Spring 2017 Assignments3
一.作业要求
原版:http://cs231n.github.io/assignments2017/assignment3/
翻译:http://www.mooc.ai/course/268/learn?lessonid=2254#lesson/2254
二.作业收获及代码
完整代码地址:
1 RNN Caption
(1)涉及到的numpy使用方法
np.repeat
np.argmax:argmax很有用,其会返回沿轴axis最大元素对应的索引。
(2)image caption 系统
需要注意:
a image caption系统应该由CNN+RNN组成,但这里由于硬件受限,我们直接使用在imageNet数据集上预训练后的CNN作用于Microsoft coco数据集,得到图片的特征向量传入RNN。
b 注意RNN训练时与测试时的差异。训练时每次梯度更新,需要对一个batch的数据做一次前向传播(T步时间),计算出损失,在做一次反向传播。计算损失时,我们是把输入的序列往后移一个T,作为groud truth,这与测试时不同。测试时我们下一个RNN单元的输入是上一个RNN单元输出的词分布采样得到的(作业里是选取得分值最大的词)。
c 在实现RNN层的前向传播和反向传播时,计算图为下图。可以看到参数W在每个时刻是共享的。并且W和h的梯度需要多条路径传来的梯度叠加。
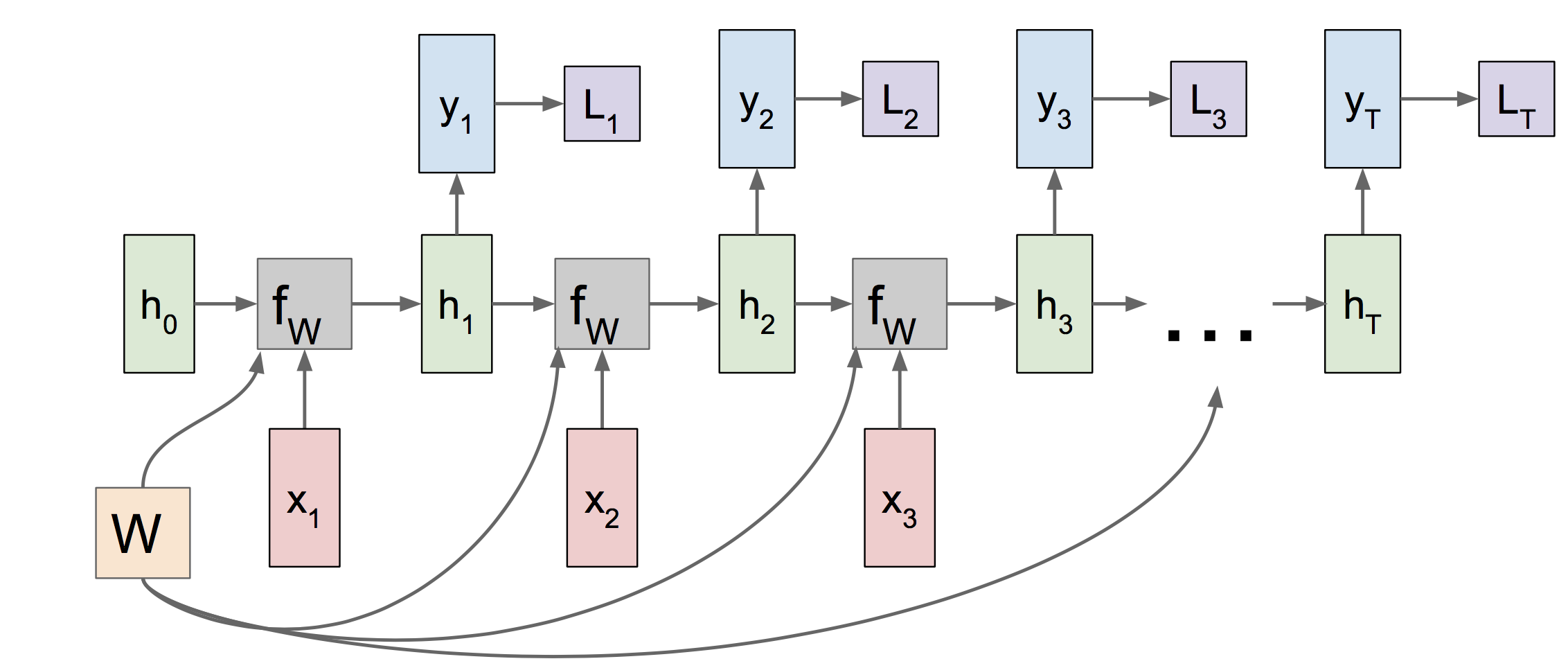
d 传入rnn的输入x为word embeding的结果,而每个词所对应的词向量与整个系统联合学习得出。因此我们还需要word embeding层的前向和反向传播。
(3)RNN单元的前向传播与反向传播
def rnn_step_forward(x, prev_h, Wx, Wh, b):
"""
Run the forward pass for a single timestep of a vanilla RNN that uses a tanh
activation function. The input data has dimension D, the hidden state has dimension H, and we use
a minibatch size of N. Inputs:
- x: Input data for this timestep, of shape (N, D).
- prev_h: Hidden state from previous timestep, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,) Returns a tuple of:
- next_h: Next hidden state, of shape (N, H)
- cache: Tuple of values needed for the backward pass.
"""
next_h, cache = None, None
##############################################################################
# TODO: Implement a single forward step for the vanilla RNN. Store the next #
# hidden state and any values you need for the backward pass in the next_h #
# and cache variables respectively. #
##############################################################################
next_h = np.tanh(prev_h.dot(Wh) + x.dot(Wx) + b)
cache = (x, prev_h, Wx, Wh, b, next_h)
##############################################################################
# END OF YOUR CODE #
##############################################################################
return next_h, cache def rnn_step_backward(dnext_h, cache):
"""
Backward pass for a single timestep of a vanilla RNN. Inputs:
- dnext_h: Gradient of loss with respect to next hidden state
- cache: Cache object from the forward pass Returns a tuple of:
- dx: Gradients of input data, of shape (N, D)
- dprev_h: Gradients of previous hidden state, of shape (N, H)
- dWx: Gradients of input-to-hidden weights, of shape (D, H)
- dWh: Gradients of hidden-to-hidden weights, of shape (H, H)
- db: Gradients of bias vector, of shape (H,)
"""
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
x, prev_h, Wx, Wh, b, next_h = cache
##############################################################################
# TODO: Implement the backward pass for a single step of a vanilla RNN. #
# #
# HINT: For the tanh function, you can compute the local derivative in terms #
# of the output value from tanh. #
##############################################################################
tmp = (1 - next_h ** 2) * dnext_h
dx = tmp.dot(Wx.T)
dprev_h = tmp.dot(Wh.T)
dWx = x.T.dot(tmp)
dWh = prev_h.T.dot(tmp)
db = np.sum(tmp, axis=0)
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dprev_h, dWx, dWh, db
(4)RNN层的前向传播及反向传播
def rnn_forward(x, h0, Wx, Wh, b):
"""
Run a vanilla RNN forward on an entire sequence of data. We assume an input
sequence composed of T vectors, each of dimension D. The RNN uses a hidden
size of H, and we work over a minibatch containing N sequences. After running
the RNN forward, we return the hidden states for all timesteps. Inputs:
- x: Input data for the entire timeseries, of shape (N, T, D).
- h0: Initial hidden state, of shape (N, H)
- Wx: Weight matrix for input-to-hidden connections, of shape (D, H)
- Wh: Weight matrix for hidden-to-hidden connections, of shape (H, H)
- b: Biases of shape (H,) Returns a tuple of:
- h: Hidden states for the entire timeseries, of shape (N, T, H).
- cache: Values needed in the backward pass
"""
h, cache = None, None
##############################################################################
# TODO: Implement forward pass for a vanilla RNN running on a sequence of #
# input data. You should use the rnn_step_forward function that you defined #
# above. You can use a for loop to help compute the forward pass. #
##############################################################################
N, T, D = x.shape
H = h0.shape[1]
prev_h = h0
cache = []
h = np.zeros((N, T, H))
for i in range(0, T):
(prev_h, cac) = rnn_step_forward(x[:, i, :], prev_h, Wx, Wh, b)
h[:, i, :] = prev_h
cache.append(cac)
##############################################################################
# END OF YOUR CODE #
##############################################################################
return h, cache def rnn_backward(dh, cache):
"""
Compute the backward pass for a vanilla RNN over an entire sequence of data. Inputs:
- dh: Upstream gradients of all hidden states, of shape (N, T, H) Returns a tuple of:
- dx: Gradient of inputs, of shape (N, T, D)
- dh0: Gradient of initial hidden state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, H)
- db: Gradient of biases, of shape (H,)
"""
dx, dh0, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a vanilla RNN running an entire #
# sequence of data. You should use the rnn_step_backward function that you #
# defined above. You can use a for loop to help compute the backward pass. #
##############################################################################
#dx, dprev_h, dWx, dWh, db = rnn_step_backward(dnext_h, cache):
if len(cache) == 0:
print('rnn length is 0, there is something wrong!')
return
T = len(cache)
N, D = cache[0][0].shape
dx = np.zeros((N, T, D))
dWx, dWh, db = 0, 0, 0
dprev_h = 0 for i in range(T, 0, -1):
dx[:, i - 1, :], dprev_h, dWxi, dWhi, dbi = rnn_step_backward(dh[:, i - 1, :] + dprev_h, cache[i - 1])
dWx += dWxi
dWh += dWhi
db += dbi
dh0 = dprev_h
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dh0, dWx, dWh, db
(5)word embedding层的前向和反向传播
word embedding 需要学习一个词向量矩阵,这个矩阵被随机初始化,然后与下游的RNN层联合学习。
def word_embedding_forward(x, W):
"""
Forward pass for word embeddings. We operate on minibatches of size N where
each sequence has length T. We assume a vocabulary of V words, assigning each
to a vector of dimension D. Inputs:
- x: Integer array of shape (N, T) giving indices of words. Each element idx
of x muxt be in the range 0 <= idx < V.
- W: Weight matrix of shape (V, D) giving word vectors for all words. Returns a tuple of:
- out: Array of shape (N, T, D) giving word vectors for all input words.
- cache: Values needed for the backward pass
"""
out, cache = None, None
##############################################################################
# TODO: Implement the forward pass for word embeddings. #
# #
# HINT: This can be done in one line using NumPy's array indexing. #
##############################################################################
N, T = x.shape
V, D = W.shape
out = np.zeros((N, T, D))
for n in range(0, N):
for t in range(0, T):
out[n, t, :] = W[x[n, t]] cache = (x, W) ##############################################################################
# END OF YOUR CODE #
##############################################################################
return out, cache def word_embedding_backward(dout, cache):
"""
Backward pass for word embeddings. We cannot back-propagate into the words
since they are integers, so we only return gradient for the word embedding
matrix. HINT: Look up the function np.add.at Inputs:
- dout: Upstream gradients of shape (N, T, D)
- cache: Values from the forward pass Returns:
- dW: Gradient of word embedding matrix, of shape (V, D).
"""
dW = None
x, W = cache
N, T, D = dout.shape
dW = np.zeros(W.shape)
##############################################################################
# TODO: Implement the backward pass for word embeddings. #
# #
# Note that Words can appear more than once in a sequence. #
# HINT: Look up the function np.add.at #
##############################################################################
#dW = np.add.at(dW, x.reshape(N * T), dout.reshape(N * T, D))
for i in range(0, N):
for j in range(0, T):
dW[x[i, j], :] += dout[i, j, :] ##############################################################################
# END OF YOUR CODE #
##############################################################################
return dW
(6)Temporal Affine layer 与 Temporal Softmax loss
Temporal Affine layer是一个简单的线性层,将每层的隐藏态h转化为各个词的分数值,Temporal Softmax loss根据分数值计算softmax损失值。
def temporal_affine_forward(x, w, b):
"""
Forward pass for a temporal affine layer. The input is a set of D-dimensional
vectors arranged into a minibatch of N timeseries, each of length T. We use
an affine function to transform each of those vectors into a new vector of
dimension M. Inputs:
- x: Input data of shape (N, T, D)
- w: Weights of shape (D, M)
- b: Biases of shape (M,) Returns a tuple of:
- out: Output data of shape (N, T, M)
- cache: Values needed for the backward pass
"""
N, T, D = x.shape
M = b.shape[0]
out = x.reshape(N * T, D).dot(w).reshape(N, T, M) + b
cache = x, w, b, out
return out, cache def temporal_affine_backward(dout, cache):
"""
Backward pass for temporal affine layer. Input:
- dout: Upstream gradients of shape (N, T, M)
- cache: Values from forward pass Returns a tuple of:
- dx: Gradient of input, of shape (N, T, D)
- dw: Gradient of weights, of shape (D, M)
- db: Gradient of biases, of shape (M,)
"""
x, w, b, out = cache
N, T, D = x.shape
M = b.shape[0] dx = dout.reshape(N * T, M).dot(w.T).reshape(N, T, D)
dw = dout.reshape(N * T, M).T.dot(x.reshape(N * T, D)).T
db = dout.sum(axis=(0, 1)) return dx, dw, db def temporal_softmax_loss(x, y, mask, verbose=False):
"""
A temporal version of softmax loss for use in RNNs. We assume that we are
making predictions over a vocabulary of size V for each timestep of a
timeseries of length T, over a minibatch of size N. The input x gives scores
for all vocabulary elements at all timesteps, and y gives the indices of the
ground-truth element at each timestep. We use a cross-entropy loss at each
timestep, summing the loss over all timesteps and averaging across the
minibatch. As an additional complication, we may want to ignore the model output at some
timesteps, since sequences of different length may have been combined into a
minibatch and padded with NULL tokens. The optional mask argument tells us
which elements should contribute to the loss. Inputs:
- x: Input scores, of shape (N, T, V)
- y: Ground-truth indices, of shape (N, T) where each element is in the range
0 <= y[i, t] < V
- mask: Boolean array of shape (N, T) where mask[i, t] tells whether or not
the scores at x[i, t] should contribute to the loss. Returns a tuple of:
- loss: Scalar giving loss
- dx: Gradient of loss with respect to scores x.
""" N, T, V = x.shape x_flat = x.reshape(N * T, V)
y_flat = y.reshape(N * T)
mask_flat = mask.reshape(N * T) probs = np.exp(x_flat - np.max(x_flat, axis=1, keepdims=True))
probs /= np.sum(probs, axis=1, keepdims=True)
loss = -np.sum(mask_flat * np.log(probs[np.arange(N * T), y_flat])) / N
dx_flat = probs.copy()
dx_flat[np.arange(N * T), y_flat] -= 1
dx_flat /= N
dx_flat *= mask_flat[:, None] if verbose: print('dx_flat: ', dx_flat.shape) dx = dx_flat.reshape(N, T, V) return loss, dx
(7)各个层之间的连接以及测试阶段的代码
类CaptioningRNN的代码将上述的各个层连接起来,传入图片特征向量作为h0,形成一个image caption系统。并且还包含了测试阶段sample的代码。
from builtins import range
from builtins import object
import numpy as np from cs231n.layers import *
from cs231n.rnn_layers import * class CaptioningRNN(object):
"""
A CaptioningRNN produces captions from image features using a recurrent
neural network. The RNN receives input vectors of size D, has a vocab size of V, works on
sequences of length T, has an RNN hidden dimension of H, uses word vectors
of dimension W, and operates on minibatches of size N. Note that we don't use any regularization for the CaptioningRNN.
""" def __init__(self, word_to_idx, input_dim=512, wordvec_dim=128,
hidden_dim=128, cell_type='rnn', dtype=np.float32):
"""
Construct a new CaptioningRNN instance. Inputs:
- word_to_idx: A dictionary giving the vocabulary. It contains V entries,
and maps each string to a unique integer in the range [0, V).
- input_dim: Dimension D of input image feature vectors.
- wordvec_dim: Dimension W of word vectors.
- hidden_dim: Dimension H for the hidden state of the RNN.
- cell_type: What type of RNN to use; either 'rnn' or 'lstm'.
- dtype: numpy datatype to use; use float32 for training and float64 for
numeric gradient checking.
"""
if cell_type not in {'rnn', 'lstm'}:
raise ValueError('Invalid cell_type "%s"' % cell_type) self.cell_type = cell_type
self.dtype = dtype
self.word_to_idx = word_to_idx
self.idx_to_word = {i: w for w, i in word_to_idx.items()}
self.params = {} vocab_size = len(word_to_idx) self._null = word_to_idx['<NULL>']
self._start = word_to_idx.get('<START>', None)
self._end = word_to_idx.get('<END>', None) # Initialize word vectors
self.params['W_embed'] = np.random.randn(vocab_size, wordvec_dim)
self.params['W_embed'] /= 100 # Initialize CNN -> hidden state projection parameters
self.params['W_proj'] = np.random.randn(input_dim, hidden_dim)
self.params['W_proj'] /= np.sqrt(input_dim)
self.params['b_proj'] = np.zeros(hidden_dim) # Initialize parameters for the RNN
dim_mul = {'lstm': 4, 'rnn': 1}[cell_type]
self.params['Wx'] = np.random.randn(wordvec_dim, dim_mul * hidden_dim)
self.params['Wx'] /= np.sqrt(wordvec_dim)
self.params['Wh'] = np.random.randn(hidden_dim, dim_mul * hidden_dim)
self.params['Wh'] /= np.sqrt(hidden_dim)
self.params['b'] = np.zeros(dim_mul * hidden_dim) # Initialize output to vocab weights
self.params['W_vocab'] = np.random.randn(hidden_dim, vocab_size)
self.params['W_vocab'] /= np.sqrt(hidden_dim)
self.params['b_vocab'] = np.zeros(vocab_size) # Cast parameters to correct dtype
for k, v in self.params.items():
self.params[k] = v.astype(self.dtype) def loss(self, features, captions):
"""
Compute training-time loss for the RNN. We input image features and
ground-truth captions for those images, and use an RNN (or LSTM) to compute
loss and gradients on all parameters. Inputs:
- features: Input image features, of shape (N, D)
- captions: Ground-truth captions; an integer array of shape (N, T) where
each element is in the range 0 <= y[i, t] < V Returns a tuple of:
- loss: Scalar loss
- grads: Dictionary of gradients parallel to self.params
"""
# Cut captions into two pieces: captions_in has everything but the last word
# and will be input to the RNN; captions_out has everything but the first
# word and this is what we will expect the RNN to generate. These are offset
# by one relative to each other because the RNN should produce word (t+1)
# after receiving word t. The first element of captions_in will be the START
# token, and the first element of captions_out will be the first word.
captions_in = captions[:, :-1]
captions_out = captions[:, 1:] # You'll need this
mask = (captions_out != self._null) # Weight and bias for the affine transform from image features to initial
# hidden state
W_proj, b_proj = self.params['W_proj'], self.params['b_proj'] # Word embedding matrix
W_embed = self.params['W_embed'] # Input-to-hidden, hidden-to-hidden, and biases for the RNN
Wx, Wh, b = self.params['Wx'], self.params['Wh'], self.params['b'] # Weight and bias for the hidden-to-vocab transformation.
W_vocab, b_vocab = self.params['W_vocab'], self.params['b_vocab'] loss, grads = 0.0, {}
############################################################################
# TODO: Implement the forward and backward passes for the CaptioningRNN. #
# In the forward pass you will need to do the following: #
# (1) Use an affine transformation to compute the initial hidden state #
# from the image features. This should produce an array of shape (N, H)#
# (2) Use a word embedding layer to transform the words in captions_in #
# from indices to vectors, giving an array of shape (N, T, W). #
# (3) Use either a vanilla RNN or LSTM (depending on self.cell_type) to #
# process the sequence of input word vectors and produce hidden state #
# vectors for all timesteps, producing an array of shape (N, T, H). #
# (4) Use a (temporal) affine transformation to compute scores over the #
# vocabulary at every timestep using the hidden states, giving an #
# array of shape (N, T, V). #
# (5) Use (temporal) softmax to compute loss using captions_out, ignoring #
# the points where the output word is <NULL> using the mask above. #
# #
# In the backward pass you will need to compute the gradient of the loss #
# with respect to all model parameters. Use the loss and grads variables #
# defined above to store loss and gradients; grads[k] should give the #
# gradients for self.params[k]. #
############################################################################ #forward pass
h0, cache_h0 = affine_forward(features, W_proj, b_proj)
x, cache_wordvec = word_embedding_forward(captions_in, W_embed)
h, cache = None, None
if self.cell_type == 'rnn':
h, cache = rnn_forward(x, h0, Wx, Wh, b)
elif self.cell_type == 'lstm':
h, cache = lstm_forward(x, h0, Wx, Wh, b)
else:
pass
scores, cache_score = temporal_affine_forward(h, W_vocab, b_vocab)
loss, dscores = temporal_softmax_loss(scores, captions_out, mask, verbose=False) #backward pass
dh, dW_vocab, db_vocab = temporal_affine_backward(dscores, cache_score)
if self.cell_type == 'rnn':
dx, dh0, dWx, dWh, db = rnn_backward(dh, cache)
elif self.cell_type == 'lstm':
dx, dh0, dWx, dWh, db = lstm_backward(dh, cache)
else:
pass
dW_embed = word_embedding_backward(dx, cache_wordvec)
dfeatures, dW_proj, db_proj = affine_backward(dh0, cache_h0) #
grads['W_proj'], grads['b_proj'] = dW_proj, db_proj
grads['W_embed'] = dW_embed
grads['Wx'], grads['Wh'], grads['b'] = dWx, dWh, db
grads['W_vocab'], grads['b_vocab'] = dW_vocab, db_vocab
############################################################################
# END OF YOUR CODE #
############################################################################ return loss, grads def sample(self, features, max_length=30):
"""
Run a test-time forward pass for the model, sampling captions for input
feature vectors. At each timestep, we embed the current word, pass it and the previous hidden
state to the RNN to get the next hidden state, use the hidden state to get
scores for all vocab words, and choose the word with the highest score as
the next word. The initial hidden state is computed by applying an affine
transform to the input image features, and the initial word is the <START>
token. For LSTMs you will also have to keep track of the cell state; in that case
the initial cell state should be zero. Inputs:
- features: Array of input image features of shape (N, D).
- max_length: Maximum length T of generated captions. Returns:
- captions: Array of shape (N, max_length) giving sampled captions,
where each element is an integer in the range [0, V). The first element
of captions should be the first sampled word, not the <START> token.
"""
N = features.shape[0]
captions = self._null * np.ones((N, max_length), dtype=np.int32) # Unpack parameters
W_proj, b_proj = self.params['W_proj'], self.params['b_proj']
W_embed = self.params['W_embed']
Wx, Wh, b = self.params['Wx'], self.params['Wh'], self.params['b']
W_vocab, b_vocab = self.params['W_vocab'], self.params['b_vocab'] ###########################################################################
# TODO: Implement test-time sampling for the model. You will need to #
# initialize the hidden state of the RNN by applying the learned affine #
# transform to the input image features. The first word that you feed to #
# the RNN should be the <START> token; its value is stored in the #
# variable self._start. At each timestep you will need to do to: #
# (1) Embed the previous word using the learned word embeddings #
# (2) Make an RNN step using the previous hidden state and the embedded #
# current word to get the next hidden state. #
# (3) Apply the learned affine transformation to the next hidden state to #
# get scores for all words in the vocabulary #
# (4) Select the word with the highest score as the next word, writing it #
# to the appropriate slot in the captions variable #
# #
# For simplicity, you do not need to stop generating after an <END> token #
# is sampled, but you can if you want to. #
# #
# HINT: You will not be able to use the rnn_forward or lstm_forward #
# functions; you'll need to call rnn_step_forward or lstm_step_forward in #
# a loop. #
###########################################################################
D = W_embed.shape[1]
h0 = features.dot(W_proj) + b_proj
prev_h = h0
prev_c = np.zeros(h0.shape)
x = W_embed[self._start, :].reshape(1, -1).repeat(N, axis=0)
for i in range(0, max_length):
if self.cell_type == 'rnn':
next_h, _ = rnn_step_forward(x, prev_h, Wx, Wh, b)
elif self.cell_type == 'lstm':
next_h, prev_c, _ = lstm_step_forward(x, prev_h, prev_c, Wx, Wh, b)
scores = next_h.dot(W_vocab) + b_vocab
next_word = np.argmax(scores, axis=1)
captions[:, i] = next_word
x = np.zeros((N, D))
for p in range(0, N):
x[p, :] = W_embed[next_word[p], :]
prev_h = next_h ############################################################################
# END OF YOUR CODE #
############################################################################
return captions
2 LSTM Caption
LSTM与普通RNN其实只是单元内部不同,输入输出多一个C。因此只要实现了单个LSTM单元的前向传播与反向传播,其他部分与RNN基本相同。
看完下面这段话以后应该会很清楚LSTM单元内部如何实现,:

(1)LSTM单元的前向和反向传播
def lstm_step_forward(x, prev_h, prev_c, Wx, Wh, b):
"""
Forward pass for a single timestep of an LSTM. The input data has dimension D, the hidden state has dimension H, and we use
a minibatch size of N. Inputs:
- x: Input data, of shape (N, D)
- prev_h: Previous hidden state, of shape (N, H)
- prev_c: previous cell state, of shape (N, H)
- Wx: Input-to-hidden weights, of shape (D, 4H)
- Wh: Hidden-to-hidden weights, of shape (H, 4H)
- b: Biases, of shape (4H,) Returns a tuple of:
- next_h: Next hidden state, of shape (N, H)
- next_c: Next cell state, of shape (N, H)
- cache: Tuple of values needed for backward pass.
"""
next_h, next_c, cache = None, None, None
#############################################################################
# TODO: Implement the forward pass for a single timestep of an LSTM. #
# You may want to use the numerically stable sigmoid implementation above. #
#############################################################################
H = prev_h.shape[1]
a = x.dot(Wx) + prev_h.dot(Wh) + b
ifo = 1.0 / (1 + np.exp(-a[:, 0:3*H]))
i = ifo[:, 0:H]
f = ifo[:, H:2*H]
o = ifo[:, 2*H:3*H]
g = np.tanh(a[:, 3*H:4*H])
next_c = prev_c * f + i * g
next_h = o * np.tanh(next_c)
cache = (x, Wx, Wh, i, f, o, g, ifo, next_c, next_h, prev_c, prev_h)
##############################################################################
# END OF YOUR CODE #
############################################################################## return next_h, next_c, cache def lstm_step_backward(dnext_h, dnext_c, cache):
"""
Backward pass for a single timestep of an LSTM. Inputs:
- dnext_h: Gradients of next hidden state, of shape (N, H)
- dnext_c: Gradients of next cell state, of shape (N, H)
- cache: Values from the forward pass Returns a tuple of:
- dx: Gradient of input data, of shape (N, D)
- dprev_h: Gradient of previous hidden state, of shape (N, H)
- dprev_c: Gradient of previous cell state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, 4H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, 4H)
- db: Gradient of biases, of shape (4H,)
"""
dx, dprev_h, dprev_c, dWx, dWh, db = None, None, None, None, None, None
H = dnext_h.shape[1]
#############################################################################
# TODO: Implement the backward pass for a single timestep of an LSTM. #
# #
# HINT: For sigmoid and tanh you can compute local derivatives in terms of #
# the output value from the nonlinearity. #
#############################################################################
x, Wx, Wh, i, f, o, g, ifo, next_c, next_h, prev_c, prev_h = cache
do = np.tanh(next_c) * dnext_h
dnext_c += dnext_h * o * (1 - np.tanh(next_c) ** 2)
df = prev_c * dnext_c
di = g * dnext_c
dg = i * dnext_c
dag = (1 - g ** 2) * dg
difo_daifo = ifo * (1 - ifo)
dai = difo_daifo[:, 0:H] * di
daf = difo_daifo[:, H:2*H] * df
dao = difo_daifo[:, 2*H:3*H] * do da = np.column_stack((dai, daf, dao, dag)) dx = da.dot(Wx.T)
dWx = x.T.dot(da)
dWh = prev_h.T.dot(da)
db = da.sum(axis=0)
dprev_h = da.dot(Wh.T)
dprev_c = f * dnext_c
##############################################################################
# END OF YOUR CODE #
############################################################################## return dx, dprev_h, dprev_c, dWx, dWh, db
(2)LSTM层的前向和反向传播
这个与普通RNN基本相同,代码不再贴出。
3 网络可视化
(本节和下一节风格迁移使用了预训练的模型SqueezeNet)
(1)Saliency Maps
Saliency Maps:查看改变图片中的哪些像素对于正确分类的score影响最大。计算正确分类的score关于输入图片的梯度并将这些梯度可视化出来即可。
tensorflow代码:
def compute_saliency_maps(X, y, model):
"""
Compute a class saliency map using the model for images X and labels y. Input:
- X: Input images, numpy array of shape (N, H, W, 3)
- y: Labels for X, numpy of shape (N,)
- model: A SqueezeNet model that will be used to compute the saliency map. Returns:
- saliency: A numpy array of shape (N, H, W) giving the saliency maps for the
input images.
"""
saliency = None
# Compute the score of the correct class for each example.
# This gives a Tensor with shape [N], the number of examples.
#
# Note: this is equivalent to scores[np.arange(N), y] we used in NumPy
# for computing vectorized losses.
correct_scores = tf.gather_nd(model.classifier,
tf.stack((tf.range(X.shape[0]), model.labels), axis=1))
###############################################################################
# TODO: Implement this function. You should use the correct_scores to compute #
# the loss, and tf.gradients to compute the gradient of the loss with respect #
# to the input image stored in model.image. #
# Use the global sess variable to finally run the computation. #
# Note: model.image and model.labels are placeholders and must be fed values #
# when you call sess.run(). #
###############################################################################
saliency_tensor = tf.gradients(correct_scores, model.image)
saliency = sess.run(saliency_tensor, feed_dict={model.image: X, model.labels: y})[0]
saliency = np.max(np.array(saliency), axis=3)
##############################################################################
# END OF YOUR CODE #
##############################################################################
return saliency
def show_saliency_maps(X, y, mask):
mask = np.asarray(mask)
Xm = X[mask]
ym = y[mask] saliency = compute_saliency_maps(Xm, ym, model)
#print(saliency.shape) for i in range(mask.size):
plt.subplot(2, mask.size, i + 1)
plt.imshow(deprocess_image(Xm[i]))
plt.axis('off')
plt.title(class_names[ym[i]])
plt.subplot(2, mask.size, mask.size + i + 1)
plt.title(mask[i])
plt.imshow(saliency[i], cmap=plt.cm.hot)
plt.axis('off')
plt.gcf().set_size_inches(10, 4)
plt.show() mask = np.arange(5)
show_saliency_maps(X, y, mask)

(2)Fooling Images
通过在原始图片上使用梯度上升,最大化某一错误类别的得分,当模型刚好能把图片误分类时停止。可以得到肉眼看上去无差别,但能够欺骗模型的Fooling Images。
def make_fooling_image(X, target_y, model):
"""
Generate a fooling image that is close to X, but that the model classifies
as target_y. Inputs:
- X: Input image, of shape (1, 224, 224, 3)
- target_y: An integer in the range [0, 1000)
- model: Pretrained SqueezeNet model Returns:
- X_fooling: An image that is close to X, but that is classifed as target_y
by the model.
"""
X_fooling = X.copy()
learning_rate = 1
##############################################################################
# TODO: Generate a fooling image X_fooling that the model will classify as #
# the class target_y. Use gradient ascent on the target class score, using #
# the model.classifier Tensor to get the class scores for the model.image. #
# When computing an update step, first normalize the gradient: #
# dX = learning_rate * g / ||g||_2 #
# #
# You should write a training loop #
# #
# HINT: For most examples, you should be able to generate a fooling image #
# in fewer than 100 iterations of gradient ascent. #
# You can print your progress over iterations to check your algorithm. #
############################################################################## grad_tensor = tf.gradients(model.classifier[:, target_y], model.image)
for i in range(0, 100):
print("iter %d"%i)
g, scores = sess.run([grad_tensor, model.classifier], feed_dict={model.image : X, model.labels : [1]})
g = g[0]
if np.argmax(scores) == target_y:
print('end')
break
X += 0.5 * g / np.sum(g ** 2) ##############################################################################
# END OF YOUR CODE #
##############################################################################
return X_fooling

(3)Class visualization
在一个随机噪声初始化的图片上使用梯度上升最大化目标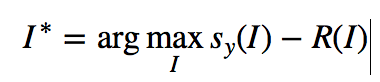 ,可以可视化出卷积网络学到的一些东西。其中S是某一类别的得分,R是正则化项,并且在生成的图片上进行周期性的blurring,使得生成的图片更好看。
,可以可视化出卷积网络学到的一些东西。其中S是某一类别的得分,R是正则化项,并且在生成的图片上进行周期性的blurring,使得生成的图片更好看。
from scipy.ndimage.filters import gaussian_filter1d
def blur_image(X, sigma=1):
X = gaussian_filter1d(X, sigma, axis=1)
X = gaussian_filter1d(X, sigma, axis=2)
return X def create_class_visualization(target_y, model, **kwargs):
"""
Generate an image to maximize the score of target_y under a pretrained model. Inputs:
- target_y: Integer in the range [0, 1000) giving the index of the class
- model: A pretrained CNN that will be used to generate the image Keyword arguments:
- l2_reg: Strength of L2 regularization on the image
- learning_rate: How big of a step to take
- num_iterations: How many iterations to use
- blur_every: How often to blur the image as an implicit regularizer
- max_jitter: How much to gjitter the image as an implicit regularizer
- show_every: How often to show the intermediate result
"""
l2_reg = kwargs.pop('l2_reg', 1e-3)
learning_rate = kwargs.pop('learning_rate', 40)
num_iterations = kwargs.pop('num_iterations', 100)
blur_every = kwargs.pop('blur_every', 10)
max_jitter = kwargs.pop('max_jitter', 16)
show_every = kwargs.pop('show_every', 25) X = 255 * np.random.rand(224, 224, 3)
X = preprocess_image(X)[None] ########################################################################
# TODO: Compute the loss and the gradient of the loss with respect to #
# the input image, model.image. We compute these outside the loop so #
# that we don't have to recompute the gradient graph at each iteration #
# #
# Note: loss and grad should be TensorFlow Tensors, not numpy arrays! #
# #
# The loss is the score for the target label, target_y. You should #
# use model.classifier to get the scores, and tf.gradients to compute #
# gradients. Don't forget the (subtracted) L2 regularization term! #
########################################################################
loss = None # scalar loss
grad = None # gradient of loss with respect to model.image, same size as model.image
loss = model.classifier[:, target_y] - l2_reg * tf.reduce_sum(model.image ** 2)
grad = tf.gradients(loss, model.image)[0] ############################################################################
# END OF YOUR CODE #
############################################################################ for t in range(num_iterations):
# Randomly jitter the image a bit; this gives slightly nicer results
ox, oy = np.random.randint(-max_jitter, max_jitter+1, 2)
Xi = X.copy()
X = np.roll(np.roll(X, ox, 1), oy, 2) ########################################################################
# TODO: Use sess to compute the value of the gradient of the score for #
# class target_y with respect to the pixels of the image, and make a #
# gradient step on the image using the learning rate. You should use #
# the grad variable you defined above. #
# #
# Be very careful about the signs of elements in your code. #
########################################################################
g = sess.run(grad, feed_dict={model.image : X.reshape((1, 224, 224, 3)), model.labels : [1]})
X += learning_rate * g
############################################################################
# END OF YOUR CODE #
############################################################################ # Undo the jitter
X = np.roll(np.roll(X, -ox, 1), -oy, 2) # As a regularizer, clip and periodically blur
X = np.clip(X, -SQUEEZENET_MEAN/SQUEEZENET_STD, (1.0 - SQUEEZENET_MEAN)/SQUEEZENET_STD)
if t % blur_every == 0:
X = blur_image(X, sigma=0.5) # Periodically show the image
if t == 0 or (t + 1) % show_every == 0 or t == num_iterations - 1:
plt.imshow(deprocess_image(X[0]))
class_name = class_names[target_y]
plt.title('%s\nIteration %d / %d' % (class_name, t + 1, num_iterations))
plt.gcf().set_size_inches(4, 4)
plt.axis('off')
plt.show()
return X

4 风格迁移
具体原理见http://www.cnblogs.com/coldyan/p/8403506.html
(1)用到的tf API:
tf.reduce_sum
tf.reshape:用的时候要想想reshape后元素是怎么排列的。
tf.concat:用于张量拼接。
(2)content loss
def content_loss(content_weight, content_current, content_original):
"""
Compute the content loss for style transfer. Inputs:
- content_weight: scalar constant we multiply the content_loss by.
- content_current: features of the current image, Tensor with shape [1, height, width, channels]
- content_target: features of the content image, Tensor with shape [1, height, width, channels] Returns:
- scalar content loss
"""
return content_weight * tf.reduce_sum((content_current - content_original) ** 2)
(3)style loss
gram matrix:
def gram_matrix(features, normalize=True):
"""
Compute the Gram matrix from features. Inputs:
- features: Tensor of shape (1, H, W, C) giving features for
a single image.
- normalize: optional, whether to normalize the Gram matrix
If True, divide the Gram matrix by the number of neurons (H * W * C) Returns:
- gram: Tensor of shape (C, C) giving the (optionally normalized)
Gram matrices for the input image.
"""
shape = tf.shape(features)
H, W, C = shape[1], shape[2], shape[3]
features = tf.reshape(features, [-1, C])
gram_matrix = tf.matmul(features, features, transpose_a=True)
if normalize:
gram_matrix /= tf.cast(H * W * C, dtype=tf.float32)
return gram_matrix
style loss:
def style_loss(feats, style_layers, style_targets, style_weights):
"""
Computes the style loss at a set of layers. Inputs:
- feats: list of the features at every layer of the current image, as produced by
the extract_features function.
- style_layers: List of layer indices into feats giving the layers to include in the
style loss.
- style_targets: List of the same length as style_layers, where style_targets[i] is
a Tensor giving the Gram matrix the source style image computed at
layer style_layers[i].
- style_weights: List of the same length as style_layers, where style_weights[i]
is a scalar giving the weight for the style loss at layer style_layers[i]. Returns:
- style_loss: A Tensor contataining the scalar style loss.
"""
# Hint: you can do this with one for loop over the style layers, and should
# not be very much code (~5 lines). You will need to use your gram_matrix function.
style_loss = 0
for i, indice in enumerate(style_layers):
cur_gram = gram_matrix(feats[indice])
target_gram = style_targets[i]
style_loss += style_weights[i] * tf.reduce_sum((cur_gram - target_gram) ** 2)
return style_loss
(4)Total-variation regularization
tv_loss定义为图像中所有相邻像素对的差值的平方和:

我们计算tv_loss的方法是,将图像向上下左右四个方向平移一个像素,分别与原图像作差求平方,再除以2,就是要求的tv_loss。
def tv_loss(img, tv_weight):
"""
Compute total variation loss. Inputs:
- img: Tensor of shape (1, H, W, 3) holding an input image.
- tv_weight: Scalar giving the weight w_t to use for the TV loss. Returns:
- loss: Tensor holding a scalar giving the total variation loss
for img weighted by tv_weight.
"""
# Your implementation should be vectorized and not require any loops!
img_left_move = tf.concat([img[:, :, 1:, :], img[:, :, -1:, :]], 2)
img_right_move = tf.concat([img[:, :, 0:1, :], img[:, :, 0:-1, :]], 2)
img_up_move = tf.concat([img[:, 1:, :, :], img[:, -1:, :, :]], 1)
img_down_move = tf.concat([img[:, 0:1, :, :], img[:, 0:-1, :, :]], 1)
tv_loss = 0
tv_loss += tf.reduce_sum((img - img_left_move) ** 2)
tv_loss += tf.reduce_sum((img - img_right_move) ** 2)
tv_loss += tf.reduce_sum((img - img_up_move) ** 2)
tv_loss += tf.reduce_sum((img - img_down_move) ** 2)
tv_loss *= tv_weight
return tv_loss / 2
(5)主程序
def style_transfer(content_image, style_image, image_size, style_size, content_layer, content_weight,
style_layers, style_weights, tv_weight, init_random = False):
"""Run style transfer! Inputs:
- content_image: filename of content image
- style_image: filename of style image
- image_size: size of smallest image dimension (used for content loss and generated image)
- style_size: size of smallest style image dimension
- content_layer: layer to use for content loss
- content_weight: weighting on content loss
- style_layers: list of layers to use for style loss
- style_weights: list of weights to use for each layer in style_layers
- tv_weight: weight of total variation regularization term
- init_random: initialize the starting image to uniform random noise
"""
# Extract features from the content image
content_img = preprocess_image(load_image(content_image, size=image_size))
feats = model.extract_features(model.image)
content_target = sess.run(feats[content_layer],
{model.image: content_img[None]}) # Extract features from the style image
style_img = preprocess_image(load_image(style_image, size=style_size))
style_feat_vars = [feats[idx] for idx in style_layers]
style_target_vars = []
# Compute list of TensorFlow Gram matrices
for style_feat_var in style_feat_vars:
style_target_vars.append(gram_matrix(style_feat_var))
# Compute list of NumPy Gram matrices by evaluating the TensorFlow graph on the style image
style_targets = sess.run(style_target_vars, {model.image: style_img[None]}) # Initialize generated image to content image if init_random:
img_var = tf.Variable(tf.random_uniform(content_img[None].shape, 0, 1), name="image")
else:
img_var = tf.Variable(content_img[None], name="image") # Extract features on generated image
feats = model.extract_features(img_var)
# Compute loss
c_loss = content_loss(content_weight, feats[content_layer], content_target)
s_loss = style_loss(feats, style_layers, style_targets, style_weights)
t_loss = tv_loss(img_var, tv_weight)
loss = c_loss + s_loss + t_loss # Set up optimization hyperparameters
initial_lr = 3.0
decayed_lr = 0.1
decay_lr_at = 180
max_iter = 200 # Create and initialize the Adam optimizer
lr_var = tf.Variable(initial_lr, name="lr")
# Create train_op that updates the generated image when run
with tf.variable_scope("optimizer") as opt_scope:
train_op = tf.train.AdamOptimizer(lr_var).minimize(loss, var_list=[img_var])
# Initialize the generated image and optimization variables
opt_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=opt_scope.name)
sess.run(tf.variables_initializer([lr_var, img_var] + opt_vars))
# Create an op that will clamp the image values when run
clamp_image_op = tf.assign(img_var, tf.clip_by_value(img_var, -1.5, 1.5)) f, axarr = plt.subplots(1,2)
axarr[0].axis('off')
axarr[1].axis('off')
axarr[0].set_title('Content Source Img.')
axarr[1].set_title('Style Source Img.')
axarr[0].imshow(deprocess_image(content_img))
axarr[1].imshow(deprocess_image(style_img))
plt.show()
plt.figure() # Hardcoded handcrafted
for t in range(max_iter):
# Take an optimization step to update img_var
sess.run(train_op)
if t < decay_lr_at:
sess.run(clamp_image_op)
if t == decay_lr_at:
sess.run(tf.assign(lr_var, decayed_lr))
if t % 100 == 0:
print('Iteration {}'.format(t))
img = sess.run(img_var)
plt.imshow(deprocess_image(img[0], rescale=True))
plt.axis('off')
plt.show()
print('Iteration {}'.format(t))
img = sess.run(img_var)
plt.imshow(deprocess_image(img[0], rescale=True))
plt.axis('off')
plt.show()
运行效果:


(6)特征反演和纹理生成
将参数中content loss的权值设为0,就等于做纹理生成。同理,将参数中styleloss的权值设为0,等于做特征反演。
纹理生成效果:


5 对抗生成网络
(1) 用到的tf API
tf.maximum
tf.random_uniform
tf.layers.dense
tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, 'discriminator'):获取“判别器”域的变量
(2) LeakyReLU
LeakyReLUy能防止Relu挂掉,因此经常被用于GAN。
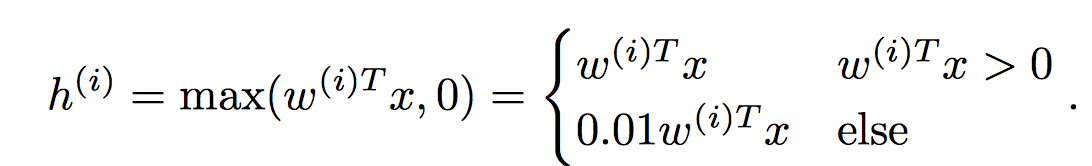
def leaky_relu(x, alpha=0.01):
"""Compute the leaky ReLU activation function. Inputs:
- x: TensorFlow Tensor with arbitrary shape
- alpha: leak parameter for leaky ReLU Returns:
TensorFlow Tensor with the same shape as x
"""
# TODO: implement leaky ReLU
return tf.maximum(x, x * alpha)
(3)判别器
判别器是一个结构如下的全连接网络
Architecture:
- Fully connected layer from size 784 to 256
- LeakyReLU with alpha 0.01
- Fully connected layer from 256 to 256
- LeakyReLU with alpha 0.01
- Fully connected layer from 256 to 1
def discriminator(x):
"""Compute discriminator score for a batch of input images. Inputs:
- x: TensorFlow Tensor of flattened input images, shape [batch_size, 784] Returns:
TensorFlow Tensor with shape [batch_size, 1], containing the score
for an image being real for each input image.
"""
with tf.variable_scope("discriminator"):
# TODO: implement architecture
x = tf.layers.dense(x, 256)
x = leaky_relu(x, alpha=0.01)
x = tf.layers.dense(x, 256)
x = leaky_relu(x, alpha=0.01)
logits = tf.layers.dense(x, 1)
return logits
(4)生成器
生成器结构如下:
Architecture:
- Fully connected layer from tf.shape(z)[1] (the number of noise dimensions) to 1024
- ReLU
- Fully connected layer from 1024 to 1024
- ReLU
- Fully connected layer from 1024 to 784
- TanH (To restrict the output to be [-1,1])
def generator(z):
"""Generate images from a random noise vector. Inputs:
- z: TensorFlow Tensor of random noise with shape [batch_size, noise_dim] Returns:
TensorFlow Tensor of generated images, with shape [batch_size, 784].
"""
with tf.variable_scope("generator"):
# TODO: implement architecture
f1 = tf.layers.dense(z, 1024, activation=tf.nn.relu)
f2 = tf.layers.dense(f1, 1024, activation=tf.nn.relu)
img = tf.layers.dense(f2, 784, activation=tf.nn.tanh)
return img
(5) GAN Loss

def gan_loss(logits_real, logits_fake):
"""Compute the GAN loss. Inputs:
- logits_real: Tensor, shape [batch_size, 1], output of discriminator
Log probability that the image is real for each real image
- logits_fake: Tensor, shape[batch_size, 1], output of discriminator
Log probability that the image is real for each fake image Returns:
- D_loss: discriminator loss scalar
- G_loss: generator loss scalar
"""
# TODO: compute D_loss and G_loss
normal_real_pro = tf.sigmoid(logits_real)
normal_fake_pro = tf.sigmoid(logits_fake)
D_loss = -tf.reduce_mean(tf.log(normal_real_pro)) - tf.reduce_mean(tf.log(1 - normal_fake_pro))
G_loss = -tf.reduce_mean(tf.log(normal_fake_pro)) return D_loss, G_loss
(6) train a GAN
tf.reset_default_graph() # number of images for each batch
batch_size = 128
# our noise dimension
noise_dim = 96 # placeholder for images from the training dataset
x = tf.placeholder(tf.float32, [None, 784])
# random noise fed into our generator
z = sample_noise(batch_size, noise_dim)
# generated images
G_sample = generator(z) with tf.variable_scope("") as scope:
#scale images to be -1 to 1
logits_real = discriminator(preprocess_img(x))
# Re-use discriminator weights on new inputs
scope.reuse_variables()
logits_fake = discriminator(G_sample) # Get the list of variables for the discriminator and generator
D_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, 'discriminator')
G_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, 'generator') # get our solver
D_solver, G_solver = get_solvers() # get our loss
D_loss, G_loss = gan_loss(logits_real, logits_fake) # setup training steps
D_train_step = D_solver.minimize(D_loss, var_list=D_vars)
G_train_step = G_solver.minimize(G_loss, var_list=G_vars)
D_extra_step = tf.get_collection(tf.GraphKeys.UPDATE_OPS, 'discriminator')
G_extra_step = tf.get_collection(tf.GraphKeys.UPDATE_OPS, 'generator')
# a giant helper function
def run_a_gan(sess, G_train_step, G_loss, D_train_step, D_loss, G_extra_step, D_extra_step,\
show_every=250, print_every=50, batch_size=128, num_epoch=10):
"""Train a GAN for a certain number of epochs. Inputs:
- sess: A tf.Session that we want to use to run our data
- G_train_step: A training step for the Generator
- G_loss: Generator loss
- D_train_step: A training step for the Generator
- D_loss: Discriminator loss
- G_extra_step: A collection of tf.GraphKeys.UPDATE_OPS for generator
- D_extra_step: A collection of tf.GraphKeys.UPDATE_OPS for discriminator
Returns:
Nothing
"""
# compute the number of iterations we need
max_iter = int(mnist.train.num_examples*num_epoch/batch_size)
for it in range(max_iter):
# every show often, show a sample result
if it % show_every == 0:
samples = sess.run(G_sample)
fig = show_images(samples[:16])
plt.show()
print()
# run a batch of data through the network
minibatch,minbatch_y = mnist.train.next_batch(batch_size)
_, D_loss_curr = sess.run([D_train_step, D_loss], feed_dict={x: minibatch})
_, G_loss_curr = sess.run([G_train_step, G_loss]) # print loss every so often.
# We want to make sure D_loss doesn't go to 0
if it % print_every == 0:
print('Iter: {}, D: {:.4}, G:{:.4}'.format(it,D_loss_curr,G_loss_curr))
print('Final images')
samples = sess.run(G_sample) fig = show_images(samples[:16])
plt.show()
with get_session() as sess:
sess.run(tf.global_variables_initializer())
run_a_gan(sess,G_train_step,G_loss,D_train_step,D_loss,G_extra_step,D_extra_step)
迭代4250次后,最终生成的图像:

(7)Least Squares GAN
Least Squares GAN 修改原始GAN的损失函数,具有训练更稳定的优点:
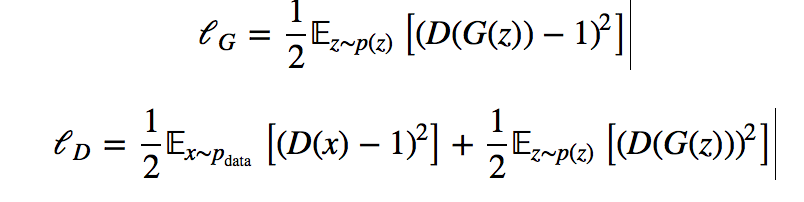
def lsgan_loss(score_real, score_fake):
"""Compute the Least Squares GAN loss. Inputs:
- score_real: Tensor, shape [batch_size, 1], output of discriminator
score for each real image
- score_fake: Tensor, shape[batch_size, 1], output of discriminator
score for each fake image Returns:
- D_loss: discriminator loss scalar
- G_loss: generator loss scalar
"""
# TODO: compute D_loss and G_loss D_loss = tf.reduce_mean((score_real - 1) ** 2) / 2 + tf.reduce_mean(score_fake ** 2) / 2
G_loss = tf.reduce_mean((score_fake - 1) ** 2) / 2
return D_loss, G_loss
(8)Deep Convolutional GANs
a 判别器
def discriminator(x):
"""Compute discriminator score for a batch of input images. Inputs:
- x: TensorFlow Tensor of flattened input images, shape [batch_size, 784] Returns:
TensorFlow Tensor with shape [batch_size, 1], containing the score
for an image being real for each input image.
"""
with tf.variable_scope("discriminator"):
# TODO: implement architecture x = tf.reshape(x, [-1, 28, 28, 1])
x = tf.layers.conv2d(inputs=x, filters=32, kernel_size=[5, 5], padding="valid")
x = leaky_relu(x, alpha=0.01)
x = tf.layers.max_pooling2d(inputs=x, pool_size=[2, 2], strides=2)
x = tf.layers.conv2d(inputs=x, filters=64, kernel_size=[5, 5], padding="valid")
x = leaky_relu(x, alpha=0.01)
x = tf.layers.max_pooling2d(inputs=x, pool_size=[2, 2], strides=2)
x = tf.reshape(x, [x.shape[0], -1])
x = tf.layers.dense(x, 1024)
x = leaky_relu(x, alpha=0.01)
logits = tf.layers.dense(x, 1)
return logits
b 生成器
def generator(z):
"""Generate images from a random noise vector. Inputs:
- z: TensorFlow Tensor of random noise with shape [batch_size, noise_dim] Returns:
TensorFlow Tensor of generated images, with shape [batch_size, 784].
"""
with tf.variable_scope("generator"):
# TODO: implement architecture
f1 = tf.layers.dense(z, 1024, activation=tf.nn.relu)
b1 = tf.layers.batch_normalization(f1)
f2 = tf.layers.dense(b1, 7 * 7 * 128, activation=tf.nn.relu)
b2 = tf.layers.batch_normalization(f2)
b2 = tf.reshape(b2, [-1, 28, 28, 8])
c1 = tf.layers.conv2d_transpose(b2, 64, [4, 4], strides=(2, 2), padding='same', activation=tf.nn.relu)
b3 = tf.layers.batch_normalization(c1)
img = tf.layers.conv2d_transpose(b3, 1, [4, 4], strides=(2, 2), padding='same', activation=tf.nn.tanh)
return img
Spring 2017 Assignments3的更多相关文章
- cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture11 Detection and Segmentation 听课笔记
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种"Unpooling"." ...
- cs231n spring 2017 lecture9 CNN Architectures 听课笔记
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture13 Generative Models
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture11 Detection and Segmentation
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种“Unpooling”.“Transpose Conv ...
- cs231n spring 2017 lecture9 CNN Architectures
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture7 Training Neural Networks II
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture16 Adversarial Examples and Adversarial Training 听课笔记
(没太听明白,以后再听) 1. 如何欺骗神经网络? 这部分研究最开始是想探究神经网络到底是如何工作的.结果人们意外的发现,可以只改变原图一点点,人眼根本看不出变化,但是神经网络会给出完全不同的答案.比 ...
随机推荐
- xtrabackup 全量备份、恢复数据
1.全量备份 [root@localhost lib]##innobackupex --defaults-file=$defaults_file --user=$mysql_username --pa ...
- 判断List中是否含有某个实体bean
注意:使用List.contains(Object object)方法判断ArrayList是否包含一个元素对象(针对于对象的属性值相同,但对象地址不同的情况),如果没有重写List的元素对象Obje ...
- [转载] 管Q某犇借的手写堆
跟gxy大神还有yzh大神学了学手写的堆,应该比stl的优先队列快很多. 其实就是维护了一个二叉堆,写进结构体里,就没啥了... 据说达哥去年NOIP靠这个暴力多骗了分 合并果子... templat ...
- MMM 数位dp学习记
数位dp学习记 by scmmm 开始日期 2019/7/17 前言 状压dp感觉很好理解(本质接近于爆搜但是又有广搜的感觉),综合了dp的高效性(至少比dfs,bfs优),又能解决普通dp难搞定的问 ...
- vs2010编译zapline-zapline.systemoptimization 注释工程中的//#define abs(value) (value >= 0 ? value : -(value))即可
vs2010编译zapline-zapline.systemoptimization-8428e72c88e0.zip出错 1>d:\program files (x86)\microsoft ...
- Excel催化剂开源第47波-Excel与PowerBIDeskTop互通互联之第一篇
当国外都在追求软件开源,并且在GitHub等平台上产生了大量优质的开源代码时,但在国内却在刮着一股收割小白智商税的知识付费热潮,实在可悲. 互联网的精神乃是分享,让分享带来更多人的受益. 在Power ...
- Gym - 101194L World Cup 暴力
World CupInput file: Standard InputOutput file: Standard OuptutTime limit: 1 second Here is World Cu ...
- android实现倒计时,最简单实现RecyclerView倒计时+SwipeRefreshLayout下拉刷新
先上效果图: RecyclerView + SwipeRefreshLayout 实现倒计时效果 MainActivity.java package top.wintp.counttimedemo1; ...
- C#7.2 新增功能
连载目录 [已更新最新开发文章,点击查看详细] C# 7.2 又是一个单点版本,它增添了大量有用的功能. 此版本的一项主要功能是避免不必要的复制或分配,进而更有效地处理值类型. C# 7.2 使 ...
- fjnuoj 1003 学长的QQ号
题目: //QQ是一个9位数,由1,2,3,4,5,9组成,且第1.6位数字相同,第2.4位数字相同,第5.7位数字相同. //我的QQ就在符合上诉条件中的所有9位数从小到大排第 ...