ActiveMQ + NodeJS + Stomp 入门
一、需求
移动端系统里有用户和文章,文章可设置权限对部分用户开放。现要实现的功能是,用户浏览自己能看的最新文章,并可以上滑分页查看。
二、数据库表设计
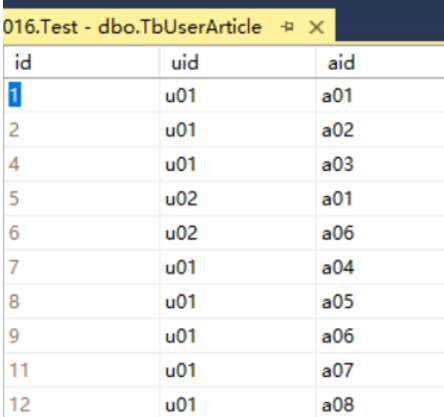
涉及到的数据库表有:用户表TbUser、文章表TbArticle、用户可见文章表TbUserArticle。其中,TbUserArticle的结构和数据如下图,字段有:自增长主键id、用户编号uid、文章编号aid。
自增长主键和分布式增长主键如何选(题外讨论):
TbUserArticle的主键是自增id,它有个缺陷是,当你的数据库有主从复制时,主从库的自增可能因死锁等原因导致不同步。不过,我们可以知道,这里的TbUserArticle的主键id不会用在其它表里,所以可以是自增id。不像用户表的主键,它就不能用自增id,因为用户表主键(uid)会经常出现在其它表中,当主从库自增不一致时,很多有uid字段的表数据在从库中就不正确了。用户表主键最好是用分布式增长主键算法生成的id(比如Snowflake雪花算法)。
那么你可能就要说了,TbUserArticle的主键为什么不直接用雪花算法产生,不管有没有用,先让主从库主键值一致总是有恃无恐。要知道,雪花算法产生的id一般是18位,而redis的zset的score是double类型,只能表达到16位"整数"部分(精确的说是9007199254740992=2的53次方)。因此,TbUserArticle的主键选择自增id。那么能不能产生一个16位(具体是53bit)的分布式增长id用于支持zset的score呢,当然也是可以的,因为目前的雪花算法是可以根据实际系统环境压缩bit位的,怎么压缩bit位呢,有许多方案,以后有需要我可以把它写出来。
建议:主键一般都要选自增id或分布式增长id,这种主键好处多多,它符合自增长(物理存储时都是在末尾追加数据,减少数据移动)、唯一性、长度小、查询快的特性,是聚集索引的很好选择。
三、redis缓存设计-zset
zset的作法及其优点说明:
1.zset的score倒序取数可以很好的满足取最新数据的需求。
2.用TbUserArticle的文章编号当value,用自增长id当score。自增id的唯一性可很方便的取下一页数据,直接取小于上次最后一笔的score即可(用lastScore表示)。而如果用文章的时间做score,则要考虑两笔文章的时间是同分同秒问题,当lastScore落在同分同秒的两篇文章之间时,就尴尬了,虽然有解,但麻烦了一点。有时的场景你用不了自增id当score,只能用文章时间,那怎么解决呢,方案就是当是同分同秒时,再根据文章编号做比较就好了,zset的score相同时,也是再根据value排序的,这块的代码实现请看下文第五点,只需稍微改点代码即可。
3.当新增或重新添加一项时,zset也会保持score排序。而如果用的是redis的list,一般就得从db重载缓存,新增进来的数据项就算是最新的,也不敢直接添加到list第一笔,因为并发情况下,保证不了最新就是在第一笔;至于重新添加进非最新项,那更是要从db取数重新装载缓存(一般是直接删除缓存,要用的时候才装载)。
4.第一次从db加载数据到zset时,可只取前N笔到zset。因为我们移动端的数据浏览,一般是只看最新N笔,当看到昨天浏览过的数据一般就不会再往下浏览。
5.控制zset为固定长度,防止一直增长,一是减少缓存开销,二是队列长度越短操作性能越高。而且redis服务端有两个参数:zset-max-ziplist-entries(zset队列长度,默认值128)和 zset-max-ziplist-value(zset每项大小,默认值64字节),它们的作用是,当zset长度小于128,且每个元素的大小小于64字节时,会启用ziplist(压缩双向链表),它的内存空间可以减少8倍左右,而且操作性能也更快。如果不满足这两个条件则是普通的skiplist(跳跃表)。另,数据结构hash和list默认长度是512。如果系统有100万个用户,每个用户都有自己的队列缓存,那么使用ziplist将节省非常大的内存空间,并提升很大的性能。
注意,当从zset移除一项数据,则看场景是否需要清空队列。否则有可能添加进来了一项很旧的数据,它会跑到缓存队列最底部,如果此旧数据比db中未进队列的数据还旧,那么队列中的数据就不正确了。(此时,用户滑到缓存最后一页时,就有可能浏览到这项不正确的数据,为什么是“有可能”,因为当取到zset最后一笔,很可能不够一页(一页10笔计算的话,90%会取不够一页),而不够一页就会从db直接取一页,从db直接取就不会有这项不正确的数据。而当zset又添加进一项新数据,末端那笔旧数据就会被T出队列(因为队列保持固定长度),zset数据又恢复正确了。不管怎样,这种问题几率虽不高,也是有解决方案,可搞个临界点处理此问题,不细说,否则又是长篇大论,最好的方案就是根据实际场景设计,比如从zset队列移除数据的情况多不多)。而如果添加到zset的数据都是最新数据,则不会有此问题。
当用唯一主键id做score时,这可是非常有用,你可以直接根据id定位到项了,至于如何大用它,我会再出篇博客。
四、代码实现
从redis缓存按页取数一般要考虑的点:
1.当根据cacheKey未取到数据时(可能是缓存过期了导致redis无此cacheKey数据),则触发重载数据(reload):从db取limit N笔数据,装载到redis zset队列中,并直接取N笔的第一页数据返回;
2.如果db本身也无对应数据,则添加"no_db_mark"标识到cacheKey队列中,下次请求则不会再触发db重载数据;
3.当取到缓存末尾时,从db取一页数据直接返回。这种情况是很少的,要根据业务场景合理规划缓存长度。
上代码:
代码注释比较详细和有用,请直接看代码。
其中,批量添加数据到zset的函数AddItemsToZset很有用,它使用lua一次性添加多笔数据到zset(注意,使用lua时,要保证lua执行快,否则它会阻塞其它命令的执行),经测试:AddItemsToZset添加1w笔数据,只需要39ms;10w笔需要448ms。因为我们只取前N笔数据到缓存,因此一般不会添加超过1w笔。
另一个通用有用的函数是GetPageDataByLastScoreFromRedis,它支持从指定的score开始取pageSize笔数据,即支持了zset分页。它是第二页(及之后)的取数,而如果取第一页取数,则直接用redis原生函数即可redis.GetRangeWithScoresFromSortedSetDesc(cacheKey, 0, pageSize - 1);。
/// <summary>
/// 分页取数帮助类
/// </summary>
public class PageDataHelper
{
public readonly static string NoDbDataMark = "no_db_data";//在zset中标识db也无数据
public static RedisHandle RedisClient = new RedisHandle();//redis操作对象示例
public static DbHandleBase DbHandle = new SqlServerHandle("Data Source=.;Initial Catalog=Test;User Id=sa;Password=123ewq;");//db操作对象示例
/// <summary>
/// 按页取数。返回文章编号列表。
/// </summary>
/// <param name="lastInfo">上一页最后一笔的score,如果为空,则说明是取第一页。</param>
/// <param name="getPast">true,用户上滑浏览下一页数据;false,用户上滑浏览最新一页数据</param>
/// <returns>返回key-value列表,key就是文章编号,value就是自增id(可用于lastScore)</returns>
public static IDictionary<string, double> GetUserPageData(string uid, int pageSize, string lastInfo, bool getPast)
{
long lastScore = ;
//1.解析lastInfo信息。->getPast为false,则固定取最新第一页数据,不用解析。lastInfo为空,则也不用解析,默认第一页
if (getPast && !string.IsNullOrWhiteSpace(lastInfo))
{
lastScore = long.Parse(lastInfo);//外层有try..catch..
}
string cacheKey = $"usr:art:{uid}";
bool isFirstPage = lastScore <= ;
using (IRedisClient redis = RedisClient.GetRedisClient())
{
if (isFirstPage)
{
//2.第一页取数
var items = redis.GetRangeWithScoresFromSortedSetDesc(cacheKey, , pageSize - );
if (items.Count == )
{
//2.1 无数据时,则从db reload数据
items = ReloadDataToRedis(redis, cacheKey, uid, pageSize);
if (items.Count == && pageSize > )
{
//如果db中也无数据,则向zset中添加一笔NoDbDataMark标识
redis.AddItemToSortedSet(cacheKey, NoDbDataMark, double.MaxValue);
}
}
else if (items.Count == && items.ContainsKey(NoDbDataMark))
{
//2.2如果取到的是NoDbDataMark标识,则说明是空数据,则要Clear,返回空列表
items.Clear();
}
//设置缓存有效期,要根据业务场景合理设置缓存有效期,这边以7天为例。
redis.ExpireEntryIn(cacheKey, new TimeSpan(, , , ));
//2.3 第一页,有多少就返回多少数据。数据如果不够一页,说明本身数据不够。
return items;
}
else
{
//3.第二页(及之后)取数
var items = GetPageDataByLastScoreFromRedis(redis, cacheKey, pageSize, lastScore);
if (items.Count < pageSize)
{
//3.1 如果取不够数据时,就到db取。如果db也不能取到一页数据,前端会显示无更多数据,不会一直db取。
return GetPageDataByLastScoreFromDb(uid, pageSize, lastScore);
}
//3.2 如果缓存数据足够,则返回缓存的数据。
return items;
}
}
}
public static Dictionary<string, double> ReloadDataToRedis(IRedisClient redis, string cacheKey, string uid, int pageSize, string bizId = "")
{
//1.db取数 取top 1000笔数据。不需要全取到缓存。
IEnumerable<dynamic> models;
using (var conn = DbHandle.CreateConnectionAndOpen())
{
var sql = $"select top 1000 id,aid from TbUserArticle where uid=@uid order by id desc;";// limit 1000;";
models = conn.Query<dynamic>(sql, new { uid = uid });
}
if (models.Count() <= ) return new Dictionary<string, double>();
//2.数据加载到redis缓存。
var itemsParam = new Dictionary<string, double>();
foreach (dynamic model in models)
{
itemsParam.Add((string)model.aid, (double)model.id);
}
//使用lua一次性添加数据到缓存。lua语句要执行快,经测试添加1w笔数据,只需要39ms;10w笔需要448ms。因为sql中有limit,因此一般不会添加超过1w笔。
//因为是原子性操作、并且是zset结构,这边不需要加锁。db取到数据应第一时间加载到redis。
AddItemsToZset(redis, cacheKey, itemsParam, true, true);
if (pageSize <= ) return null;
//3.直接由models返回第一页数据。
return models.Take(pageSize).ToDictionary(x => (string)x.aid, y => (double)y.id);
} public static Dictionary<string, double> GetPageDataByLastScoreFromDb(string uid, int pageSize, double lastScore)
{
//db取一页数据。
var sql = $"select top {pageSize} id,aid from TbUserArticle where uid=@uid and id<{lastScore}order by id desc;";// limit {pageSize};";
using (var conn = DbHandle.CreateConnectionAndOpen())
{
return conn.Query<dynamic>(sql, new { uid = uid }).ToDictionary(x => (string)x.aid, y => (double)y.id);
}
}
#region 通用函数
/// <summary>
/// ZSet第一页之后的取数,从lastScore开始取pageSize笔数据(第一页之后才有lastScore)。
/// 使用lua,保证原子性操作。
/// </summary>
public static Dictionary<string, double> GetPageDataByLastScoreFromRedis(IRedisClient redis, string zsetKey, int pageSize, double lastScore)
{
//ZREVRANGEBYSCORE: from lastScore to '-inf'.
var luaBody = @"local sets = redis.call('ZREVRANGEBYSCORE', KEYS[1], ARGV[1], '-inf', 'WITHSCORES');
local result = {};
local index=0;
local pageSize=ARGV[2]*1;
local lastScore=ARGV[1]*1;
for i = 1, #sets, 2 do
if index>=pageSize then
break;
end
if (lastScore>sets[i+1]*1) then
table.insert(result, sets[i]);
table.insert(result, sets[i+1]);
index=index+1;
end
end
return result";
//ARGV[1]:lastScore ARGV[2]:pageSize
var list = redis.ExecLuaAsList(luaBody, new string[] { zsetKey }, new string[] { lastScore.ToString(), pageSize.ToString() });
var result = new Dictionary<string, double>();
for (var i = ; i < list.Count; i += )
{
result.Add(list[i], Convert.ToDouble(list[i + ]));
}
return result;
}
/// <summary>
/// 添加一项到zset缓存中。
/// </summary>
/// <param name="item">要添加到zset的数据项</param>
/// <param name="maxCount">控制zset最大长度,如果为0,则不控制。</param>
/// <returns></returns>
public static string AddItemToZset(IRedisClient redis, string zsetKey, KeyValuePair<string, double> item, int maxCount = )
{
var items = new Dictionary<string, double>() { { item.Key, item.Value } };
return AddItemsToZset(redis, zsetKey, items);
}
/// <summary>
/// 添加多项到zset缓存中。
/// </summary>
/// <param name="items">要添加到zset的数据列表</param>
/// <param name="hasCacheExpire">缓存zsetKey是否有设置缓存有效期。如果有设置缓存有效期,则当缓存中无数据时,可能是缓存过期;而如果缓存无有效期,缓存中无数据,就是db和缓存都无数据</param>
/// <param name="isReload">是否是reload情况,true重载情况;false追加</param>
/// <param name="maxCount">控制zset最大长度,如果为0,则不控制。</param>
/// <returns></returns>
public static string AddItemsToZset(IRedisClient redis, string zsetKey, Dictionary<string, double> items, bool hasCacheExpire = true
, bool isReload = false, int maxCount = )
{
//!isReload,是因为如果isReload=true情况无数据,则也要进来重载队列为无数据(即,如果之前有数据要重载为无数据)
if (!isReload && items.Count <= ) return null;
var argArr = new List<string>(items.Count * + );//lua参数数组
//var hasCacheExpire = cacheValidTime != null;
//第一个lua参数是hasCacheExpire
argArr.Add(hasCacheExpire ? "" : "");
//第二个lua参数是maxCount
argArr.Add(maxCount.ToString());
//组合lua其它参数列表:ZADD的参数
foreach (var item in items)
{
//Add score。 //ZADD KEY_NAME SCORE1 VALUE1
argArr.Add(item.Value.ToString());
argArr.Add(item.Key);
}
#region lua
/*
* 以下lua命令说明。
* 1.ZREVRANGE从大到小取第一笔数据firstMark;
* 2.缓存有设置有效期时(hasCacheExpire=1),如果第一笔数据firstMark为nil,则说明列表是空(失效key、未生成key),则不做任何处理,直接返回字符串not_exist_key。因为可能是用户失效数据,用户长期未访问,则不添加,后继来访问时重载数据。
* 3.如果firstMark标识为no_db_data,则是被api标识为db没数据,而此时因要ZADD数据进来,因此要把此标识删除。其中,ZREMRANGEBYRANK从小到大删除,-1是倒数第一笔。
* 4.ZADD数据进来
* 5.KeepLength保持队列长度操作。如果队列长度(由ZCARD获取)超过指定的maxCount,则从队列第一笔开始删除多余元素,即score最小开始删除。
* 6.maxCount为>0才KeepLength。返回数值:curCount - maxCount。(可以用返回值简单算出队列当前长度curCount)。如果返回值小于等于0则说明没有触发删除操作。
* 7.maxCount为<=0时,直接返回'no_remove'。
*/
//清空原来,重新加载数据的情况
const string reloadLua = "redis.call('DEL', KEYS[1]) ";
//追加数据到zset的情况
const string addToLua =
@"local firstMark = redis.call('ZREVRANGE',KEYS[1],0,0);
local hasCacheExpire=ARGV[1]*1;
if hasCacheExpire==1 and firstMark and firstMark[1]==nil then
return 'not_exist_key';
end
if firstMark and firstMark[1]=='{0}' then
redis.call('ZREMRANGEBYRANK', KEYS[1], -1,-1);
end";
const string constAllLua =
@"{0}
for i=3, #ARGV, 2
do redis.call('ZADD', KEYS[1], ARGV[i], ARGV[i+1]);
end
local maxCount=ARGV[2]*1;
if maxCount>0 then
local curCount= redis.call('ZCARD', KEYS[1]);
local removeCount=curCount - maxCount;
if removeCount>0 then
redis.call('ZREMRANGEBYRANK', KEYS[1], 0,removeCount-1);
end
return removeCount;
end
return 'no_remove';";
#endregion
var luaBody = string.Format(constAllLua, isReload ? reloadLua : string.Format(addToLua, NoDbDataMark));
var luaResult = redis.ExecLuaAsString(luaBody, new string[] { zsetKey }, argArr.ToArray());
return luaResult;
}
#endregion
}
五、用时间做score,同分同秒问题解决
如果是用时间做score,会有同分同秒问题,比如在TbUserArticle里增加了“时间”栏位。解决方法代码只需稍作微改,参数除了lastScore(此时是“时间”),还需要传lastAid(文章编号)。
1. 缓存处理修改,只动了以下红色粗体字。(注:当zset的两笔数据score相同时,是再根据value排序的):
public static Dictionary<string, double> GetPageDataByLastScoreFromRedis(IRedisClient redis, string zsetKey, int pageSize, double lastScore,string lastAid)
{
//ZREVRANGEBYSCORE: from lastScore to '-inf'.
var luaBody = @"local sets = redis.call('ZREVRANGEBYSCORE', KEYS[1], ARGV[1], '-inf', 'WITHSCORES');
local result = {};
local index=0;
local pageSize=ARGV[2]*1;
local lastScore=ARGV[1]*1;
local lastAid=ARGV[3];
for i = 1, #sets, 2 do
if index>=pageSize then
break;
end
if (lastScore>sets[i+1]*1) or (lastScore==sets[i+1]*1 and lastAid>sets[i]) then
table.insert(result, sets[i]);
table.insert(result, sets[i+1]);
index=index+1;
end
end
return result";
//ARGV[1]:lastScore ARGV[2]:pageSize
var list = redis.ExecLuaAsList(luaBody, new string[] { zsetKey }, new string[] { lastScore.ToString(), pageSize.ToString(), lastAid });
var result = new Dictionary<string, double>();
for (var i = ; i < list.Count; i += )
{
result.Add(list[i], Convert.ToDouble(list[i + ]));
}
return result;
}
2.db取数修改
reload sql
$"select top 1000 时间,aid from TbUserArticle where uid=@uid order by 时间 desc,aid desc;";
db中取一页的sql
$"select top {pageSize} 时间,aid from TbUserArticle where uid=@uid and (时间<{lastScore} or (时间={lastScore} and aid<'{lastAid}')) order by 时间 desc,aid desc;";
这样就可以了,中心思想就是:当“时间={lastScore} ”,那么就增加文章编号比较条件。
转自:https://www.cnblogs.com/michaeldonghan/p/12184975.html
ActiveMQ + NodeJS + Stomp 入门的更多相关文章
- ActiveMQ + NodeJS + Stomp 极简入门
前提 安装ActiveMQ和Nodejs 测试步骤 1.执行bin\win32\activemq.bat启动MQ服务 2. 打开http://localhost:8161/admin/topics.j ...
- ActiveMQ、Stomp、SockJS入门级应用
使用ActiveMQ.Stomp.SockJS实现实时在线聊天 ActiveMQ : 强大的开源即时通讯和集成模式的服务器.在本项目中充当消息代理服务器,stomp协议服务端. 安装:在官网下载,直接 ...
- nodeJS 菜鸟入门
从一个简单的 HTTP 服务开始旅程-- 创建一个 server.js 文件,写入: //最简单的 http 服务例子 var http = require("http"); ht ...
- nodejs快速入门
目录: 编写第一个Node.js程序: 异步式I/O和事件循环: 模块和包: 调试. 1. 编写第一个Node.js程序: Node.js 具有深厚的开源血统,它诞生于托管了许多优秀开源项目的网站—— ...
- ActiveMQ使用STOMP协议的一个错误问题:Unexpected ACK received for message-id
使用某些语言环境下的stomp包(比如php python ruby),可能会出现如下问题: Unexpected ACK received for message-id 这一般可能有两个原因. 1. ...
- 02 nodejs命令参数(NodeJS基础入门)
声明:本文章可供有一定js基础的朋友参考nodejs入门,本文未讲解nodejs的安装,如有需要的同学可以加QQ3382260752找我,进行交流学习. 建议使用开发软件:webstorm或hbuil ...
- ActiveMQ安装与入门程序 & JMS的消息结构
1.Activemq安装 直接到官网下载:记住apache的官网是域名反过来,比如我们找activemq就是activemq.apache.org. 最新版本要求最低的JDK是8,所以最好在电脑装多个 ...
- ActiveMQ专题1: 入门实例
序 好久没有写博客了,最近真的是可以说是忙成狗了.项目的事和自己的终身大事忙得焦头烂额,好在是一切都是越来越好了...... 趁着项目今天唯一的一点喘息时间,加上项目开始接触到的mq,开始写一篇amq ...
- 【NodeJs】入门笔记一
忙乎了两周,把一个后台模型项目完成了,整个过程又进步不少,私喜一下. 暂时可以悠闲两天,又一次把node教程拿出来,每次都看一点点,积少成多吧. 查了很多资料,觉得从<Node入门>开始看 ...
随机推荐
- redis常用命令记录
cd App/opt/redis/bin/ ./redis-cli 1.查看所有key值 keys 前缀* 2.删除指定key值 删除一条 del key全名 删除多条 exit ./redis-cl ...
- CATransition 动画处理视图切换
一:引入包和头文件: 需要在frameworks中添加QuartzCore.framework 在接口程序中加上头文件 #import <QuartzCore/QuartzCore.h& ...
- base64 图片编码之再优化
首先进入网站: http://b64.io/ 最多可减少图片体积容量近70%,建议不要优化base 64 图片格式为gif , 已实测如果用gif的话会增加容量.
- Java从零开始学三(public class和class)
使用public class和class声明的区别 public class文件名称必须与类名称一致 class文件名称可以与类名称不一致
- 【转】Spring中IoC的优点与缺点
1. 优点 我们知道,在Java基本教程中有一个定律告诉我们:所有的对象都必须创建:或者说:使用对象之前必须创建,但是现在我们可以不必一定遵循这个定律了,我们可以从Ioc容器中直接获得一个对象然后直接 ...
- gulp 常用插件汇总
2017-07-26更新:图片压缩插件使用gulp-smushit,gulp-smushit压缩率比较大,gulp-imagemin 图片压缩插件压缩率不明显. 见下图压缩率: 1.gulp安装 参照 ...
- Unix 网络编程 读书笔记3
第四章 基本tcp 套接口编程 注意区分AF_XXX 和PF_XXX,AF代表address family, PF代表protocol family. 1 socket 函数 2 connect 函数 ...
- eclipse 导入tortoiseSVN检出项目,不显示svn信息(eclipse安装svn插件)
eclipse 导入tortoiseSVN检出项目,不显示svn信息(eclipse安装svn插件) CreateTime--2018年5月10日14:10:35 Author:Marydon 1 ...
- maven 创建web项目的标准目录结构
maven 创建web项目的标准目录结构 CreateTime--2018年4月18日21:05:37 Author:Marydon 1.标准目录介绍(开发目录) 2.在eclipse下,目录展示 ...
- 【BIRT】在页面上展示xxxx年xx月xx日
我们在做报表开发的时候经常会遇到一个问题,就是需要在报表上展示”xxxx年xx月xx日”这种日期,例如:需要在报表展示日期如下图: 我们现在数据库存储的日期是:20171231 那么我们如何转化为 这 ...