Elastic Stack 笔记(一)CentOS7.5 搭建 Elasticsearch5.6 集群
一、前言
Elasticsearch 是一个基于 Lucene 的分布式搜索引擎服务,采用 Java 语言编写,使用 Lucene 构建索引、提供搜索功能。虽然 Lucene 的功能已经非常强大,但是 Lucene 只是一个由 Java 语言编写的库,专注底层搜索的建设,而 Elasticsearch 专注于企业应用。
基于 Elasticsearch 衍生出来了一系列开源软件,统称为 Elastic Stack,主要包括分布式搜索引擎 Elasticsearch 、日志采集与解析工具 Logstash、可视化分析平台 Kibana、数据采集工具 Beats 家族等。在没有引入 Beats 之前,Elasticsearch、Logstash、Kibana 三者简称为 ELK Stack,是非常流行的日志解决方案。后来 Elastic 公司推出了 Beats 家族,在数据收集方面使用 Beats 取代了 Logstash,解决了 Logstash 在各服务器节点上占用系统资源高的问题。此外还有 X-Pack 也是 Elastic Stack 的扩展,将安全、警告、监视、报告和图形功能包含在一个易于安装的软件包中。在 Elasticsearch 5.x 之前,必须单独安装 shield、watcher 和 Marvel 插件才能获得在 X-Pack 中所有的功能。
二、搭建 Elasticsearch5.6.0 集群
首先是单节点安装,安装好之后,其他节点方法相同,只需要修改一下 Elasticsearch 的 elasticsearch.yml 文件,设置好自己的角色和绑定自己的 IP 即可。如果是多节点集群,则首先要安装 SSH(Secure Shell),生成密钥对,设置 SSH 无密码登录,且所有节点都需要安装设置。
2.1 查看当前 Linux 发行版本号和系统位数
[root@masternode ~]# cat /etc/redhat-release
CentOS Linux release 7.5. (Core)
[root@masternode ~]# getconf LONG_BIT
得知系统版本为 CentOS 7.5 x64。
2.2 安装 JDK 8.x
下载 JDK
Elasticsearch 5.x 及以上的版本要求 JDK 版本不低于 1.8,此处安装 JDK 1.8.162。
JDK 所有版本下载地址为:http://www.oracle.com/technetwork/java/javase/archive-139210.html,请注意下载的是JDK,而不是 JRE,如下图:
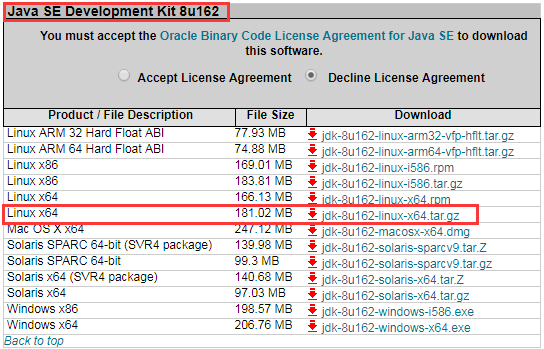
安装 JDK
首先创建需要安装到的目录:
[root@masternode ~]# mkdir /opt/jdk
然后解压压缩包:
tar zxvf /usr/software/jdk-8u162-linux-x64.tar.gz -C /opt/jdk
此时会将压缩包的内容解压到刚才创建的 /opt/jdk 目录下:
[root@masternode ~]# ls /opt/jdk
jdk1..0_162
设置 Java 环境变量
[root@masternode ~]# vim /etc/profile
在最后添加:
#Java variables
export JAVA_HOME=/opt/jdk/jdk1..0_162
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib
export CLASSPATH=$CLASSPATH:$JAVA_HOME/jre/lib
保存后,执行如下命令使配置文件在当前 shell 环境生效:
[root@masternode ~]# source /etc/profile
检查 JDK 是否安装成功:
[root@masternode ~]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) -Bit Server VM (build 25.162-b12, mixed mode)
也可以解压到任意目录,然后 mv 到指定目录。
2.3 安装 Elasticsearch
下载 Elasticsearch 5.6.0
访问 Elastic 官网所有版本下载地址:https://www.elastic.co/downloads/past-releases,选择需要的版本,此处选择 5.6.0,如下:

安装 Elasticsearch
首先创建 /opt/elk 目录,如下:
[root@masternode ~]# mkdir /opt/elk
解压 Elasticsearch:
tar zxvf /usr/software/elasticsearch-5.6..tar.gz -C /opt/elk
此时会将压缩包的内容解压到刚才创建的 /opt/elk 目录下:
[root@masternode ~]# ls /opt/elk
elasticsearch-5.6.
也可以解压到任意目录,然后 mv 到指定目录。
2.4 创建 Elasticsearch 账户
在 Elasticsearch 5.0 之后,不能使用 root 账户启动,elasticsearch 必须使用非root用户启动,需要先创建一个 Elasticsearch 的账户和组,如下:
[root@masternode ~]# useradd esuser
[root@masternode ~]# passwd esuser
[root@masternode ~]# chown -R esuser:esuser /opt/elk/elasticsearch-5.6.
[root@masternode ~]# ll /opt/elk
total
drwxr-xr-x. esuser esuser May : elasticsearch-5.6.
如上所示,elasticsearch 的用户和所属组都已经改成了 esuser。
2.5 设置 es 的配置文件
主配置文件:/opt/elk/elasticsearch-5.6.0/config/elasticsearch.yml
jvm参数配置文件:/opt/elk/elasticsearch-5.6.0/config/jvm.options
日志配置文件:/opt/elk/elasticsearch-5.6.0/cofnig/log4j2.properties
此处主要设置主配置文件:elasticsearch.yml,注意 es 5.0 之后,在此配置文件中不能再指定索引级别的配置了,如 index.number_of_shards: 5 和 index.number_of_replicas: 1。
#Elasticsearch params
cluster.name: Banon
node.name: masternode
node.master: true
node.data: true
network.host: 192.168.56.110
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.56.110"]
以上设置项目的简单说明:
cluster.name: Banon,可以确定你的集群名称,当你的 elasticsearch 集群在同一个网段中,elasticsearch 会自动的找到具有相同 cluster.name 的 elasticsearch 服务,并自动加入该集群,默认值为:elasticsearch。
node.name: masternode,节点名称,可自动生成也可手动配置,默认值为随机指定一个漫威漫画中 3000 多个角色的名字。
node.master: true,允许一个节点是否可以成为一个 master 节点,es 是默认集群中的第一台机器为 master,如果这台机器停止就会重新选举 master,默认值为 true。
node.data: true,允许该节点存储数据,默认值为 true。
network.host: 192.168.56.110,绑定监听的 IP,可以是 IPv4 或 IPv6 的地址,默认为 0.0.0.0。
http.port: 9200,设置对外服务的http端口,默认为 9200。
transport.tcp.port: 9300,设置节点间交互的tcp端口,默认是 9300。
discovery.zen.ping.unicast.hosts: ["192.168.56.119"],这是一个集群中的主节点的初始列表,当节点(主节点或者数据节点)启动时使用这个列表进行探测,可以设置多个,格式为:["host1", "host2:port"],默认为 ["127.0.0.1", "[::1]"]。
注意:
1. es 5.0 之前可以在该配置文件中设置如下两个参数,5.0 之后已经不能指定索引级别的配置了:
index.number_of_shards: 5,设置索引的分片数,默认为 5。
index.number_of_replicas: 1,设置索引的副本数,默认为 1。
2. 根据 node.master 和 node.data 设置的不同值,配置文件中给出了几种配置高性能集群拓扑结构的模式,如下:
1)如果你想让节点从不选举为主节点,只用来存储数据,可作为负载器
node.master: false
node.data: true
node.ingest: true #默认true
2)如果想让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调器
node.master: true
node.data: false
node.ingest: true
3)如果想让节点既不称为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等
node.master: false
node.data: false
node.ingest: true
4)仅作为协调器
node.master: false
node.data: false
node.ingest: false
3. 注意 YAML 的语法:
1)使用空格 Space 缩进表示分层,不同层次之间的缩进可以使用不同的空格数目,但是同层元素一定左对齐,即前面空格数目相同(不能使用 Tab,各个系统 Tab对应的 Space 数目可能不同,导致层次混乱);
2)'#'表示注释,只能单行注释,从#开始处到行尾;
3)破折号后面跟一个空格(a dash and space)表示列表;
4)用冒号和空格表示键值对 key: value;(冒号后、value前有一个空格)
5)简单数据(scalars,标量数据)可以不使用引号括起来,包括字符串数据。用单引号或者双引号括起来的被当作字符串数据,在单引号或双引号中使用C风格的转义字符。
2.6 开启需要使用到的端口
如果我们想在另外机器的浏览器地址栏直接输入网址:http://192.168.56.110:9200 来访问,前提是开启了 9200 端口,由于集群中不同节点之间也需要互相访问,所以还需要开启 9300 端口。
CentOS7.x 永久开启如下两个端口:
[root@localhost ~]# firewall-cmd --zone=public --add-port=9200/tcp --permanent
[root@localhost ~]# firewall-cmd --zone=public --add-port=9300/tcp --permanent
重启防火墙:
[root@localhost ~]# firewall-cmd --reload
在之前的 CentOS 版本(比如5和6)的防火墙为 netfilter,CentOS7 的防火墙为 firewalld。很多人将Linux之前版本的防火墙称作 iptables,其实 iptables 仅仅是 netfilter 中的一个工具,可自行搜索设置,此处不再讲解。
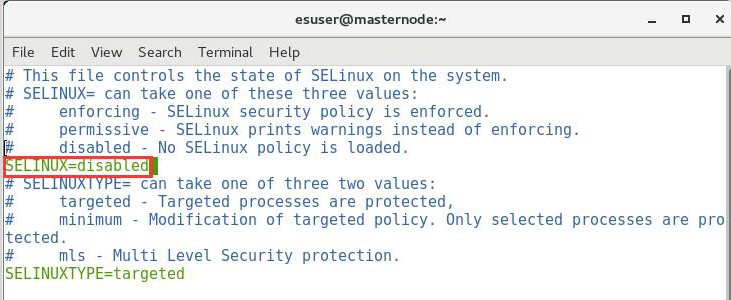
同时,我们将 selinux 也一起关闭掉,置为 disabled 即可,selinux 是 RedHat/CentOS 系统特有的安全机制,因为这种机制限制太多,而且配置也过于繁琐,所以很少有人去使用它。使用如下命令修改:# vi /etc/selinux/config,如图:
2.7 启动 Elasticsearch
es 5.0 之后不能使用 root 账户启动 es 了,使用我们上面新建的 esuser 账户启动。
控制台启动命令为:
[esuser@masternode elasticsearch-5.6.]$ pwd
/opt/elk/elasticsearch-5.6.
[esuser@masternode elasticsearch-5.6.]$ ./bin/elasticsearch
如果出现 started 字符串提示,则表示已经正常启动了。
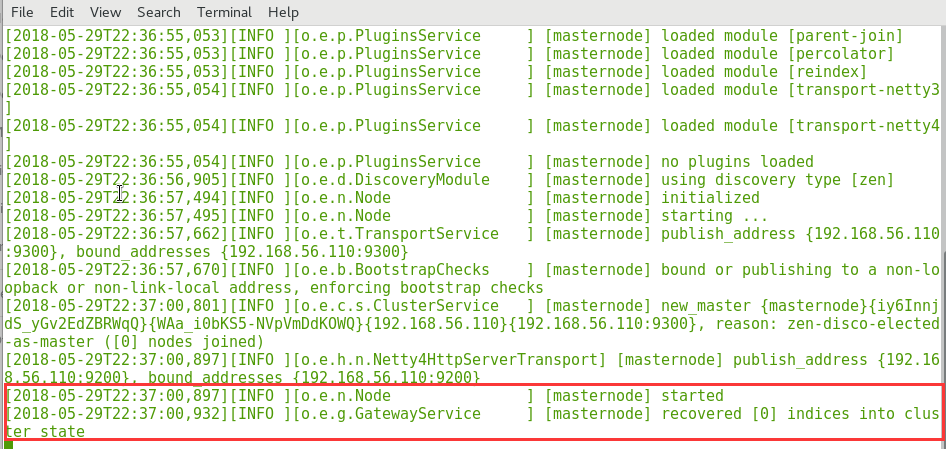
也有可能在第一次启动时遇到如下 error:

可参考本文附录进行设置。
控制台启动的方式适合于开发阶段或者测试阶段,能够及时发现错误,并且能立刻关闭,只需要按 ctrl + c 组合键即可结束前台进程。如果在生产环境中,Elasticsearch 应当作为系统服务在后台启动。
后台启动 Elasticsearch 的命令如下:
[esuser@masternode elasticsearch-5.6.]$ ./bin/elasticsearch -d
但是,后台启动之后,如果想关闭 es,则首先需要找到 es 的进程 id,即 PID,然后使用 kill PID 结束 es 进程。
查找 Elasticsearch 进程 id 可以使用 jps 命令,也可以使用 ps aux |grep elasticsearch 命令,如下所示:
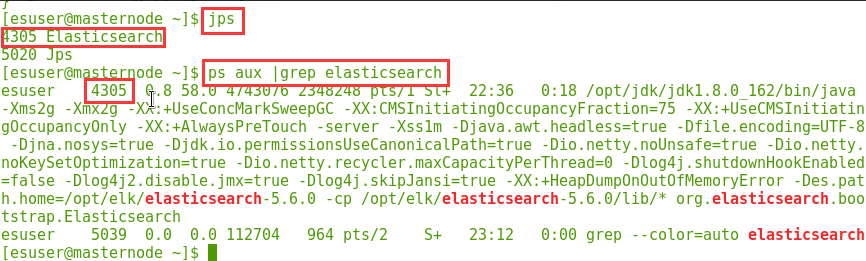
因为 Elasticsearch 是运行在 JVM 之上的,所以可以使用 jps(Java Virtual Machine Process Status Tool 的缩写,是 JDK 提供的 一个查看当前 Java 进程的小工具,可在 JDK 的安装目录下找到该工具:opt/jdk/jdk1.8.0_162/bin)命令查看 Elasticsearch 是否启动成功,已经成功后的进程 PID。
正常启动后,我们可以在其他及其上,使用浏览器进行访问:

也可以使用 curl 访问:

返回的结果是一样的,此时,如果在当前集群节点上访问 http://localhost:9200/,是访问不到的,因为我们上面的配置文件中绑定的 network.host 为:192.168.56.110。
通过返回结果可以知道,已经启动了一个名为 masternode 的 Elasticsearch 节点,加入的集群是 Banon,Elasticsearch 的版本是 5.6.0,版本发行日期为 2017-09-07,Lucene 的版本为 6.6.0。
创建集群的其他节点
当上面的节点创建好之后,将其创建为基础镜像,然后安装好其他的节点,然后设置如下:
1)设置主机名称为 datanode1:
[root@masternode ~]# vim /etc/hostname
[root@masternode ~]# cat /etc/hostname
datanode1
2)设置 static 静态IP 为 192.168.56.111:
[root@masternode network-scripts]# pwd
/etc/sysconfig/network-scripts
[root@masternode network-scripts]# cat ifcfg-enp0s8
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="enp0s8"
DEVICE="enp0s8"
ONBOOT="yes"
IPADDR="192.168.56.111"
NETMASK=255.255.255.0
ZONE=public
3)编辑 /opt/elk/elasticsearch-5.6.0/config/elasticsearch.yml,修改 IP network.host: 192.168.56.111
#Elasticsearch params
cluster.name: Banon
node.name: datanode1
node.master: false
node.data: true
network.host: 192.168.56.111
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.56.110"]
http.cors.enabled: true
http.cors.allow-origin: "*"
设置好之后重启这个机器,这个新的节点即可加入集群。
需要注意的是:创建基础镜像时,Elasticsearch 的 data 目录下应该是空的,不要存在数据,否则使用该基础镜像创建的节点在启动时会出现如下错误:……with the same id but is a different node instance
查看集群健康状态:http://192.168.56.110:9200/_cluster/health?pretty
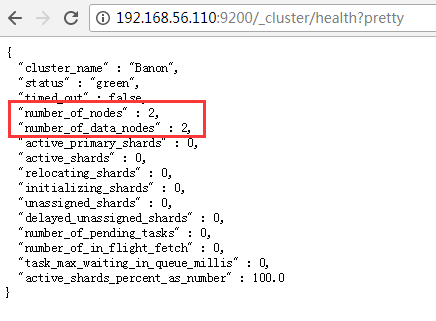
可以看出启动了两个节点,且均为 data 节点(第一个节点 masternode 既为 master 节点也同时为 data 节点,第二个节点 datanode 只是 data 节点)。
为了避免版本混乱,从 5.0 版本开始,Elastic 公司将各组件的版本号统一。使用时,各组件版本号应该一致,Elastic Static 的版本号形式为 X.Y.Z,例如 5.6.0,各组件的 Z 可以不相同,但是 X 和 Y 必须一致。
附录
第一次启动 Elasticsearch 时,出现 ERROR: bootstrap checks failed 的解决方案:
1、 错误:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
原因:在 Linux 的系统中对于进程会有一些限制
解决办法:
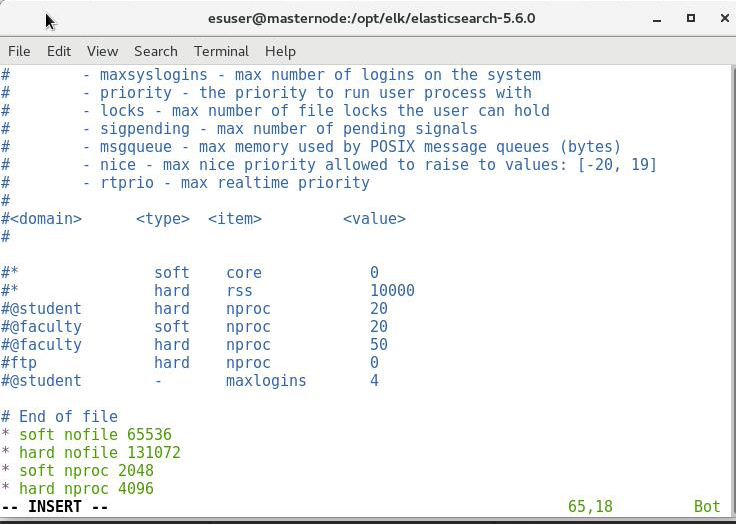
使用 root 用户,编辑 /etc/security/limits.conf
[root@localhost elasticsearch]# vi /etc/security/limits.conf
在文件末尾加入以下代码:
elasticsearch soft nofile 65536
elasticsearch hard nofile 131072
elasticsearch soft nproc 2048
elasticsearch hard nproc 4096
然后,保存并退出,如下:
2、 错误:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
原因:操作系统的 vm.max_map_count 参数设置太小导致的
解决办法:
使用 root 用户,修改 /etc/sysctl.conf 文件,使其永久生效。
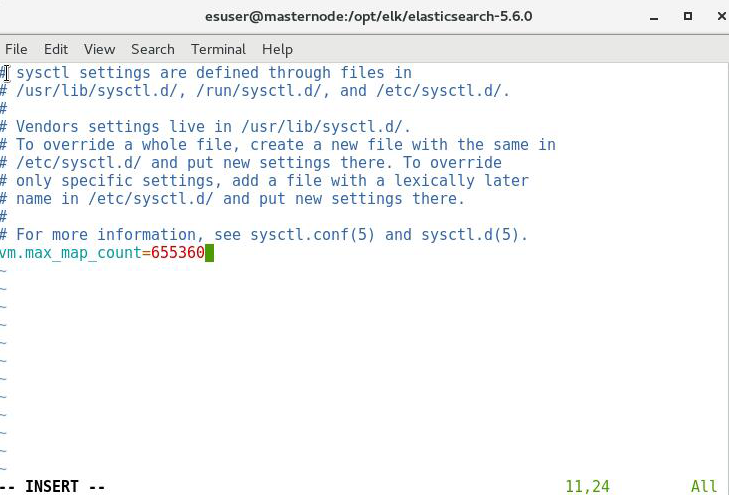
[root@localhost ~]# vi /etc/sysctl.conf
在文件末尾添加这一行:
vm.max_map_count=655360
保存并退出,如下:
更多问题可参考如下文章:
Elastic Stack 笔记(一)CentOS7.5 搭建 Elasticsearch5.6 集群的更多相关文章
- CentOS7.5搭建Hadoop分布式集群
材料:3台虚拟主机,ip分别为: 192.168.1.201 192.168.1.202 192.168.1.203 1.配置主机名称 三个ip与主机名称分别对应关系如下: 192.168.1.201 ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
- centos7搭建ELK Cluster集群日志分析平台
应用场景:ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平台 ...
- 虚拟机搭建Zookeeper服务器集群完整笔记
虚拟机搭建Zookeeper服务器集群完整笔记 本笔记主要记录自己搭建Zookeeper服务器的全过程,默认已经安装部署好Centos7. 一.虚拟机下Centos无法联网解决方案 1.首先调整虚拟机 ...
- centos7搭建ELK Cluster集群日志分析平台(四):Fliebeat-简单测试
续之前安装好的ELK集群 各主机:es-1 ~ es-3 :192.168.1.21/22/23 logstash: 192.168.1.24 kibana: 192.168.1.25 测试机:cli ...
- centos7搭建ELK Cluster集群日志分析平台(三):Kibana
续 centos7搭建ELK Cluster集群日志分析平台(一) 续 centos7搭建ELK Cluster集群日志分析平台(二) 已经安装好elasticsearch 5.4集群和logst ...
- centos7搭建ELK Cluster集群日志分析平台(二):Logstash
续 centos7搭建ELK Cluster集群日志分析平台(一) 已经安装完Elasticsearch 5.4 集群. 安装Logstash步骤 . 安装Java 8 官方说明:需要安装Java ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- RocketMQ学习笔记(4)----RocketMQ搭建双Master集群
前面已经学习了RockeMQ的四种集群方式,接下来就来搭建一个双Master(2m)的集群环境. 1. 双Master服务器环境 序号 ip 用户名 密码 角色 模式 (1) 47.105.145.1 ...
随机推荐
- Shiro权限注解原理
概述 前不久刚学会使用权限注解(),开始思索了一番.最开始猜测实现方式是注解@Aspect,具体实现方式类似如下所示(切面记录审计日志).后来发现并非如此,所以特地分析一下源码. @Component ...
- 自然语言处理(NLP)的一般处理流程!
1. 什么是NLP 自然语言处理 (Natural Language Processing) 是人工智能(AI)的一个子领域.自然语言处理是研究在人与人交互中以及在人与计算机交互中的语言问题的一门学科 ...
- Eclipse导入spring-boot-plus(三)
Eclipse导入spring-boot-plus 安装lombok插件 !!!请先确保Eclipse已安装lombok插件!!!
- tab栏切换制作
tab栏切换制作 先上图 要求1:默认状态,第一个选项卡被选中,展示第一个选项卡的内容 策略:第一个选项卡默认有被选中的样式,第一个选项卡对应的display: block,其他的dispaly设为n ...
- 梳理commons-lang工具包
目录 概述 builder包 NumberUtils 转换 String 类型为原始类型 截取小数位数 创建包装类型 最大值 | 最小值 关于数字的检查 mutable包 relect包 Constr ...
- 真正加速Jenkins安装插件速度
本文主旨 看到好多加速Jenkins安装插件速度的文章, 大多数教程中都是在插件配置里使用下边的url来替换原有的https://mirrors.tuna.tsinghua.edu.cn/jenkin ...
- Liunx软件安装之Redis
Redis是一个开源(BSD许可),内存数据结构存储,用作数据库,缓存和消息代理.它支持数据结构,如字符串,散列,列表,集合,带有范围查询的排序集,位图,超级日志和带有半径查询的地理空间索引.Redi ...
- JDBC主要API学习总结
JDBC主要API学习 一.JDBC主要API简介 JDBC API 是一系列的接口,它使得应用程序能够进行数据库联接,执行SQL语句,并且得到返回结果. 二.Driver 接口 Java.sql.D ...
- Oracle数据库之六 单行函数
六.单行函数 6.1.认识单行函数 函数就是和 Java 语言之中的方法的功能是一样的,都是为了完成某些特定操作的功能支持,而在 Oracle 数据库里面也包含了大量的单行函数,这些函数掌握了以后 ...
- MySQL之PXC集群搭建
一.PXC 介绍 1.1 PXC 简介 PXC 是一套 MySQL 高可用集群解决方案,与传统的基于主从复制模式的集群架构相比 PXC 最突出特点就是解决了诟病已久的数据复制延迟问题,基本上可以达到实 ...