一个导致MGR数据混乱Bug的分析和修复
1、背景
MGR是个好东西,因为他从本质上解决了数据不一致的问题。不光是解决了问题,而且出自名门正派(Oracle的MySQL团队),对品质和后续的维护,我们是可以期待的。
但是在调研的过程中,发现有个严重的bug(https://bugs.mysql.com/bug.php?id=92690),在网络有延迟、丢包和数据损坏时,会导致各个节点间数据严重不一致。而上述网络情况,在跨地域部署时候,出现的概率还是比较高的,因此,必须解决上述问题。我也一直在等待官方团队的修复(该bug在2018年11月5号被提出,截止到写作这篇文章,已经3个月了),但是一直没有bug fix放出。
2、社区对于该bug的分析
a)相同gtid编号,内容不同
从这个bug submmiter的分析来看,即使是相同的gtid编号,其内容也不相同,甚至操作的表都不一样。
gr01 > show binlog events in 'binlog.000223' from 11590 limit 11;
+---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+
| binlog.000223 | 11590 | Gtid | 10 | 11651 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:295533' |
| binlog.000223 | 11651 | Query | 10 | 11723 | BEGIN |
| binlog.000223 | 11723 | Table_map | 10 | 11775 | table_id: 125 (db1.sbtest6) |
| binlog.000223 | 11775 | Update_rows | 10 | 12185 | table_id: 125 flags: STMT_END_F |
| binlog.000223 | 12185 | Table_map | 10 | 12237 | table_id: 116 (db1.sbtest5) |
| binlog.000223 | 12237 | Update_rows | 10 | 12647 | table_id: 116 flags: STMT_END_F |
| binlog.000223 | 12647 | Table_map | 10 | 12699 | table_id: 118 (db1.sbtest1) |
| binlog.000223 | 12699 | Delete_rows | 10 | 12919 | table_id: 118 flags: STMT_END_F |
| binlog.000223 | 12919 | Table_map | 10 | 12971 | table_id: 118 (db1.sbtest1) |
| binlog.000223 | 12971 | Write_rows | 10 | 13191 | table_id: 118 flags: STMT_END_F |
| binlog.000223 | 13191 | Xid | 10 | 13218 | COMMIT /* xid=6231928 */ |
+---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+
11 rows in set (0.00 sec) gr02 > show binlog events in 'binlog.000221' from 9912 limit 11;
+---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+
| binlog.000221 | 9912 | Gtid | 10 | 9973 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:295533' |
| binlog.000221 | 9973 | Query | 10 | 10037 | BEGIN |
| binlog.000221 | 10037 | Table_map | 10 | 10089 | table_id: 108 (db1.sbtest5) |
| binlog.000221 | 10089 | Update_rows | 10 | 10499 | table_id: 108 flags: STMT_END_F |
| binlog.000221 | 10499 | Table_map | 10 | 10551 | table_id: 110 (db1.sbtest4) |
| binlog.000221 | 10551 | Update_rows | 10 | 10961 | table_id: 110 flags: STMT_END_F |
| binlog.000221 | 10961 | Table_map | 10 | 11014 | table_id: 109 (db1.sbtest10) |
| binlog.000221 | 11014 | Delete_rows | 10 | 11234 | table_id: 109 flags: STMT_END_F |
| binlog.000221 | 11234 | Table_map | 10 | 11287 | table_id: 109 (db1.sbtest10) |
| binlog.000221 | 11287 | Write_rows | 10 | 11507 | table_id: 109 flags: STMT_END_F |
| binlog.000221 | 11507 | Xid | 10 | 11534 | COMMIT /* xid=1185380 */ |
+---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+
11 rows in set (0.00 sec)
b)相同的paxos信息编号,消息类型不同
社区内有人在MGR源码中加入日志,分析出相同编号的paxos信息,在Primary节点上是带有实际的信息(和应用相关的,比如binlog的信息),但是在Secondary节点上是空消息(noop,不会提交给应用)。因此出现了数据不一致。
c)prepare阶段出现问题
注意,这里的prepare和数据库概念无关,而是paxos中的prepare。相关概念参考这篇博客(http://mysqlhighavailability.com/the-king-is-dead-long-live-the-king-our-homegrown-paxos-based-consensus/)。下图中的Election和prepare的含义是一样的。
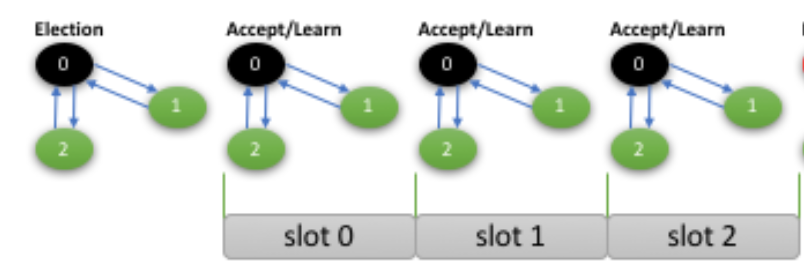
简要来说,任何一个节点在发送一个消息的时候,
1)先发送prepare消息,以确定其要发起提议的值;
2)根据上一步的结果,发送accept信息到各个参与节点;
3)如果收到多数派的回应,则发送learn信息,如果其他节点(比如节点1)收到learn信息,则消息的值,(在节点1)被确认了。
从上面可以看出,一个消息的发送,需要经过3个阶段,不仅产生了较大的网络流量,更糟糕的是整个消息,从被发起到被确认经历了较大延迟。
因此很多paxos的变种,都会试图去优化这个过程。比如在系统运行稳定时,省略了第一步的prepare阶段。但是在系统不稳定时,比如某个节点发现其缺少某个编号的消息时,会走完整的三阶段。
而该bug正好就是在网络很糟糕的情况下出现,因此有很大可能性就是prepare阶段出现了问题。
3、相关概念补充
a)节点编号
每个节点都有一个编号。比如一个MGR集群,有三个节点,那么其编号就分别是0,1,2。其中编号的大小与是否为Primary无关
b)消息编号
消息编号由两部分组成,第一部分是64位的无符号数,一般是递增的,另一部分是节点编号。
比如(10064,0)就是一个消息编号
c)投票号
投票号也是由两个部分组成,第一部分是32位的有符号数,另一部分也是节点编号。
4、笔者分析
a)分析方法
之前所熟悉和擅长的方法,尤其是调试方式上,在分布式系统中显得力不从心。比如在研发智能SQL优化器时,利用gdb,帮助我了解了很多优化器的细节。但是对于分布式系统来说,一旦使用gdb挂载,可能会对其行为产生影响。因此笔者采用,以日志为主,gdb为辅的调试方法
b)paxos消息分析
1)结果正确、网络正常
节点编号:0,Primary节点
in push_msg_2p msg_no 1683, 0
in dispatch_op msg_no 1683, 0, paxos op accept_op from : 0 to : 0
in dispatch_op msg_no 1683, 0, paxos op ack_accept_op from : 0 to : 0
in dispatch_op msg_no 1683, 0, paxos op ack_accept_op from : 2 to : 0
in dispatch_op msg_no 1683, 0, paxos op tiny_learn_op from : 0 to : 0
in dispatch_op msg_no 1683, 0, paxos op ack_accept_op from : 1 to : 0
msg_no 1683, 0 cargo_type : app_type , msg_type : normal, pax_op : learn_op
节点编号:2,Secondary节点
in dispatch_op msg_no 1683, 0, paxos op accept_op from : 0 to : 2
in dispatch_op msg_no 1683, 0, paxos op tiny_learn_op from : 0 to : 2
msg_no 1683, 0 cargo_type : app_type , msg_type : normal, pax_op : learn_op
节点编号:1,Secondary节点
in dispatch_op msg_no 1683, 0, paxos op accept_op from : 0 to : 1
in dispatch_op msg_no 1683, 0, paxos op tiny_learn_op from : 0 to : 1
msg_no 1683, 0 cargo_type : app_type , msg_type : normal, pax_op : learn_op
分析:
A)0号节点发送编号为(1683,0)的消息
in push_msg_2p msg_no ,
B)0,1、2号节点均收到accept_op
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op accept_op from : to :
C)0,1、2号节点均回复ack_accept_ok
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
注意到0号节点在收到2个ack_accept_ok(大多数)时,就开始发送tiny_learn_op,其中0号节点立即收到了这个消息
D)0、1、2号节点收到tiny_learn_op,表示消息在各个节点确认了。
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
E)0、1、2号节点将收到的信息,传送给上层应用
msg_no , cargo_type : app_type , msg_type : normal, pax_op : learn_op
msg_no , cargo_type : app_type , msg_type : normal, pax_op : learn_op
msg_no , cargo_type : app_type , msg_type : normal, pax_op : learn_op
2)结果正确、网络不正常
节点编号:,Primary节点
in push_msg_2p msg_no ,
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
msg_no , cargo_type : app_type , msg_type : normal, pax_op : learn_op 节点编号:,Secondary节点
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
msg_no , cargo_type : app_type , msg_type : normal, pax_op : learn_op
in dispatch_op msg_no , , paxos op read_op from : to : 节点编号:,Secondary节点
in read_missing_values msg_no ,
in dispatch_op msg_no , , paxos op learn_op from : to :
msg_no , cargo_type : app_type , msg_type : normal, pax_op : learn_op
分析:
对比情况 1),有如下几个发现
A)0号节点,只收到两个ack_accept_op(来自0、2号),其中缺失了1号节点的回复。但是由于构成了多数派,还是能够成功。
B)1号节点发现缺少编号(44043,0)的信息后,往节点2发送read_op的信息,以获取缺失的信息
in dispatch_op msg_no , , paxos op read_op from : to :
C)2号节点,将信息发给1号节点
in dispatch_op msg_no , , paxos op learn_op from : to :
3)节点错误、网络不正常
节点编号:0,Primary节点
in push_msg_2p msg_no ,
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
in dispatch_op msg_no , , paxos op read_op from : to :
in dispatch_op msg_no , , paxos op read_op from : to :
in dispatch_op msg_no , , paxos op prepare_op from : to :
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
in dispatch_op msg_no , , paxos op read_op from : to :
in dispatch_op msg_no , , paxos op read_op from : to :
msg_no , cargo_type : app_type , msg_type : normal, pax_op : learn_op 节点编号:2,Secondary节点
in dispatch_op msg_no , , paxos op accept_op from : to :
in read_missing_values msg_no ,
in read_missing_values msg_no ,
in dispatch_op msg_no , , paxos op read_op from : to :
in read_missing_values msg_no ,
in dispatch_op msg_no , , paxos op prepare_op from : to :
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
msg_no , is no_op
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
in dispatch_op msg_no , , paxos op learn_op from : to :
in dispatch_op msg_no , , paxos op learn_op from : to : 节点编号:1,Secondary节点
in read_missing_values msg_no ,
in dispatch_op msg_no , , paxos op read_op from : to :
in read_missing_values msg_no ,
in read_missing_values msg_no ,
in push_msg_3p msg_no ,
in dispatch_op msg_no , , paxos op prepare_op from : to :
in dispatch_op msg_no , , paxos op ack_prepare_empty_op from : to :
in dispatch_op msg_no , , paxos op ack_prepare_op from : to :
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
msg_no , is no_op
分析:
A)0号节点发送消息(44044, 0),只有0、2节点回复了。
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
B)0号节点,发送tiny_learn_op,但是只有0号节点收到了,此时编号为(44044, 0)的消息,在0号节点确定了,但是2号节点还未及时收到tiny_learn_op
msg_no , is no_op
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
注意2号节点,在消息(44044, 0)被确定为no_op时,才收到tiny_learn_op。也就是说这个tiny_learn_op对于2号节点来说,就像没收到过一样
C)1、2号节点,试图读取缺失的(44044, 0)消息(通过发送read_op),但是由于网络问题,均没有得到及时的回复
in dispatch_op msg_no , , paxos op read_op from : to :
in dispatch_op msg_no , , paxos op read_op from : to :
in dispatch_op msg_no , , paxos op read_op from : to :
in dispatch_op msg_no , , paxos op read_op from : to :
D)1号节点试图针对(44044, 0)发起noop消息提议
in push_msg_3p msg_no ,
注意关键点,错误在下一步
E)节点1试图获得他应该提议的值,并完成了propose过程
in dispatch_op msg_no , , paxos op prepare_op from : to :
in dispatch_op msg_no , , paxos op ack_prepare_empty_op from : to :
in dispatch_op msg_no , , paxos op ack_prepare_op from : to :
in dispatch_op msg_no , , paxos op accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op ack_accept_op from : to :
in dispatch_op msg_no , , paxos op tiny_learn_op from : to :
msg_no , is no_op
E.1)节点1发送prepare_op,并收到了节点1、2的回复
E.2) 节点1是没有值(因为其之前没有收到过来自节点0的accept_op),所以其回复ack_prepare_empty_op
E.3) 节点2有值(参考A),所以其回复ack_prepare_op
E.4)原则上节点1会发起节点2返回给的值,但是从结果来看,其并没有。
msg_no , is no_op
针对这个问题,笔者仔细阅读MGR的prepare阶段的源码,核心代码为

int gt_ballot(ballot x, ballot y) {
return x.cnt > y.cnt || (x.cnt == y.cnt && x.node > y.node);
}
只有满足这个条件,节点1才会使用节点2返回的值。
F)进一步研究发现,凡是编号大的节点发起的noop提议都有可能会有上述问题。
in handle_ack_prepare msg_no , , m->proposal.cnt = , m->proposal.node = , p->proposer.msg->proposal.cnt = , p->proposer.msg->proposal.node = 1
由于初始化的时候,cnt均为0,大小完全取决于节点编号。 本例中为 0 < 1 , 所以无法使用0的值
5、解决办法
static void propose_noop(synode_no find, pax_machine *p) {
/* Prepare to send a noop */
site_def const *site = find_site_def(find);
assert(!too_far(find));
replace_pax_msg(&p->proposer.msg, pax_msg_new(find, site));
/* set cnt to -1 when propose noop*/
int cnt = -;
node_no nodeno = VOID_NODE_NO;
if (site) nodeno = get_nodeno(site);
init_ballot(&p->proposer.msg->proposal, cnt, nodeno);
/* set cnt to -1 when propose noop*/
assert(p->proposer.msg);
create_noop(p->proposer.msg);
//printf("in propose_noop msg_no %lld, %d\n", p->proposer.msg->synode.msgno, p->proposer.msg->synode.node);
//fflush(stdout);
/* DBGOUT(FN; SYCEXP(find);); */
push_msg_3p(site, p, clone_pax_msg(p->proposer.msg), find, no_op);
}
代码中红色部分为增加部分。修改后,由于 -1 < 0, 所以解决了那个问题。
一个导致MGR数据混乱Bug的分析和修复的更多相关文章
- Druid:一个用于大数据实时处理的开源分布式系统——大数据实时查询和分析的高容错、高性能开源分布式系统
转自:http://www.36dsj.com/archives/28590 Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分 ...
- Druid:一个用于大数据实时处理的开源分布式系统
Druid是一个用于大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析.尤其是当发生代码部署.机器故障以及其他产品系统遇到宕机等情况时,Druid仍 ...
- 三年之久的 etcd3 数据不一致 bug 分析
问题背景 诡异的 K8S 滚动更新异常 笔者某天收到同事反馈,测试环境中 K8S 集群进行滚动更新发布时未生效.通过 kube-apiserver 查看发现,对应的 Deployment 版本已经是最 ...
- 一个bug案例分析
Bug描述: 某大型系统的一个提供基础数据服务的子系统A进行了一次升级.升级的内容为:优化了失败重传功能,在优化的同时,开发人员发现传输数据的时间戳精度只是精确到了秒,于是顺手把精度改成了1/100秒 ...
- 一个驱动导致的内存泄漏问题的分析过程(meminfo->pmap->slabtop->alloc_calls)
关键词:sqllite.meminfo.slabinfo.alloc_calls.nand.SUnreclaim等等. 下面记录一个由于驱动导致的内存泄漏问题分析过程. 首先介绍问题背景,在一款嵌入式 ...
- MO拆分计划行程序中写入PRODUCTIONORDERS表数据出现重复导致报错(BUG)20180502
错误提示:ORA-00001: 违反唯一约束条件 (ABPPMGR.C0248833319_6192)ORA-06512: 在 "STG.FP_MO_SPLIT", line 19 ...
- 改进动态设置query cache导致额外锁开销的问题分析及解决方法-mysql 5.5 以上版本
改进动态设置query cache导致额外锁开销的问题分析及解决方法 关键字:dynamic switch for query cache, lock overhead for query cach ...
- 对BUG的分析与理解
对BUG的分析与理解 bug的分类 bug,其实就是软件期望的行为与实际行为的差异.从程序的角度来看,在软件整个生命周期中都会有bug的出现.需求分析过程中,需求理解的不足,导致的理解错位 ,遗漏甚至 ...
- MySQL 5.7 GTID OOM bug案例分析 --大量压测后主从不同步
转载自:http://www.sohu.com/a/231766385_487483 MySQL 5.7是十年内最为经典的版本,这个观点区区已经表示过很多次.然而,经典也是由不断地迭代所打造的传奇.5 ...
随机推荐
- 转载:python的编码处理(一)
以下内容转载自: http://in355hz.iteye.com/blog/1860787 最近业务中需要用 Python 写一些脚本.尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些, ...
- 【数据结构】循环队列 C语言实现
"Queue.h" #include "Queue.h" #include <stdio.h> #include <stdlib.h> ...
- libcurl同时下载多个文件
#include <errno.h> #include <stdlib.h> #include <string.h> #ifndef WIN32 #include ...
- 026.1 网络编程 获取IP地址
前面提及的:OSI,TCP-IP,IP地址,端口,协议概念我都清楚,所以我直接跳过前面,来到使用这里. //获取本机IP InetAddress ip = InetAddress.getLocalHo ...
- lambda表达式和groovy闭包的区别
groovy定义的闭包是 Closure 的实例,lambda表达式只是在特定的接⼝或者抽象类的匿名实现,他们之间最主要区别闭包可以灵活的配置代理策略⽽labmda表达式不允许
- 使用python来搞定redis的订阅功能
好久没写博客了. 最近公司开了新项目,我负责的内容之一是系统的后端.具体项目内容我就不介绍了,但是用到的技术有些还是很有趣的,值得记录一下.今天介绍的就是其中一个:利用redis的pubsub订阅 ...
- Java阶段性总结与获奖感想
一.获奖感想 这次能获得小黄衫,可以说是对我自己这半学期以来努力学习的一种肯定,也是激励我继续努力的动力. 首先,我要感谢给予我们耳目一新的学习方式的娄老师.我曾在我期望的师生关系中提到,我的高中班主 ...
- Apache HttpComponents中的cookie匹配策略
Apache HttpComponents中的cookie匹配策略 */--> pre.src {background-color: #292b2e; color: #b2b2b2;} pre. ...
- Kafka设计解析(十八)Kafka与Flink集成
转载自 huxihx,原文链接 Kafka与Flink集成 Apache Flink是新一代的分布式流式数据处理框架,它统一的处理引擎既可以处理批数据(batch data)也可以处理流式数据(str ...
- Kafka设计解析(十一)Kafka无消息丢失配置
转载自 huxihx,原文链接 Kafka无消息丢失配置 目录 一.Producer端二.Consumer端 Kafka到底会不会丢数据(data loss)? 通常不会,但有些情况下的确有可能会发生 ...