Zookeeper学习之路 (二)集群搭建
ZooKeeper 软件安装须知
鉴于 ZooKeeper 本身的特点,服务器集群的节点数推荐设置为奇数台。我这里我规划为三台, 为别为 hadoop1,hadoop2,hadoop3
ZooKeeper 的集群安装
ZooKeeper 的下载
下载地址:http://mirrors.hust.edu.cn/apache/ZooKeeper/
此处使用的是3.4.10版本
解压安装到自己的目录
[hadoop@hadoop1 ~]$ tar -zxvf zookeeper-3.4.10.tar.gz -C apps/

ZooKeeper 运行最重要的四个东西
修改配置文件
[hadoop@hadoop1 zookeeper-3.4.10]$ cd conf/
[hadoop@hadoop1 conf]$ mv zoo_sample.cfg zoo.cfg
[hadoop@hadoop1 conf]$ vi zoo.cfg
基本配置
tickTime
心跳基本时间单位,毫秒级,ZK基本上所有的时间都是这个时间的整数倍。
initLimit
tickTime的个数,表示在leader选举结束后,followers与leader同步需要的时间,如果followers比较多或者说leader的数据灰常多时,同步时间相应可能会增加,那么这个值也需要相应增加。当然,这个值也是follower和observer在开始同步leader的数据时的最大等待时间(setSoTimeout)
syncLimit
tickTime的个数,这时间容易和上面的时间混淆,它也表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间。
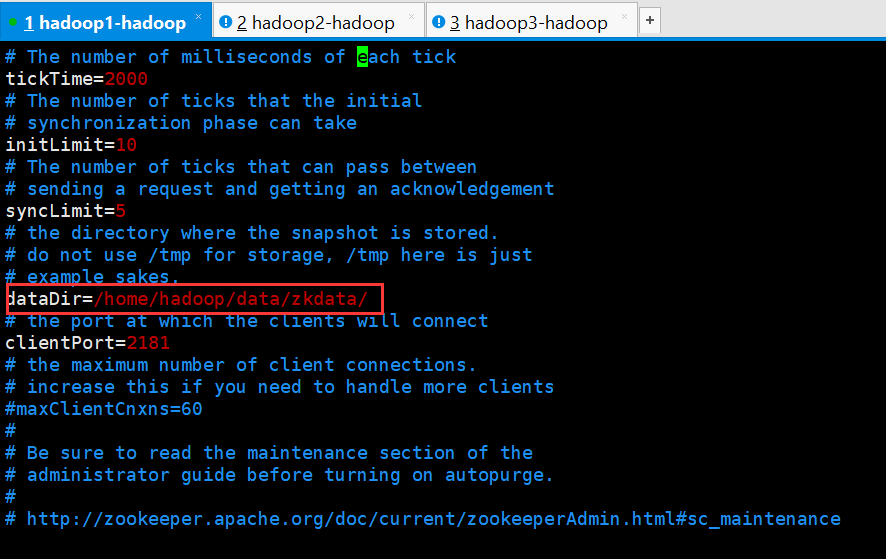
dataDir
内存数据库快照存放地址,如果没有指定事务日志存放地址(dataLogDir),默认也是存放在这个路径下,建议两个地址分开存放到不同的设备上。
clientPort
配置ZK监听客户端连接的端口
在配置文件末尾添加
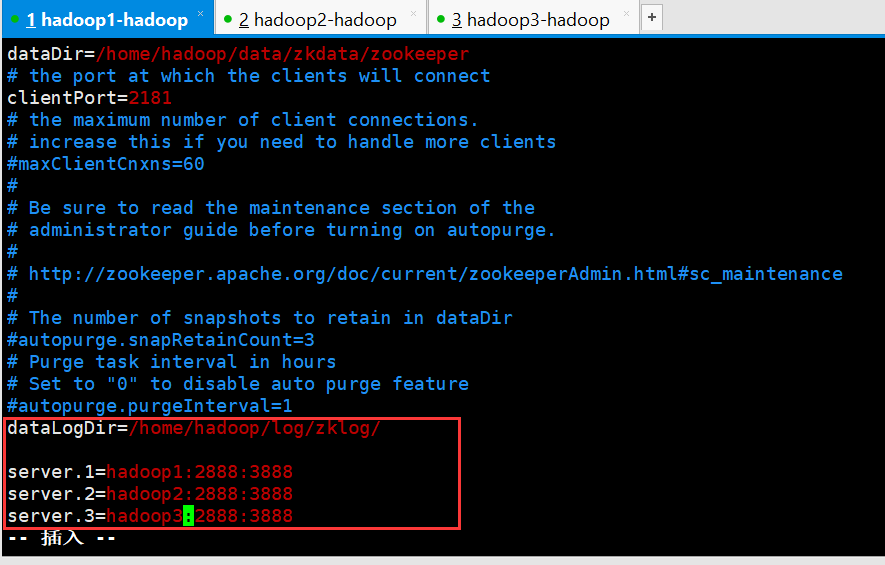
server.serverid=host:tickpot:electionport
server:固定写法
serverid:每个服务器的指定ID(必须处于1-255之间,必须每一台机器不能重复)
host:主机名
tickpot:心跳通信端口
electionport:选举端口
高级配置
dataLogDir
将事务日志存储在该路径下,比较重要,这个日志存储的设备效率会影响ZK的写吞吐量。
globalOutstandingLimit
(Java system property: zookeeper.globalOutstandingLimit)默认值是1000,限定了所有连接到服务器上但是还没有返回响应的请求个数(所有客户端请求的总数,不是连接总数),这个参数是针对单台服务器而言,设定太大可能会导致内存溢出。
preAllocSize
(Java system property: zookeeper.preAllocSize)默认值64M,以KB为单位,预先分配额定空间用于后续transactionlog 写入,每当剩余空间小于4K时,就会又分配64M,如此循环。如果SNAP做得比较频繁(snapCount比较小的时候),那么请减少这个值。
snapCount
(Java system property: zookeeper.snapCount)默认值100,000,当transaction每达到snapCount/2+rand.nextInt(snapCount/2)时,就做一次SNAPSHOT,默认情况下是50,000~100,000条transactionlog就会做一次,之所以用随机数是为了避免所有服务器可能在同一时间做snapshot.
traceFile (Java system property: requestTraceFile)
maxClientCnxns
默认值是10,一个客户端能够连接到同一个服务器上的最大连接数,根据IP来区分。如果设置为0,表示没有任何限制。设置该值一方面是为了防止DoS攻击。
clientPortAddress
与clientPort匹配,表示某个IP地址,如果服务器有多个网络接口(多个IP地址),如果没有设置这个属性,则clientPort会绑定到所有IP地址上,否则只绑定到该设置的IP地址上。
minSessionTimeout
最小的session time时间,默认值是2个tick time,客户端设置的session time 如果小于这个值,则会被强制协调为这个最小值。
maxSessionTimeout
最大的session time 时间,默认值是20个tick time. ,客户端设置的session time 如果大于这个值,则会被强制协调为这个最大值。
集群配置选项
electionAlg
领导选举算法,默认是3(fast leader election,基于TCP),0表示leader选举算法(基于UDP),1表示非授权快速选举算法(基于UDP),2表示授权快速选举算法(基于UDP),目前1和2算法都没有应用,不建议使用,0算法未来也可能会被干掉,只保留3(fast leader election)算法,因此最好直接使用默认就好。
initLimit
tickTime的个数,表示在leader选举结束后,followers与leader同步需要的时间,如果followers比较多或者说leader的数据灰常多时,同步时间相应可能会增加,那么这个值也需要相应增加。当然,这个值也是follower和observer在开始同步leader的数据时的最大等待时间(setSoTimeout)
syncLimit
tickTime的个数,这时间容易和上面的时间混淆,它也表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间。
leaderServes
(Java system property: zookeeper.leaderServes) 如果该值不是no,则表示该服务器作为leader时是需要接受客户端连接的。为了获得更高吞吐量,当服务器数三台以上时一般建议设置为no。
cnxTimeout
(Java system property: zookeeper.cnxTimeout) 默认值是5000,单位ms 表示leaderelection时打开连接的超时时间,只用在算法3中。
ZK的不安全配置项
skipACL
(Java systemproperty: zookeeper.skipACL) 默认值是no,忽略所有ACL检查,相当于开放了所有数据权限给任何人。
forceSync
(Java systemproperty: zookeeper.forceSync) 默认值是yes, 表示transactionlog在commit时是否立即写到磁盘上,如果关闭这个选项可能会在断电时丢失信息。
jute.maxbuffer
(Java system property: jute.maxbuffer)默认值0xfffff,单位是KB,表示节点数据最多1M。如果要设置这个值,必须要在所有服务器上都需要设置。
授权认证配置项
DigestAuthenticationProvider.superDigest
(Java system property only: zookeeper.DigestAuthenticationProvider.superDigest) 设置这个值是为了确定一个超级用户,它的值格式为
super:<base64encoded(SHA1(idpassword))> ,一旦当前连接addAuthInfo超级用户验证通过,后续所有操作都不会checkACL.
将配置文件分发到集群其他机器中
[hadoop@hadoop1 apps]$ scp -r zookeeper-3.4.10/ hadoop2:$PWD
[hadoop@hadoop1 apps]$ scp -r zookeeper-3.4.10/ hadoop3:$PWD
然后是最重要的步骤,一定不能忘了。 去你的各个 ZooKeeper 服务器节点,新建目录 dataDir=/home/hadoop/data/zkdata,这个 目录就是你在 zoo.cfg 中配置的 dataDir 的目录,建好之后,在里面新建一个文件,文件 名叫 myid,里面存放的内容就是服务器的 id,就是 server.1=hadoop01:2888:3888 当中的 id, 就是 1,那么对应的每个服务器节点都应该做类似的操作 拿服务器 hadoop1 举例:
[hadoop@hadoop1 ~]$ mkdir /home/hadoop/data/zkdata
[hadoop@hadoop1 ~]$ cd data/zkdata/
[hadoop@hadoop1 zkdata]$ echo 1 > myid
当以上所有步骤都完成时,意味着我们 ZooKeeper 的配置文件相关的修改都做完了。
配置环境变量
[hadoop@hadoop1 ~]$ vi .bashrc
#Zookeeper
export ZOOKEEPER_HOME=/home/hadoop/apps/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
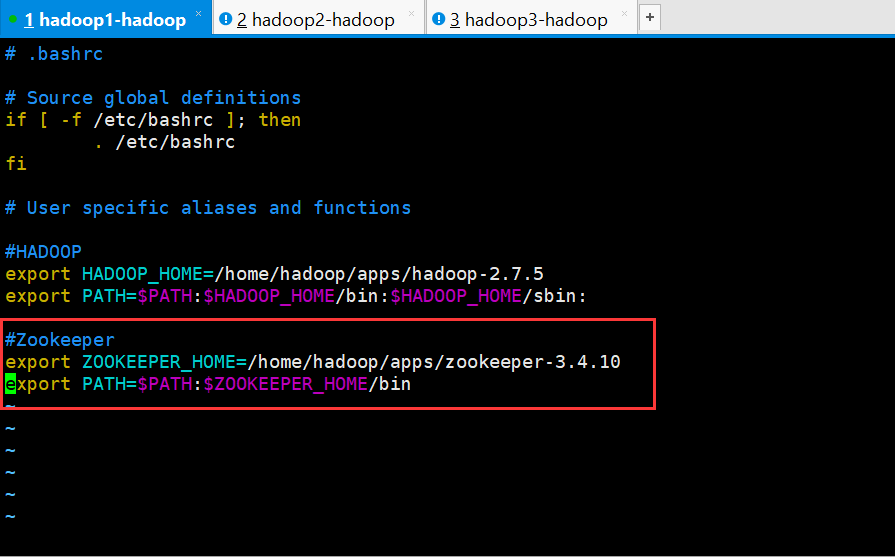
保存退出
[hadoop@hadoop1 ~]$ source .bash
启动软件,并验证安装是否成功
命令
启动:zkServer.sh start
停止:zkServer.sh stop
查看状态:zkServer.sh status
注意:虽然我们在配置文件中写明了服务器的列表信息,但是,我们还是需要去每一台服务 器去启动,不是一键启动集群模式
每启动一台查看一下状态再启动下一台
启动hadoop1
[hadoop@hadoop1 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[hadoop@hadoop1 ~]$
启动hadoop2
[hadoop@hadoop2 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
[hadoop@hadoop2 ~]$
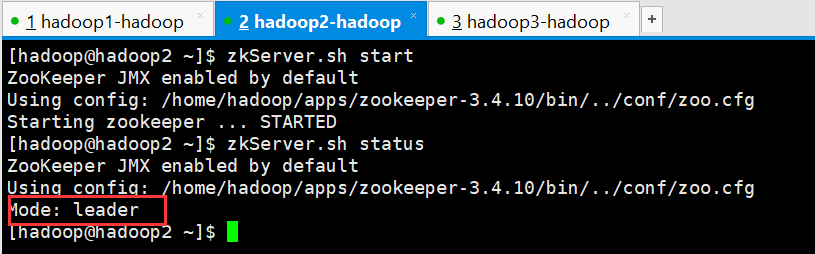
此时在查看hadoop1的状态
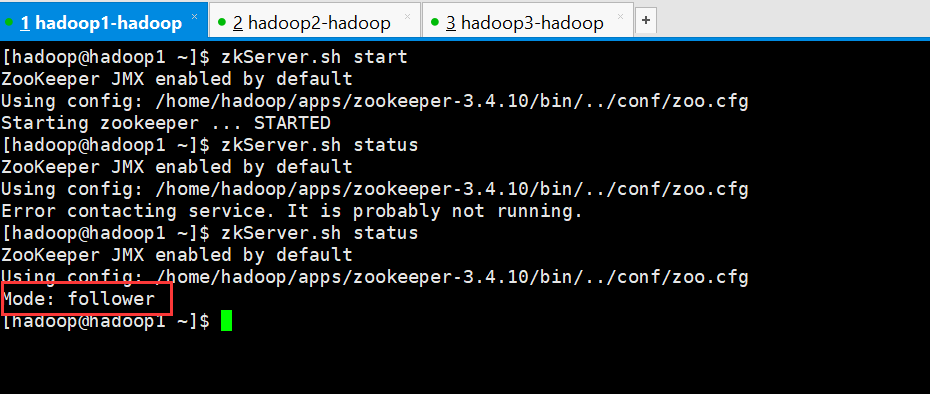
启动hadoop3
[hadoop@hadoop3 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop3 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop3 ~]$
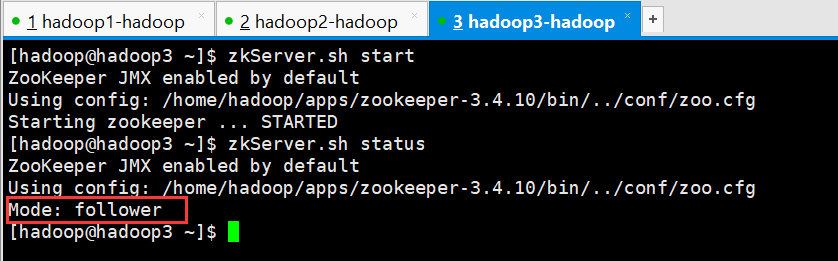
查看进程
3台机器上都有QuorumPeerMain进程
[hadoop@hadoop1 ~]$ jps
2499 Jps
2404 QuorumPeerMain
[hadoop@hadoop1 ~]$
Zookeeper学习之路 (二)集群搭建的更多相关文章
- ZooKeeper学习笔记一:集群搭建
作者:Grey 原文地址:ZooKeeper学习笔记一:集群搭建 说明 单机版的zk安装和运行参考:https://zookeeper.apache.org/doc/r3.6.3/zookeeperS ...
- 28.zookeeper单机(Standalones模式)和集群搭建笔记
zookeeper单机(Standalones模式)和集群搭建: 前奏: (1).zookeeper也可以在windows下使用,和linux一样可以单机也可以集群,具体就是解压zookeeper-3 ...
- ZooKeeper在centos6.4的集群搭建
首先给一个小tips,在搭建zookeeper之前,需要配置好java环境,请参看我的另一篇文章<Jdk1.8在CentOS7中的安装与配置>,还需要免密码登录,请参看我的另一篇文章< ...
- zookeeper与卡夫卡集群搭建
首先这片博客没有任何理论性的东西,只是详细说明kafka与zookeeper集群的搭建过程,需要三台linux服务器. java环境变量设置 zookeeper集群搭建 kafka集群搭建 java环 ...
- redis 学习笔记(6)-cluster集群搭建
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞shardi ...
- 【Spark-core学习之三】 Spark集群搭建 & spark-shell & Master HA
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- spark学习5(hbase集群搭建)
第一步:Hbase安装 hadoop,zookeeper前面都安装好了 将hbase-1.1.3-bin.tar.gz上传到/usr/HBase目录下 [root@spark1 HBase]# chm ...
- spark学习1(hadoop集群搭建)
把原先搭建的集群环境给删除了,自己重新搭建了一次,将笔记整理在这里,方便自己以后查看 第一步:安装主节点spark1 第一个节点:centos虚拟机安装,全名spark1,用户名hadoop,密码12 ...
- redis学习五,redis集群搭建及添加主从节点
redis集群 java架构师项目实战,高并发集群分布式,大数据高可用,视频教程 在redis3.0之前,出现了sentinel工具来监控各个Master的状态(可以看上一篇博客).如果Master异 ...
- Redis Cluster集群搭建与应用
1.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper,但从redis 3.0之后版本支持redis-cluster集群,redis-cluster采用无中心结 ...
随机推荐
- 第一次搭建dns服务器
CentOS 7 搭建DNS服务器 主要参考的是小左先森的一篇博客:https://blog.51cto.com/13525470/2054121. 1.搭建过程中遇到的几个问题说一下: a.在重启服 ...
- 福州大学oj 1752 A^B mod C ===>数论的基本功。位运用。五星*****
Problem 1752 A^B mod C Accept: 579 Submit: 2598Time Limit: 1000 mSec Memory Limit : 32768 KB P ...
- JDBC程序优化--提取配置信息放到属性文件中
JDBC程序优化--提取配置信息放到属性文件中 此处仅仅优化JDBC连接部分,代码如下: public class ConnectionFactory { private static String ...
- Java程序中的死锁
什么是死锁? 死锁是一种特定的程序状态,主要是由于循环依赖导致彼此一直处于等待中,而使得程序陷入僵局,相当尴尬.死锁不仅仅发生在线程之间,而对于资源独占的进程之间同样可能出现死锁.通常来说,我们所说的 ...
- Dubbo安装及其实战1
一.Dubbo安装 (1)安装zk和tomcat yum 安装tomcat 默认路径为 /usr/share/tomcat zookeeper 我这里采用的是使用zookeeper管理的.所以要安装z ...
- sql SUM求和
- Android下用程序的方法为ListView设置分割线Divider样式
使用XML的时候可以使用android:divider属性为ListView设置分割线的样式(颜色或者资源文件),而在Java代码中默认提供的方法 listView.setDivider() 却只支持 ...
- JavaWeb学习总结(十):Session简单使用
一.Session简单介绍 在WEB开发中,服务器可以为每个用户浏览器创建一个会话对象(session对象),注意:一个浏览器独占一个session对象(默认情况下).因此,在需要保存用户数据时,服务 ...
- linux 安装 zookeeper 集群
关闭防火墙 systemctl stop firewalld.service systemctl disable firewalld.servicesystemctl status firewalld ...
- Storm默认配置 default.yaml
default.yaml文件所在位置:apache-storm-0.9.4.tar.gz/apache-storm-0.9.4/lib/storm-core-0.94.jar/default.yaml ...