Java基础专题
Java后端知识点汇总——Java基础专题
全套Java知识点汇总目录,见https://www.cnblogs.com/autism-dong/p/11831922.html
1、解释下什么是面向对象?面向对象和面向过程的区别?
面向对象是一种基于面向过程的编程思想,是向现实世界模型的自然延伸,这是一种“万物皆对象”的编程思想。由执行者变为指挥者,在现实生活中的任何物体都可以归为一类事物,而每一个个体都是一类事物的实例。面向对象的编程是以对象为中心,以消息为驱动。
区别: (1)编程思路不同:面向过程以实现功能的函数开发为主,而面向对象要首先抽象出类、属性及其方法,然后通过实例化类、执行方法来完成功能。
(2)封装性:都具有封装性,但是面向过程是封装的是功能,而面向对象封装的是数据和功能。
(3)面向对象具有继承性和多态性,而面向过程没有继承性和多态性,所以面向对象优势很明显。
2、面向对象的三大特性?分别解释下?
(1)封装:通常认为封装是把数据和操作数据的方法封装起来,对数据的访问只能通过已定义的接口。
(2)继承:继承是从已有类得到继承信息创建新类的过程。提供继承信息的类被称为父类(超类/基类),得到继承信息的被称为子类(派生类)。
(3)多态:分为编译时多态(方法重载)和运行时多态(方法重写)。要实现多态需要做两件事:一是子类继承父类并重写父类中的方法,二是用父类型引用子类型对象,这样同样的引用调用同样的方法 就会根据子类对象的不同而表现出不同的行为。
关于继承的几点补充:
(1)子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。因为在一个子类被创建的时候,首先会在内存中创建一个父类对象,然后在父类对象外部放上子类独有的属性,两者合起来形成一个子类的对象;
(2)子类可以拥有自己属性和方法;
(3)子类可以用自己的方式实现父类的方法。(重写)
3、JDK、JRE、JVM 三者之间的关系?JDK(Java Development Kit):是 Java 开发工具包,是整个 Java 的核心,包括了 Java 运行环境 JRE、Java 工具和 Java 基础类库。JRE( Java Runtime Environment):是 Java 的运行环境,包含 JVM 标准实现及 Java 核心类库。JVM(Java Virtual Machine):是 Java 虚拟机,是整个 Java 实现跨平台的最核心的部分,能够运行以 Java 语言写作的软件程序。所有的 Java 程序会首先被编译为 .class 的类文件,这种类文件可以在虚拟机上执行。
4、重载和重写的区别?
(1)重载:编译时多态、同一个类中同名的方法具有不同的参数列表、不能根据返回类型进行区分【因为:函数调用时不能指定类型信息,编译器不知道你要调哪个函数】;
(2)重写(又名覆盖):运行时多态、子类与父类之间、子类重写父类的方法具有相同的返回类型、更好的访问权限。
5、Java 中是否可以重写一个 private 或者 static 方法?
Java 中 static 方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而 static 方法是编译时静态绑定的。static 方法跟类的任何实例都不相关,所以概念上不适用。 Java 中也不可以覆盖 private 的方法,因为 private 修饰的变量和方法只能在当前类中使用, 如果是其他的类继承当前类是不能访问到 private 变量或方法的,当然也不能覆盖。
静态方法的补充
静态的方法可以被继承,但是不能重写。如果父类和子类中存在同样名称和参数的静态方法,那么该子类的方法会把原来继承过来的父类的方法隐藏,而不是重写。通俗的讲就是父类的方法和子类的方法是两个没有关系的方法,具体调用哪一个方法是看是哪个对象的引用;这种父子类方法也不在存在多态的性质。
6、构造器是否可以被重写?
在讲继承的时候我们就知道父类的私有属性和构造方法并不能被继承,所以 Constructor 也就不能被 Override(重写),但是可以 Overload(重载),所以你可以看到一个类中有多个构造函数的情况。
7、构造方法有哪些特性?
(1)名字与类名相同;(2)没有返回值,但不能用 void 声明构造函数;
(3)成类的对象时自动执行,无需调用。
8、在 Java 中定义一个不做事且没有参数的构造方法有什么作用?
Java 程序在执行子类的构造方法之前,如果没有用 super() 来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用 super() 来调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类中找不到没有参数的构造方法可供执行。解决办法是:在父类里加上一个不做事且没有参数的构造方法。
9、Java 中创建对象的几种方式?1、使用 new 关键字;2、使用 Class 类的 newInstance 方法,该方法调用无参的构造器创建对象(反射):Class.forName.newInstance();3、使用 clone() 方法;4、反序列化,比如调用 ObjectInputStream 类的 readObject() 方法。
10、抽象类和接口有什么区别?
(1)抽象类中可以定义构造函数,接口不能定义构造函数;
(2)抽象类中可以有抽象方法和具体方法,而接口中只能有抽象方法(public abstract);
(3)抽象类中的成员权限可以是 public、默认、protected(抽象类中抽象方法就是为了重写,所以不能被 private 修饰),而接口中的成员只可以是 public(方法默认:public abstrat、成员变量默认:public static final);
(4)抽象类中可以包含静态方法,而接口中不可以包含静态方法;
JDK8中的改变:
1、在 JDK1.8中,允许在接口中包含带有具体实现的方法,使用 default 修饰,这类方法就是默认方法。
2、抽象类中可以包含静态方法,在 JDK1.8 之前接口中不能包含静态方法,JDK1.8 以后可以包含。之前不能包含是因为,接口不可以实现方法,只可以定义方法,所以不能使用静态方法(因为静态方法必须实现)。现在可以包含了,只能直接用接口调用静态方法。JDK1.8 仍然不可以包含静态代码块。
11、静态变量和实例变量的区别?
静态变量:是被 static 修饰的变量,也称为类变量,它属于类,因此不管创建多少个对象,静态变量在内存中有且仅有一个拷贝;静态变量可以实现让多个对象共享内存。
实例变量:属于某一实例,需要先创建对象,然后通过对象才能访问到它。
12、short s1 = 1;s1 = s1 + 1;有什么错?那么 short s1 = 1; s1 += 1;呢?有没有错误?
对于 short s1 = 1; s1 = s1 + 1; 来说,在 s1 + 1 运算时会自动提升表达式的类型为 int ,那么将 int 型值赋值给 short 型变量,s1 会出现类型转换错误。对于 short s1 = 1; s1 += 1; 来说,+= 是 Java 语言规定的运算符,Java 编译器会对它进行特殊处理,因此可以正确编译。
13、Integer 和 int 的区别?
(1)int 是 Java 的八种基本数据类型之一,而 Integer 是 Java 为 int 类型提供的封装类;
(2)int 型变量的默认值是 0,Integer 变量的默认值是 null,这一点说明 Integer 可以区分出未赋值和值为 0 的区分;
(3)Integer 变量必须实例化后才可以使用,而 int 不需要。
关于 Integer 和 int 的比较的延伸:
1、由于 Integer 变量实际上是对一个 Integer 对象的引用,所以两个通过 new 生成的 Integer 变量永远是不相等的,因为其内存地址是不同的;
2、Integer 变量和 int 变量比较时,只要两个变量的值是相等的,则结果为 true。因为包装类 Integer 和基本数据类型 int 类型进行比较时,Java 会自动拆包装类为 int,然后进行比较,实际上就是两个 int 型变量在进行比较;
3、非 new 生成的 Integer 变量和 new Integer() 生成的变量进行比较时,结果为 false。因为非 new 生成的 Integer 变量指向的是 Java 常量池中的对象,而 new Integer() 生成的变量指向堆中新建的对象,两者在内存中的地址不同;
4、对于两个非 new 生成的 Integer 对象进行比较时,如果两个变量的值在区间 [-128, 127] 之间,则比较结果为 true,否则为 false。Java 在编译 Integer i = 100 时,会编译成 Integer i = Integer.valueOf(100),而 Integer 类型的 valueOf 的源码如下所示:
public static Integer valueOf(int var0) { return var0 >= -128 && var0 <= Integer.IntegerCache.high ? Integer.IntegerCache.cache[var0 + 128] : new Integer(var0);}
从上面的代码中可以看出:Java 对于 [-128, 127] 之间的数会进行缓存,比如:Integer i = 127,会将 127 进行缓存,下次再写 Integer j = 127 的时候,就会直接从缓存中取出,而对于这个区间之外的数就需要 new 了。
- 包装类的缓存:
Boolean:全部缓存
Byte:全部缓存
Character:<= 127 缓存
Short:-128 — 127 缓存
Long:-128 — 127 缓存
Integer:-128 — 127 缓存
Float:没有缓存
Doulbe:没有缓存
14、装箱和拆箱
自动装箱是 Java 编译器在基本数据类型和对应得包装类之间做的一个转化。比如:把 int 转化成 Integer,double 转化成 Double 等等。反之就是自动拆箱。
原始类型:boolean、char、byte、short、int、long、float、double
封装类型:Boolean、Character、Byte、Short、Integer、Long、Float、Double
15、switch 语句能否作用在 byte 上,能否作用在 long 上,能否作用在 String 上?
在 switch(expr 1) 中,expr1 只能是一个整数表达式或者枚举常量。而整数表达式可以是 int 基本数据类型或者 Integer 包装类型。由于,byte、short、char 都可以隐式转换为 int,所以,这些类型以及这些类型的包装类型也都是可以的。而 long 和 String 类型都不符合 switch 的语法规定,并且不能被隐式的转换为 int 类型,所以,它们不能作用于 switch 语句中。不过,需要注意的是在 JDK1.7 版本之后 switch 就可以作用在 String 上了。
16、字节和字符的区别?
字节是存储容量的基本单位;字符是数字、字母、汉字以及其他语言的各种符号;1 字节 = 8 个二进制单位,一个字符由一个字节或多个字节的二进制单位组成。
17、String 为什么要设计为不可变类?
在 Java 中将 String 设计成不可变的是综合考虑到各种因素的结果。主要的原因主要有以下三点:
(1)字符串常量池的需要:字符串常量池是 Java 堆内存中一个特殊的存储区域, 当创建一个 String 对象时,假如此字符串值已经存在于常量池中,则不会创建一个新的对象,而是引用已经存在的对象;
(2)允许 String 对象缓存 HashCode:Java 中 String 对象的哈希码被频繁地使用, 比如在 HashMap 等容器中。字符串不变性保证了 hash 码的唯一性,因此可以放心地进行缓存。这也是一种性能优化手段,意味着不必每次都去计算新的哈希码;
(3)String 被许多的 Java 类(库)用来当做参数,例如:网络连接地址 URL、文件路径 path、还有反射机制所需要的 String 参数等, 假若 String 不是固定不变的,将会引起各种安全隐患。
18、String、StringBuilder、StringBuffer 的区别?
String:用于字符串操作,属于不可变类;【补充:String 不是基本数据类型,是引用类型,底层用 char 数组实现的】
StringBuilder:与 StringBuffer 类似,都是字符串缓冲区,但线程不安全;
StringBuffer:也用于字符串操作,不同之处是 StringBuffer 属于可变类,对方法加了同步锁,线程安全。
StringBuffer的补充:
说明:StringBuffer 中并不是所有方法都使用了 Synchronized 修饰来实现同步:
@Override
public StringBuffer insert(int dstOffset, CharSequence s) {
// Note, synchronization achieved via invocations of other StringBuffer methods
// after narrowing of s to specific type
// Ditto for toStringCache clearing
super.insert(dstOffset, s);
return this;
}
执行效率:StringBuilder > StringBuffer > String
19、String 字符串修改实现的原理?
当用 String 类型来对字符串进行修改时,其实现方法是首先创建一个 StringBuffer,其次调用 StringBuffer 的 append() 方法,
最后调用 StringBuffer 的 toString() 方法把结果返回。
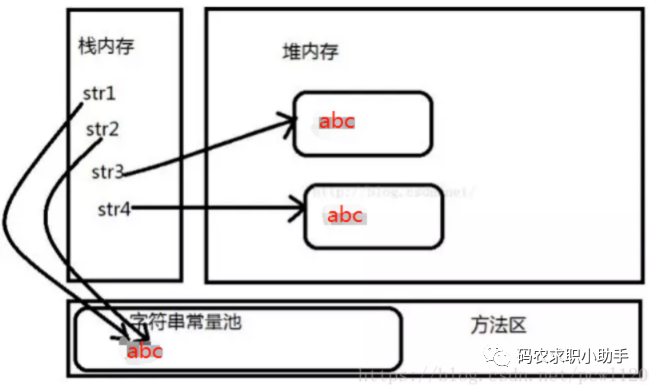
20、String str = "i" 与 String str = new String("i") 一样吗?
不一样,因为内存的分配方式不一样。String str = "i" 的方式,Java 虚拟机会将其分配到常量池中;而 String str = new String("i") 则会被分到堆内存中。
public class StringTest { public static void main(String[] args) {
String str1 = "abc";
String str2 = "abc";
String str3 = new String("abc");
String str4 = new String("abc");
System.out.println(str1 == str2); // true
System.out.println(str1 == str3); // false
System.out.println(str3 == str4); // false
System.out.println(str3.equals(str4)); // true
}
}
在执行 String str1 = "abc" 的时候,JVM 会首先检查字符串常量池中是否已经存在该字符串对象,如果已经存在,那么就不会再创建了,直接返回该字符串在字符串常量池中的内存地址;如果该字符串还不存在字符串常量池中,那么就会在字符串常量池中创建该字符串对象,然后再返回。所以在执行 String str2 = "abc" 的时候,因为字符串常量池中已经存在“abc”字符串对象了,就不会在字符串常量池中再次创建了,所以栈内存中 str1 和 str2 的内存地址都是指向 "abc" 在字符串常量池中的位置,所以 str1 = str2 的运行结果为 true。
而在执行 String str3 = new String("abc") 的时候,JVM 会首先检查字符串常量池中是否已经存在“abc”字符串,如果已经存在,则不会在字符串常量池中再创建了;如果不存在,则就会在字符串常量池中创建 "abc" 字符串对象,然后再到堆内存中再创建一份字符串对象,把字符串常量池中的 "abc" 字符串内容拷贝到内存中的字符串对象中,然后返回堆内存中该字符串的内存地址,即栈内存中存储的地址是堆内存中对象的内存地址。String str4 = new String("abc") 是在堆内存中又创建了一个对象,所以 str 3 == str4 运行的结果是 false。str1、str2、str3、str4 在内存中的存储状况如下图所示:
21、String 类的常用方法都有那些?
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母
toUpperCase():将字符串转成大写字符。
substring():截取字符串。equals():字符串比较。
22、final 修饰 StringBuffer 后还可以 append 吗?
可以。final 修饰的是一个引用变量,那么这个引用始终只能指向这个对象,但是这个对象内部的属性是可以变化的。
官方文档解释:
once a final variable has been assigned, it always contains the same value. If a final variable holds a reference to an object, then the state of the object may be changed by operations on the object, but the variable will always refer to the same object.
23、Object 的常用方法有哪些?
clone 方法:用于创建并返回当前对象的一份拷贝;
getClass 方法:用于返回当前运行时对象的 Class;
toString 方法:返回对象的字符串表示形式;
finalize 方法:实例被垃圾回收器回收时触发的方法;
equals 方法:用于比较两个对象的内存地址是否相等,一般需要重写;
hashCode 方法:用于返回对象的哈希值;
notify 方法:唤醒一个在此对象监视器上等待的线程。如果有多个线程在等待只会唤醒一个。
notifyAll 方法:作用跟 notify() 一样,只不过会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
wait 方法:让当前对象等待;
.......
24、为什么 wait/notify 方法放在 Object 类中而不是 Thread 类中?
一个很明显的原因是 Java 提供的锁是对象级的而不是线程级的,每个对象都有锁,通过线程获得。如果线程需要等待某些锁,那么调用对象中的 wait() 方法就有意义了。如果 wait() 方法定义在 Thread 类中,线程正在等待的是哪个锁就不明显了。简单的说,由于 wait,notify 和 notifyAll 都是锁级别的操作,所以把他们定义在 Object 类中因为锁属于对象。
25、final、finally、finalize 的区别?
final:用于声明属性、方法和类,分别表示属性不可变、方法不可覆盖、被其修饰的类不可继承;
finally:异常处理语句结构的一部分,表示总是执行;
finallize:Object类的一个方法,在垃圾回收时会调用被回收对象的finalize。
26、finally 块中的代码什么时候被执行?
在 Java 语言的异常处理中,finally 块的作用就是为了保证无论出现什么情况,finally 块里的代码一定会被执行。由于程序执行 return 就意味着结束对当前函数的调用并跳出这个函数体,因此任何语句要执行都只能在 return 前执行(除非碰到 exit 函数),因此 finally 块里的代码也是在 return 之前执行的。
此外,如果 try-finally 或者 catch-finally 中都有 return,那么 finally 块中的 return 将会覆盖别处的 return 语句,最终返回到调用者那里的是 finally 中 return 的值。
27、finally 是不是一定会被执行到?
不一定。下面列举两种执行不到的情况:
(1)当程序进入 try 块之前就出现异常时,会直接结束,不会执行 finally 块中的代码;
(2)当程序在 try 块中强制退出时也不会去执行 finally 块中的代码,比如在 try 块中执行 exit 方法。
28、try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
会。程序在执行到 return 时会首先将返回值存储在一个指定的位置,其次去执行 finally 块,最后再返回。因此,对基本数据类型,在 finally 块中改变 return 的值没有任何影响,直接覆盖掉;而对引用类型是有影响的,返回的是在 finally 对 前面 return 语句返回对象的修改值。
29、try-catch-finally 中那个部分可以省略?catch 可以省略。try 只适合处理运行时异常,try+catch 适合处理运行时异常+普通异常。也就是说,如果你只用 try 去处理普通异常却不加以 catch 处理,编译是通不过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用 catch 显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以 catch 可以省略,你加上 catch 编译器也觉得无可厚非。
30、static 关键字的作用?
(1)静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份;
(2)静态方法:静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字;
(3)静态语句块:静态语句块在类初始化时运行一次;
(4)静态内部类:非静态内部类依赖于外部类的实例,而静态内部类不需要。静态内部类不能访问外部类的非静态的变量和方法;
(5)初始化顺序:静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
public static String staticField = "静态变量";
static { System.out.println("静态语句块"); ---- 1 }
public String field = "实例变量"; ---- 2
{ System.out.println("普通语句块"); ----3 }
// 最后才是构造函数的初始化
public InitialOrderTest() {
System.out.println("构造函数"); ----4
}
初始化补充:
存在继承的情况下,初始化顺序为:
1. 父类(静态变量、静态语句块) 2. 子类(静态变量、静态语句块)3. 父类(实例变量、普通语句块)4. 父类(构造函数)5. 子类(实例变量、普通语句块)6. 子类(构造函数)
31、super 关键字的作用?
(1)访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。
(2)访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
(3)this 和 super 不能同时出现在一个构造函数里面,因为 this 必然会调用其它的构造函数,其它的构造函数必然也会有 super 语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。
32、transient 关键字的作用?
对于不想进行序列化的变量,使用 transient 关键字修饰。transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化。当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
33、== 和 equals 的区别?
==:如果比较的对象是基本数据类型,则比较的是数值是否相等;如果比较的是引用数据类型,则比较的是对象的地址值是否相等。
equals 方法:用来比较两个对象的内容是否相等。注意:equals 方法不能用于比较基本数据类型的变量。如果没有对 equals 方法进行重写,则比较的是引用类型的变量所指向的对象的地址(很多类重新了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下 equals 比较的是值是否相等)。
34、两个对象的 hashCode() 相同,则 equals() 也一定为 true 吗?
两个对象的 hashCode() 相同,equals() 不一定为 true。因为在散列表中,hashCode() 相等即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等【散列冲突】。
35、为什么重写 equals() 就一定要重写 hashCode() 方法?
这个问题应该是有个前提,就是你需要用到 HashMap、HashSet 等 Java 集合,用不到哈希表的话,其实仅仅重写 equals() 方法也可以。而工作中的场景是常常用到 Java 集合,所以 Java 官方建议重写 equals() 就一定要重写 hashCode() 方法。
对于对象集合的判重,如果一个集合含有 10000 个对象实例,仅仅使用 equals() 方法的话,那么对于一个对象判重就需要比较 10000 次,随着集合规模的增大,时间开销是很大的。但是同时使用哈希表的话,就能快速定位到对象的大概存储位置,并且在定位到大概存储位置后,后续比较过程中,如果两个对象的 hashCode 不相同,也不再需要调用 equals() 方法,从而大大减少了 equals() 比较次数。
所以从程序实现原理上来讲的话,既需要 equals() 方法,也需要 hashCode() 方法。那么既然重写了 equals(),那么也要重写 hashCode() 方法,以保证两者之间的配合关系。
hashCode()与equals()的相关规定:
1、如果两个对象相等,则 hashCode 一定也是相同的;2、两个对象相等,对两个对象分别调用 equals 方法都返回 true;3、两个对象有相同的 hashCode 值,它们也不一定是相等的;4、因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖;5、hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
36、& 和 && 的区别?
Java 中 && 和 & 都是表示与的逻辑运算符,都表示逻辑运输符 and,当两边的表达式都为 true 的时候,整个运算结果才为 true,否则为 false。
&&:有短路功能,当第一个表达式的值为 false 的时候,则不再计算第二个表达式;
&:不管第一个表达式结果是否为 true,第二个都会执行。除此之外,& 还可以用作位运算符:当 & 两边的表达式不是 Boolean 类型的时候,& 表示按位操作。
37、Java 中的参数传递时传值呢?还是传引用?
Java 的参数是以值传递的形式传入方法中,而不是引用传递。当传递方法参数类型为基本数据类型(数字以及布尔值)时,一个方法是不可能修改一个基本数据类型的参数。当传递方法参数类型为引用数据类型时,一个方法将修改一个引用数据类型的参数所指向对象的值。即使 Java 函数在传递引用数据类型时,也只是拷贝了引用的值罢了,之所以能修改引用数据是因为它们同时指向了一个对象,但这仍然是按值调用而不是引用调用。
38、Java 中的 Math.round(-1.5) 等于多少?
等于 -1,因为在数轴上取值时,中间值(0.5)向右取整,所以正 0.5 是往上取整,负 0.5 是直接舍弃。
39、两个二进制数的异或结果是什么?
两个二进制数异或结果是这两个二进制数差的绝对值。表达式如下:a^b = |a-b|。
两个二进制 a 与 b 异或,即 a 和 b 两个数按位进行运算。如果对应的位相同,则为 0(相当于对应的算术相减),如果不同即为 1(相当于对应的算术相加)。由于二进制每个位只有两种状态,要么是 0,要么是 1,则按位异或操作可表达为按位相减取值相对值,再按位累加。
40、Error 和 Exception 的区别?
Error 类和 Exception 类的父类都是 Throwable 类。主要区别如下:
Error 类: 一般是指与虚拟机相关的问题,如:系统崩溃、虚拟机错误、内存空间不足、方法调用栈溢出等。这类错误将会导致应用程序中断,仅靠程序本身无法恢复和预防;
Exception 类:分为运行时异常和受检查的异常。
41、运行时异常与受检异常有何异同?
运行时异常:如:空指针异常、指定的类找不到、数组越界、方法传递参数错误、数据类型转换错误。可以编译通过,但是一运行就停止了,程序不会自己处理;受检查异常:要么用 try … catch… 捕获,要么用 throws 声明抛出,交给父类处理。
42、throw 和 throws 的区别?(1)throw:在方法体内部,表示抛出异常,由方法体内部的语句处理;throw 是具体向外抛出异常的动作,所以它抛出的是一个异常实例;(2)throws:在方法声明后面,表示如果抛出异常,由该方法的调用者来进行异常的处理;表示出现异常的可能性,并不一定会发生这种异常。
43、常见的异常类有哪些?
NullPointerException:当应用程序试图访问空对象时,则抛出该异常。SQLException:提供关于数据库访问错误或其他错误信息的异常。
IndexOutOfBoundsException:指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出。
FileNotFoundException:当试图打开指定路径名表示的文件失败时,抛出此异常。
IOException:当发生某种 I/O 异常时,抛出此异常。此类是失败或中断的 I/O 操作生成的异常的通用类。
ClassCastException:当试图将对象强制转换为不是实例的子类时,抛出该异常。IllegalArgumentException:抛出的异常表明向方法传递了一个不合法或不正确的参数。
44、主线程可以捕获到子线程的异常吗?
线程设计的理念:“线程的问题应该线程自己本身来解决,而不要委托到外部”。
正常情况下,如果不做特殊的处理,在主线程中是不能够捕获到子线程中的异常的。如果想要在主线程中捕获子线程的异常,我们可以用如下的方式进行处理,使用 Thread 的静态方法。
Thread.setDefaultUncaughtExceptionHandler(new MyUncaughtExceptionHandle());45、Java 的泛型是如何工作的 ? 什么是类型擦除 ?
泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如:List<String> 在运行时仅用一个 List 来表示。这样做的目的,是确保能和 Java 5 之前的版本开发二进制类库进行兼容。
类型擦除:泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。在泛型类被类型擦除的时候,之前泛型类中的类型参数部分如果没有指定上限,如 <T> 则会被转译成普通的 Object 类型,如果指定了上限如 <T extends String> 则类型参数就被替换成类型上限。
补充:
List<String> list = new ArrayList<String>();1、两个 String 其实只有第一个起作用,后面一个没什么卵用,只不过 JDK7 才开始支持 List<String>list = new ArrayList<> 这种写法。
2、第一个 String 就是告诉编译器,List 中存储的是 String 对象,也就是起类型检查的作用,之后编译器会擦除泛型占位符,以保证兼容以前的代码。
46、什么是泛型中的限定通配符和非限定通配符 ?
限定通配符对类型进行了限制。有两种限定通配符,一种是<? extends T> 它通过确保类型必须是 T 的子类来设定类型的上界,另一种是<? super T>它通过确保类型必须是 T 的父类来设定类型的下界。泛型类型必须用限定内的类型来进行初始化,否则会导致编译错误。另一方面 <?> 表示了非限定通配符,因为 <?> 可以用任意类型来替代。
47、List<? extends T> 和 List <? super T> 之间有什么区别 ?
这两个 List 的声明都是限定通配符的例子,List<? extends T> 可以接受任何继承自 T 的类型的 List,而List <? super T> 可以接受任何 T 的父类构成的 List。例如 List<? extends Number> 可以接受 List<Integer> 或 List<Float>。
补充:
Array 不支持泛型,要用 List 代替 Array,因为 List 可以提供编译器的类型安全保证,而 Array却不能。
48、如何实现对象的克隆?
(1)实现 Cloneable 接口并重写 Object 类中的 clone() 方法;(2)实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深克隆。
49、深克隆和浅克隆的区别?
(1)浅克隆:拷贝对象和原始对象的引用类型引用同一个对象。浅克隆只是复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化,这就是浅克隆。(2)深克隆:拷贝对象和原始对象的引用类型引用不同对象。深拷贝是将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变,这就是深拷贝(例:JSON.parse() 和 JSON.stringify(),但是此方法无法复制函数类型)。
克隆的补充:
深克隆的实现就是在引用类型所在的类实现 Cloneable 接口,并使用 public 访问修饰符重写 clone 方法。Java 中定义的 clone 没有深浅之分,都是统一的调用 Object 的 clone 方法。为什么会有深克隆的概念?是由于我们在实现的过程中刻意的嵌套了 clone 方法的调用。也就是说深克隆就是在需要克隆的对象类型的类中重新实现克隆方法 clone()。
50、什么是 Java 的序列化,如何实现 Java 的序列化?
对象序列化是一个用于将对象状态转换为字节流的过程,可以将其保存到磁盘文件中或通过网络发送到任何其他程序。从字节流创建对象的相反的过程称为反序列化。而创建的字节流是与平台无关的,在一个平台上序列化的对象可以在不同的平台上反序列化。序列化是为了解决在对象流进行读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现 Serializable 接口,该接口没有需要实现的方法,只是用于标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个 ObjectOutputStream 对象,接着使用 ObjectOutputStream 对象的 writeObject(Object obj) 方法可以将参数为 obj 的对象写出,要恢复的话则使用输入流。
51、什么情况下需要序列化?
(1)当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
(2)当你想用套接字在网络上传送对象的时候;(3)当你想通过 RMI 传输对象的时候。
52、Java 中的反射是什么意思?有哪些应用场景?
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
(1)Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
(2)Method :可以使用 invoke() 方法调用与 Method 对象关联的方法;
(3)Constructor :可以用 Constructor 创建新的对象。
应用举例:工厂模式,使用反射机制,根据全限定类名获得某个类的 Class 实例。
53、反射的优缺点?
优点:
运行期类型的判断,class.forName() 动态加载类,提高代码的灵活度;
缺点:尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。(1)性能开销 :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
(2)安全限制 :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
(3)内部暴露:由于反射允许代码执行一些在正常情况下不被允许的操作(比如:访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
54、Java 中的动态代理是什么?有哪些应用?
动态代理:当想要给实现了某个接口的类中的方法,加一些额外的处理。比如说加日志,加事务等。可以给这个类创建一个代理,故名思议就是创建一个新的类,这个类不仅包含原来类方法的功能,而且还在原来的基础上添加了额外处理的新功能。这个代理类并不是定义好的,是动态生成的。具有解耦意义,灵活,扩展性强。动态代理的应用:Spring 的 AOP 、加事务、加权限、加日志。
55、怎么实现动态代理?
首先必须定义一个接口,还要有一个 InvocationHandler(将实现接口的类的对象传递给它)处理类。再有一个工具类 Proxy(习惯性将其称为代理类,因为调用它的 newInstance() 可以产生代理对象,其实它只是一个产生代理对象的工具类)。利用到 InvocationHandler,拼接代理类源码,将其编译生成代理类的二进制码,利用加载器加载,并将其实例化产生代理对象,最后返回。
每一个动态代理类都必须要实现 InvocationHandler 这个接口,并且每个代理类的实例都关联到了一个 handler,当我们通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由 InvocationHandler 这个接口的 invoke 方法来进行调用。我们来看看 InvocationHandler 这个接口的唯一一个方法 invoke 方法:
Object invoke(Object proxy, Method method, Object[] args) throws Throwableproxy: 指代我们所代理的那个真实对象method: 指代的是我们所要调用真实对象的某个方法的 Method 对象args: 指代的是调用真实对象某个方法时接受的参数Proxy 类的作用是动态创建一个代理对象的类。它提供了许多的方法,但是我们用的最多的就是 newProxyInstance 这个方法:
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler handler) throws IllegalArgumentExceptionloader:一个 ClassLoader 对象,定义了由哪个 ClassLoader 对象来对生成的代理对象进行加载;interfaces:一个 Interface 对象的数组,表示的是我将要给我需要代理的对象提供一组什么接口,如果我提供了一组接口给它,那么这个代理对象就宣称实现了该接口(多态),这样我就能调用这组接口中的方法了 handler:一个 InvocationHandler 对象,表示的是当我这个动态代理对象在调用方法的时候,会关联到哪一个 InvocationHandler 对象上。
通过 Proxy.newProxyInstance 创建的代理对象是在 Jvm 运行时动态生成的一个对象,它并不是我们的 InvocationHandler 类型,也不是我们定义的那组接口的类型,而是在运行是动态生成的一个对象。
56、Java 中的 IO 流的分类?说出几个你熟悉的实现类?
按功能来分:输入流(input)、输出流(output)。按类型来分:字节流 和 字符流。
字节流:InputStream/OutputStream 是字节流的抽象类,这两个抽象类又派生了若干子类,不同的子类分别处理不同的操作类型。具体子类如下所示:
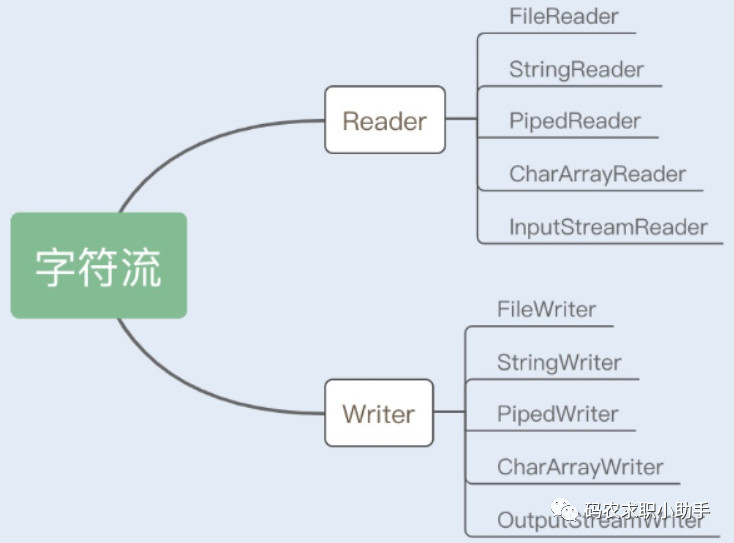
字符流:Reader/Writer 是字符的抽象类,这两个抽象类也派生了若干子类,不同的子类分别处理不同的操作类型。

57、字节流和字符流有什么区别?
字节流按 8 位传输,以字节为单位输入输出数据,字符流按 16 位传输,以字符为单位输入输出数据。
但是不管文件读写还是网络发送接收,信息的最小存储单元都是字节。
58、BIO、NIO、AIO 有什么区别?
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机 1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。NIO 是一种同步非阻塞的 I/O 模型,在 Java1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。NIO 提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步 IO 的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。
Java基础专题的更多相关文章
- 【Java基础专题】编码与乱码(05)---GBK与UTF-8之间的转换
原文出自:http://www.blogjava.net/pengpenglin/archive/2010/02/22/313669.html 在很多论坛.网上经常有网友问" 为什么我使用 ...
- Java多线程专题1: 并发与并行的基础概念
合集目录 Java多线程专题1: 并发与并行的基础概念 什么是多线程并发和并行? 并发: Concurrency 特指单核可以处理多任务, 这种机制主要实现于操作系统层面, 用于充分利用单CPU的性能 ...
- Java多线程专题4: 锁的实现基础 AQS
合集目录 Java多线程专题4: 锁的实现基础 AQS 对 AQS(AbstractQueuedSynchronizer)的理解 Provides a framework for implementi ...
- Java面试专题-基础篇(1)
- 微冷的雨Java基础学习手记(一)
使用Java理解程序逻辑 之凌波微步 船舶停靠在港湾是很安全的,但这不是造船的目的 北大青鸟五道口原玉明老师出品 1.学习方法: 01.找一本好书 初始阶段不适合,可以放到第二个阶段,看到知识点时,要 ...
- JAVA基础知识(转)
本文就java基础部分容易混淆的一些知识点进行了一下总结.因为Java本身知识点非常多,不可能在很短的篇幅就能叙述完,而且就某一个点来讲,如欲仔细去探究,也能阐述的非常多.这里不做全面仔细的论述,仅做 ...
- Java基础面试知识点总结
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Java基础知识点总结
前言 本文主要是我之前复习Java基础原理过程中写的Java基础知识点总结.Java的知识点其实非常多,并且有些知识点比较难以理解,有时候我们自以为理解了某些内容,其实可能只是停留在表面上,没有理解其 ...
- 阿里P7整理“硬核”面试文档:Java基础+数据库+算法+框架技术等
现在的程序员越来越多,大部分的程序员都想着自己能够进入大厂工作,但每个人的能力都是有差距的,所以并不是人人都能跨进BATJ.即使如此,但身在职场的我们一刻也不能懈怠,既然对BATJ好奇,那么就要朝这个 ...
随机推荐
- Provider模式应用demo
参考ObjectPool对象池设计原理还原一个简易的Provider模式. using System; using System.Dynamic; using System.Reflection.Me ...
- 如何在云服务器上自动运行.py文件
如果你在云服务器上运行的目的是保持一直运行,那就继续往下看吧. 有很多种方法,我这里说的是在linux上操作的一种. 利用screen会话分离. 因为在Screen环境下,所有的会话都独立的运行,并拥 ...
- Linux服务器部署.Net Core笔记:一、开启ssh服务
开启ssh服务需要root权限,先用root账户登陆系统 在安装ssh前我们先更新一下yum:yum update 先检查有没有安装ssh服务:rpm -qa | grep ssh 如果没有安装ssh ...
- WPF 3D足球导览
根据博文:https://www.cnblogs.com/duel/p/regular3dpoints.html获取足球的3D坐标后,在每一个坐标位置创建一个ModelVisual3D元素,既能实现炫 ...
- 用js写一个鼠标坐标实例
HTML代码 写一个div来作为鼠标区域 div中写一个span显示坐标信息 <body> <div id=""> <span></spa ...
- Android 数据库 SQLiteOpenHelper
public class DbOpenHelper extends SQLiteOpenHelper { private static String name = "test.db" ...
- mysql与python的交互
mysql是一种关系型数据库,是为了表示事物与事物之间的关系,本身存于数据库中的内容意义并不大,所以广泛应用于编程语言中,python中九含有与MySQL交互的模块 pymysql 编程对mysql的 ...
- latex 对中文字体设置的一些解决
latex 对中文字体设置的一些解决 直接使用Xelatex编译带中文的文件时,会出现无法识别的错误,这是因为latex默认的环境不支持中文,这时可以使用CTex 宏集.ctex 宏包或xeCJK 宏 ...
- 两种最常用的 HTTP 操作方法是:GET 和 POST。
什么是 HTTP? 超文本传输协议(HTTP)的设计目的是保证客户机与服务器之间的通信. HTTP 的工作方式是客户机与服务器之间的请求-应答协议. web 浏览器可能是客户端,而计算机上的网络应用程 ...
- 网络爬虫引发的问题及robots协议
一.网络爬虫的尺寸 1.以爬取网页,玩转网页为目的进行小规模,数据量小对爬取速度不敏感的可以使用request库实现功能(占90%) 2.以爬取网站或爬取系列网站为目的,比如说获取一个或多个旅游网站的 ...