.0编译、安装及使用(集成ElasticSearch,导入Hive数据)
1.编译阶段 组件信息: 组件名称 版本 Atals 2.2.0 HBase 2.2.6 Hive 3.1.2 Hadoop 3.1.1 Kafka 2.11_2.4.1 Zookeeper 3.6. ...
- Logstash:使用 Logstash 导入 CSV 文件示例
转载自:https://elasticstack.blog.csdn.net/article/details/114374804 在今天的文章中,我将展示如何使用 file input 结合 mult ...
- ABP(现代ASP.NET样板开发框架)系列之19、ABP应用层——审计日志
点这里进入ABP系列文章总目录 基于DDD的现代ASP.NET开发框架--ABP系列之19.ABP应用层——审计日志 ABP是“ASP.NET Boilerplate Project (ASP.NET ...
- ABP文档 - 审计日志
文档目录 本节内容: 简介 关于 IAuditingStore 配置 通过特性启用/禁用 注意 简介 维基百科:“一个审计追踪(也叫审计日志)是一个安全相关的时序记录.记录组.和/或记录源和目标,作为 ...
随机推荐
- php 事务处理,ActiveMQ的发送消息,与处理消息
可以通过链式发送->处理->发送...的方式处理类似事务型业务逻辑 比如 发送一个注册消息,消息队列处理完注册以后,紧接着发送一个新手优惠券赠送,赠送完再发一个其它后续逻辑处理的消息等待后 ...
- 645. Set Mismatch
static int wing=[]() { std::ios::sync_with_stdio(false); cin.tie(NULL); ; }(); class Solution { publ ...
- [原创汉化] 价值990美元的顶级专业数据恢复软件O&O DiskRecovery 11(技术员版)汉化绿色版
百度没搜索到11有汉化版的,有空就把它汉化了,大部分借鉴的是以前汉化版的词条.另外,顺便做了个二合一的单文件版给有需要的朋友. 运行环境: 可用于 Windows 2000/XP/2003/Vista ...
- [转]关于docker包存储结构说明
原文:http://blog.csdn.net/w412692660/article/details/49005631 前段时间与同事交流docker的安装包层次结构,并沟通相关每个文件的作用,但是一 ...
- Redis配置总结
一:常用配置 1.bind,格式为bind 127.0.0.1:这个是很重要的配置,如果bind 127.0.0.1则外部网络是访问不了的(如果外部网络要访问还要开放端口) 2.port,格式为por ...
- java浅拷贝和深拷贝
转:http://blog.csdn.net/u014727260/article/details/55003402 实现clone的2点: 1,clone方法是Object类的一个方法,所以任何一个 ...
- python3中 for line1 in f1.readlines():,for line1 in f1:,循环读取一个文件夹
循环读取一个文件: fr.seek(0) fr.seek(0, 0) 概述 seek() 方法用于移动文件读取指针到指定位置. 语法 seek() 方法语法如下: fileObject.seek(of ...
- android java层实现hook替换method
Android上的热修复框架 AndFix 大家都很熟悉了,它的原理实际上很简单: 方法替换——Java层的每一个方法在虚拟机实现里面都对应着一个ArtMethod的结构体,只要把原方法的结构体内容替 ...
- hdu 4995 离线处理+模拟
http://acm.hdu.edu.cn/showproblem.php?pid=4995 给定一维坐标下的n个点,以及每个点的权值,有m次查询,每次将查询的x点上的权值修改为离x最近的k个点权值的 ...
- COM是如何实现STA的
Rather than using thread synchronization objects (mutexes, semaphores, and so forth) to control acce ...