11-hdfs-NameNode-HA-wtihQJM解决单点故障问题
在hdfs中, NN只有一个, 但其中保存的数据尤其重要, 所以需要将元数据保存, 其中源数据有2个形式, fsimage 和 edit文件, 最简单的解决方法就是复制fsimage, 并在文件修改时同时修改 NNActive 和 NNStandby 中的edit, 保存在第三方的QJM中, 所以多个NN除了active接受用户请求外, 无其他区别
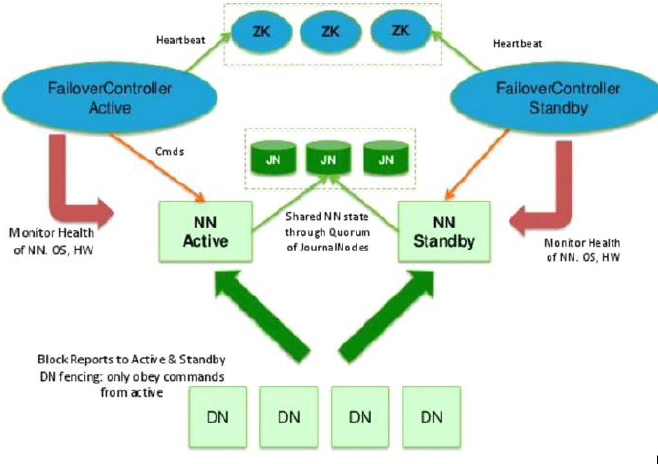
首先是, 集群规划:
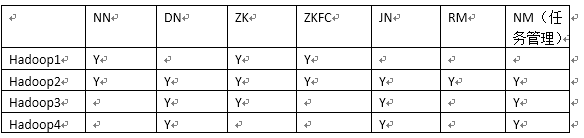
可以看到NN是有1和2组成active和standby的, 之前说过NN需要有DNN免密登录的权限, 所以, 两台分别设置其他三台的免密登录
1, 多台NN间切换, 通过zookeeper来实现的
1) 安装zookeeper.3.4.6.tar.gz, 并创建 conf/zoo.cfg文件
tickTime=
dataDir=/var/lib/zookeeper
clientPort=
initLimit=
syncLimit=
server.=192.168.208.106::
server.=192.168.208.107::
server.=192.168.208.108::
2), 创建data目录和log目录(mkdir -p)
3), 在 ${dataDir}/下面 配置节点信息 myid, 跟上面的server.x保持一致
4), 启动, cd /usr/opt/zookeeper3.4.6/bin
zkServer.sh start
5), 链接内存数据库, 通过get 和ls 等命令可查看数据库中的内容
zkCli.sh
zookeeper启动后, 就不要关闭了...
zk启动脚本:
脚本启动不管用的, 把环境变量配置在 ~/.bashrc下, 因为ssh分为登陆和非登陆, 读取配置文件的顺序不同
#!/bin/bash
host=(node2 node3 node4) start() {
for i in ${host[@]}
do
echo start $i
ssh -o StrictHostKeyChecking=no root@$i "/usr/local/zookeeper-3.4.11/bin/zkServer.sh start"
ssh -o StrictHostKeyChecking=no root@$i "jps"
echo start $i done
done
} stop() {
for i in ${host[@]}
do
echo stop $i
ssh -o StrictHostKeyChecking=no root@$i "/usr/local/zookeeper-3.4.11/bin/zkServer.sh stop"
ssh -o StrictHostKeyChecking=no root@$i "jps"
echo stop $i done
done
} case "$1" in start)
start
;; stop)
stop
;; *)
echo "Usage: start|stop"
;; esac
2, 修改hdfs的配置文件
2.1), 删除masters, 不需要SNN了
rm -rf /usr/opt/hadoop-2.5./etc/hadoop
2.2) 删除原集群中的数据文件
rm -rf /opt/hadoop
2.3) hdfs-site.xml
servername, zookeeper 使用
<property>
<name>dfs.nameservices</name>
<value>hdfscluster</value>
</property>
节点协议( 有几个nameNode定义几个)
<property>
<name>dfs.ha.namenodes.hdfscluster</name>
<value>nn1,nn2</value>
</property>
rpc协议( 文件上传下载使用)
<property>
<name>dfs.namenode.rpc-address.hdfscluster.nn1</name>
<value>192.168.208.106:</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdfscluster.nn2</name>
<value>192.168.208.107:</value>
</property>
http协议
<property>
<name>dfs.namenode.http-address.hdfscluster.nn1</name>
<value>192.168.208.:</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfscluster.nn2</name>
<value>192.168.208.:</value>
</property>
qjm节点, journalNodes节点, 用于缓存edits文件, uri, 分号隔开
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.208.107:8485;192.168.208.108:8485;192.168.208.109:8485/hdfscluster</value>
</property>
帮助客户端获得activeNameNode
<property>
<name>dfs.client.failover.proxy.provider.hdfscluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
远程登陆, 需要ssh密钥文件
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
journalNode 数据存放的目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalNode/data</value>
</property>
2.4) core-site.xml, 修改下入口即可
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfscluster</value>
</property>
3, 启用自动切换
3.1), hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
3.2), core-site.xml, 更改一个配置即可, hadoop.tmp.dir仍然保留
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.208.106:,192.168.208.107:,192.168.208.108:</value>
</property>
4, 启动journalNode
hadoop-daemon.sh start journalnode
查看日志检查是否成功启动
停止: hadoop-daemon.sh stop journalnode
lgos/hadoop-root-journalnode-node4.log
5, 格式化其中一个NN
hdfs namenode -format
6, 拷贝fsimage 到另一台 NN上, 或者手动拷贝过去也可以
#启动刚刚格式化的NN
hadoop-daemon.sh start namenode
#在没有格式化的NN上执行
hdfs namenode -bootstrapStandby
#启动第二个NN
hadoop-daemon.sh start namenode
7, 初始化zookeeper, 在active的NN上执行
hdfs zkfc -formatZK
8, 启动
start-dfs.sh
排错时, 可用jps命令查看集群端口号, 然后kill -9, 或者 killall java
ps: 记得上个博客的配置, slaves等
以后启动时, 先启动3台zookeeper, 然后 start-dfs.sh 即可以了
非常坑, 因为私钥文件root前面没有加 / 表明根目录, 卡了一个小时!!!!
系列来自尚学堂
11-hdfs-NameNode-HA-wtihQJM解决单点故障问题的更多相关文章
- HDFS NameNode HA 部署文档
简介: HDFS High Availability Using the Quorum Journal Manager Hadoop 2.x 中,HDFS 组件有三个角色:NameNode.DataN ...
- Apache hadoop namenode ha和yarn ha ---HDFS高可用性
HDFS高可用性Hadoop HDFS 的两大问题:NameNode单点:虽然有StandbyNameNode,但是冷备方案,达不到高可用--阶段性的合并edits和fsimage,以缩短集群启动的时 ...
- HDFS namenode 高可用(HA)搭建指南 QJM方式 ——本质是多个namenode选举master,用paxos实现一致性
一.HDFS的高可用性 1.概述 本指南提供了一个HDFS的高可用性(HA)功能的概述,以及如何配置和管理HDFS高可用性(HA)集群.本文档假定读者具有对HDFS集群的组件和节点类型具有一定理解.有 ...
- HDFS的HA(高可用)
HDFS的HA(高可用) 概述 (1)实现高可用最关键的策略是[消除单点故障].HA 严格来说应该分成各个组件的 HA 机制:HDFS 的 HA 和 YARN 的 HA. (2)Hadoop2.0 之 ...
- hadoop2—namenode—HA原理详解
在hadoop1中NameNode存在一个单点故障问题,也就是说如果NameNode所在的机器发生故障,那么整个集群就将不可用(hadoop1中有个SecorndaryNameNode,但是它并不是N ...
- CDH4.1基于Quorum-based Journaling的NameNode HA
几个星期前, Cloudera发布了CDH 4.1最新的更新版本,这是第一个真正意义上的独立高可用性HDFS NameNode的hadoop版本,不依赖于特殊的硬件或外部软件.这篇文章从开发者的角度来 ...
- Hadoop2.0 Namenode HA实现方案
Hadoop2.0 Namenode HA实现方案介绍及汇总 基于社区最新release的Hadoop2.2.0版本,调研了hadoop HA方面的内容.hadoop2.0主要的新特性(Hadoop2 ...
- Hadoop2之NameNode HA详解
在Hadoop1中NameNode存在一个单点故障问题,如果NameNode所在的机器发生故障,整个集群就将不可用(Hadoop1中虽然有个SecorndaryNameNode,但是它并不是NameN ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
随机推荐
- EBS R12 探索之路【EBS 经典SQL分享】
http://bbs.erp100.com/thread-251217-1-1.html 1. 查询EBS 系统在线人数 SELECT U.USER_NAME ,APP.APPLICATION_SHO ...
- 在Windows Server 2012 R2域环境中禁用(取消)密码复杂策略
windows server 2012域环境默认启用密码复杂策略,例如: 至少有六个字符长,包含以下四类字符中的三类字符:英文大写字母(A 到 Z),英文小写字母(a 到 z),10 个基本数字(0 ...
- java 执行sql文件
# 背景 用例执行完毕,期望回滚数据,因此希望执行sql来回滚数据 # 步骤 直接show代码,借助的是mybatis的ScriptRunner /** * 执行xx库下的表备份脚本 * * @par ...
- RTOS双向链表数据结构
在学习RTOS操作系统时,在任务优先级设置时用到了双向链表,说实话数据结构的东西只是停留在大学上课阶段,并未实践过,在操作系统中看得云里雾里,遂将其单独拿来了进行了一下思考,经过一个上午的摸索逐渐领会 ...
- 构造回文-C++实现
腾讯2017暑期实习生招聘笔试题……做了一个世纪才做出来 //腾讯2017暑期实习生招聘第一道题.做了一个世纪才做出来………………太菜了 /** 题目: 给定一个字符串s,你可以从中删除一些字符,使得 ...
- AJPFX告诉你MT4平台有什么优势?
FX TERMINAL(Meta Trader4)交易平台功能 成功驾驭金融市场的第一步是拥有正确的工具.AJPFX为客户提供二十四小时的在线交易服务,MT4交易软件是目前全世界上最为先进,应用最为广 ...
- S11 day 97 -98天 Luffycity项目
1. 建模 from django.db import models from django.contrib.contenttypes.fields import GenericForeignKey, ...
- redis惊群
本文链接:http://www.cnblogs.com/zhenghongxin/p/8681168.html 什么是惊群 首先,我们使用缓存的主要目的就是为了高并发情况下的高可用,换句话说,在使用了 ...
- 2018-2019-2 20175306实验三敏捷开发与XP实践《Java开发环境的熟悉》实验报告
2018-2019-2 20175306实验三敏捷开发与XP实践<Java开发环境的熟悉>实验报告 实验内容 XP基础 XP核心实践 相关工具 实验要求 1.没有Linux基础的同学建议先 ...
- 牛客第六场 J.Heritage of skywalkert(On求前k大)
题目传送门:https://www.nowcoder.com/acm/contest/144/J 题意:给一个function,构造n个数,求出其中任意两个的lcm的最大值. 分析:要求最大的lcm, ...