学习笔记—MapReduce
MapReduce是什么
MapReduce是一种分布式计算编程框架,是Hadoop主要组成部分之一,可以让用户专注于编写核心逻辑代码,最后以高可靠、高容错的方式在大型集群上并行处理大量数据。
MapReduce的存储
MapReduce的数据是存储在HDFS上的,HDFS也是Hadoop的主要组成部分之一。下边是MapReduce在HDFS上的存储的图解
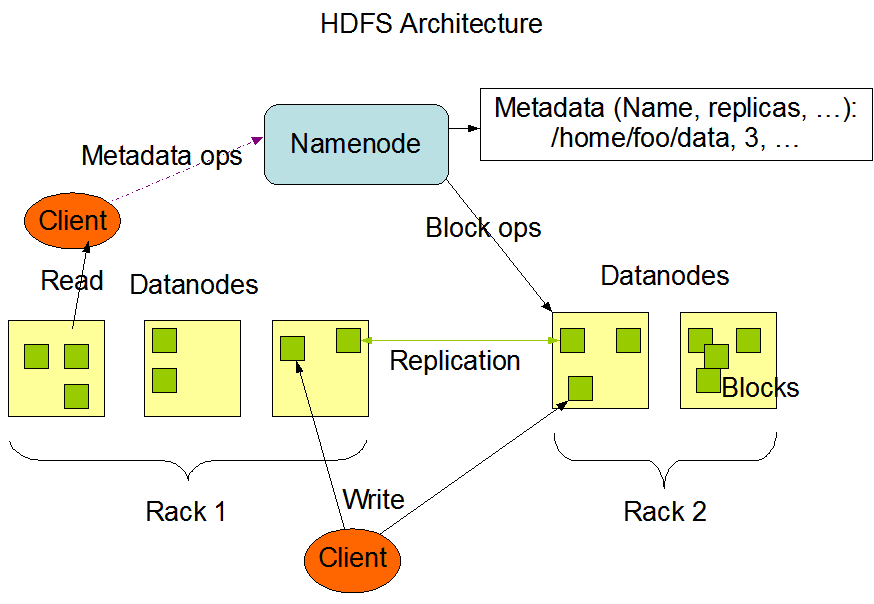
HDFS主要有Namenode和Datanode两部分组成,整个集群有一个Namenode和多个DataNode,通常每一个节点一个DataNode,Namenode的主要功能是用来管理客户端client对数据文件的操作请求和储存数据文件的地址。DataNode主要是用来储存和管理本节点的数据文件。节点内部数据文件被分为一个或多个block块(block默认大小原来是64MB,后来变为128MB),然后这些块储存在一组DataNode中。(这里不对HDFS做过多的介绍,后续会写一篇详细的HDFS笔记)
MapReduce的运行流程


1、首先把需要处理的数据文件上传到HDFS上,然后这些数据会被分为好多个小的分片,然后每个分片对应一个map任务,推荐情况下分片的大小等于block块的大小。然后map的计算结果会暂存到一个内存缓冲区内,该缓冲区默认为100M,等缓存的数据达到一个阈值的时候,默认情况下是80%,然后会在磁盘创建一个文件,开始向文件里边写入数据。
2、map任务的输入数据的格式是<key,value>对的形式,我们也可以自定义自己的<key,value>类型。然后map在往内存缓冲区里写入数据的时候会根据key进行排序,同样溢写到磁盘的文件里的数据也是排好序的,最后map任务结束的时候可能会产生多个数据文件,然后把这些数据文件再根据归并排序合并成一个大的文件。
3、然后每个分片都会经过map任务后产生一个排好序的文件,同样文件的格式也是<key,value>对的形式,然后通过对key进行hash的方式把数据分配到不同的reduce里边去,这样对每个分片的数据进行hash,再把每个分片分配过来的数据进行合并,合并过程中也是不断进行排序的。最后数据经过reduce任务的处理就产生了最后的输出。
4、在我们开发中只需要对中间map和reduce的逻辑进行开发就可以了,中间分片,排序,合并,分配都有MapReduce框架帮我完成了。
MapReduce的资源调度系统
最后我们来看一下MapReduce的资源调度系统Yarn。
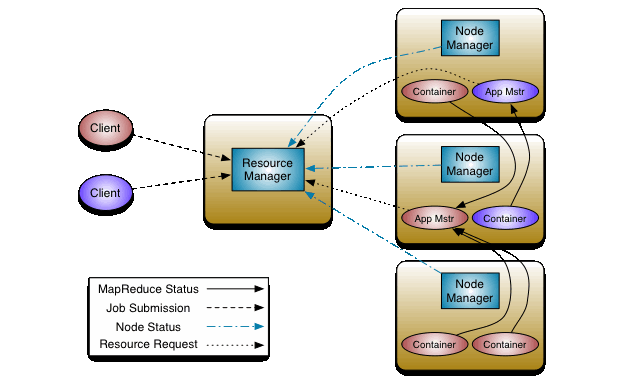
Yarn的基本思想是将资源管理和作业调度/监视的功能分解为单独的守护进程。全局唯一的ResourceManager是负责所有应用程序之间的资源的调度和分配,每个程序有一个ApplicationMaster,ApplicationMaster实际上是一个特定于框架的库,其任务是协调来自ResourceManager的资源,并与NodeManager一起执行和监视任务。NodeManager是每台机器框架代理,监视其资源使用情况(CPU,内存,磁盘,网络)并将其报告给ResourceManager。
WordConut代码
- python实现
map.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
for line in sys.stdin:
words = line.strip().split()
for word in words:
print('%s\t%s' % (word, 1))
reduce.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
current_word = None
sum = 0
for line in sys.stdin:
word, count = line.strip().split(' ')
if current_word == None:
current_word = word
if word != current_word:
print('%s\t%s' % (current_word, sum))
current_word = word
sum = 0
sum += int(count)
print('%s\t%s' % (current_word, sum))
我们先把输入文件上传到HDFS上去
hadoop fs -put /input.txt /
然后在Linux下运行,为了方便我们把命令写成了shell文件
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH="/input.txt"
OUTPUT_FILE_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrush $OUTPUT_FILE_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_FILE_PATH \
-mapper "python map.py" \
-reducer "python reduce.py" \
-file "./map.py" \
-file "./reduce.py"
- java实现
MyMap.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text text = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word: words){
text.set(word);
context.write(text,one);
}
}
}
MyReduce.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i:values){
sum+=i.get();
}
result.set(sum);
context.write(key,result);
}
}
WordCount.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
把工程打成jar包,然后把jar包和输入文件上传到HDfs
$ hadoop fs -put /wordcount.jar /
$ hadoop fs -put /input.txt /
执行wordcount任务
$ bin/hadoop jar wordcount.jar WordCount /input.txt /user/joe/wordcount/output
欢迎关注公众号:「努力给自己看」

学习笔记—MapReduce的更多相关文章
- Hadoop学习笔记—MapReduce的理解
我不喜欢照搬书上的东西,我觉得那样写个blog没多大意义,不如直接把那本书那一页告诉大家,来得省事.我喜欢将我自己的理解.所以我会说说我对于Hadoop对大量数据进行处理的理解.如果有理解不对欢迎批评 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- MongoDB学习笔记~环境搭建
回到目录 Redis学习笔记已经告一段落,Redis仓储也已经实现了,对于key/value结构的redis我更愿意使用它来实现数据集的缓存机制,而对于结构灵活,查询效率高的时候使用redis就有点不 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- 学习笔记:The Log(我所读过的最好的一篇分布式技术文章)
前言 这是一篇学习笔记. 学习的材料来自Jay Kreps的一篇讲Log的博文. 原文很长,但是我坚持看完了,收获颇多,也深深为Jay哥的技术能力.架构能力和对于分布式系统的理解之深刻所折服.同时也因 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
随机推荐
- android studio使用openssl
前言 逆向的基础是开发, 逆向分析时很多时候会使用一些公开的加密函数来对数据进行加密,通过使用 openssl 熟悉下. 正文 首先得先编译出来 openssl,然后把它们复制到你的工程目录下. in ...
- Linux less/more命令详解
less 的用法比起 more 更加的有弹性.在 more 的时候,我们并没有办法向前面翻, 只能往后面看,但若使用了 less 时,就可以使用 [pageup] [pagedown] 等按键的功能来 ...
- Win7如何设置多用户同时远程登录
有时候服务器是Win7系统的时候,远程登录桌面时,即使登录的是不同的管理账号,还是会把远程登录的人给记下来.即不同的账号只能同时存在一个会话窗.本文教大家如果设置Win7让两个账号的两会话同时存在,且 ...
- 第一次项目冲刺(Alpha版本)2017/11/17
一.当天站立式会议 会议内容 1.对数据库的设计的进一步讨论 2.讨论SSH一些配置细节 3.分配今天的任务 二.任务分解图 三.燃尽图 四.心得 刚接触冲刺,一开始任务没有分布很多,大家要一些熟悉的 ...
- 【websocket-sharp】使用
一 介绍 WebSocket# 提供了实现WebSocket协议客户端和服务器. WebSocket协议是基于TCP的一种新的网络协议.它实现了浏览器与服务器全双工(full-duplex)通信——允 ...
- Mina使用总结(三)MinaClient
简单的Mina客户端代码MinaSimpleClient.java: package com.bypay.mina.client; import java.net.InetSocketAddress; ...
- python subprocess 和 multiprocess选择以及我遇到的坑
The subprocess option: subprocess is 用来执行其他的可执行程序的,即执行外部命令. 他是os.fork() 和 os.execve() 的封装. 他启动的进程不会把 ...
- 自定义配置编译linux内核
1 编译linux内核原因一般情况下,我们是不需要重新去编译linux内核的,但如果你发现你需要修改内核的某个部分或者说你需要的某个模块并没有编译进内核,那里你可以通过重新编译内核来满足你的需求,比如 ...
- 20165318 2017-2018-2 《Java程序设计》第三周学习总结
20165318 2017-2018-2 <Java程序设计>第三周学习总结 学习总结 我感觉从这一章开始,新的知识点扑面而来,很多定义都是之前没有接触过的,看书的时候难免有些晦涩.但由于 ...
- 2754. [SCOI2012]喵星球上的点名【后缀数组】
Description a180285幸运地被选做了地球到喵星球的留学生.他发现喵星人在上课前的点名现象非常有趣. 假设课堂上有N个喵星人,每个喵星人的名字由姓和名构成.喵星球上的老师会选择M个串 ...