Linux curl 常用示例
本篇文章包含了curl的常用案例使用。
如果想了解curl选项的详细说明,请参考前一篇文章「Linux curl 命令详解」。
常见网页访问示例
基本用法
访问一个网页
curl https://www.baidu.com
执行后,相关的网页信息会打印出来
进度条展示
有时候我们不需要进度表展示,而需要进度条展示。比如:下载文件时。
可以通过 -#, --progress-bar 选项实现。
[root@iZ28xbsfvc4Z ]# curl https://www.baidu.com | head -n1 # 进度表显示
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
--:--:-- --:--:-- --:--:--
<!DOCTYPE html>
[root@iZ28xbsfvc4Z ]# curl -# https://www.baidu.com | head -n1 # 进度条显示
######################################################################## 100.0%
<!DOCTYPE html>
静默模式与错误信息打印
当我们做一些操作时,可能会出现进度表。这时我们可以使用 -s, --silent 静默模式去掉这些不必要的信息。
如果使用 -s, --silent 时,还需要打印错误信息,那么还需要使用 -S, --show-error 选项。
静默模式示例
[root@iZ28xbsfvc4Z ~]# curl https://www.baidu.com | head -n1
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
--:--:-- --:--:-- --:--:--
<!DOCTYPE html>
[root@iZ28xbsfvc4Z ~]# curl -s https://www.baidu.com | head -n1
<!DOCTYPE html>
静默模式结合错误信息打印
[root@iZ28xbsfvc4Z ]# curl -s https://140.205.16.113/
[root@iZ28xbsfvc4Z ]#
[root@iZ28xbsfvc4Z ]# curl -sS https://140.205.16.113/
curl: () Unable to communicate securely with peer: requested domain name does not match the server's certificate.
显示详细操作信息
使用 -v, --verbose 选项实现。
以 > 开头的行表示curl发送的”header data”;< 表示curl接收到的通常情况下隐藏的”header data”;而以 * 开头的行表示curl提供的附加信息。
[root@iZ28xbsfvc4Z ]# curl -v https://www.baidu.com
* About to connect() to www.baidu.com port (#)
* Trying 180.101.49.12...
* Connected to www.baidu.com (180.101.49.12) port (#)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
* SSL connection using TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
* Server certificate:
* subject: CN=baidu.com,O="Beijing Baidu Netcom Science Technology Co., Ltd",OU=service operation department,L=beijing,ST=beijing,C=CN
* start date: May :: GMT
* expire date: Jun :: GMT
* common name: baidu.com
* issuer: CN=GlobalSign Organization Validation CA - SHA256 - G2,O=GlobalSign nv-sa,C=BE
> GET / HTTP/1.1
> User-Agent: curl/7.29.
> Host: www.baidu.com
> Accept: */*
>
< HTTP/1.1 200 OK
< Accept-Ranges: bytes
< Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
< Connection: Keep-Alive
< Content-Length: 2443
< Content-Type: text/html
< Date: Fri, 12 Jul 2019 08:26:23 GMT
< Etag: "588603eb-98b"
< Last-Modified: Mon, 23 Jan 2017 13:23:55 GMT
< Pragma: no-cache
< Server: bfe/1.0.8.18
< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
<
<!DOCTYPE html>
……………… # curl 网页的具体信息
指定访问的请求方法
当然curl默认使用GET方式访问。使用了 -d, --data <data> 选项,那么会默认为 POST方法访问。如果此时还想实现 GET 访问,那么可以使用 -G, --get 选项强制curl 使用GET方法访问。
同时 -X, --request <command> 选项也可以指定访问方法。
POST请求和数据传输
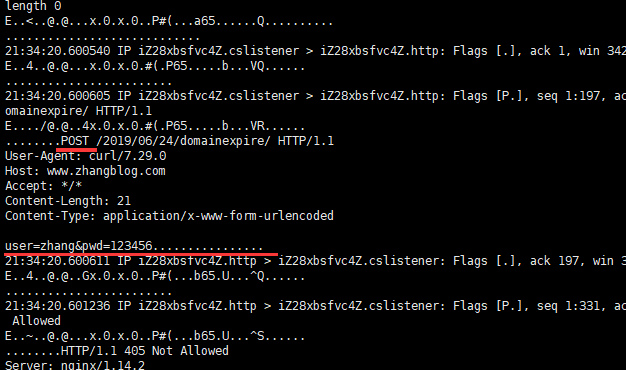
为了抓包查看信息所以使用了 --local-port <num>[-num] 选项,在实际应用中不需要该选项。
[root@iZ28xbsfvc4Z ~]# curl -sv --local-port -X POST -d 'user=zhang&pwd=123456' http://www.zhangblog.com/2019/06/24/domainexpire/ | head -n1
## 或者
[root@iZ28xbsfvc4Z ~]# curl -sv --local-port -d 'user=zhang&pwd=123456' http://www.zhangblog.com/2019/06/24/domainexpire/ | head -n1
* About to connect() to www.zhangblog.com port (#)
* Trying 120.27.48.179...
* Connected to www.zhangblog.com (120.27.48.179) port (#)
> POST ////domainexpire/ HTTP/1.1 # POST 请求方法
> User-Agent: curl/7.29.
> Host: www.zhangblog.com
> Accept: */*
> Content-Length: 21
> Content-Type: application/x-www-form-urlencoded
>
} [data not shown]
* upload completely sent off: 21 out of 21 bytes
< HTTP/1.1 405 Not Allowed
< Server: nginx/1.14.2
< Date: Thu, 18 Jul 2019 07:56:23 GMT
< Content-Type: text/html
< Content-Length: 173
< Connection: keep-alive
<
{ [data not shown]
* Connection #0 to host www.zhangblog.com left intact
<html>
抓包信息
[root@iZ28xbsfvc4Z tcpdump]# tcpdump -i any port -A -s
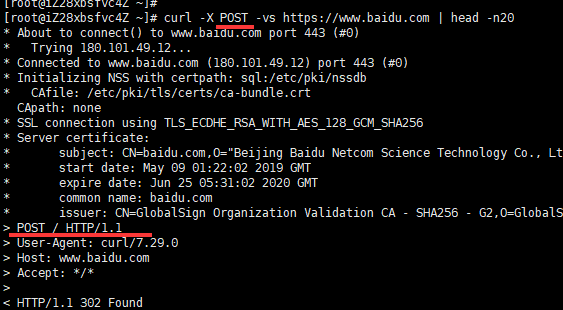
指定请求方法
curl -vs -X POST https://www.baidu.com | head -n1
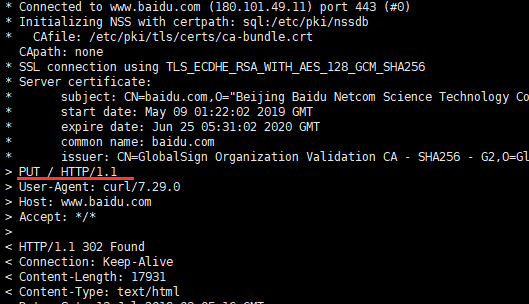
curl -vs -X PUT https://www.baidu.com | head -n1
保存访问网页
使用linux的重定向功能保存
curl www.baidu.com >> baidu.html
使用curl的大O选项
通过 -O, --remote-name 选项实现。
[root@iZ28xbsfvc4Z ]# curl -O https://www.baidu.com # 使用了 -O 选项,必须指定到具体的文件 错误使用
curl: Remote file name has no length!
curl: try 'curl --help' or 'curl --manual' for more information
[root@iZ28xbsfvc4Z ]# curl -O https://www.baidu.com/index.html # 使用了 -O 选项,必须指定到具体的文件 正确使用
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
--:--:-- --:--:-- --:--:--
使用curl的小o选项
通过 -o, --output <file> 选项实现。
[root@iZ28xbsfvc4Z ]# curl -o sina.txt https://www.sina.com.cn/ # 单个操作
[root@iZ28xbsfvc4Z ]# ll
-rw-r--r-- root root Jul : sina.txt
[root@iZ28xbsfvc4Z ]# curl "http://www.{baidu,douban}.com" -o "site_#1.txt" # 批量操作,注意curl 的地址需要用引号括起来
[/]: http://www.baidu.com --> site_baidu.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
--:--:-- --:--:-- --:--:-- [/]: http://www.douban.com --> site_douban.txt
--:--:-- --:--:-- --:--:--
[root@iZ28xbsfvc4Z ]#
[root@iZ28xbsfvc4Z ]# ll
total
-rw-r--r-- root root Jul : site_baidu.txt
-rw-r--r-- root root Jul : site_douban.txt
允许不安全访问
当我们使用curl进行https访问访问时,如果SSL证书是我们自签发的证书,那么这个时候需要使用 -k, --insecure 选项,允许不安全的访问。
[root@iZ28xbsfvc4Z ~]# curl https://140.205.16.113/ # 被拒绝
curl: () Unable to communicate securely with peer: requested domain name does not match the server's certificate.
[root@iZ28xbsfvc4Z ~]#
[root@iZ28xbsfvc4Z ~]# curl -k https://140.205.16.113/ # 允许执行不安全的证书连接
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html>
<head><title> Forbidden</title></head>
<body bgcolor="white">
<h1> Forbidden</h1>
<p>You don't have permission to access the URL on this server.<hr/>Powered by Tengine</body>
</html>
获取HTTP响应状态码
在脚本中,这是很常见的测试网站是否正常的用法。
通过 -w, --write-out <format> 选项实现。
[root@iZ28xbsfvc4Z ]# curl -o /dev/null -s -w %{http_code} https://baidu.com
[root@iZ28xbsfvc4Z ]#
[root@iZ28xbsfvc4Z ]#
[root@iZ28xbsfvc4Z ]# curl -o /dev/null -s -w %{http_code} https://www.baidu.com
[root@iZ28xbsfvc4Z ]#
指定proxy服务器以及其端口
很多时候上网需要用到代理服务器(比如是使用代理服务器上网或者因为使用curl别人网站而被别人屏蔽IP地址的时候),幸运的是curl通过使用 -x, --proxy <[protocol://][user:password@]proxyhost[:port]> 选项来支持设置代理。
curl -x 192.168.100.100: https://www.baidu.com
模仿浏览器访问
有些网站需要使用特定的浏览器去访问他们,有些还需要使用某些特定的浏览器版本。我们可以通过 -A, --user-agent <agent string> 或者 -H, --header <header> 选项实现模拟浏览器访问。
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/75.0.3770.999" http://www.zhangblog.com/2019/06/24/domainexpire/
或者
curl -H 'User-Agent: Mozilla/5.0' http://www.zhangblog.com/2019/06/24/domainexpire/
伪造referer(盗链)
有些网站的网页对http访问的链接来源做了访问限制,这些限制几乎都是通过referer来实现的。
比如:要求是先访问首页,然后再访问首页中的邮箱页面,这时访问邮箱的referer地址就是访问首页成功后的页面地址。如果服务器发现对邮箱页面访问的referer地址不是首页的地址,就断定那是个盗连了。
可以通过 -e, --referer 或则 -H, --header <header> 实现伪造 referer 。
curl -e 'https://www.baidu.com' http://www.zhangblog.com/2019/06/24/domainexpire/
或者
curl -H 'Referer: https://www.baidu.com' http://www.zhangblog.com/2019/06/24/domainexpire/
构造HTTP请求头
可以通过 -H, --header <header> 实现构造http请求头。
curl -H 'Connection: keep-alive' -H 'Referer: https://sina.com.cn' -H 'User-Agent: Mozilla/1.0' http://www.zhangblog.com/2019/06/24/domainexpire/
保存响应头信息
可以通过 -D, --dump-header <file> 选项实现。
[root@iZ28xbsfvc4Z ]# curl -D baidu_header.info www.baidu.com
………………
[root@iZ28xbsfvc4Z ]# ll
total
-rw-r--r-- root root Jul : baidu_header.info # 生成的头文件
限时访问
--connect-timeout <seconds> 连接服务端的超时时间。这只限制了连接阶段,一旦curl连接了此选项就不再使用了。
# 当前 https://www.zhangXX.com 是国外服务器,访问受限
[root@iZ28xbsfvc4Z ~]# curl --connect-timeout https://www.zhangXX.com | head
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
--:--:-- :: --:--:--
curl: () Connection timed out after milliseconds
-m, --max-time <seconds> 允许整个操作花费的最大时间(以秒为单位)。这对于防止由于网络或链接变慢而导致批处理作业挂起数小时非常有用。
[root@iZ28xbsfvc4Z ~]# curl -m --limit-rate http://www.baidu.com/ | head # 超过10秒后,断开连接
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
:: :: ::
curl: () Operation timed out after milliseconds with out of bytes received
<!DOCTYPE html>
<!--STATUS OK--><html> <head><met
### 或
[root@iZ28xbsfvc4Z ~]# curl -m https://www.zhangXX.com | head # 超过10秒后,断开连接
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
--:--:-- :: --:--:--
curl: () Connection timed out after milliseconds
显示抓取错误
当我们请求访问失败时或者没有该网页时,网站一般都会给出一个错误的提示页面。
如果我们不需要这个错误页面,只想得到简洁的错误信息。那么可以通过 -f, --fail 选项实现。
[root@iZ28xbsfvc4Z ]# curl http://www.zhangblog.com/201912312
<html>
<head><title> Not Found</title></head>
<body bgcolor="white">
<center><h1> Not Found</h1></center>
<hr><center>nginx/1.14.</center>
</body>
</html>
[root@iZ28xbsfvc4Z ]# curl -f http://www.zhangblog.com/201912312 # 得到更简洁的错误信息
curl: () The requested URL returned error: Not Found
表单登录与cookie使用
参见:「Linux curl 表单登录或提交与cookie使用」
文件上传与下载
涉及 FTP 服务,简单快速搭建可参考:《CentOS7下安装FTP服务》「https://www.cnblogs.com/zhi-leaf/p/5983550.html」
文件下载
网页文件下载
# 以进度条展示,而不是进度表展示
[root@iZ28xbsfvc4Z ]# curl -# -o tmp.data2 http://www.zhangblog.com/uploads/tmp/tmp.data
######################################################################## 100.0%
FTP文件下载
说明1:其中 ftp1 用户是ftp服务端的账号,具体家目录是:/mnt/ftp1
说明2:当我们使用 curl 通过 FTP 进行下载时,后面跟的路径都是:当前使用的 ftp 账号家目录为基础的相对路径,然后找到的目标文件。
示例1
# 其中 tmp.data 的绝对路径是:/mnt/ftp1/tmpdata/tmp.data ;ftp1 账号的家目录是:/mnt/ftp1
# 说明:/tmpdata/tmp.data 这个路径是针对 ftp1 账号的家目录而言的
[yun@nginx_proxy01 ]$ curl -O ftp://ftp1:123456@172.16.1.195:21/tmpdata/tmp.data
# 或者
[yun@nginx_proxy01 ]$ curl -O -u ftp1: ftp://172.16.1.195:21/tmpdata/tmp.data
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
2048M 2048M 39.5M :: :: --:--:-- 143M
示例2
# 其中 nginx-1.14..tar.gz 的绝对路径是:/tmp/nginx-1.14..tar.gz ;ftp1 账号的家目录是:/mnt/ftp1
# 说明:/../../tmp/nginx-1.14..tar.gz 这个路径是针对 ftp1 账号的家目录而言的
[yun@nginx_proxy01 ]$ curl -O ftp://ftp1:123456@172.16.1.195:21/../../tmp/nginx-1.14.2.tar.gz
# 或者
[yun@nginx_proxy01 ]$ curl -O -u ftp1: ftp://172.16.1.195:21/../../tmp/nginx-1.14.2.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
991k 991k 5910k --:--:-- --:--:-- --:--:-- 5937k
文件上传
FTP文件上传
可以通过 -T, --upload-file <file> 选项实现。
说明1:其中 ftp1 用户是ftp服务端的账号,具体家目录是:/mnt/ftp1
# 其中 tmp_client.data 是客户端本地文件;
# /tmpdata/ 这个路径是针对 ftp1 账号的家目录而言的,且上传时该目录必须是存在的,否则上传失败。
# 因此上传后文件在ftp服务端的绝对路径是:/mnt/ftp1/tmpdata/tmp_client.data
[yun@nginx_proxy01 ]$ curl -T tmp_client.data ftp://ftp1:123456@172.16.1.195:21/tmpdata/
# 或者
[yun@nginx_proxy01 ]$ curl -T tmp_client.data -u ftp1: ftp://172.16.1.195:21/tmpdata/
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
2048M 2048M 95.4M :: :: --:--:-- 49.3M
断点续传
使用 -C, --continue-at <offset> 选项实现。其中使用 “-C -“「注意有空格和无空格的情况」,告诉curl自动找出在哪里/如何恢复传输。
网页端断点续传下载
curl -C - -o tmp.data http://www.zhangblog.com/uploads/tmp/tmp.data # 下载一个 2G 的文件
FTP断点续传下载
细节就不多说了,可参见上面的「FTP文件下载」
curl -C - -o tmp.data1 ftp://ftp1:123456@172.16.1.195:21/tmpdata/tmp.data # 下载一个 2G 的文件
# 或则
curl -C - -o tmp.data1 -u ftp1: ftp://172.16.1.195:21/tmpdata/tmp.data # 下载一个 2G 的文件
分段下载
有时文件比较大,或者难以迅速传输,而利用分段传输,可以实现稳定、高效并且有保障的传输,更具有实用性,同时容易对差错文件进行更正。
可使用 -r, --range <range> 选项实现。
如下示例使用了同一张图片,大小为 18196 字节。
网页端分段下载
分段下载
[root@iZ28xbsfvc4Z ]# curl -I http://www.zhangblog.com/uploads/hexo/00.jpg # 查看文件大小
HTTP/1.1 OK
Server: nginx/1.14.
Date: Mon, Jul :: GMT
Content-Type: image/jpeg
Content-Length: # 文件大小
Last-Modified: Fri, Jul :: GMT
Connection: keep-alive
ETag: "5d1f04aa-4714"
Accept-Ranges: bytes
### 分段下载一个文件
[root@iZ28xbsfvc4Z ]# curl -r - -o -jpg.part1 http://www.zhangblog.com/uploads/hexo/00.jpg
[root@iZ28xbsfvc4Z ]# curl -r - -o -jpg.part2 http://www.zhangblog.com/uploads/hexo/00.jpg
[root@iZ28xbsfvc4Z ]# curl -r - -o -jpg.part3 http://www.zhangblog.com/uploads/hexo/00.jpg
查看下载文件
[root@iZ28xbsfvc4Z ]# ll
total
-rw-r--r-- root root Jul : -jpg.part1
-rw-r--r-- root root Jul : -jpg.part2
-rw-r--r-- root root Jul : -jpg.part3
文件合并
[root@iZ28xbsfvc4Z ]# cat -jpg.part1 -jpg.part2 -jpg.part3 > .jpg
[root@iZ28xbsfvc4Z ]# ll .jpg
total
-rw-r--r-- root root Jul : .jpg
FTP分段下载
分段下载
[yun@nginx_proxy01 ]$ curl -r - -o -jpg.part1 ftp://ftp1:123456@172.16.1.195:21/tmpdata/00.jpg
[yun@nginx_proxy01 ]$ curl -r - -o -jpg.part2 ftp://ftp1:123456@172.16.1.195:21/tmpdata/00.jpg
[yun@nginx_proxy01 ]$ curl -r - -o -jpg.part3 ftp://ftp1:123456@172.16.1.195:21/tmpdata/00.jpg
查看下载文件
[yun@nginx_proxy01 ]$ ll -jpg.part*
-rw-rw-r-- yun yun Jul : -jpg.part1
-rw-rw-r-- yun yun Jul : -jpg.part2
-rw-rw-r-- yun yun Jul : -jpg.part3
文件合并
[yun@nginx_proxy01 ]$ cat -jpg.part1 -jpg.part2 -jpg.part3 > .jpg
[yun@nginx_proxy01 ]$ ll .jpg
-rw-rw-r-- yun yun Jul : .jpg
推荐阅读
如果觉得不错就点个赞呗 (-^O^-) !
———END———-

Linux curl 常用示例的更多相关文章
- Linux Curl常用命令使用【转】
Curl是Linux下一个很强大的http命令行工具,其功能十分强大. 1)读取网页 $ curl linuxidc.com">http://www.linuxidc.com 2)保存 ...
- Linux curl 常用命令
命令:curl在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具.它支持文件的上传和下载,是综合传输工具,但按传统,习惯称url为下载工具. ...
- Linux curl 命令详解
命令概要 该命令设计用于在没有用户交互的情况下工作. curl 是一个工具,用于传输来自服务器或者到服务器的数据.「向服务器传输数据或者获取来自服务器的数据」 可支持的协议有(DICT.FILE.FT ...
- Linux curl 表单登录或提交与cookie使用
本文主要讲解通过curl 实现表单提交登录.单独的表单提交与表单登录都差不多,因此就不单独说了. 说明:针对curl表单提交实现登录,不是所有网站都适用,原因是有些网站后台做了限制或有其他校验.我们不 ...
- Linux ar命令介绍 和常用示例
制作静态库要用到ar命令,命令格式: ar [-]{dmpqrtx}[abcfilNoPsSuvV] [membername] [count] archive files... {dmpqrtx}中的 ...
- Linux系统管理常用命令
Linux系统管理常用命令 分类: Linux2011-01-10 18:26 1538人阅读 评论(0) 收藏 举报 linuxcommandservicenginxuserunix 目录(?)[+ ...
- Linux curl 命令模拟 POST/GET 请求
Linux curl 命令模拟 POST/GET 请求 本文链接:https://blog.csdn.net/sunboy_2050/article/details/82156402 curl 命 ...
- linux curl 命令详解,以及实例
linux curl是一个利用URL规则在命令行下工作的文件传输工具.它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称url为下载工具. 一,curl命令参数,有好多我没有用过,也不知道翻 ...
- 爹地,我找到了!,15个极好的Linux find命令示例
爹地,我找到了!, 15个极好的Linux find命令示例 英文原文:Daddy, I found it!, 15 Awesome Linux Find Command Examples 标签: L ...
随机推荐
- RT-Thread定时器以及结构体指针的一些思考
定时器分为软件定时器和硬件定时器.顾名思义,软件定时器就是有操作系统提供的软件定时器,硬件定时器就是用硬件芯片提供的定时器. 而在RT-Thread操作系统提供的定时器是软件定时器,但是为了便于管理, ...
- redis 发布和订阅实现
参考文献 15天玩转redis -- 第九篇 发布/订阅模式 <Redis设计与实现> 命令简介 在redis用户手册中,跟发布订阅相关的命令有如下的六个: PSUBSCRIBE PUBL ...
- 侦听器watch 监听单个属性
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- (转)User-Agent的由来(原来这么有意思)
你是否好奇标识浏览器身份的User-Agent,为什么每个浏览器都有Mozilla字样?Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ( ...
- Egret入门学习日记 --- 第四篇
第四篇(学习篇) 好了,今天继续把昨天的问题解决了. 今天见鬼了. 现在界面又出来了.唯一我动过的地方,应该就是这里: 是的,我点了一下刷新.之后,不管我怎么创建新的EXML文件,放在src目录,还是 ...
- 从无到有构建vue实战项目(五)
八.错误总结(一) webpack打包项目识别子组件路径问题 之所以出现了这样的问题是因为在webpack打包项目时,未将此处的子组件路径正确识别: 将此处的carousel改为carousel.vu ...
- BZOJ3033 太鼓达人题解
太鼓达人 时间限制: 1 Sec 内存限制: 128 MB 题目描述 七夕祭上,Vani牵着cl的手,在明亮的灯光和欢乐的气氛中愉快地穿行.这时,在前面忽然出现了一台太鼓达人机台,而在机台前坐着的是 ...
- weblogic安装时检查监视器: 必须配置为至少显示 256 种颜色,实际空间未知→失败
1.首先如果你出现的结果是[未通过],则设置DISPLAY环境变量. 按网上方法:export DISPLAY=:0.0 然后继续安装你的东西……若成功则恭喜你~ 若[失败],按网上方法让你去看日志 ...
- panic: time: missing Location in call to Time.In
docker容器发布go项目出现以下问题: panic: time: missing Location in call to Time.In COPY --from=build /usr/share/ ...
- 请问 imgbtn上怎样添加文字呢
陈桂城(49868971) 2013/10/14 21:29:57 <imgbtn>文字</imgbtn>