高并发第九弹:逃不掉的Map --> HashMap,TreeMap,ConcurrentHashMap
平时大家都会经常使用到 Map,面试的时候又经常会遇到问Map的,其中主要就是 ConcurrentHashMap,在说ConcurrentHashMap.我们还是先看一下,
其他两个基础的 Map 类: HashMap 和 TreeMap
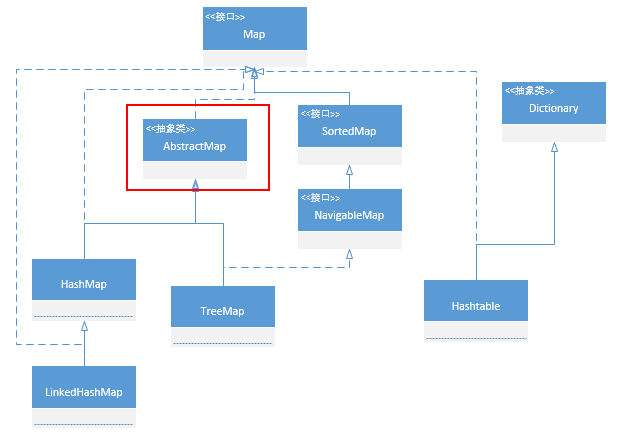
HashMap:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable,Serializable { // 这里有个很逗的事情 hashMap 继承了AvstractMap 为什么还要实现Map? 据说,作者说的 这只是个错误的写法 Q_Q
TreeMap:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable public interface NavigableMap<K,V> extends SortedMap<K,V>
| 实现 | 存储 | 遍历 | 性能损耗 | 键值对 | 安全 | 效率 | |
| TreeMap | SortMap接口,基于红黑树 | 默认按键的升序排序 | Iterator遍历是排序的 | 插入、删除 | 键、值都不能为null | 非并发安全Map | 适用于在Map中插入、删除和定位元素 |
| HashMap | 基于哈希散列表实现 | 随机存储 | Iterator遍历是随机的 | 基本无 | 只允许键、值均为null | 非并发安全Map | 适用于按自然顺序或自定义顺序遍历键(key) |
HashMap通常比TreeMap快一点(树和哈希表的数据结构使然),建议多使用HashMap,在需要排序的Map时候才用TreeMap。
那么现在就聊一下 HashMap和ConcurrentHashMap
我们都知道ConcurrentHashMap 是线程安全的.那为什么HashMap就线程不安全了呢?
这里有很不错的解释https://my.oschina.net/hosee/blog/673521
还有一个路径太长了.给个短的 还可以的
总结起来就是:
1. resize死循环
我们都知道HashMap初始容量大小为16,一般来说,当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大。
在rehash的时候,在多线程的时候容易造成环形链表
2.fail-fast
如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这个异常意在提醒开发者及早意识到线程安全问题,具体原因请查看ConcurrentModificationException的原因以及解决措施 看了这个 我觉得需要去修改一下我原来说的CopyAndWriteArrayList 了
ConcurrentHashMap来了.面试以前遇到了很多次
(1)结构 [Java7与Java8不同]
JDK7
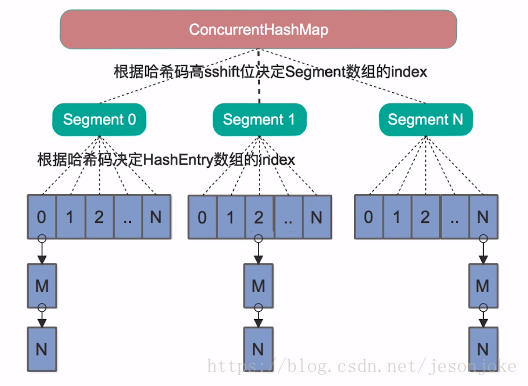
1.ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)
2 . 当我们读取某个Key的时候它先取出key的Hash值,并将Hash值得高sshift位与Segment的个数取模,决定key属于哪个Segment。接着像HashMap一样操作Segment。 为了保证不同的Hash值保存到不同的Segment中,ConcurrentHashMap对Hash值也做了专门的优化。
3. 如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。(文档的说法是根据你并发的线程数量决定,太多会导性能降低)
2. JDK8中的实现
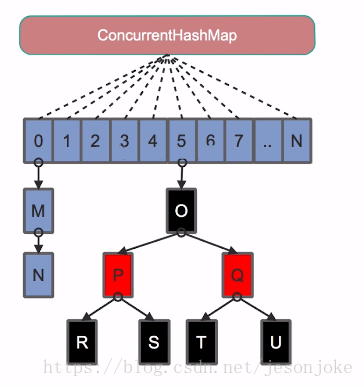
ConcurrentHashMap在JDK8中进行了巨大改动,很需要通过源码来再次学习下Doug Lea的实现方法。
它摒弃了Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法。它沿用了与它同时期的HashMap版本的思想,底层依然由“数组”+链表+红黑树的方式思想(JDK7与JDK8中HashMap的实现),但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。
总结
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
jdk7中ConcurrentHashmap中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能,所以jdk8 中完全重写了concurrentHashmap,代码量从原来的1000多行变成了 6000多 行,实现上也和原来的分段式存储有很大的区别。
主要设计上的变化有以下几点:
- 不采用segment而采用node,锁住node来实现减小锁粒度。
- 设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
- 使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
- sizeCtl的不同值来代表不同含义,起到了控制的作用。
至于为什么JDK8中使用synchronized而不是ReentrantLock,我猜是因为JDK8中对synchronized有了足够的优化吧。
总结:
HashMap非线程安全、ConcurrentHashMap线程安全 (可以看下这个,很有ConcurrentHashMap能完全替代HashTable吗?)
HashMap允许Key与Value为空,ConcurrentHashMap不允许
HashMap不允许通过迭代器遍历的同时修改,ConcurrentHashMap允许。并且更新可见
高并发第九弹:逃不掉的Map --> HashMap,TreeMap,ConcurrentHashMap的更多相关文章
- 高并发第二弹:并发概念及内存模型(JMM)
高并发第二弹:并发概念及内存模型(JMM) 感谢 : 深入Java内存模型 http://www.importnew.com/10589.html, cpu缓存一致性 https://www.cnbl ...
- Java并发指南13:Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析 转自https://www.javadoop.com/post/hashmap#toc7 部分内容转自 http: ...
- 高并发第八弹:J.U.C起航(java.util.concurrent)
java.util.concurrent是JDK自带的一个并发的包主要分为以下5部分: 并发工具类(tools) 显示锁(locks) 原子变量类(aotmic) 并发集合(collections) ...
- 高并发第十一弹:J.U.C -AQS(AbstractQueuedSynchronizer) 组件:Lock,ReentrantLock,ReentrantReadWriteLock,StampedLock
既然说到J.U.C 的AQS(AbstractQueuedSynchronizer) 不说 Lock 是不可能的.不过实话来说,一般 JKD8 以后我一般都不用Lock了.毕竟sychronize ...
- Web大规模高并发请求和抢购的解决方案
电商的秒杀和抢购,对我们来说,都不是一个陌生的东西.然而,从技术的角度来说,这对于Web系统是一个巨大的考验.当一个Web系统,在一秒钟内收到数以万计甚至更多请求时,系统的优化和稳定至关重要.这次我们 ...
- Java 高并发解决方案(电商的秒杀和抢购)
转载:https://blog.csdn.net/icangfeng/article/details/81201575 电商的秒杀和抢购,对我们来说,都不是一个陌生的东西.然而,从技术的角度来说,这对 ...
- 《实战Java高并发程序设计》读书笔记
文章目录 第二章 Java并行程序基础 2.1 线程的基本操作 2.1.1 线程中断 2.1.2 等待(wait)和通知(notify) 2.1.3 等待线程结束(join)和谦让(yield) 2. ...
- 资深P7架构师详解淘宝服务端高并发分布式架构演进之路
1. 概述 本文以淘宝作为例子,介绍从一百个并发到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让大家对架构的演进有一个整体的认知,文章最后汇总了一些架构设计的原则. ...
- 服务端高并发分布式架构演进之路 转载,原文地址:https://segmentfault.com/a/1190000018626163
1. 概述 本文以淘宝作为例子,介绍从一百个到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让大家对架构的演进有一个整体的认知,文章最后汇总了一些架构设计的原则. 特 ...
随机推荐
- hdu5833----高斯消元
题目大意: 给你n个整数,从中选一些数,他们的乘积为一个完全平方数 问有多少种这样的方式,已知这些数的素因素不超过2000. 思路: 一个完全平方数素因素的个数肯定是偶数个. 我们只要从n个数中选取所 ...
- css字体中英速查表
例1(小米米官网):font-family: "Arial","Microsoft YaHei","黑体","宋体",s ...
- 00-python概述。
人生苦短,我用Python. -发展历史: - 1989年,由Guido van Rossum开始开发, - 1991年,发布第一个公开发行版,第一个Python编译器(同时也是解释器)诞生. - 2 ...
- SecurityManager入门
java安全管理器SecurityManager入门 SecurityManager 每个Java应用都可以有自己的安全管理器,它是防范恶意攻击的主要安全卫士. 安全管理器通过执行运行阶段检查和访问授 ...
- 【转】JMeter学习参数化User Defined Variables与User Parameters
偶然发现JMeter中有两个元件(User Defined Variables与User Parameters)很相近,刚开始时我也没注意,两者有什么不同.使用时却发现两者使用场景有些不同,现在小结一 ...
- 解决axios请求本地的json文件在打包后路径出错问题
vue 项目中使用axios请求了本地项目的static文件夹下的json文件,使用npm run build 打包后,在Hbuilder编辑器打开,页面报错404: 在浏览器打开的路径 http:/ ...
- php-echo原理
1.语法分析 unticked_statement: | T_ECHO echo_expr_list ';' ; echo_expr_list: echo_expr_list TSRMLS_CC); ...
- deepin安装Mariadb后,登录时出现ERROR 1045 (28000): Access denied for user 'root'@'localhost'
安装Mariadb的时候设置了root密码,但是登录的时候出现了这样的提示 这里记录下我的处理方法.我是用的如果重置root密码的套路. 首先,在/etc/mysql/mariadb.conf.d/5 ...
- linux 可执行文件与写操作的同步问题
当一个可执行文件已经为write而open时,此时的可执行文件是不允许被执行的.反过来,一个文件正在执行时,它也是不允许同时被write模式而open的.这个约束很好理解,因为文件执行和文件被写应该需 ...
- 再学Java 之 解决No enclosing instance of type * is accessible
深夜,临睡前写了个小程序,出了点小问题 public class Test_drive { public static void main(String[] args){ A a = new A(); ...