深度学习模型训练技巧 Tips for Deep Learning
一、深度学习建模与调试流程
先看训练集上的结果怎么样(有些机器学习模型没必要这么做,比如决策树、KNN、Adaboost 啥的,理论上在训练集上一定能做到完全正确,没啥好检查的)
Deep Learning 里面过拟合并不是首要的问题,或者说想要把神经网络训练得好,至少先在训练集上结果非常好,再考虑那些改善过拟合的技术(BN,Dropout 之类的)。否则的话回去检查三个 step 哪里有问题。
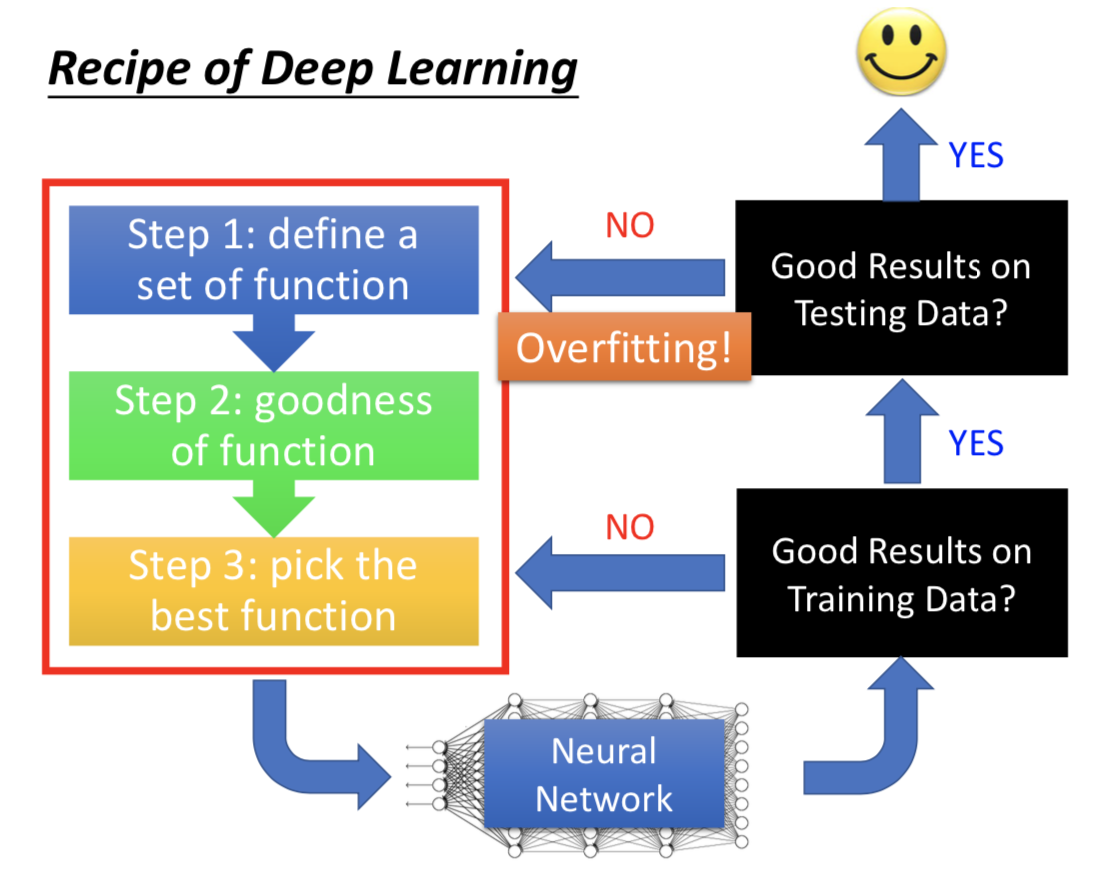
Deep Learning 中的方法为了解决两个主要问题而提出:1.训练集做得不好;2.训练集做得好,测试集做得不好
实际应用的时候搞清楚自己面对的问题,选择对应的技巧。
二、激活函数
1. sigmoid
梯度消失:网络很深的时候,靠近输入的 hidden layers 的梯度对损失函数影响很小, 参数更新的就很慢;靠近输出的情况反之。前面几层的参数都还没怎么更新的时候就收敛了。
原因也比较简单,反向传播的时候每经过一层,都会乘上小于 1 的数(sigmoid 函数 会把输入压到 0~1 之间),结果就越来越衰减。
早期用 RBM ,先训练好前面几层。
2. ReLU
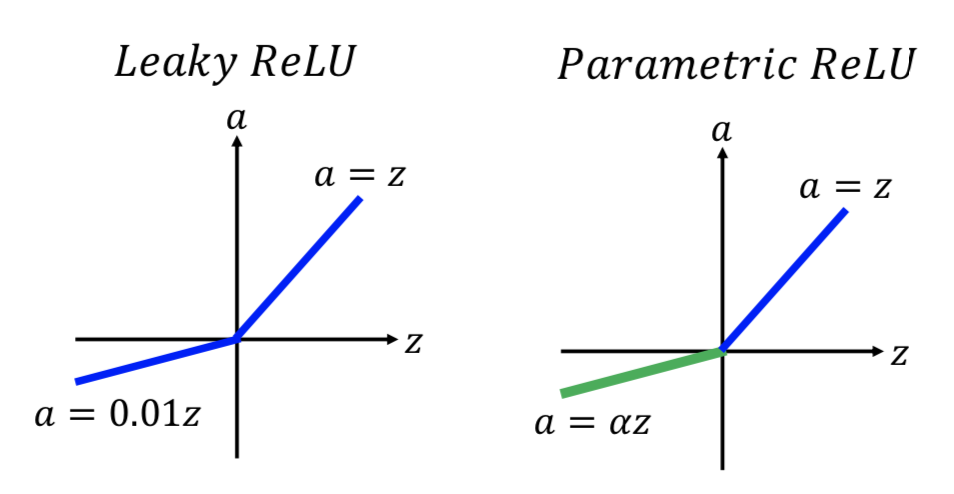
3. maxout network
每个神经元的激活函数的具体形式,是可以学习来的(不一定非得像 ReLU 那样在原点分段):
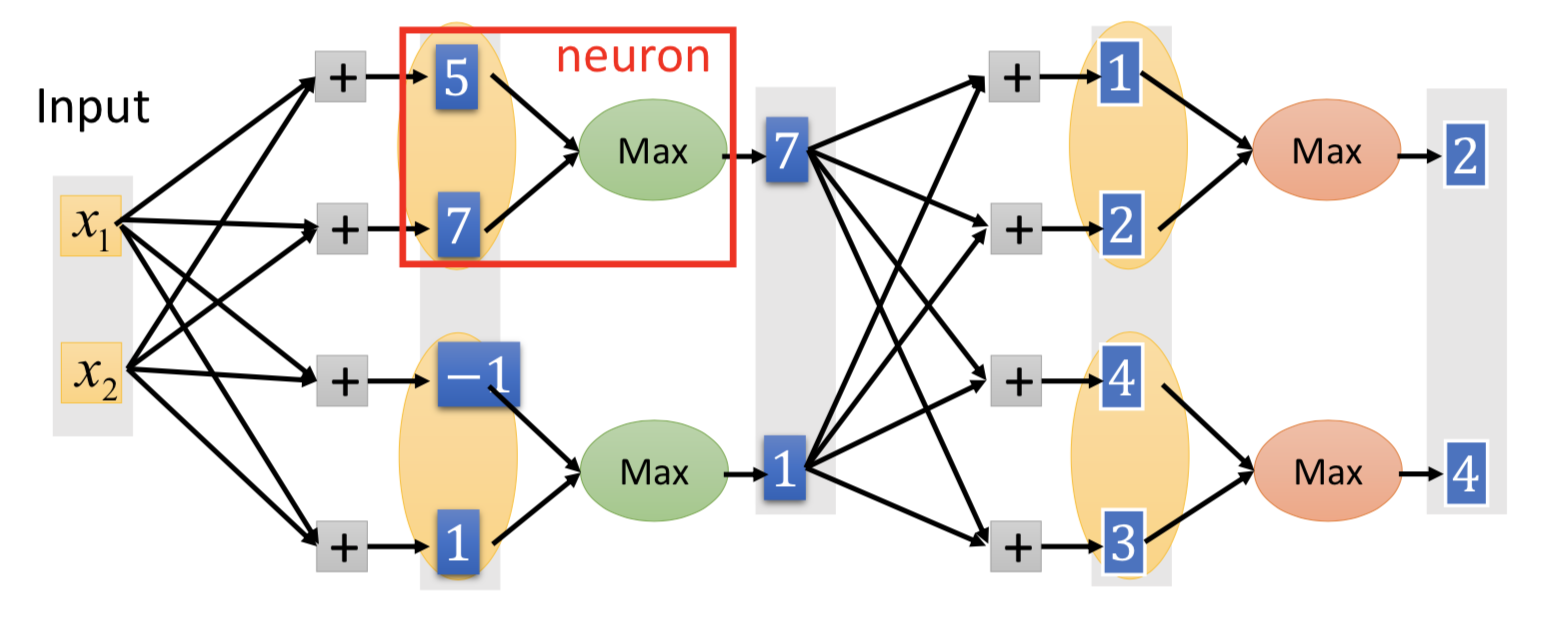
哪些神经元要被 group 起来是事先决定的(比如随机2个或者3个一组之类的,几个一组也可以作为一个参数来学习)。
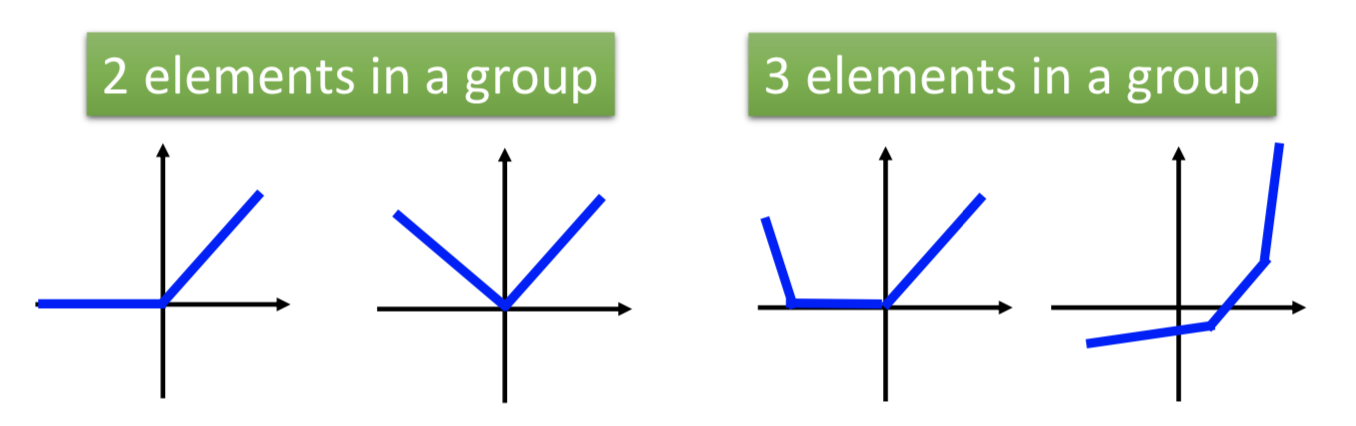
ReLU 就是特殊情况下的 maxout ;但 maxout 可以实现更多可能的激活函数(具体是什么样的函数,根本上是由参数 w 决定的)。
三、梯度下降的改进
1. Adagrad
在梯度下降中已经总结过,在不同方向上需要不同的学习率。
学习率时间衰减 + 从开始到当前时刻的梯度平方和求平均来估计二阶微分的大小趋势

2. RMSProp
error surface 非常复杂,即使在同一个方向上,学习率也需要不断调整。进阶版 Adagrad,动态调整学习率。
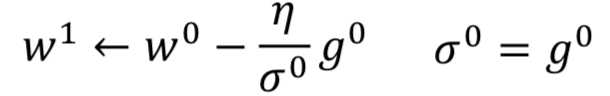
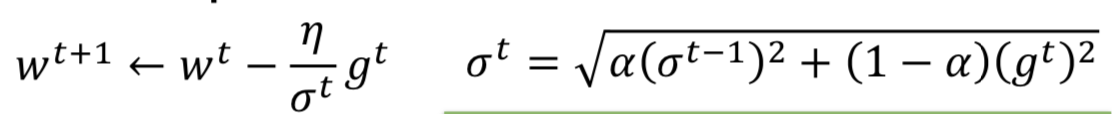
在 decaying 累计的先前梯度,通过调整alpha的大小,来选择是考虑先前的梯度(t 时刻之前的累积)多一些,还是当前的梯度(t时刻的)多一些
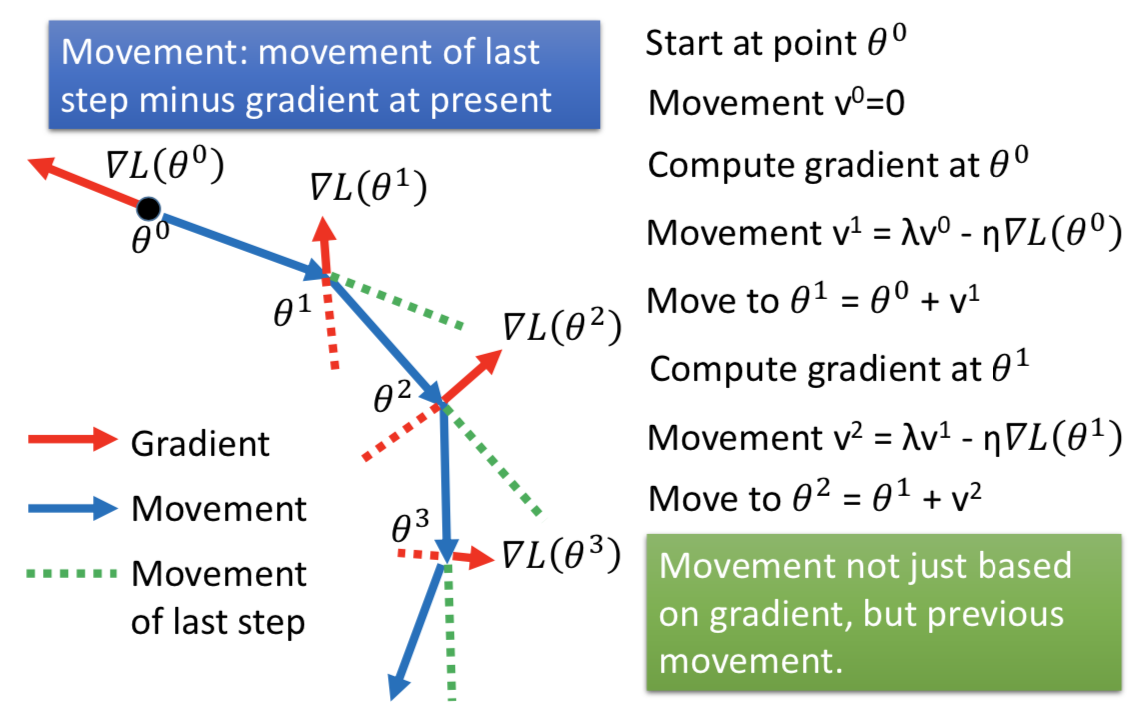
3. Momentum
解决一点 local minima 和 plateau 的问题
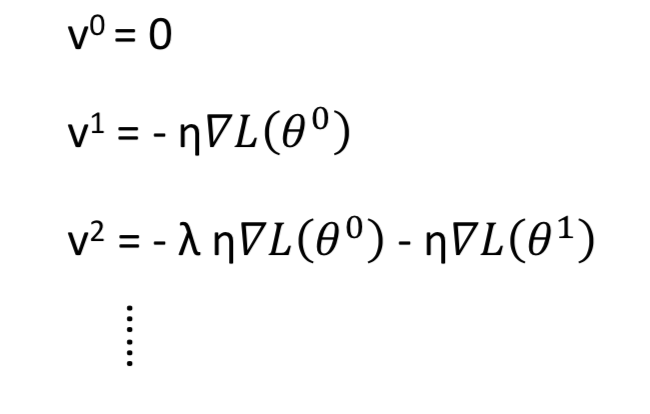
4. Adam
RMSProp + Momentum,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。

其中,在迭代初始阶段,mt 和 vt 有一个向初值的偏移(过多的偏向了 0),因此可以对一阶和二阶动量做偏置校正 (bias correction),这样每次迭代学习率都有一个确定的范围,参数更新比较平稳。
四、正则化
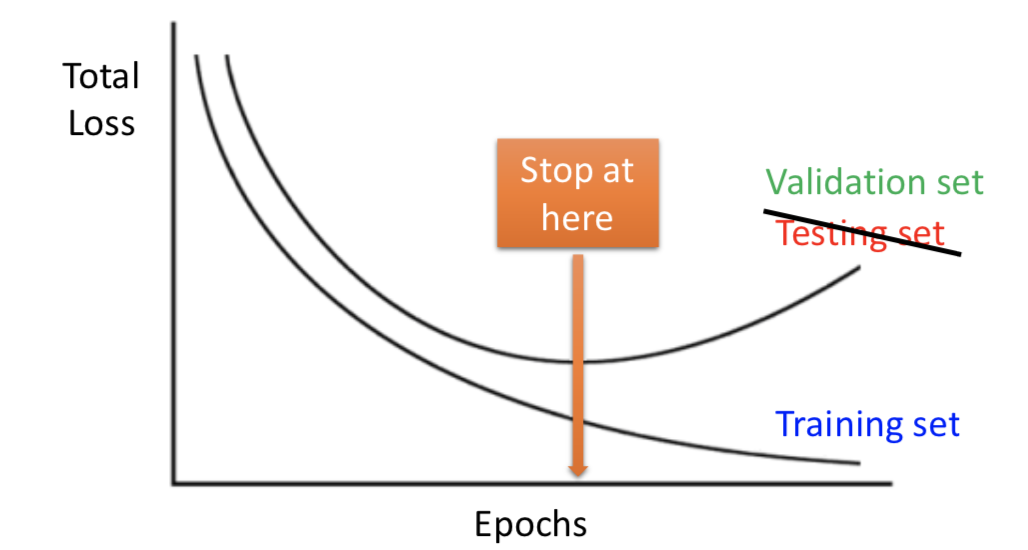
1. Early Stopping
机器学习中比较常见的技巧
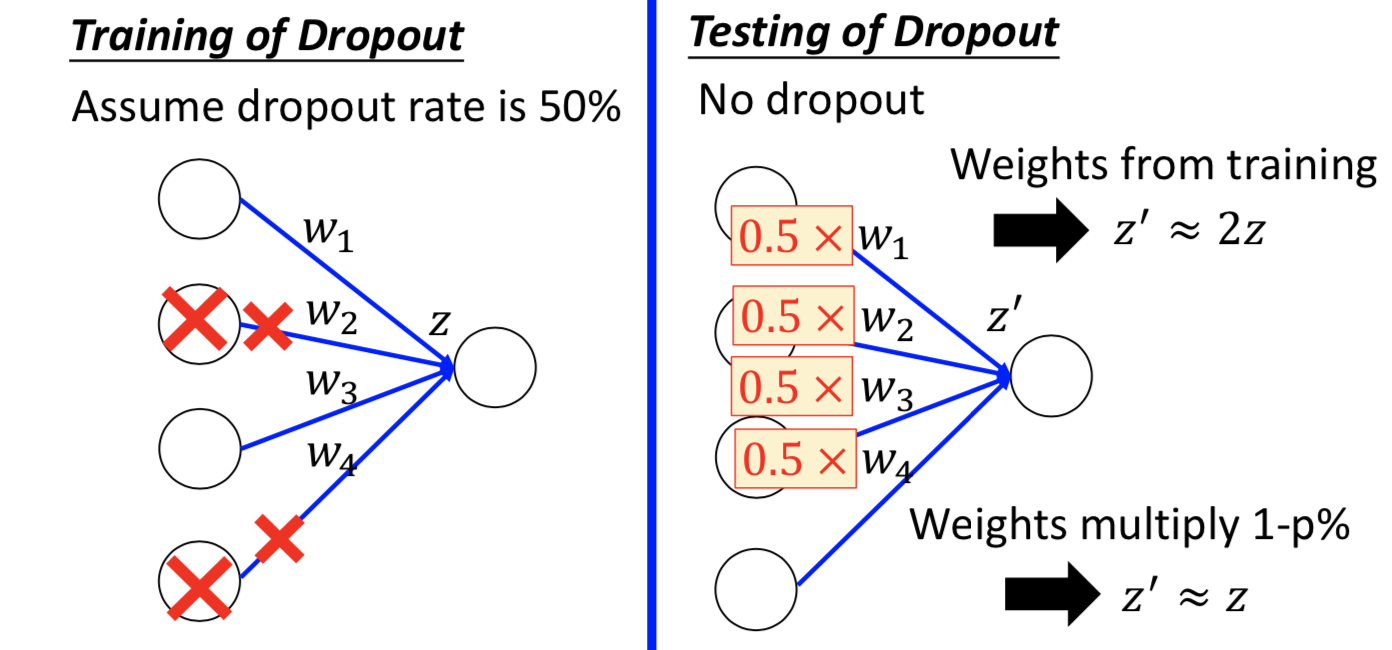
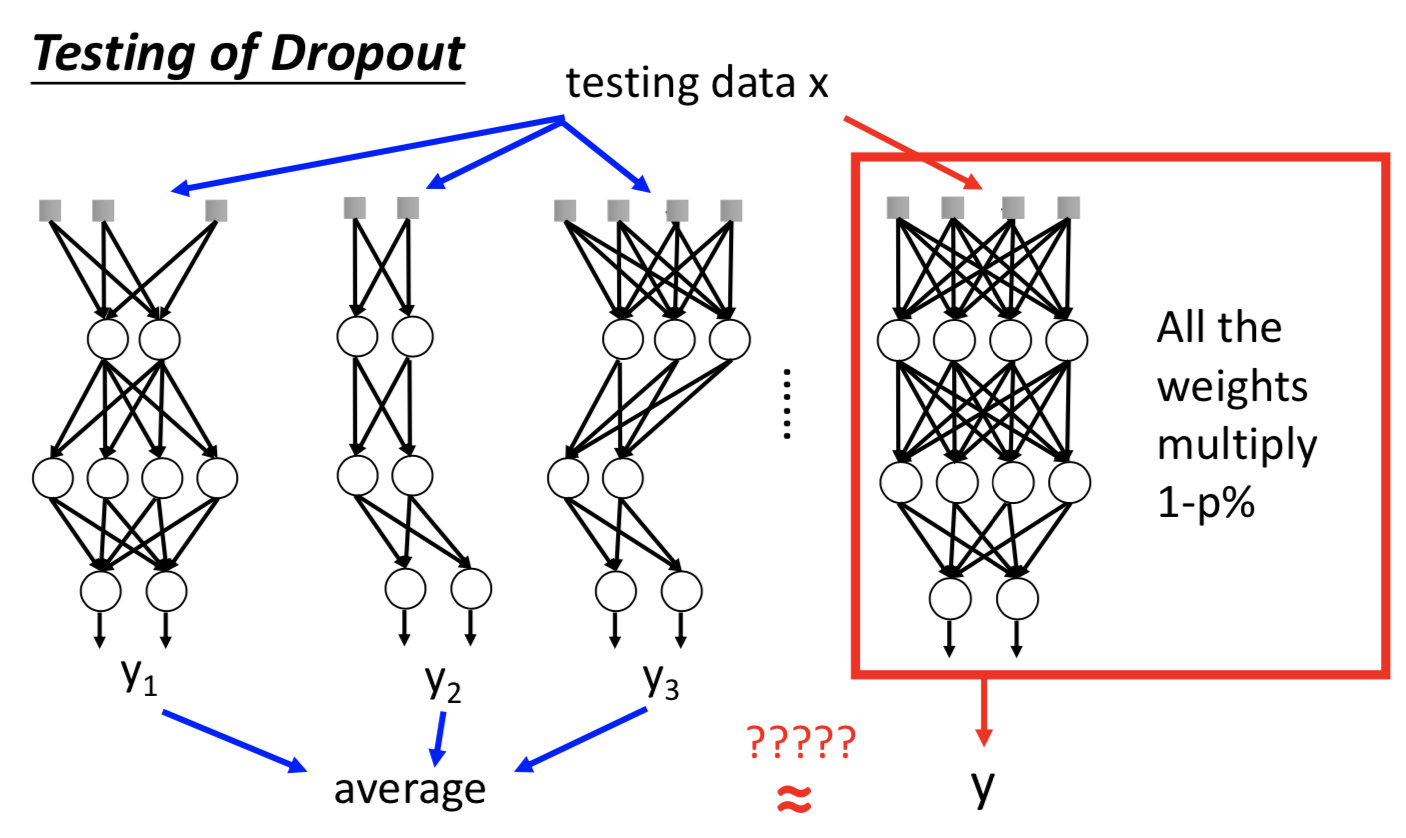
2. Dropout
神经网络中才会用
随机 kill 掉一定比例的神经元。测试的时候不做,而且还要补偿参数。

深度学习模型训练技巧 Tips for Deep Learning的更多相关文章
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 深度学习与计算机视觉(11)_基于deep learning的快速图像检索系统
深度学习与计算机视觉(11)_基于deep learning的快速图像检索系统 作者:寒小阳 时间:2016年3月. 出处:http://blog.csdn.net/han_xiaoyang/arti ...
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)【转】
本文转载自:https://blog.csdn.net/xummgg/article/details/69214366 前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络,并把 ...
- TensorFlow和深度学习新手教程(TensorFlow and deep learning without a PhD)
前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络.并把其PPT的參考学习资料给了我们, 这是codelabs上的教程:<TensorFlow and deep lear ...
- 深度学习FPGA实现基础知识10(Deep Learning(深度学习)卷积神经网络(Convolutional Neural Network,CNN))
需求说明:深度学习FPGA实现知识储备 来自:http://blog.csdn.net/stdcoutzyx/article/details/41596663 说明:图文并茂,言简意赅. 自今年七月份 ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
- 在NLP中深度学习模型何时需要树形结构?
在NLP中深度学习模型何时需要树形结构? 前段时间阅读了Jiwei Li等人[1]在EMNLP2015上发表的论文<When Are Tree Structures Necessary for ...
随机推荐
- redis module 学习—官网文档整理
前言 redis在4.0版本中,推出了一个非常吸引的特性,可以通过编写插件的模式,来动态扩展redis的能力.在4.0之前,如果用户想拥有一个带TTL的INCRBY 命令,那么用户只能自己去改代码,重 ...
- scrapy实战2分布式爬取lagou招聘(加入了免费的User-Agent随机动态获取库 fake-useragent 使用方法查看:https://github.com/hellysmile/fake-useragent)
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- scrapy基础知识之随机切换fake-useragent 库的使用:
pip install fake-useragent from fake_useragent import UserAgent ua = UserAgent() middlewares.py from ...
- 【无线安全实践入门】网络扫描和ARP欺骗
文中可能存在错误操作或错误理解,望大家不吝指正. 同时也希望可以帮助到想要学习接触此方面.或兴趣使然的你,让你有个大概的印象. !阅前须知! 本文是基于我几年前的一本笔记本,上面记录了我学习网络基础时 ...
- 扒一扒那些教程中不常被提及的JavaScript小技巧
1.过滤唯一值 Set类型是在ES6中新增的,它类似于数组,但是成员的值都是唯一的,没有重复的值.结合扩展运算符(...)我们可以创建一个新的数组,达到过滤原数组重复值的功能. const array ...
- 剑指offer第二版-5.替换空格
面试题5:替换空格 题目要求: 实现一个函数,把字符串中的每个空格都替换成“%20”,已知原位置后面有足够的空余位置,要求改替换过程发生在原来的位置上. 思路: 首先遍历字符串求出串中空格的数量,求出 ...
- ~~函数基础(三):嵌套函数&匿名函数~~
进击のpython 嵌套函数&匿名函数 讲完作用域之后 对变量的作用范围有大致的了解了吗? 讲个稍微小进阶的东西吧 能够帮助你更加的理解全局和局部变量 嵌套函数 玩过俄罗斯套娃不? 没玩过听过 ...
- 教你如何上传项目到GitHub
前言: 作为一个开发人员怎么可以不会使用GitHub呢,正好我也研究了一下如何往GitHub上传项目,这篇博客给初学者们观看,大佬请绕道. 新建GitHub仓库 没有注册过的先去GitHub官网进行注 ...
- WinForm控件之【DateTimePicker】
基本介绍 时间控件应用较为广泛,属性设置项也比较完善是非常好用的控件. 常设置属性.事件 CustomFormat:当Format属性设置为自定义类型时可自定义控件时间的显示格式: Enabled:指 ...
- Prim算法与Kruskal(没有代码)
两个最小生成树算法, 都有一个共同的思想: 这棵树是一点一点长大的; 并且每次生长, 都是贪心的. 不同之处是: Kruscal算法是以边为中心的, 每次找最小的并且有用的边添加到树上; Prim算法 ...