MySQL集群读写分离的自定义实现
基于MySQL Router可以实现高可用,读写分离,负载均衡之类的,MySQL Router可以说是非常轻量级的一个中间件了。
看了一下MySQL Router的原理,其实并不复杂,原理也并不难理解,其实就是一个类似于VIP的代理功能,其中一个MySQL Router有两个端口号,分别是对读和写的转发。
至于选择哪个端口号,需要在申请连接的时候自定义选择,换句话说就是在生成连接字符串的时候,要指明是读操作还是写操作,然后由MySQL Router转发到具体的服务器上。
引用这里的话说就是:
一般来说,通过不同端口实现读/写分离,并非好方法,最大的原因是需要在应用程序代码中指定这些连接端口。
但是,MySQL Router只能通过这种方式实现读写分离,所以MySQL Router拿来当玩具玩玩就好。其原理参考下图,相关安装配置等非常简单。
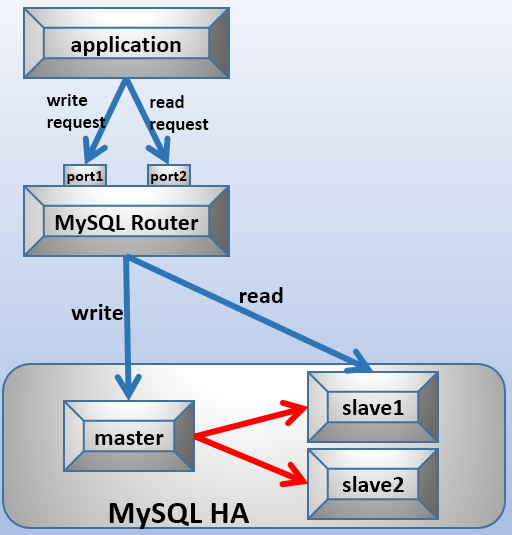
其实暂不论“MySQL Router拿来当玩具玩玩就好”,类似需要自己指定端口(或者说指定读写)来实现读写分离这种方式,自己完全可以实现,又何必用一个中间件呢?
对于MySQL Router来说,它自己本身又是单点的,还要考虑Router自身的高可用(解决了一个问题的同时又引入一个问题)。
很早之前就在想,可不可以尝试不借助中间件,也就无需关注中间件自身的高可用,自己实现读写分离呢?
对于最简单的master-salve复制的集群方式的读写分离,
可以集群中的不同节点指定不同的优先级,把master服务器的优先级指定到最高,其余两个指定成一个较低的优先级
对于应用程序发起的请求,需要指明是读还是写,如果是写操作,就指定到master上执行,如果是读操作,就随机地指向slave操作,完全可以在连接层就实现类似于MySQL Router的功能。
其实非常简单,花不了多久就可以实现类似这么一个功能,在连接层实现读写分离,高可用,负载均衡,demo一个代码实现。
如下简单从数据库连接层实现了读写分离以及负载均衡。
1,写请求指向连接字符串中最高优先级的master,如果指定的最高优先级实例不可用,这里假如是实现了故障转移,依次寻找次优先级的实例
2,slave复制master的数据,读请求随机指向不同的slave,一旦某个slave不可用,继续寻找其他的slave
3,维护一个连接池,连接一律从连接池中获取。
故障转移可以独立实现,不需要在连接层做,连接层也不是做故障转移的。这样一旦发生故障,只要实现了故障转移,应用程序端可以不用做任何修改。
# -*- coding: utf-8 -*-
import pymysql
import random
from DBUtils.PooledDB import PooledDB
import socket class MySQLRouter: operation = None
conn_list = [] def __init__(self, *args, **kwargs):
for k, v in kwargs.items():
setattr(self, k, v) # 探测实例端口号
@staticmethod
def get_mysqlservice_status(host,port):
mysql_stat = None
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = s.connect_ex((host, int(port)))
# port os open
if (result == 0):
mysql_stat = 1
return mysql_stat def get_connection(self):
if not conn_list:
raise("no config error") conn = None
current_conn = None
# 依据节点优先级排序
self.conn_list.sort(key=lambda k: (k.get('priority', 0)))
#写或者未定义请求,一律指向高优先级的服务器,可读写
if(self.operation.lower() == "write") or not self.operation:
for conn in conn_list:
# 如果最高优先级的主节点不可达,这里假设成功实现了故障转移,继续找次优先级的实例。
if self.get_mysqlservice_status(conn["host"], conn["port"]):
current_conn = conn
break
else:
continue
#读请求随机指向不同的slave
elif(self.operation.lower() == "read"):
#随机获取除了最该优先级节点之外的节点
conn_read_list = conn_list[1:len(conn_list)]
random.shuffle(conn_read_list)
for conn in conn_read_list:
#如果不可达,继续寻找其他除了主节点之外的节点
if self.get_mysqlservice_status(conn["host"], conn["port"]):
current_conn = conn
break
else:
continue
try:
#从连接池中获取当前连接
if (current_conn):
pool = PooledDB(pymysql,20, host=current_conn["host"], port=current_conn["port"], user=current_conn["user"], password=current_conn["password"],db=current_conn["database"])
conn = pool.connection()
except:
raise if not conn:
raise("create connection error") return conn; if __name__ == '__main__': #定义三个实例
conn_1 = {'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': 'root',"database":"db01","priority":100}
conn_2 = {'host': '127.0.0.1', 'port': 3307, 'user': 'root', 'password': 'root',"database":"db01","priority":200}
conn_3 = {'host': '127.0.0.1', 'port': 3308, 'user': 'root', 'password': 'root',"database":"db01","priority":300} conn_list = []
conn_list.append(conn_1)
conn_list.append(conn_2)
conn_list.append(conn_3) print("####execute update on master####")
myrouter = MySQLRouter(conn_list=conn_list, operation="write")
conn = myrouter.get_connection()
cursor = conn.cursor()
cursor.execute("update t01 set update_date = now() where id = 1")
conn.commit()
cursor.close()
conn.close() print("####loop execute read on slave,query result####")
#循环读,判断读指向哪个节点。
for loop in range(10):
myrouter = MySQLRouter(conn_list = conn_list,operation = "read")
conn = myrouter.get_connection()
cursor = conn.cursor()
cursor.execute("SELECT id,cast(update_date as char), CONCAT('instance port is: ', CAST( @@PORT AS CHAR)) AS port FROM t01;")
result = cursor.fetchone()
print(result)
cursor.close()
conn.close()
这里用过服务器的一个优先级,将写请求指向最高优先级的master服务器,读请求随机指向非最高优先级的slave,
对于更新请求,都在master上执行,slave复制了master的数据,每次读到的数据都不一样,并且每次都请求的执行,基本上都随机地指向了两台slave服务器
通过查询返回一个端口号,来判断读请求是否平均分散到了不通的slave端。

与“MySQL Router拿来当玩具玩玩就好”相比,这里的实现一样low,因为对数据的请求需要请求明确指定是读还是写。
不过,对于自动读写分离,无非是一个SQL语句执行的是的读或写判断问题,并非难事,这个需要解析请求的SQL是读的还是写的问题。
某些数据库中间件可以实现自动的读写分离,但是要明白,对于那些支持自动读写分离的中间件,往往是要受到一定的约束的,比如不能用存储过程什么的,为什么呢?
还是上面提到的SQL解析的问题,因为一旦使用了存储过程,无法解析出来这个SQL到底是执行的是读还是写,最起码不是太直接。
对于SQL读写的判断,也就是维护一个读或者写的枚举正则表达式,非读即写,只是要格外关注这个读写的判断的效率问题。
MySQL集群读写分离的自定义实现的更多相关文章
- docker+mysql集群+读写分离+mycat管理+垂直分库+负载均衡
依然如此,只要大家跟着我的步骤一步步来,100%是可以测试成功的 centos6.8已不再维护,可能很多人的虚拟机中无法使用yum命令下载docker, 但是阿里源还是可以用的 因为他的centos- ...
- Mysql集群读写分离(Amoeba)
Amoeba原理戳这里:Amoeba详细介绍 实验环境 Master.Amoeba--IP:192.168.1.5 Slave---IP:192.168.1.10 安装JDK JDK下载地址:http ...
- 使用mysql-proxy 快速实现mysql 集群 读写分离
目前较为常见的mysql读写分离分为两种: 1. 基于程序代码内部实现:在代码中对select操作分发到从库:其它操作由主库执行:这类方法也是目前生产环境应用最广泛,知名的如DISCUZ X2.优点是 ...
- MySQL集群系列2:通过keepalived实现双主集群读写分离
在上一节基础上,通过添加keepalived实现读写分离. 首先关闭防火墙 安装keepalived keepalived 2台机器都要安装 rpm .el6.x86_64/ 注意上面要替换成你的内核 ...
- 十四、linux-MySQL的数据库集群读写分离及高可用性、备份等
一.数据库集群及高可用性 二.mysql实现读写分离 mysql实现读写分离有多种方式: 1)代码语言(php\python\java等)层面实现读写分离,找开发进行实现. 2)通过软件工具实现读写分 ...
- 利用MySQL Router构建读写分离MGR集群
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 目录 1. 部署MySQL Router 2. 启动mysqlrouter服务 3. 确认读写分离效果 4. 确认只读负载 ...
- linux上使用amoeba实现MySql集群,以及读写分离,主从复制
一.由于是MySql集群,所以就不可能只有一个MySql,需要多个MySql,具体安装步骤,可以参考http://www.cnblogs.com/ywzq/p/4882140.html这个地址进行安装 ...
- MySQL集群(三)mysql-proxy搭建负载均衡与读写分离
前言 前面学习了主从复制和主主复制,接下来给大家分享一下怎么去使用mysql-proxy这个插件去配置MySQL集群中的负载均衡以及读写分离. 注意:这里比较坑的就是mysql-proxy一直没有更新 ...
- 2.Mysql集群------Mycat读写分离
前言: Mycat: 一个彻底开源的,面向企业应用开发的大数据库集群 支持事务.ACID.可以替代MySQL的加强版数据库 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群 一 ...
随机推荐
- 最全的防火墙(firewalld)
第1章 防火墙的介绍 1.1 防火墙的介绍 1.1.1 概念 动态管理防火墙服务(图形界面和linux界面都可以实现) 支持不同防火墙的区域信息 属于传输层次的防火墙 1.1.2 防火墙的默认规则 ...
- FPGA+VGA+OV7725 视频图像FPGA开发板 图像采集板CP511A使用
- jvm调优、常用工具
ps -ef | grep java查出进程id jmap -heap ID 查出jvm配置信息 加入参数:打印Gc日志,分析 GC日志分析工具: GCeasy 降低minor gc 和 full g ...
- Jenkins编译过程中出现ERROR_ Failed to parse POMs错误
一.在使用jenkins编写过程中突然出现以下问题 Parsing POMs Established TCP socket on 59407 [java] $ java -cp /var/lib/je ...
- Unity各平台宏定义
属性 方法 UNITY_EDITOR #define directive for calling Unity Editor scripts from your game code. UNITY_EDI ...
- python并发之多进程
#mutiprocessing模块 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程.Pytho ...
- SSM(Spring+SpringMVC+Mybatis)框架整合
1.数据准备 SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for `admin` -- - ...
- Centos+Nginx+NetCore3.1
Centos+Nginx+NetCore3.1部署 1 先将vs2019升级到,16.4.0版本 2.新建一.netcore3.1的web程序 3.编译后将项目上传到centos服务器 4.配置ngi ...
- 在Chrome 中使用Vimium
原文连接:https://blog.csdn.net/wuxianjiezh/article/details/91848604 Vimium:像在 Vim 中一样使用 Chrome 安装 使用方法 在 ...
- 新人踩坑的一天——springboot注入mapper时出现java.lang.NullPointerException: null
来公司的第二周接到了定时任务的开发需求:每天早上十点发送用户报表邮件 .校招新人菜鸟没做过这玩意有些懵(尴尬)于是决定分步写,从excel导出->邮件发送->定时器实现->mappe ...