HBase 架构与工作原理3 - HBase 读写与删除原理
本文系转载,如有侵权,请联系我:likui0913@gmail.com
一、前言
在 HBase 中,Region 是有效性和分布的基本单位,这通常也是我们在维护时能直接操作的最小单位。比如当一个集群的存储在各个节点不均衡时,HMaster 便是通过移动 Region 来达到集群的平衡。或者某一个 Region 的请求过高时,通过分裂 Region 来分散请求。或者我们可以指定 Region 的 startKey 和 endKey 来设计它的数据存放范围等等。
所以,HBase 在读写数据时,都需要先找到对应的 Region,然后再通过具体的 Region 进行实际的数据读写。
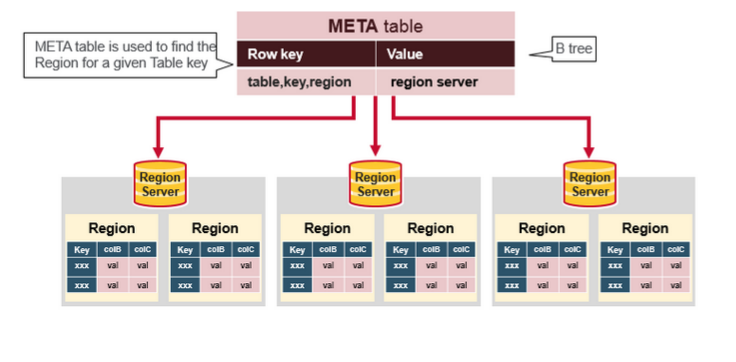
目录表(Catalog Tables)
客户端在访问 Region 中的数据之前,需要先通过 HMaster 确定 Region 的位置,而 HMaster 则将所有 Region 的元信息都保存在 hbase:meta 中。
hbase:meta
Meta 表是一个特殊的 HBase 表,它保存了集群中所有 Region 的列表,它的地址被存储在 Zookeeper 中。其表结构如下:
- RowKey:
- Region Key 格式([table],[region start key],[region id])
- Values:
- info:regionInfo (序列化的.META.的HRegionInfo实例)
- info:server(保存.META.的RegionServer的server:port)
- info:serverStartCode(保存.META.的RegionServer进程的启动时间)
根据 Meta 表中的数据,可以确定客户端所访问的 RowKey 所处的实际位置。
二、读取与缓存元数据(首次读取或写入)
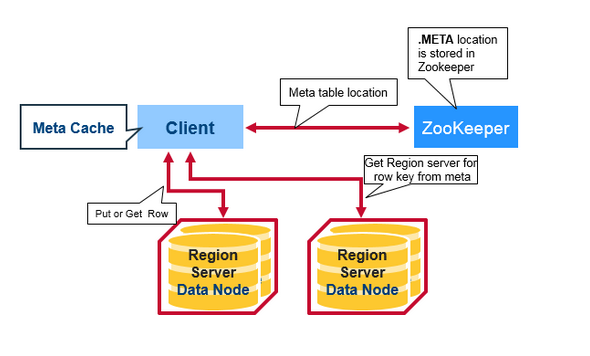
客户端第一次读取或写入 HBase 时将发生以下步骤:
1) 客户端从 Zookeeper 获取存储 META 表的 Region 服务器地址; 2) 客户端查询 META 表所在服务器来获取与想要访问的行键相对应的 RegionServer 地址,然后客户端将这些信息与 META 表位置一起缓存; 3) 客户端从对应的 RegionServer 获取指定行;
对于之后的读取,客户端使用缓存的信息来检索 META 的位置和已经读取过的行键位置信息。随着时间的推移,它将不需要查询 META 表,直到由于某个 Region 已经移动或丢失,客户端才会重新查询并更新缓存。
三、HBase 写入原理
在初次读取写入时,客户端已经缓存了 META 表的信息,同时因为在 HBase 中数据是按行键有序排列的,所以客户端能过通过将要写入数据的行键和缓存信息直接找到对应的 RegionServer 和 Region 位置。那么当客户端发出 Put 请求直到数据真正写入磁盘,它将主要经过以下步骤:
1) 将数据写入预写日志 WAL 2) 写入并排序 MemStore 缓存数据 3) 刷新缓存中的数据,并写入到 HFile磁盘
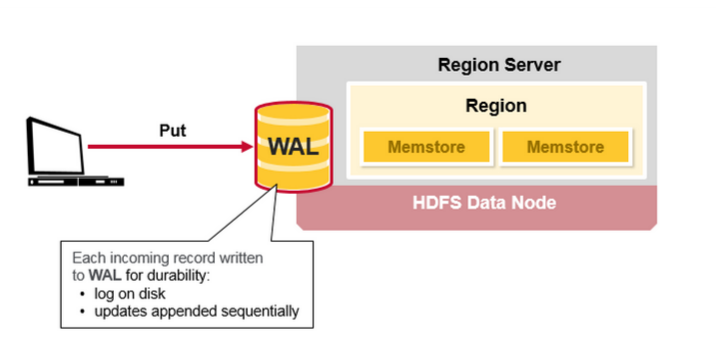
1. 将数据写入预写日志 WAL
当客户端发出 Put 请求时,HBase 首先会将数据写入预写日志:
- 编辑 WAL 文件,将数据附加到 WAL 文件的末尾(满足 HDFS 只允许追加的特性);
- 如果服务器崩溃,那么将通过 WAL 文件恢复尚未保存的数据;
2. 写入并排序 MemStore 缓存数据
一旦数据写入 WAL 成功后,数据将被放入 MemStore 中,然后将 Put 请求确认返回给客户端。客户端接收到确认信息后,对于客户端来说,此次操作便结束了。
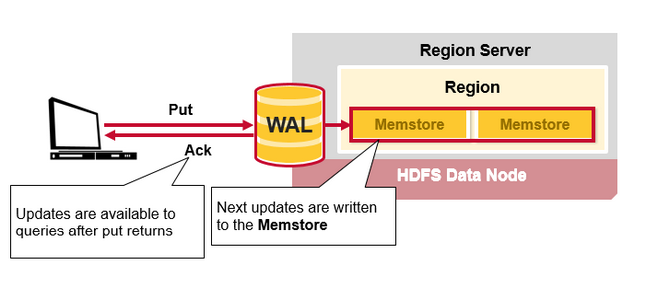
数据放入 MemStore 中后,HBase 不会立即刷新数据到磁盘,而是先更新存储数据使其作为有序的 KeyValues 结构,与存储在 HFile 中的结构相同,并等待 MemStore 累积到足够的数据时才会刷新数据以写入磁盘。
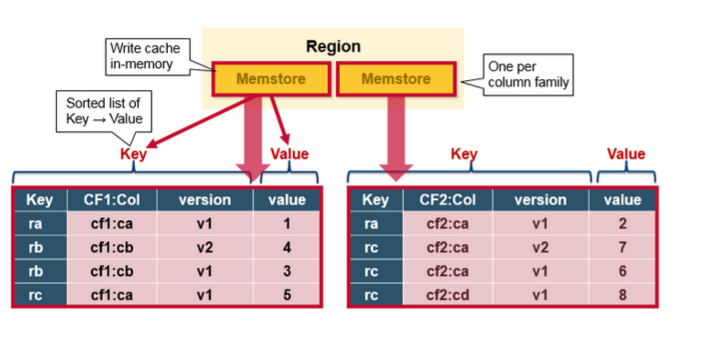
3. 刷新缓存中的数据,并写入到 HFile磁盘
当 MemStore 累积到足够的数据时,整个有序的数据集将被写入 HDFS 中的一个新的 HFile 文件。至此,客户端从发出 Put 请求到数据持久化的过程才算是真正的完成。
可能影响性能的因素
- 因为每一个列族都有一个 MemStore,而当发生刷新时,属于同一个 Region 下的所有 MemStore 都将刷新,这可能导致性能下降,并影响最终的 HFile 文件大小(HDFS 不适合存储小文件),所以列族的数量应该被限制以提高整体效率。
四、HBase 读取原理
根据 HBase 的 RegionServers 的结构可知:在 HBase 中,与一行数据相对应的 KeyValue 单元格可能位于多个位置,比如:行单元格(row cells)已经保存在 HFiles 中,最近更新的单元格位于 MemStore 中,最近读取的单元格位于 BlockCache 中。所以当客户端读取一行数据时,HBase 需要将这些数据合并以得到最新的值。
读取合并
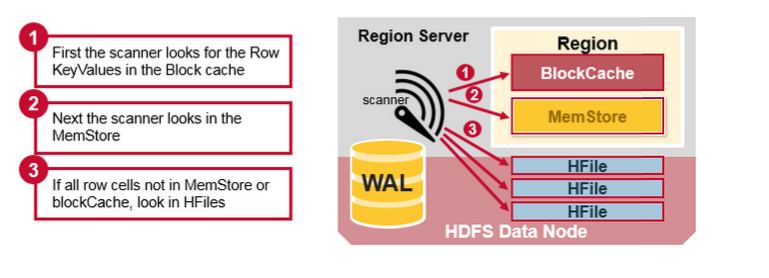
HBase 将通过以下步骤来合并 BlockCache、MemStore 和 HFile 中的数据:
1) 首先,扫描程序查找 BlockCache 中的行单元格(读取缓存)。最近读取的 keyValue 被缓存在这里,并且当需要使用内存时,清除掉最近使用最少的数据; 2) 然后,扫描器在 MemStore 中查找包含最近写入内存中的缓存数据; 3) 如果扫描器在 MemStore 和 BlockCache 中没有找到所有的行单元格,HBase 将使用 BlockCache 索引和 Bloom 过滤器将 HFile 加载到内存中,它可能包含目标行单元格。
注:Bloom 过滤器确定的结果并不一定总是准确的,但是否定的结果却一定保证准确。
可能影响性能的因素
- 刷新数据时,一个 MemStore 可能会产生多个相同的 HFile 文件(为什么会产生多个相同的文件?),这意味着读取时可能需要检查多个文件,这可能会影响性能。这种行为被称为读取放大;
- 客户端使用扫描全表数据操作时,可能会检查更多的文件,所以不建议使用扫描全表操作;
五、HBase 删除原理
HBase 的删除操作并不会立即将数据从磁盘上删除,这主要是因为 HBase 的数据通常被保存在 HDFS 之中,而 HDFS 只允许新增或者追加数据文件,所以删除操作主要是对要被删除的数据打上标记。
HFile 中保存了已经排序过的 KeyValue 数据,KeyValue 类的数据结构如下:
{
keylength,
valuelength,
key: {
rowLength,
row (i.e., the rowkey),
columnfamilylength,
columnfamily,
columnqualifier,
timestamp,
keytype (e.g., Put, Delete, DeleteColumn, DeleteFamily)
}
value
}
当执行删除操作时,HBase 新插入一条相同的 KeyValue 数据,但是使 keytype=Delete,这便意味着数据被删除了,直到发生 Major_compaction 操作时,数据才会被真正的从磁盘上删除。
参考链接
HBase 架构与工作原理3 - HBase 读写与删除原理的更多相关文章
- HBase 架构与工作原理2 - HBase 组件
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.HBase 组件概览 Master-Slave 模式: HBase 体系结构遵循传统的 master-slave 模式,由一 ...
- HBase(三)HBase架构与工作原理
一.系统架构 注意:应该是每一个 RegionServer 就只有一个 HLog,而不是一个 Region 有一个 HLog. 从HBase的架构图上可以看出,HBase中的组件包括Client.Zo ...
- HBase 架构与工作原理4 - 压缩、分裂与故障恢复
本文系转载,如有侵权,请联系我:likui0913@gmail.com Compacation HBase 在读写的过程中,难免会产生无效的数据以及过小的文件,比如:MemStore 在未达到指定大小 ...
- HBase 架构与工作原理1 - HBase 的数据模型
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.应用场景 HBase 与 Google 的 BigTable 极为相似,可以说 HBase 就是根据 BigTable 设计 ...
- HBase 架构与工作原理5 - Region 的部分特性
本文系转载,如有侵权,请联系我:likui0913@gmail.com Region Region 是表格可用性和分布的基本元素,由列族(Column Family)构成的 Store 组成.对象的层 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- Hbase架构与原理(转)
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利 ...
- Hbase架构和读写流程
转载自:http://www.cnblogs.com/muzili-ykt/p/muzili_ykt.html 在HBase读写时,相同Cell(RowKey/ColumnFamily/Column相 ...
- hbase架构和读写过程
转载自:https://www.cnblogs.com/itboys/p/7603634.html 在HBase读写时,相同Cell(RowKey/ColumnFamily/Column相同)并不保证 ...
随机推荐
- Velocity学习3
Velocity快速入门教程 Apache的速度是一个基于Java的的模板引擎(模板引擎),它允许任何人仅仅简单的使用模板语言(模板语言)来引用由java的代码定义的对象. 官网介绍如下: Veloc ...
- AngularJS中Directive指令系列 - bindToController属性的使用
默认false.这个属性用来绑定scope的属性直接赋给controller.可以为true或者和scope相同格式的对象. 此外使用此属性,要设置controller的别名,通常通过"co ...
- 在CentOS上安装Mysql使用yum安装mysql
https://jingyan.baidu.com/article/c74d600079be530f6a595dc3.html
- CSS快速入门-定位布局(九宫格)
实现效果图: 看上去是不是很屌的样子?其实实现起来主要就是用到了一个float,不难. 实现步骤:1.新建一个大div,300*30002.里面放5个小div,100*1003.将div定位
- dbutis事务管理
1.在dao层用dbutils实现事务管理 //从a--->b帐户转100元 public void transfer() throws SQLException{ Connection con ...
- 180918-JDK之Deflater压缩与Inflater解压
JDK 压缩与解压工具类 在实际的应用场景中,特别是对外传输数据时,将原始数据压缩之后丢出去,可以说是非常常见的一个case了,平常倒是没有直接使用JDK原生的压缩工具类,使用Protosutff和K ...
- Centos6.8配置JDK
下载jdk-版本号.tar.gz 解压到/usr/local/ vi /etc/profile 最后一行添加如下内容: export JAVA_HOME=/usr/local/jdk-版本号expor ...
- 007 --MySQL索引底层实现原理
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构.提取句子主干,就可以得到索引的本质:索引是数据结构. 我们知道,数据库查询是数据库的最主要功能之一.我们都希望查 ...
- C++ 单例模式总结与剖析
目录 C++ 单例模式总结与剖析 一.什么是单例 二.C++单例的实现 2.1 基础要点 2.2 C++ 实现单例的几种方式 2.3 单例的模板 三.何时应该使用或者不使用单例 反对单例的理由 参考文 ...
- 单纯形法MATALAB实现
参考单纯形法的步骤,MATALAB中的实现如下(求极小值): 注:对于极大值的求解,只需要对目标函数添加负号,求解出来的\(X\),再带入原目标函数即可. function [ X, z ] = si ...