Azkaban学习之路(四)—— Azkaban Flow 2.0的使用
一、Flow 2.0 简介
1.1 Flow 2.0 的产生
Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用Flow 2.0,因为Flow 1.0会在将来的版本被移除。Flow 2.0的主要设计思想是提供1.0所没有的流级定义。用户可以将属于给定流的所有job / properties文件合并到单个流定义文件中,其内容采用YAML语法进行定义,同时还支持在流中再定义流,称为为嵌入流或子流。
1.2 基本结构
项目zip将包含多个流YAML文件,一个项目YAML文件以及可选库和源代码。Flow YAML文件的基本结构如下:
- 每个Flow都在单个YAML文件中定义;
- 流文件以流名称命名,如:
my-flow-name.flow; - 包含DAG中的所有节点;
- 每个节点可以是作业或流程;
- 每个节点 可以拥有 name, type, config, dependsOn 和 nodes sections等属性;
- 通过列出dependsOn列表中的父节点来指定节点依赖性;
- 包含与流相关的其他配置;
- 当前properties文件中流的所有常见属性都将迁移到每个流YAML文件中的config部分。
官方提供了一个比较完善的配置样例,如下:
config:
user.to.proxy: azktest
param.hadoopOutData: /tmp/wordcounthadoopout
param.inData: /tmp/wordcountpigin
param.outData: /tmp/wordcountpigout
# This section defines the list of jobs
# A node can be a job or a flow
# In this example, all nodes are jobs
nodes:
# Job definition
# The job definition is like a YAMLified version of properties file
# with one major difference. All custom properties are now clubbed together
# in a config section in the definition.
# The first line describes the name of the job
- name: AZTest
type: noop
# The dependsOn section contains the list of parent nodes the current
# node depends on
dependsOn:
- hadoopWC1
- NoOpTest1
- hive2
- java1
- jobCommand2
- name: pigWordCount1
type: pig
# The config section contains custom arguments or parameters which are
# required by the job
config:
pig.script: src/main/pig/wordCountText.pig
- name: hadoopWC1
type: hadoopJava
dependsOn:
- pigWordCount1
config:
classpath: ./*
force.output.overwrite: true
input.path: ${param.inData}
job.class: com.linkedin.wordcount.WordCount
main.args: ${param.inData} ${param.hadoopOutData}
output.path: ${param.hadoopOutData}
- name: hive1
type: hive
config:
hive.script: src/main/hive/showdb.q
- name: NoOpTest1
type: noop
- name: hive2
type: hive
dependsOn:
- hive1
config:
hive.script: src/main/hive/showTables.sql
- name: java1
type: javaprocess
config:
Xms: 96M
java.class: com.linkedin.foo.HelloJavaProcessJob
- name: jobCommand1
type: command
config:
command: echo "hello world from job_command_1"
- name: jobCommand2
type: command
dependsOn:
- jobCommand1
config:
command: echo "hello world from job_command_2"
二、YAML语法
想要使用 Flow 2.0 进行工作流的配置,首先需要了解YAML 。YAML 是一种简洁的非标记语言,有着严格的格式要求的,如果你的格式配置失败,上传到Azkaban的时候就会抛出解析异常。
2.1 基本规则
- 大小写敏感 ;
- 使用缩进表示层级关系 ;
- 缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级;
- 使用#表示注释 ;
- 字符串默认不用加单双引号,但单引号和双引号都可以使用,双引号表示不需要对特殊字符进行转义;
- YAML中提供了多种常量结构,包括:整数,浮点数,字符串,NULL,日期,布尔,时间。
2.2 对象的写法
# value 与 : 符号之间必须要有一个空格
key: value
2.3 map的写法
# 写法一 同一缩进的所有键值对属于一个map
key:
key1: value1
key2: value2
# 写法二
{key1: value1, key2: value2}
2.3 数组的写法
# 写法一 使用一个短横线加一个空格代表一个数组项
- a
- b
- c
# 写法二
[a,b,c]
2.5 单双引号
支持单引号和双引号,但双引号不会对特殊字符进行转义:
s1: '内容\n字符串'
s2: "内容\n字符串"
转换后:
{ s1: '内容\\n字符串', s2: '内容\n字符串' }
2.6 特殊符号
一个YAML文件中可以包括多个文档,使用---进行分割。
2.7 配置引用
Flow 2.0 建议将公共参数定义在config下,并通过${}进行引用。
三、简单任务调度
3.1 任务配置
新建flow配置文件:
nodes:
- name: jobA
type: command
config:
command: echo "Hello Azkaban Flow 2.0."
在当前的版本中,Azkaban同时支持 Flow 1.0 和 Flow 2.0,如果你希望以2.0的方式运行,则需要新建一个project文件,指明是使用的是Flow 2.0:
azkaban-flow-version: 2.0
3.2 打包上传

3.3 执行结果
由于在1.0 版本中已经介绍过Web UI的使用,这里就不再赘述。对于1.0和2.0版本,只有配置方式有所不同,其他上传执行的方式都是相同的。执行结果如下:
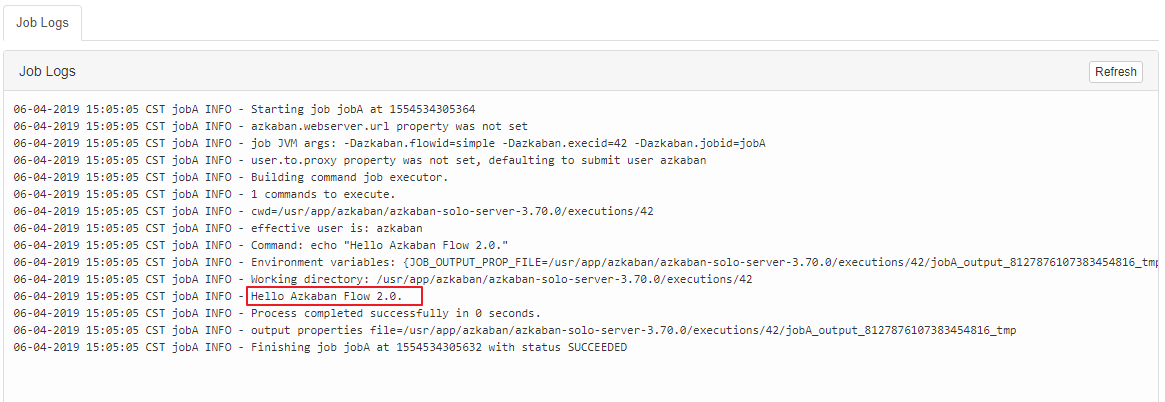
四、多任务调度
和1.0给出的案例一样,这里假设我们有五个任务(jobA——jobE), D 任务需要在A,B,C任务执行完成后才能执行,而 E 任务则需要在 D 任务执行完成后才能执行,相关配置文件应如下。可以看到在1.0中我们需要分别定义五个配置文件,而在2.0中我们只需要一个配置文件即可完成配置。
nodes:
- name: jobE
type: command
config:
command: echo "This is job E"
# jobE depends on jobD
dependsOn:
- jobD
- name: jobD
type: command
config:
command: echo "This is job D"
# jobD depends on jobA、jobB、jobC
dependsOn:
- jobA
- jobB
- jobC
- name: jobA
type: command
config:
command: echo "This is job A"
- name: jobB
type: command
config:
command: echo "This is job B"
- name: jobC
type: command
config:
command: echo "This is job C"
五、内嵌流
Flow2.0 支持在一个Flow中定义另一个Flow,称为内嵌流或者子流。这里给出一个内嵌流的示例,其Flow配置如下:
nodes:
- name: jobC
type: command
config:
command: echo "This is job C"
dependsOn:
- embedded_flow
- name: embedded_flow
type: flow
config:
prop: value
nodes:
- name: jobB
type: command
config:
command: echo "This is job B"
dependsOn:
- jobA
- name: jobA
type: command
config:
command: echo "This is job A"
内嵌流的DAG图如下:
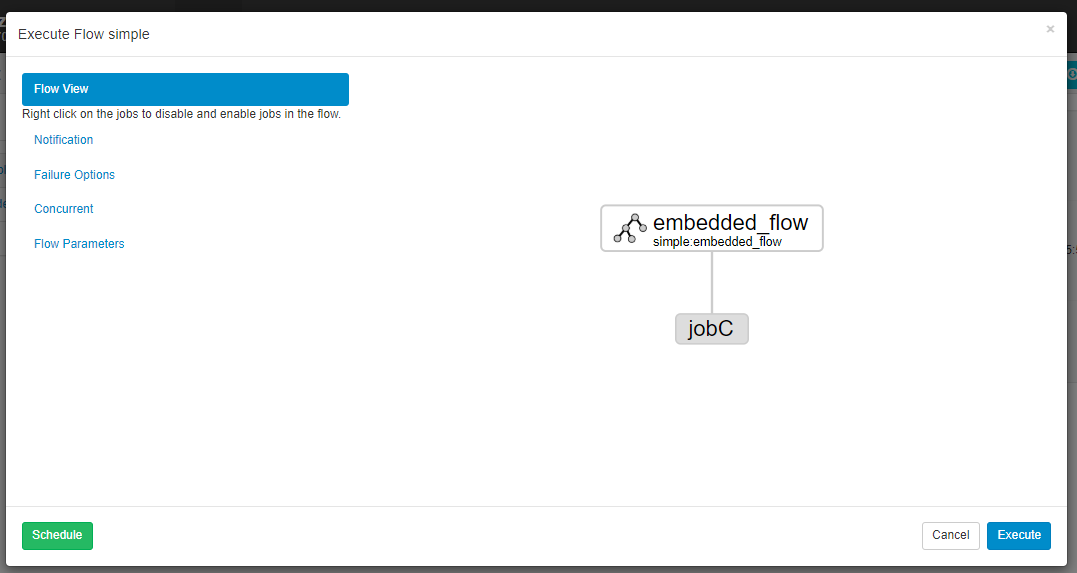
执行情况如下:

参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Azkaban学习之路(四)—— Azkaban Flow 2.0的使用的更多相关文章
- Azkaban学习之路(三)—— Azkaban Flow 1.0 的使用
一.简介 Azkaban主要通过界面上传配置文件来进行任务的调度.它有两个重要的概念: Job: 你需要执行的调度任务: Flow:一个获取多个Job及它们之间的依赖关系所组成的图表叫做Flow. 目 ...
- Azkaban学习之路 (二)Azkaban的安装
安装过程 1.软件介绍 Azkaban Web 服务器:azkaban-web-server-2.5.0.tar.gz Azkaban Excutor 执行服务器:azkaban-executor-s ...
- Azkaban学习之路 (一)Azkaban的基础介绍
一.为什么需要工作流调度器 1.一个完整的数据分析系统通常都是由大量任务单元组成: shell 脚本程序,java 程序,mapreduce 程序.hive 脚本等 2.各任务单元之间存在时间先后及前 ...
- Azkaban学习之路(一)—— Azkaban 简介
一.Azkaban 介绍 1.1 背景 一个完整的大数据分析系统,必然由很多任务单元(如数据收集.数据清洗.数据存储.数据分析等)组成,所有的任务单元及其之间的依赖关系组成了复杂的工作流.复杂的工作流 ...
- Redis——学习之路四(初识主从配置)
首先我们配置一台master服务器,两台slave服务器.master服务器配置就是默认配置 端口为6379,添加就一个密码CeshiPassword,然后启动master服务器. 两台slave服务 ...
- Azkaban学习之路 (三)Azkaban的使用
界面介绍 首页有四个菜单 projects:最重要的部分,创建一个工程,所有flows将在工程中运行. scheduling:显示定时任务 executing:显示当前运行的任务 history:显示 ...
- Azkaban学习之路(二)—— Azkaban 3.x 编译及部署
一.Azkaban 源码编译 1.1 下载并解压 Azkaban 在3.0版本之后就不提供对应的安装包,需要自己下载源码进行编译. 下载所需版本的源码,Azkaban的源码托管在GitHub上,地址为 ...
- zigbee学习之路(四):按键控制(中断方式)
一.前言 通过上次的学习,我们学习了如何用按键控制led,但是在实际应用中,这种查询方式占用了cpu的时间,如果通过中断控制就可以解决这个问题,我们今天就来学习按键控制的中断方式. 二.原理分析 传统 ...
- [原创]java WEB学习笔记79:Hibernate学习之路--- 四种对象的状态,session核心方法:save()方法,persist()方法,get() 和 load() 方法,update()方法,saveOrUpdate() 方法,merge() 方法,delete() 方法,evict(),hibernate 调用存储过程,hibernate 与 触发器协同工作
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
随机推荐
- UML静态视图——类图、对象图、包图
绘画类的最重要的图是抽象类.让我们回顾一下类的基本内容. 一.分类 1.类的概念: 面向对象编程的类是一个基本概念.类是具有相同特性的.办法.集合语义和一组对象的关系. 2.类分类: 实体类:保存要放 ...
- JQuery在一个简单的表单验证的例子
html代码例如以下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http:/ ...
- 写在程序猿的困惑(特别Java程序猿)入行一年,感觉我不知道接下来该怎么办才能不断进步的,寻求翼
入行了一年.感觉不知道接下来该怎么做才干继续进步了,求不吝赐教(V2EX) @kafka0102 :做技术能够学的东西太多了.仅仅是在不同的阶段做好不同的规划.要结合当前所做的事情去做更深入或广度的学 ...
- wpf Storyboard 不存在可解析名称“ ”的适用名称领域 No applicable name scope exists to resolve the name
原文:wpf Storyboard 不存在可解析名称“ ”的适用名称领域 No applicable name scope exists to resolve the name 写了一个 Storyb ...
- CefSharp For WPF基本使用
原文:CefSharp For WPF基本使用 Nuget引用 CefSharp.Wpf CefSharp.Common cef.redist.x64 cef.redist.x86 直接搜索安装Cef ...
- WPF- 模拟触发Touch Events
原文:WPF- 模拟触发Touch Events 基于API: [DllImport("User32.dll")] public static extern bool Initia ...
- ASP .NET My97DatePicker
My97DatePicker http://jingyan.baidu.com/article/e6c8503c7244bae54f1a18c7.html <input type="t ...
- mysql 视图,存储过程,游标,触发器,用户管理简单应用
mysql视图——是一个虚拟的表,只包含使用时动态查询的数据 优点:重用sql语句,简化复杂的SQL操作,保护数据,可以给用户看到表的部分字段而不是全部,更改数据格式和表现形式 规则: 名称唯一,必须 ...
- MVVMLight 实现指定Frame控件的导航
原文:MVVMLight 实现指定Frame控件的导航 在UWP开发中,利用汉堡菜单实现导航是常见的方法.汉堡菜单导航一般都需要新建一个Frame控件,并对其进行导航,但是在MvvmLight框架默认 ...
- 客户端技术的一点思考(数据存储用SQLite, XMPP通讯用Gloox, Web交互用LibCurl, 数据打包用Protocol Buffer, socket通讯用boost asio)
今天看到CSDN上这么一篇< 彻底放弃没落的MFC,对新人的忠告!>, 作为一个一直在Windows上搞客户端开发的C++程序员,几年前也有过类似的隐忧(参见 落伍的感觉), 现在却有一些 ...