Spark RDD 窄依赖研究
1.. 简介
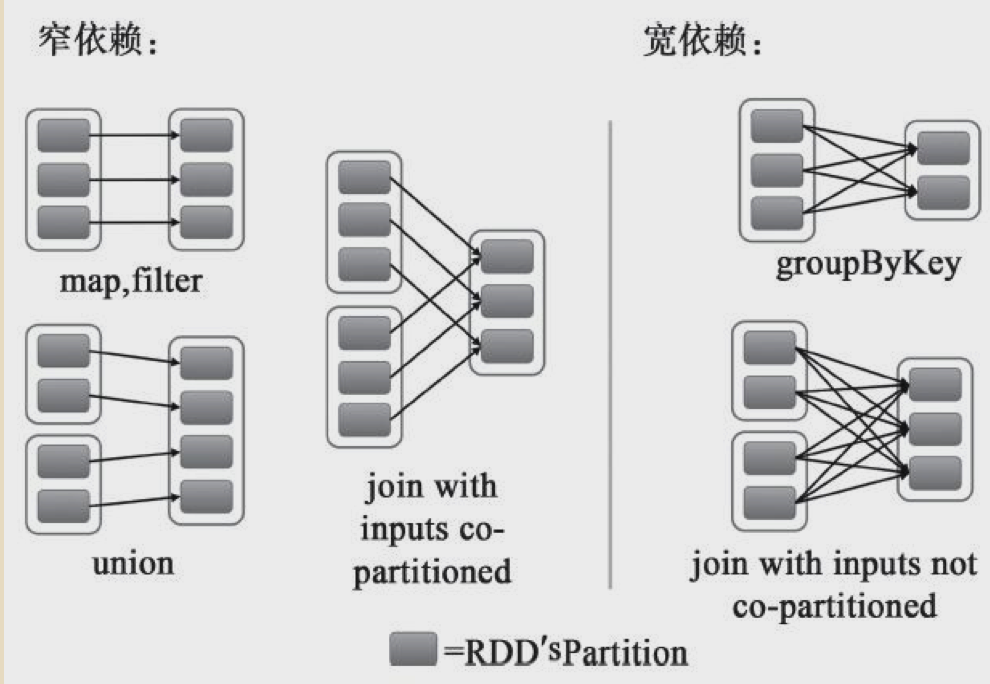
spark从RDD依赖上来说分为窄依赖和宽依赖。
其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依赖。
宽依赖会触发shuffe,宽依赖也是一个job钟不同stage的分界线。
本篇文章主要讨论一下窄依赖的场景。
2.依赖关系的建立
字RDD内部维护着父RDD的依赖关系,下列是依赖的抽象类,其中属性rdd就是父RDD
/**
* :: DeveloperApi ::
* Base class for dependencies.
*/
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
3.窄依赖的三种形式:
窄依赖的抽象类如下:
/**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int] override def rdd: RDD[T] = _rdd
}
窄依赖形式一:MAP,Filter....
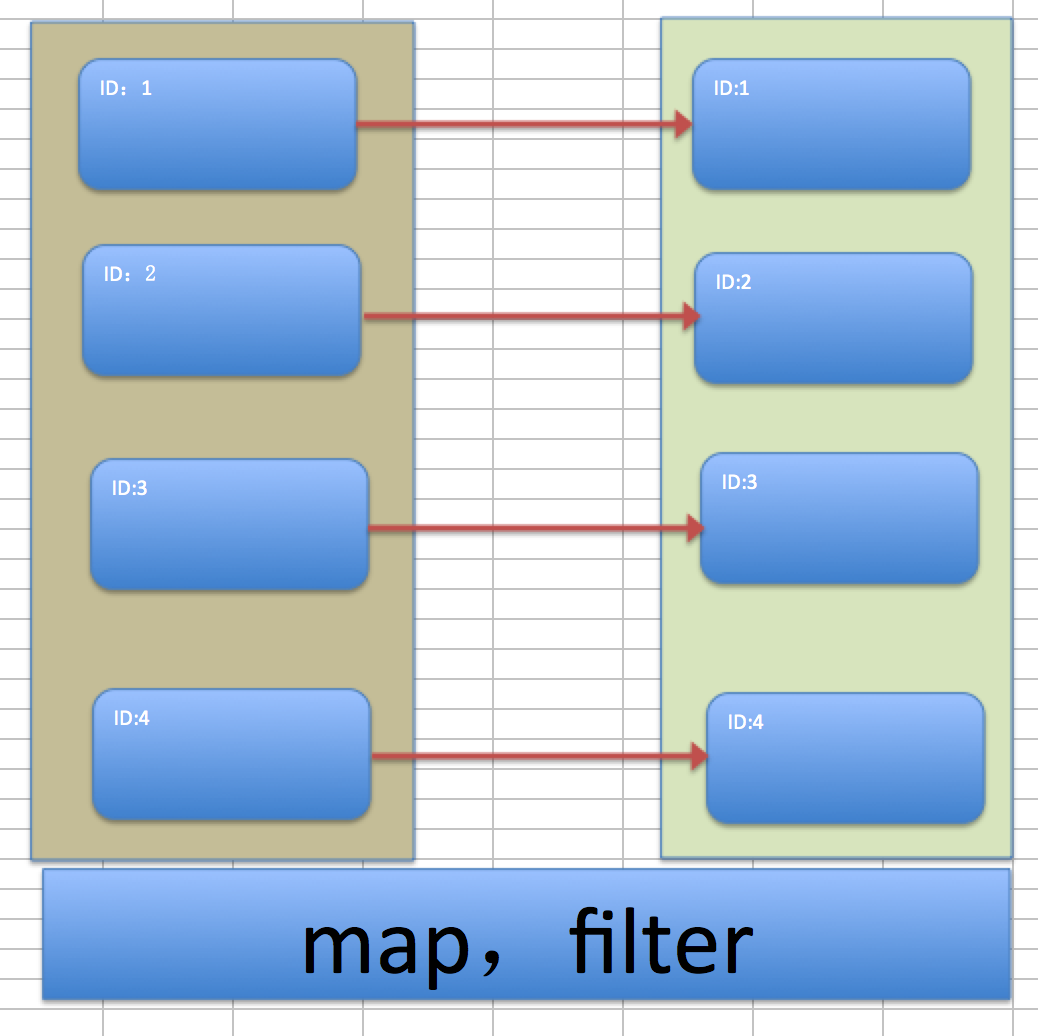
如上两个RDD的转换时通过MAP或者Filter等转换的,RDD的各个partition都是一一对应的,从执行时可以并行化的。
子RDD的分区依赖的父RDD的分区ID是一样不会有变化,这样的窄依赖实现类如下:
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId) //子RDD的某个分区ID是和父RDD的分区ID是一致的
}
窄依赖方式二:UNION
先来看看其实现类:
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
一开始并不好理解上述代码,可参考下图,下图中将各个参数的意义图形化展示:
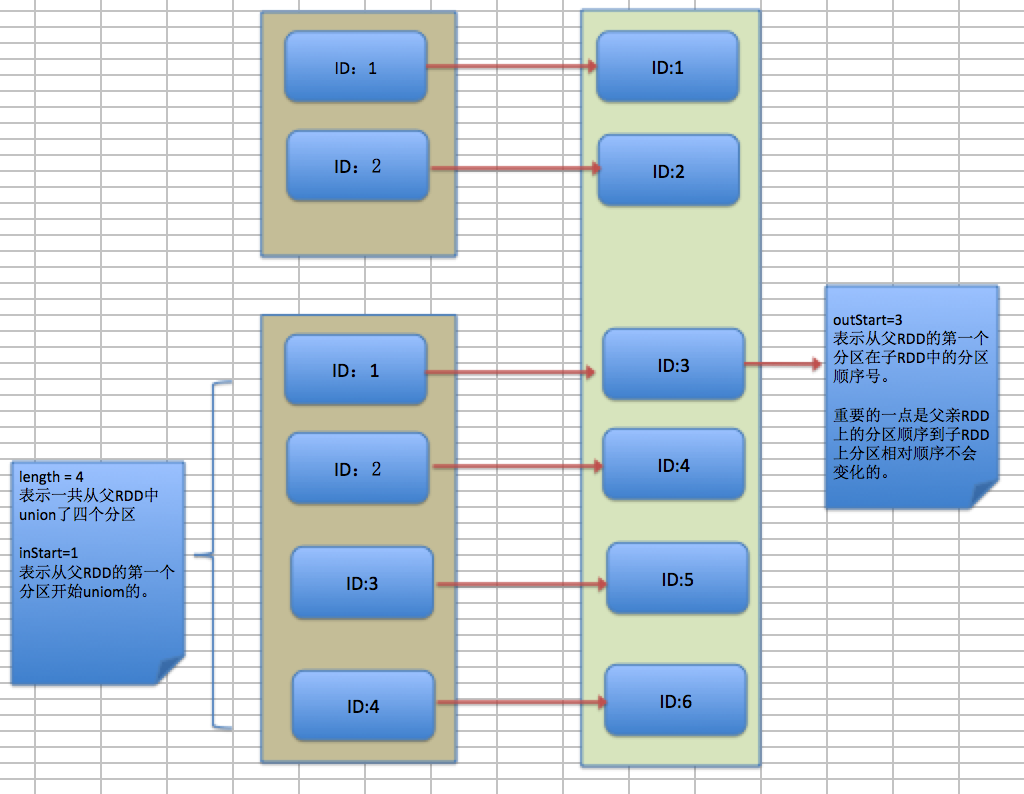
所以上述中子RDD分区中的位号(partitionid)和父RDD的位置号(partitionid)相对的差值 (outStart-inStart)
if (partitionId >= outStart && partitionId < outStart + length) 这段代码的意义:检查当前子RDD分区ID是否在当前父RDD下的范围内
partitionId - outStart + inStart 的意思是:当前子RDD分区id(位置号)与差值相减得出其在父RDD上的分区位置号(id)其实就是:partitionId - (outStart-inStart) 窄依赖方式三:join with inputs co-partitioned
此场景适用于窄依赖方式一。
Spark RDD 窄依赖研究的更多相关文章
- spark rdd 宽窄依赖理解
== 转载 == http://blog.csdn.net/houmou/article/details/52531205 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过 ...
- Spark RDD的依赖解读
在Spark中, RDD是有依赖关系的,这种依赖关系有两种类型 窄依赖(Narrow Dependency) 宽依赖(Wide Dependency) 以下图说明RDD的窄依赖和宽依赖 窄依赖 窄依赖 ...
- Spark RDD 宽窄依赖
RDD 宽窄依赖 RDD之间有一系列的依赖关系, 可分为窄依赖和宽依赖 窄依赖 从 RDD 的 parition 角度来看 父 RRD 的 parition 和 子 RDD 的 parition 之间 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage.划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销. http://spark. ...
- Spark 中的宽依赖和窄依赖
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系.针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow de ...
- Spark Streaming揭秘 Day8 RDD生命周期研究
Spark Streaming揭秘 Day8 RDD生命周期研究 今天让我们进一步深入SparkStreaming中RDD的运行机制.从完整的生命周期角度来说,有三个问题是需要解决的: RDD到底是怎 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
随机推荐
- LEP所需环境
一.LEP所需环境 Python 3.6 Flask Docker 二.Python安装 LEP必须在Python3.6环境下运行,如果是在Python2.7下运行会报以下错误! Python3.6的 ...
- 模板:插头dp
前言: 严格来讲有关dp的都不应该叫做模板,因为dp太活了,但是一是为了整理插头dp的知识,二是插头dp有良好的套路性,所以姑且还叫做模板吧. 这里先推荐一波CDQ的论文和这篇博客http://www ...
- WEB入门.六 盒子模型
学习内容 CSS盒子模型 盒子之间的关系 页面元素定位 能力目标 理解盒子模型 理解内容与表现分离的优点 理解并掌握盒子之间的关系 理解并掌握绝对定位与相对定位的用法 本章简介 上一章节中已经讲解了页 ...
- python之旅:python中range()和len()函数区别
函数:len() 作用:返回字符串.列表.字典.元组等长度 语法:len(str) 参数: str:要计算的字符串.列表.字典.元组等 返回值:字符串.列表.字典.元组等元素的长度 实例 1.计算字符 ...
- R语言缺失值高级处理方法
0 引言 对于一些数据集,不可避免的出现缺失值.对缺失值的处理非常重要,它是我们能否继续进行数据分析的关键,也是能否继续大数据分析的数据基础. 1 缺失值分类 在对缺失数据进行处理前,了解数据缺失的机 ...
- K8S调度之节点亲和性
Node Affinity Affinity 翻译成中文是"亲和性",它对应的是 Anti-Affinity,我们翻译成"互斥".这两个词比较形象,可以把 po ...
- PyQt 5.4参考指南 ---- PyQt5和PyQt4之间的差异
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/in ...
- bzoj千题计划145:bzoj3262: 陌上花开
http://www.lydsy.com/JudgeOnline/problem.php?id=3262 三维偏序 第一维排序,第二维CDQ分治,第三维树状数组 #include<cstdio& ...
- noi题库(noi.openjudge.cn) 3.9数据结构之C++STL T1——T2
T1 1806:词典 描述 你旅游到了一个国外的城市.那里的人们说的外国语言你不能理解.不过幸运的是,你有一本词典可以帮助你. 输入首先输入一个词典,词典中包含不超过100000个词条,每个词条占据一 ...
- java类的定义