13. Go 语言网络爬虫
Go 语言网络爬虫
本章将完整地展示一个应用程序的设计、编写和简单试用的全过程,从而把前面讲到的所有 Go 知识贯穿起来。在这个过程中,加深对这些知识的记忆和理解,以及再次说明怎样把它们用到实处。由本章的标题可知,它是一个网络爬虫(或称网络内容爬取程序)的框架。
默认情况下,基于这个框架编写的网络爬虫程序是单机版的,也就是说,它仅会在一台计算机上运行。不过,在框架中留有一些易于扩展的接口,可以很方便地利用它们编写出一个分布式程序。当然,在这之前,需要先搞懂什么是分布式计算。
Go语言的特点是通过内部调度可以最大限度地利用单机的计算能力。然而,在分布式计算方面,它本身其实并没有提供什么现成的东西,还需要使用一些第三方的框架或工具,或者自己编写和搭建。
Go语言网络爬虫概述
简单来说,网络爬虫是互联网终端用户的模仿者。它模仿的主要对象有两个,一个是坐在计算器前使用网络浏览器访问网络内容的人类用户,另一个就是网络浏览器。
网络爬虫会模仿人类用户输入某个网站的网络地址,并试图访问该网站上的内容,还会模仿网络浏览器根据给定的网络地址去下载相应的内容。这里所说的内容可以是 HTML 页面、图片文件、音视频数据流,等等。
在下载到对应的内容之后,网络爬虫会根据预设的规则对它进行分析和筛选。这些筛选岀的部分会马上得到特定的处理。与此同时,网络爬虫还会像人类用户点击网页中某个他感兴趣的链接那样,继续访问和下载相关联的其他内容,然后再重复上述步骤,直到满足停止的条件。
如上所述,网络爬虫应该根据使用者的意愿自动下载、分析、筛选、统计以及存储指定的网络内容。注意,这里的关键词是“自动”和“根据意愿”。“自动”的含义是,网络爬虫在启动后自己完成整个爬取过程而无需人工干预,并且还能够在过程结束之后自动停止。而“根据意愿”则是说,网络爬虫最大限度地允许使用者对其爬取过程进行定制。
乍一看,要做到自动爬取貌似并不困难。我们只需让网络爬虫根据相关的网络地址不断地下载对应的内容即可。但是,窥探其中就可以发现,这里有很多细节需要我们进行特别处理,如下所示。
- 有效网络地址的发现和提取。
- 有效网络地址的边界定义和检查。
- 重复的网络地址的过滤。
在这些细节当中,有的是比较容易处理的,而有的则需要额外的解决方案。例如,我们都知道,基于 HTML 的网页中可以包含代表按钮的 button 标签。
让网络浏览器在终端用户点击按钮的时候加载并显示另一个网页可以有很多种方法,其中,非常常用的一种方法就是为该标签添加 onclick 属性并把一些 JavaScript 语言的代码作为它的值。
虽然这个方法如此常用,但是我们要想让网络爬虫可以从中提取出有效的网络地址却是比较 困难的,因为这涉及对JavaScript程序的理解。JavaScript代码的编写方法繁多,要想让 网络爬虫完全理解它们,恐怕就需要用到某个JavaScript程序解析器的 Go语言实现了。
另一方面,由于互联网对人们生活和工作的全面渗透,我们可以通过各种途径找到各式各样的网络爬虫实现,它们几乎都有着复杂而又独特的逻辑。这些复杂的逻辑主要针对如下几个方面。
- 在根据网络地址组装 HTTP 请求时,需要为其设定各种各样的头部 (Header) 和主体 (Body)。
- 对网页中的链接和内容进行筛选时需要用到的各种条件,这里所说的条件包括提取条件、过滤条件和分类条件,等等。
- 处理筛选出的内容时涉及的各种方式和步骤。
这些逻辑绝大多数都与网络爬虫使用者当时的意愿有关。换句话说,它们都与具体的使用目的有着紧密的联系。也许它们并不应该是网络爬虫的核心功能,而应该作为扩展功能或可定制的功能存在。
因此,我想我们更应该编写一个容易被定制和扩展的网络爬虫框架,而非一个满足特定爬取目的的网络爬虫,这样才能使这个程序成为一个可适用于不同应用场景的通用工具。
既然如此,接下来我们就要搞清楚该程序应该或可以做哪些事,这也能够让我们进一步明确它的功能、用途和意义。
功能需求和分析
概括来讲,网络爬虫框架会反复执行如下步骤直至触碰到停止条件。
1) “下载器”
下载与给定网络地址相对应的内容。其中,在下载“请求”的组装方面,网络爬虫框架为使用者尽量预留出定制接口。使用者可以使用这些接口自定义“请求”的组装方法。
2) “分析器”
分析下载到的内容,并从中筛选出可用的部分(以下称为“条目”)和需要访问的新网络地址。其中,在用于分析和筛选内容的规则和策略方面,应该由网络爬虫框架提供灵活的定制接口。
换句话说,由于只有使用者自己才知道他们真正想要的是什么,所以应该允许他们对这些规则和策略进行深入的定制。网络爬虫框架仅需要规定好定制的方式即可。
3) “分析器”
把筛选出的“条目”发送给“条目处理管道”。同时,它会把发现的新网络地址和其他一些信息组装成新的下载“请求”,然后把这些请求发送给“下载器”。在此步骤中,我们会过滤掉一些不符合要求的网络地址,比如忽略超出有效边界的网络地址。
你可能已经注意到,在这几个步骤中,我使用引号突出展示了几个名词,即下载器、请求、分析器、条目和条目处理管道,其中,请求和条目都代表了某类数据,而其他 3 个名词则代表了处理数据的子程序(可称为处理模块或组件)。
它们与前面已经提到过的网络内容(或称对请求的响应)共同描述了数据在网络爬虫程序中的流转方式。下图演示了起始于首次请求的数据流程图。
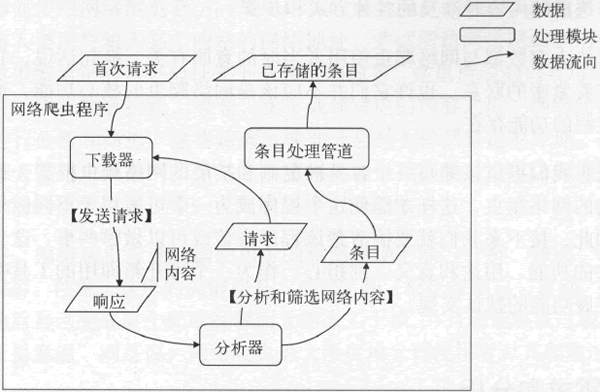
图:起始于首次请求的数据流程图
从上图中,我们可以清晰地看到每一个处理模块能够接受的输入和可以产生的输出。实际上,我们将要编写的网络爬虫框架就会以此为依据形成几个相对独立的子程序。
当然,为了维护它们的运行和协作的有效性,框架中还会存在其他一些子程序。关于它们,我会在后面陆续予以说明。
这里,我再次强调一下网络爬虫框架与网络爬虫实现的区别。作为一个框架,该程序在每个处理模块中给予使用者尽量多的定制方法,而不去涉及各个处理步骤的实现细节。
另外,框架更多地考虑使用者自定义的处理步骤在执行期间可能发生的各种情况和问题,并注意对这些问题的处理方式,这样才能在易于扩展的同时保证框架的稳定性。这方面的思考和策略会体现在该网络爬虫框架的各阶段设计和编码实现之中。
下面我就根据上述分析对这一程序进行总体设计。
总体设计
通过上图可知,网络爬虫框架的处理模块有 3 个:下载器、分析器和条目处理管道。再加上调度和协调这些处理模块运行的控制模块,我们就可以明晰该框架的模块划分了。我把这里提到的控制模块称为调度器。下面是这 4 个模块各自承担的职责。
1) 下载器
接受请求类型的数据,并依据该请求获得 HTTP 请求;将 HTTP 请求发送至与指定的网络地址对应的远程服务器;在 HTTP 请求发送完毕之后,立即等待相应的 HTTP 响应的到来;在收到 HTTP 响应之后,将其封装成响应并作为输出返回给下载器的调用方。
其中,HTTP 客户端程序可以由网络爬虫框架的使用方自行定义。另外,若在该子流程执行期间发生了错误,应该立即以适当的方式告知使用方。对于其他模块来讲,也是这样。
2) 分析器
接受响应类型的数据,并依据该响应获得 HTTP 响应;对该 HTTP 响应的内容进行检查,并根据给定的规则进行分析、筛选以及生成新的请求或条目;将生成的请求或条目作为输出返回给分析器的调用方。
在分析器的职责中,我可以想到的能够留给网络爬虫框架的使用方自定义的部分并不少。例如,对 HTTP 响应的前期检查、对内容的筛选,以及生成请求和条目的方式,等等。不过,我在后面会对这些可以自定义的部分进行一些取舍。
3) 条目处理管道
接受条目类型的数据,并对其执行若干步骤的处理;条目处理管道中可以产出最终的数据;这个最终的数据可以在其中的某个处理步骤中被持久化(不论是本地存储还是发送给远程的存储服务器)以备后用。
我们可以把这些处理步骤的具体实现留给网络爬虫框架的使用方自行定义。这样,网络爬虫框架就可以真正地与条目处理的细节脱离开来。网络爬虫框架丝毫不关心这些条目怎样被处理和持久化,它仅仅负责控制整体的处理流程。我把负责单个处理步骤的程序称为条目处理器。
条目处理器接受条目类型的数据,并把处理完成的条目返回给条目处理管道。条目处理管道会紧接着把该条目传递给下一个条目处理器,直至给定的条目处理器列表中的每个条目处理器都处理过该条目为止。
4) 调度器
调度器在启动时仅接受首次请求,并且不会产生任何输出。调度器的主要职责是调度各个处理模块的运行。其中包括维护各个处理模块的实例、在不同的处理模块实例之间传递数据(包括请求、响应和条目),以及监控所有这些被调度者的状态,等等。
有了调度器的维护,各个处理模块得以保持其职责的简洁和专一。由于调度器是网络爬虫框架中最重要的一个模块,所以还需要再编写出一些工具来支撑起它的功能。
在弄清楚网络爬虫框架中各个模块的职责之后,你知道它是以调度器为核心的。此外,为了并发执行的需要,除调度器之外的其他模块都可以是多实例的,它们由调度器持有、维护和调用。反过来讲,这些处理模块的实例会从调度器那里接受输入,并在进行相应的处理后将输出返回给调度器。
最后,与另外两个处理模块相比,条目处理管道是比较特殊的。顾名思义,它是以流式处理为基础的,其设计灵感来自于我之前讲过的 Linux 系统中的管道。
我们可以不断地向该管道发送条目,而该管道则会让其中的若干个条目处理器依次处理每一个条目。我们可以很轻易地使用一些同步方法来保证条目处理管道的并发安全性,因此即使调度器只持有该管道的一个实例,也不会有任何问题。
下图展示了调度器与各个处理模块之间的关系,图中加入了一个新的元素——工具箱,之前所说的用于支撑调度器功能的那些工具就是工具箱的一部分。顾名思义,工具箱不是一个完整的模块,而是一些工具的集合,这些工具是调度器与所有处理模块之间的桥梁。
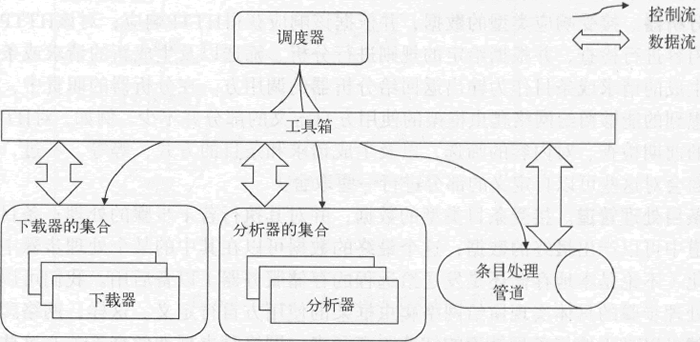
图:调度器与各处理模块的关系
至此,大家对网络爬虫框架的设计有了一个宏观上的认识。不过,我还未提及在这个总体设计之下包含的大量设计技巧和决策。这些技巧和决策不但与一些通用的程序设计原则有关,还涉及很多依赖于 Go语言的编程风格和方式方法。
这也从侧面说明,由于几乎所有语言都有着非常鲜明的特点和比较擅长的领域,所以在设计一个需要由特定语言实现的软件或程序时,多多少少会考虑到这门语言自身的特性。也就是说,软件设计不是与具体的语言毫不相关的。反过来讲,总会有一门或几门语言非常适合实现某一类软件或程序。
Go语言网络爬虫中的基本数据结构
为了承载和封装数据,需要先声明一些基本的数据结构。网络爬虫框架中的各个模块都会用到这些数据结构,所以可以说它们是这一程序的基础。
在分析网络爬虫框架的需求时,提到过这样几类数据——请求、响应、条目,下面我们逐个讲解它们的声明和设计理念。
请求用来承载向某一个网络地址发起的 HTTP 请求,它由调度器或分析器生成并传递给下载器,下载器会根据它从远程服务器下载相应的内容。因此,它有一个 net/http.Request 类型的字段。
不过,为了减少不必要的零值生成(http.Request 是一个结构体类型,它的零值不是 nil)和实例复制,我们把 *http.Request 作为该字段的类型。下面是 base.Request 类型的声明的第一个版本:
//数据请求的类型
type Request struct {
// HTTP请求
httpReq *http.Request
}我把基本数据结构的声明都放到了示例项目下的代码包 gopcp.v2/chapter6/webcra-wler/module 中。因此,其他代码包中的代码在访问这些类型时一般会用到限定符 module。示例项目大家可以从我的网盘中下载(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)。
从已经提到的相关需求来看,这样的声明已经足够了。不过,我也说过网络爬虫能够在爬取过程结束之后自动停止。那么,网络爬虫在对一个网站上的内容爬取到什么程度才结束呢?量化内容爬取程度的一个比较常用的方法,是计算每个下载的网络内容的深度。
网络爬虫可以根据最大深度的预设值忽略掉对“更深”的网络内容的下载。当所有在该最大深度范围内的网络内容都下载完成时,就意味着爬取过程即将结束。待这些内容分析和处理完成后,就能够判定网络爬虫对爬取过程的执行是否真正结束了。因此, 为了记录网络内容的深度,我们还应该在 Request 类型的声明中加入一个字段,它的第二个版本如下:
//数据请求的类型
type Request struct {
// HTTP请求
httpReq *http.Request
//请求的深度
depth uint32
}
//用于创建一个新的请求实例
func NewRequest(httpReq *http.Request, depth uint32) *Request {
return &Request{httpReq: httpReq, depth: depth}
}
//用于获取 HTTP 请求
func (req *Request) HTTPReq() *http.Request {
return req.httpReq
}
//用于获取请求的深度
func (req *Request) Depth() uint32 {
return req.depth
}我希望这个类型的值是不可变的。也就是说,在该类型的一个值创建和初始化之后, 当前代码包之外的任何代码都不能更改它的任何字段值。对于这样的需求,一般会通过以下 3 个步骤来实现。
1) 把该类型的所有字段的访问权限都设置为包级私有。也就是说,要保证这些字段 的名称首字母均为小写。
2) 编写一个创建和初始化该类型值的函数。由于该类型的所有字段均不能被当前代码包之外的代码直接访问,所以它们自然也就无法为这样的字段赋值。这也是需要编写这样一个函数的原因。这类函数的名称一般都以“New”为前缀,它们会接受一些参数值,然后以此为基础初始化一个目标类型的值并将其作为函数结果返回。
3) 编写必要的用来获取字段值的方法。这一步骤并不是必需的。不编写这样的方法的原因可能是想要完全隐藏字段值,也可能是字段的类型导致不宜公开其值。比如,如果字段是引用类型的,那么只要它的值可以被外部获取,就等于让外部有了修改权限。
注意,NewRequest 函数的结果类型是 Request,而不是 Requesto 这样做的主要原因是要为 Request 类型编写指针方法而非值方法,并以此让 Request 成为某个接口类型的实现类型。更深层次的原因是,值在作为参数传递给函数或者作为结果由函数返回时会被复制一次。指针值往往更能减小复制的开销。
这里再说明一下 Request 类型的 depth字段。理论上,uint32 类型已经可以使 depth 字段的值足够大了。由于深度值不可能是负数,所以也不需要为此牺牲正整数的部分取值范围。传递给调度器的首次请求的深度值是 0,这也是首次请求的一个标识。
那么,后续请求的深度值应该怎样计算和传递呢?假设下载器发出了首次请求“A”并成功接收到了响应,经过分析器的分析,其中找到了两个新的网络地址并生成了新的请求“B”和“C”,那么这两个新请求的深度值就为 1。
如果在接收并分析了请求“B”的响应之后又生成了一个新请求“D”,那么后者的深度值就是 2,以此类推。我们可以把首次请求看作请求“B”和请求“C”的父请求,反过来讲,可以把请求“B”和请求“C”视作首次请求的子请求。
因此,就有了这样一条规则:一个请求的深度值等于对它的父请求的深度值递增一次后的结果。
理解了刚刚对请求深度值计算方法的描述之后,你可能会发现:只有对某个请求的响应内容进行分析之后,才可能需要生成新的请求。并且,调度器并不会直接把请求作为参数传递给分析器。这样不符合我们先前对数据流转方式的设计,同时也会使这两个处理模块之间的交互变得混乱。
显然,响应也携带深度值。一方面,这可以算作标示响应深度的一种方式。另一方面,也是更重要的一方面,它可以作为新请求的深度值的计算依据。因此,Response 类型的声明如下:
//数据响应的类型
type Response struct {
// HTTP响应
httpResp *http.Response
//响应的深度
depth uint32
}
//用于创建一个新的响应实例
func NewResponse(httpResp *http.Response, depth uint32) *Response {
return &Response{httpResp: httpResp, depth: depth}
}
//用于获取HTTP响应
func (resp *Response) HTTPResp() *http.Response {
return resp.httpResp
}
//用于获取响应深度
func (resp *Response) Depth() uint32 {
return resp.depth
}这个类型的声明不再做解释,其各部分的含义与 Request 类型类似。
除了请求和响应这两个有着对应关系的数据结构之外,还需要定义条目的结构。条目的实例需要存储的内容比请求和响应复杂得多。因为对响应的内容进行筛选并生成出条目的规则也是由网络爬虫框架的使用者自己制定的。
因此,条目的结构足够灵活,其实例可以容纳所有可能从响应内容中筛选出的数据。基于此,我这样定义条目的类型声明:
//条目的类型
type Item map[string]interface{}我们把 Item 类型声明为字典类型 map[string]interface{} 的别名类型,这样就可以最大限度地存储多样的数据了。由于条目处理器也是由网络爬虫框架的使用者提供,所以这里并不用考虑字典中的各个元素值是否可以被条目处理器正确理解的问题。
好了,我们需要的 3 个基本数据类型都在这里了。为了能够用一个类型从整体上标识这 3 个基本数据类型,我们又声明了 Data 接口类型:
//数据的接口类型
type Data interface {
//用于判断数据是否有效
Valid() bool
}这个接口类型只有一个名为 Valid 的方法,可以通过调用该方法来判断数据的有效性。显然,Data接口类型的作用更多的是作为数据类型的一个标签,而不是定义某种类型的行为。为了让表示请求、响应或条目的类型都实现 Data 接口,又在当前的源码文件中添加了这样几个方法:
//用于判断请求是否有效
func (req *Request) Valid() bool {
return req.httpReq != nil && req.httpReq.URL != nil
}
//用于判断响应是否有效
func (resp *Response) Valid() bool {
return resp.httpResp != nil && resp.httpResp.Body != nil
}
//用于判断条目是否有效
func (item Item) Valid() bool {
return item != nil
}这样一来,这 3 个类型因 Data 接口类型而被归为一类。在后面,你会了解到这样做还有另外的功效。
至此,实现网络爬虫框架需要用到的基本数据类型均已编写完成。不过,这里我们还需要一个额外的类型,这个类型是作为 error 接口类型的实现类型而存在的。它的主要作用是封装爬取过程中出现的错误,并以统一的方式生成字符串形式的描述。
我们知道, 只要某个类型的方法集合中包含了下面这个方法,就等于实现了 error 接口类型:
func Error() string为此,首先声明了一个名为 CrawlerError 的接口类型:
//爬虫错误的接口类型
type CrawlerError interface {
//用于获得错误的类型
Type() ErrorType
//用于获得错误提示信息
Error() string
}我们把它放在了 gopcp.v2/chapter6/webcrawler/errors 代码包中,其中 Type 方法的结果类型 ErrorType 只是一个 string 类型的别名类型而已。另外,由于 CrawlerError 类型的声明中也包含了 Error 方法,所以只要某个类型实现了它,就等于实现了 error 接口类型。
先编写这样一个接口类型而不是直接编写出 error 接口类型的实现类型的原因有两个。第一,我们在编程过程中应该遵循面向接口编程的原则,这个原则我已经提过多次了。第二是为了扩展 error 接口类型。网络爬虫框架拥有多个处理模块,错误类型值可以表明该错误是哪一个处理模块产生的,这也是 Type 方法起到的作用。
下面就让我们来实现这个接口类型。遵照本书中对实现类型的命名风格,我们声明了结构体类型 myCrawlerError:
//爬虫错误的实现类型
type myCrawlerError struct {
//错误的类型
errType ErrorType
//错误的提示信息
errMsg string
//完整的错误提示信息
fullErrMsg string
}字段 errMsg 的值由初始化 myCrawlerError 类型值的一方给出,这与传递给 errors.New 函数的参数值的含义类似。作为附加信息,errType 字段的值就是该类型的 Type 方法的结果值,它代表了错误类型。为了便于使用者为该字段赋值,还声明了一些常量:
//错误类型常量
const (
//下载器错误
ERROR_TYPE_DOWNLOADER ErrorType = "downloader error"
//分祈器错误
ERROR_TYPE_ANALYZER ErrorType = "analyzer error"
//条目处理管道错误
ERROR_TYPE_PIPELINE ErrorType = "pipeline error"
//调调度器错误
ERROR_TYPE_SCHEDULER ErrorType = "scheduler error"
)可以看到,这 4 个常量的类型都是 ErrorType,它们分别与网络爬虫框架中的主要模块相对应。当某个模块在运行过程中出现了错误,程序就会使用对应的 ErrorType 类型的常量来初始化一个 CrawlerError 类型的错误值。具体的初始化方法就是使用 NewCrawler-Error 函数,其声明如下:
//用于创建一个新的爬虫错误值
func NewCrawlerError(errType ErrorType, errMsg string) CrawlerError {
return &myCrawlerErro:r{
errType: errType,
errMsg: strings.TrimSpace(errMsg),
}
}从该函数的函数体可以看出,*myCrawlerError 类型是 CrawlerError 类型的一个实现类型。*myCrawlerError 型的方法集合中包含 CrawlerError 口类型中的 Type 方法和 Error 方法:
func (ce *myCrawlerError) Type() ErrorType {
return ce.errType
}
func (ce *myCrawlerError) Error() string {
if ce.fullErrMsg == "" {
ce.genFullErrMsg()
}
return ce.fullErrMsg
}你可能已经发现,Error 方法中用到了 myCrawlerError 型的 fullErrMsg 字段。并且,它还调用了一个名为 genFullErrMsg 的方法,该方法的实现如下:
//用于生成错误提示信息,并给相应的字段赋值
func (ce *myCrawlerError) genFullErrMsg() {
var buffer bytes.Buffer
buffer.Writestring("crawler error:")
if ce.errType != "" {
buffer.WriteString(string(ce.errType))
buffer.WriteString(":")
}
buffer.WriteString(ce. errMsg)
ce.fullErrMsg = fmt.Sprintf("%s", buffer.String())
return
}genFullErrMsg 方法同样是 myCrawlerError 类型的指针方法,它的功能是生成 Error 方法需要返回的结果值。可以看到,这里没有直接用 errMsg 字段的值,而是以它为基础生成了一条更完整的错误提示信息。在这条信息中,明确显示岀它是一个网络爬虫的错误,也给出了错误的类型和详情。
注意,这条错误提示信息缓存在 fullErrMsg 字段中。回顾该类型的 Error 方法的实现,只有当 fullErrMsg 字段的值为 "" 时,才会调用 genFullErrMsg 方法,否则会直接把 fullErrMsg 字段的值作为 Error 方法的结果值返回。
这也是为了避免频繁地拼接字符串给程序性能带来的负面影响。在 genFullErrMsg 方法的实现中使用了 bytes.Buffer 类型值作为拼接错误信息的手段。
虽然这样做确实可以大大减小这一负面影响,但是由于 myCrawlerError 类型的值是不可变的,所以缓存错误提示信息还是很有必要的。其根本原因是,对这样的不可变值的缓存永远不会失效。
前面展示的这些类型对于承载数据(不论是正常数据还是错误信息)来说已经足够了,它们是网络爬虫框架中最基本的元素。
Go语言网络爬虫的接口设计
这里所说的接口是指网络爬虫框架中各个模块的接口。与先前描述的基本数据结构不同,它们的主要职责是定义模块的行为。在定义行为的过程中,我会对它们应有的功能作进一步的审视,同时也会更多地思考它们之间的协作方式。
下面就开始逐一设计网络爬虫框架中的这类接口,以及相关的其他类型。为了更易于理解,先从那几个处理模块的接口开始,然后再去考虑怎样定义调度器以及它会用到的各种工具的行为。
下载器
下载器的功能就是从网络中的目标服务器上下载内容。内容在网络中的唯一标识是网络地址,但是它只能起到定位的作用,并不是成功下载内容的充分条件。
HTTP 协议是基于 TCP/IP 协议栈的应用层协议,它是互联网世界的根基之一。因此,互联网时代诞生的绝大多数语言都会使用不同的方式提供针对该协议的 API。当然,Go语言也不例外。Go 的标准库代码包 net/http 就提供了这类 API。
在编写网络爬虫框架的基本数据结构时,就用过其中的两个类型:http.Request 和 http.Response。实际上,我们将要构建的网络爬虫框架就是以 HTTP 协议和 net/http 代码包中的 API 为基础的。
从下载器充当的角色来讲,它的功能只有两个:发送请求和接收响应。因此,我可以设计出这样一个方法声明:
//用于根据请求获取内容并返回响应
Download(req *Request) (*Response, error)Download 的签名完全体现出了下载器应有的功能。但是作为处理模块,下载器还应该拥有一些方法以供统计、描述之用。不过正因为这些方法是所有处理模块都应具备的,所以要编写一个更加抽象的接口类型。请看下面的声明:
//Module代表组件的基础接口类型。
//该接口的实现类型必须是并发安全的
type Module interface {
//用于获取当前组件的ID
ID() MID
//用于获取当前组件的网络地址的字符串形式
Addr() string
//用于荻取当前组件的评分
Score() uint64
//用于设置当前组件的评分
SetScore(score uint64)
//用于获取评分计算器
ScoreCalculator() CalculateScore
//用于获取当前组件被调用的计数
CalledCount() uint64
//用于获取当前组件接受的调用的计数,
//组件一般会由于超负荷或参数有误而拒绝调用
AcceptedCount() uint64
//用于获取当前组件已成功完成的调用的计数
CompletedCount() uint64
//用于获取当前组件正在处理的调用的数量
HandlingNumber() uint64
//用于一次性获取所有计数
Counts() Counts
//用于获取组件摘要
Summary() SummaryStruet
}处理模块之所以又称为组件,是因为它们实现的都是扩展功能,可组装到网络爬虫框架上。但同时它们又是重要的,因为如果没有它们,就无法使用这个框架编写出一个可以运转起来的网络爬虫。
Module 接口定义了组件的基本行为。其中,MID 是 string 的别名类型,它的值一般由 3 部分组成:标识组件类型的字母、代表生成顺序的序列号和用于定位组件的网络地址。网络地址是可选的,因为组件实例可以和网络爬虫的主程序处于同一个进程中。下面的模版声明可以很好地说明 MID 类型值的构成:
//组件ID的模板
var midTemplate = "%s%d|%s"说到标识组件类型的字母,就要先介绍一下组件的类型。请看下面的声明:
//组件的类型
type Type string
//当前认可的组件类型的常量
const (
//下载器
TYPE_DOWNLOADER Type = "downloader"
//分析器
TYPE_ANALYZER Type = "analyzer"
//棗目处理管道
TYPE_PIPELINE Type = "pipeline"
)组件类型常量的值已经直白地表达了其含义。基于此,我可以明确它们与字母之间的对应关系:
//合法的组件类型-字母的映射
var legalTypeLetterMap = map[Type]string{
TYPE_DOWNLOADER: "D",
TYPE_ANALYZER: "A",
TYPE_PIPELINE: "P",
}组件 ID 中的序列号可以由网络爬虫框架的使用方提供。这就需要我们在框架内提供一个工具,以便于统一序列号的生成和获取。序列号原则上是不能重复的,也是顺序给出的。但是如果序列号超出了给定范围,就可以循环使用。据此,我编写了一个序列号生成器的接口类型:
//序列号生成器的接口类型
type SNGenertor interface {
//用于获取预设的最小序列号
Start() uint64
//用于获取预设的最大序列号
Max() uint64
//用于获取下一个序列号
Next() uint64
//用于获取循环计数
CycleCount() uint64
//用于获得一个序列号并准备下一个序列号
Get() uint64
}其中最小序列号和最大序列号都可以由使用方在初始化序列号生成器时给定。循环计数代表了生成器生成的序列号在前两者指定的范围内循环的次数。
网络地址在 MID 中的格式是 ":",例如 "127.0.0.1:8080",这类字符串其实就是 Module 接口的 Addr 方法返回的。
下图展示和总结了组件 ID 的构成及生成方法。
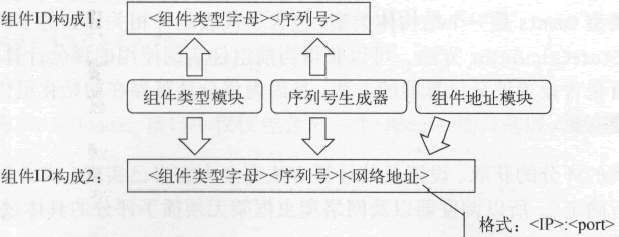
图:组件 ID 的构成及生成方法
这里涉及的模块以及其他与组件有关的所有基础接口和模块都放到了代码包 gopcp.v2/chapter6/webcrawler/module 中。大家可以在我的网盘中下载(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)。
Module 接口中的第 3 个至第 5 个方法是关于组件评分的,这又涉及组件注册方面的设计。按照我的设想,在网络爬虫程序真正启动之前,应该先向组件注册器注册足够的组件实例。只有如此,程序才能正常运转。组件注册器可以注册、注销以及获取某类组件的实例,并且还可以清空所有组件实例。所以,它的接口类型这样声明:
//组件注册器的接口
type Regisinterface {
//用于注册组件实例
Register(module Module) (bool, error)
//用于注销组件实例
Unregister(mid MID) (bool, error)
//用于获取一个指定类型的组件的实例,
//该函数基于负载均衡策略返回实例
Get(moduleType Type) (Module, error)
//用于获取指定类型的所有组件实例
GetAllByType(moduleType Type) (map[MID]Module, error)
//用于获取所有组件实例
GetAll() map[MID]Module
//清除所有的组件注册记录
Clear()
}这个接口的 Get 方法用于获取一个特定类型的组件实例,它实现某种负载均衡策略,使得同一类型的多个组件实例有相对平均的机会作为结果返回。这里所说的负载均衡策略就是基于组件评分的。组件评分可以通过 Module 接口定义的 Score 方法获得。相对地,SetScore 方法用于设置评分。这个评分的计算方法抽象为名为 CalculateScore 的函数类型,其声明如下:
//用于计算组件评分的函数类型
type CalculateScore func(counts Counts) uint64其参数类型 Counts 是一个结构体类型,包含了代表组件相关计数的字段。通过 Module 接口定义的 ScoreCalculator 方法,可以获得当前组件实例使用的评分计算器。Module 接口之所以没有包含设置评分计算器的方法,是因为评分计算器在初始化组件实例时给定,并且之后不能变更。
组件实例的评分的获取、设置及其计算方法完全由它自己实现(或者由网络爬虫框架的使用方自行确定),所以调度器以及网络爬虫框架无须插手评分的具体过程,仅仅确定评分的制度就好了。
再回到 Module 接口的声明,其中第 6 个至第 10 个方法用于获取各种计数,并且第 10 个方法的结果的类型就是 Counts。这就形成了一个闭环,让组件的评分机制在接口层面变得完整。
Module 接口中的最后一个方法 Summary,用于获取组件实例的摘要信息。注意,这个摘要信息并不是字符串形式的,而是 SummaryStruct 类型的。这种结构化的摘要信息对于控制模块和监控工具都更加友好,同时也有助于组装和嵌入。SummaryStruct 类型的声明是这样的:
//组件摘要结构的类型
type SummaryStruct struct {
ID MID 'json:"id"'
Called uint64 'json:"called"'
Accepted uint64 'json:"accepted"'
Completed uint64 'json:"completed"'
Handling uint64 'json:"handling"'
Extra interface{} 'json:"extra,omitempty"'
}如果你使用过标准库中的 encoding/json 包的话,就一定知道这个类型的值可以序列化为 JSON 格式的字符串。实际上,网络爬虫框架中的所有摘要类信息都是如此。当今主流的日志收集系统大都可以宜接解析 JSON 格式的日志文本。
另外,你可以顺便注意一下 SummaryStruct 类型中的 Extra 字段,该字段的作用是为额外的组件信息的纳入提供支持。
讲完了 Module 接口的声明以及相关的各种类型定义和设计理念,让我们再回过头去接着设计下载器的接口。有了上述的一系列铺垫,组件实例的基本结构和方法以及对它们的管理规则都已经比较明确了。下载器的接口声明反而变得简单了,如下所示:
// Downloader代表下载器的接口类型。
// 该接口的实现类型必须是并发安全的
type Downloader interface {
Module
//根据请求获取内容并返回响应
Download(req *Request) (*Response, error)
}可以看到,Downloader 接口中仅仅包含了一个 Module 接口的嵌入和前面提到的那个 Download 方法。
分析器
分析器的职责是根据给定的规则分析响应,下面就是其接口类型的声明:
// Analyzer代表分析器的接口类型。
// 该接口的实现类型必须是并发安全的
type Analyzer interface {
Module
//用于返回当前分析器使用的响应解析函数的列表
RespParsers() []ParseResponse
//根据规则分析响应并返回请求和条目,
//响应需要分别经过若干响应解析函数的处理,然后合并结果
Analyze(resp *Response) ([]Data, []error)
}Analyzer 接口与下载器的接口一样,都嵌入了 Module 接口,并且都声明了一个简单明了的方法用于执行属于自己的任务。这里多出的 RespParsers 方法用于获取分析器示例使用的响应解析器(也称 HTTP 响应解析函数),它的结果类型是元素类型为 ParseResponse 的切片类型。
ParseResponse 是一个函数类型,它的声明如下:
//用于解析 http 响应的函数的类型
type ParseResponse func(httpResp *http.Response, respDepth uint32) ([]Data, []error)声明这样一个函数类型的意义在于让网络爬虫框架的使用者可以自定义响应的分析过程,以及生成相应的请求和条目的方式。该函数类型的参数 httpResp 表示目标服务器返回的 HTTP 响应,而参数 respDepth 则代表了该响应的深度。
我实际上把整个响应分析、筛选和结果生成的过程都寄托于使用者提供的 ParseResponse 函数类型的实现。而在 Analyze 方法的实现中,我只想把若干个此类 HTTP 响应解析函数的结果合并起来返回而已。
这里体现了多层定制接口的设计理念。第一层接口就是 Downloader、Analyzer 这类,你可以完全实现自己的下载器和分析器。第二层就是诸如 ParseResponse 的函数类型。如果你想使用框架提供的默认组件实现,就可以只编写这类函数,这同样也可以达到高度定制的目的。
条目处理管道
条目处理管道的功能就是为条目的处理提供环境,并控制整体的处理流程,具体的处理步骤由网络爬虫框架的使用者提供。实现单一处理步骤的程序称为条目处理器。它的类型同样由单一的函数类型代表,所以也可以称为条目处理函数。这又会是一组双层定制接口,下面我们来看看相关的类型声明:
// Pipeline 代表条目处理管道的接口类型。
// 该接口的实现类型必须是并发安全的
type Pipeline interface {
Module
//用于返回当前条目处理管道使用的条目处理函数的列表
ItemProcessors() []ProcessItem
// Send 会向条目处理管道发送条目
//条目需要依次经过若干条目处理函数的处理
Send(item Item) []error
// FailFast 方法会返回一个布尔值,该值表示当前条目处理管道是否是快速失败的。
//这里的快速失败是指:只要在处理某个条目时在某一个步骤上出错,
//那么条目处理管道就会忽略掉后续的所有处理步骤并报告错误
FailFast() bool
//设置是否快速失败
SetFailFast(failFast bool)
}
//用于处理条目的函数的类型
type ProcessItem func(item Item) (result Item, err error)Pipeline 接口中最重要的方法就是 Send 方法,该方法使条目处理管道的使用方可以向它发送条目,以使其中的条目处理器(也称条目处理函数)对这些条目进行处理。
FailFast 方法和 SetFailFast 对应于条目处理管道的“快速失败”特性。方法的注释对这一特性已有清晰的描述。至于 ItemProcessors 方法,我就不多说了。
函数类型 Processitem 接受一个需要处理的条目,并把处理后的条目和可能发生的错误作为结果值返回。如果第二个结果值不为 nil,就说明在这个处理过程中发生了一个错误。
最后,一定要注意,与下载器和分析器一样,条目处理管道的实现也一定要是并发安全的。也就是说,它们的任何方法在同时调用时都不能产生竞态条件。这主要是因为调度器会在任何需要的时候从组件注册器中获取一个组件实例并使用。
同一个组件实例可能会用来并发处理多个数据。组件实例不能成为调度器执行并发调度的阻碍。此外,与之有关的各种计数和摘要信息的读写操作同样要求组件本身具有并发安全性。
调度器
调度器属于控制模块而非处理模块,它需要对各个处理模块的运作进行调度和控制。可以说,调度器是网络爬虫框架的心脏。因此,我需要由它来启动和停止爬取流程。另外,出于监控整个爬取流程的目的,还应该在这里提供获取实时状态和摘要信息的方法。
依照这样的思路,我们编写了这样一个接口类型声明:
//调度器的接口类型
type Scheduler interface {
// Init用于初始化调度器。
//参数requestArgs代表请求相关的参数。
//参数dataArgs代表数据相关的参数。
//参数moduleArgs代表组件相关的参数
Init(requestArgs RequestArgs,
dataArgs DataArgs,
moduleArgs ModuleArgs) (err error)
// Start用于启动调度器并执行爬取流程
//参数firstHTTPReq代表首次请求,调度器会以此为起始点开始执行爬取流程
Start(firstHTTPReq *http.Request) (err error)
//Stop用于停止调度器的运行
//所有处理模块执行的流程都会被中止
Stop() (err error)
//用于获取调度器的状态
Status() Status
// ErrorChan用于获得错误通道。
//调度器以及各个处理模块运行过程中出现的所有错误都会被发送到该通道。
//若结果值为nil,则说明错误通道不可用或调度器已停止
ErrorChan() <-chan error
//用于判断所有处理模块是否都处于空闲状态
Idle() bool
//用于获取摘要实例
Summary() SchedSummary
}Scheduler 接口类型的声明及相关代码都放在 gopcp.v2/chapter6/webcrawler/scheduler 代码包中。
Scheduler 接口的 Init 方法用于调度器的初始化。初始化调度器需要一些参数,这些参数分为 3 类:请求相关参数、数据相关参数和组件相关参数。这 3 类参数分别封装在了 RequestArgs、DataArgs 和 ModuleArgs 类型中。RequestArgs 类型的声明如下:
//请求相关的参数容器的类型
type RequestAigs struet {
// AcceptedDomains 代表可以接受的 URL 的主域名的列表。
// URL 主域名不在列表中的请求都会被忽略
AcceptedDomains []string 'json:"accepted_primary_domains"'
// MaxDepth 代表需要爬取的最大深度。
//实际深度大于此值的请求都会被忽略
MaxDepth uint32 'json:"max_depth"'
}该类型中的两个字段都是用来定义爬取范围的。AcceptedDomains 用于指定可以接受的 HTTP 请求的 URL,用其主域名作为限定条件。因为几乎没有一个非个人的网站不存在指向其他网站的链接。
所以,如果不加以控制,随着爬取深度的增加,爬取范围会不断地急剧扩大。这对于网络爬虫程序可能会是一个灾难。导致的结果就是,新的爬取目标越来越多,爬取过程总也无法结束。所以,我们一定要在爬取广度方面有所约束。
而最大爬取深度则是另外一方面的约束,我在前面已经描述过它的计算方法。有了这两个方面的约束,我们就为爬取明确了一个范围,爬取的目标不会也不应该超岀这个范围。
DataArgs 类型中包括的是与数据缓冲池相关的字段,这些字段的值用于初始化对应的数据缓冲池。调度器使用这些数据缓冲池传递数据。具体来说,调度器使用的数据缓冲池有 4 个——请求缓冲池、响应缓冲池、条目缓冲池和错误缓冲池,它们分别用来传输请求类型、响应类型、条目类型和 error 类型的数据。
根据我对缓冲池的接口类型的定义(至此还未讲过),每个缓冲池需要两个参数,包括:缓冲池中单一缓冲器的容量,以及缓冲池包含的缓冲器的最大数量。这样算来,DataArgs 类型中字段的总数就是 8,下面是该类型的声明:
//数据相关的参数容器的类型
type DataArgs struct {
//请求缓冲器的容量
ReqBufferCap uint32 'json:":req_buffer_cap"'
//请求缓冲器的最大数量
ReqMaxBufferNumber uint32 'json:"req_max_buffer_number"'
//响应缓冲器的容量
RespBufferCap uint32 'json:":resp_buffer_cap"'
//响应缓冲器的最大数量
RespMaxBufferNumber uint32 'json:"resp_max_buffer_number"'
//条目缓冲器的容量
ItemBufferCap uint32 'json:"item_buffer_cap"'
//条目缓冲器的最大数量
ItemMaxBufferNumber uint32 'json:"item_max_buffer_number"'
//错误缓冲器的容量
ErrorBufferCap uint32 'json:"error_buffer_cap"'
//错误缓冲器的最大数量
ErrorMaxBufferNumber uint32 'json:"error_max_buffer_number"'
}关于缓冲池和缓冲器的接口定义,后面会专门介绍,这里只需要知道一个缓冲池会包含若干个缓冲器,两者都实现了并发安全的、队列式的数据传输功能,但前者是可伸缩的。
ModuleArgs 类型的参数是最重要的,它可以提供 3 种组件的实例列表,其结构如下:
//组件相关的撰数容器的类型
type ModuleArgs struct {
//下载器列表
Downloaders []module.Downloader
//分析器列表
Analyzers []module.Analyzer
//条目处理管道管道列表
Pipelines []module.Pipeline
}有了这些参数,网络爬虫程序就可以正常启动了。不过,拿到这些参数时,需要做的第一件事就必须是检查它们的有效性。为了让这类参数容器必须提供检查的方法,我编写了一个接口类型,并让上述 3 个类型都实现它:
//参数容器的接口类型
type Args interface {
// Check 用于自检参数的有效性。
//若结果值为nil,则说明未发现问题,否则就意味着自检未通过
Check() error
}对于 RequestArg 类型的值来说,若 AcceptedDomains 字段的值为 nil,就说明参数无效。对于 DataArgs 类型的值来说,任何字段的值都不能为 0。而对于 ModuleArgs 类型的值来说,3 种组件的实例都必须至少提供一个。
Scheduler 接口的实现实例需要通过上述这些参数正确设置自己的状态,并为启动做好准备。一旦初始化成功,就可以调用它的 Start 方法以启动调度器。Start 方法只接受一个参数——首次请求。一旦满足了这最后一个必要条件,调度器就可以按照既定流程运转起来了。
Scheduler 接口的 Stop 方法可以停止调度器的运行。调度器的启动和停止都可能失败。更具体地说,如果代表错误的方法的结果值不为 nil,就说明调用没有成功。对于启动来说,失败的原因可能是有无效的参数,也可能是调度器当时的状态不能启动。
对于停止来说,状态不对应该是唯一的失败原因。因为停止的方式是向调度器内部和各个组件异步发出停止信号,所以即使有什么问题,也不会反映在 Stop 方法的结果值上。
Scheduler 接口的 Status 方法用于获取调度器当时的状态。它的返回结果是 Status 类型的,该类型是一个 uint8 类型的别名类型。调度器的状态值会被限定在一个很有限的范围内。下面通过一系列常量来表示这一范围:
const (
//未初始化的状态
SCHED_STATUS_UNINITIALIZED Status = 0
//正在初始花的状态
SCHED_STATUS_INITIALIZING Status = 1
//已初始化焉状态
SCHED_STATUS_INITIALIZED Status = 2
//正在启动岛状态
SCHED_STATUS_STARTING Status = 3
//已启动的状态
SCHED_STATUS_STARTED Status = 4
//正在停止的状态
SCHED_STATUS_STOPPING Status = 5
//已停止的状态
SCHED_STATUS_STOPPED Status = 6
)调度器在状态转换方面需要有一套规则,具体如下。
- 当调度器处于正在初始化、正在启动或正在停止状态时,不能由外部触发状态的变化。也就是说,这时的调度器不能被初始化、启动或停止。
- 处于未初始化状态时,调度器不能被启动或停止。理所应当,没有必要的参数设置,调度器是无法运作的。
- 处于已启动状态时,调度器不能被初始化或启动。调度器是可以被再初始化的,但是必须在未启动的情况下才能这样做。另外,调用运行中的调度器的 Start 方法是不会成功的。
- 仅当调度器处于已启动状态时,才能被停止。换句话说,对不在运行中的调度器调用 Stop 方法肯定会失败。
纵观这些规则可以看出,调度器的初始化、启动和停止是需要按照次序进行的。只有已初始化的调度器才能被启动,只有已启动的调度器才能被停止。另一方面,允许重新初始化操作使得调度器可被复用。
调度器处于未初始化、已初始化或已停状态时,都可以重新初始化。下图展示了调度器的状态转换。
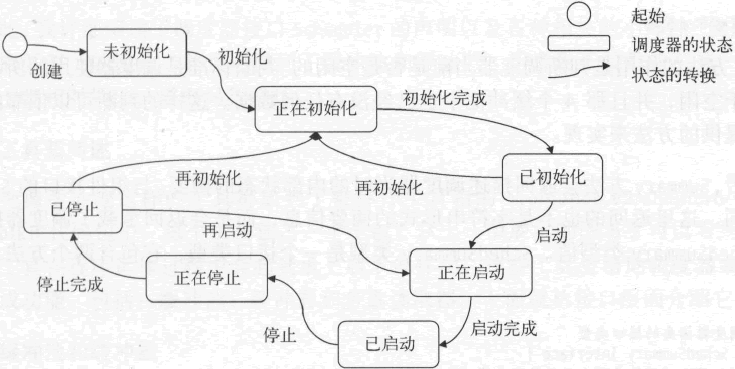
图:调度器的状态转换
Scheduler 接口中声明的最后 3 个方法 ErrorChan、Idle 和 Summary 都是用于获取调度器的运行状况的。调度器一旦启动,它的内部状态会随具体情况不断变化。对于调度器的使用方来说,只能也只应该通过这 3 个方法获取其运行状况。
ErrorChan 方法用于获得错误通道。注意,其结果类型是 <-chan error,一个只允许接收操作的单向通道类型。调度器会把运行期间发生的绝大部分错误都封装成错误值并放入这个错误通道。调度器的使用方在启动它之后立即调用 ErrorChan 方法并不断地尝试从其结果值中获取错误值,就像这样:
//省略部分代码
sched := NewScheduler()
err := sched.Init(requestArgs, dmtaArgs, moduleArgs)
if err != nil {
logger.Fatalf("An error occurs when initializing scheduler: %s", err)
}
err = sched.Start(firstHTTPReq)
if err != nil {
logger.Fatalf("An error occurs when starting scheduler: %s", err)
}
//观察错误
go func() {
errChan := sched.ErrorChan()
for {
err, ok := <-errChan
if !ok {
break
}
logger.Errorf("An error occurs when :running schedule: %s", err)
}
}()
//省略部分代码Idle 方法的作用是判断调度器当前是否是空闲的。判断标准是调度器使用的所有组件都正处于空闲,并且那 4 个缓冲池中也已经没有任何数据。这样的判断可以依靠组件和缓冲池提供的方法来实现。
最后,Summary 方法会返回描述调度器当时的内部状态的摘要。与组件接口的 Summary 方法相同,这里返回的也不是字符串形式的摘要信息,而是会返回承载了调度器摘要信息的 SchedSummary 类型值。SchedSummary 类型是一个接口类型,它包含两个方法,如下所示:
//调度器摘要的接口类型
type SchedSummary interface {
//用于获得摘要信息的结构化形式
Struet() SummaryStruct
//用于获得摘要信息的字符串形式
String() string
}该类型的值本身并不是摘要,但可以用两种方式输出摘要。结构化的摘要信息可供调度器的使用方再加工,而字符串形式的摘要信息可供直接打印。该接口中的 Struct 方法会返回 SummaryStruct 类型的值。它与组件接口 Module 的 Summary 方法的结果类型同名,但却不是同一个类型,也不在同一个代码包内。我们是这样声明这里的 SummaryStruct 类型的:
//表示调度器摘要的结构
type SummaryStruct struct {
RequestArgs RequestArgs 'json:"dequest_args"'
DataArgs DataArgs 'json:"data_args"'
ModuleArgs ModuleArgsSummary 'json:"module_args"'
Status string 'json:"status"'
Downloaders []module.SummaryStruct 'json:"downloaders"、
Analyzers []module.SummmiyStnict 'json:"analyzers"'
Pipelines []module.SummaryStruct 'json:"pipelines"'
ReqBufferPool BufferPoolSummaryStruct 'json:"request_buffer_pool"'
RespBufferPool BufferPoolSummaryStruet 'json:":response_buffer_pool"'
ItemBufferPool BufferPoolSummaryStruet 'json:"item_buffer_pool"'
ErrorBufferPool BufferPoolSummaryStruct 'json:"error_buffer_pool"'
NumURL uint64 'json:"url_number"'
}从其中字段的命名和类型上,你就可以猜出它们的含义。它们用于描述调度器接受的参数、调度器的状态,及其使用的各个组件和缓冲池的状态等。理想情况下,调度器的使用方定时收集这样的摘要,并在必要时予以展现。
顺便提一下,调用包级私有函数 newSchedSummary 可以创建一个 SchedSummary 类型值,只要你传给它必要的参数值。
至此,我详细阐述了调度器接口 Scheduler 的声明以及各种相关的小部件(包括参数、状态、摘要等)的设计,并且还提到了缓冲池和缓冲器。后者属于较重的工具,在设计和实现上都相对烦琐,需要另行描述。
工具箱简述
我们把像缓冲池这样的工具都放到了被称作工具箱的 src/gopcp.v2/chapter6/webcra-wler/toolkit 代码包中,每个工具独占一个子包。工具箱中的工具在程序运作过程中会起到承上启下的作用,这些工具会帮助调度器或组件更好地完成功能,包括:缓冲池、缓冲器和多重读取器。
缓冲池和缓冲器
缓冲池和缓冲器是一对程序实体。缓冲器是缓冲池的底层支持,缓冲池是缓冲器的再封装。缓冲池利用它持有的缓冲器实现数据存取的功能,并可以根据情况自动增减它持有的缓冲器的数量。下面先来看缓冲池的接口声明:
//数据缓冲池的接口类型
type Pool interface {
//用于获取池中缓冲器的统一容量
BufferCap() uint32
//用于获取池中缓冲器的最大数量
MaxBufferNumber() uint32
//用于获取池中缓冲器的数量
BufferNumber() uint32
//用于获取缓冲池中数据的总数
Total() uint64
// Put用于向缓冲池放入数据。
//注意!本方法是阻寒的。
//若缓冲池已关闭,则会直接返回非 nil 的错误值
Put(datum interface{}) error
// Get用于从缓冲池获取数据。
//注意!本方法是阻塞的。
//若缓冲池已关闭,则会直接返回非nil的错误值
Get() (datum interface{}, err error)
// Close用于关闭缓冲池。
//若缓冲池之前已关闭则返回false,否则返回true
Close() bool
//用于判断缓冲池是否已关闭
Closed() bool
}前面讲调度器的数据相关参数时,提到过缓冲池中单一缓冲器的容量和缓冲池包含的缓冲器的最大数量。Pool 接口中的 BufferCap 和 MaxBufferNumber 方法分别用于获得这两个数值。
实际上,调度器在拿到 DataArgs 类型的参数值并确认有效之后,就会用其中字段的值去初始化对应的缓冲池。缓冲池会在内部记录下这两个参数值,并在存取数据的时候使用它们。
BufferNumber 方法用于获取缓冲池实例在当下实际持有的缓冲器的数量,这个数量总会大于等于 1 且小于等于上述的缓冲器最大数量。
Total 方法用于获取缓冲池实例在当下实际持有的数据的总数,这个总数总会小于等于单一缓冲器容量和缓冲器最大数量的乘积。
Put 方法和 Get 方法需要实现缓冲池最核心的功能——数据的存入和读岀。对于这样的操作,在缓冲池关闭之后是不成功的。这时总是返回非 nil 的错误值。另外,这两个方法都是阻塞的。当缓冲池已满时,对 Put 方法的调用会产生阻塞。当缓冲池已空时,对 Get 方法的调用会产生阻塞。这遵从通道类型的行为模式。
最后,Close 方法会关闭当前的缓冲池实例。如果后者已关闭,就会返回 false,否则返回 true。Closed 方法用于判断当前的缓冲池实例是否已关闭。
如果缓冲池只持有固定数量的缓冲器,那么它的实现会变得非常简单,基本上只利用缓冲器的方法实现功能就可以了。不过这样的话,再封装一层就没什么意义了。缓冲池这一层的核心功能恰恰就是动态伸缩。
对于一个固定容量的缓冲来说,缓冲器可以完全胜任,用不着缓冲池。并且,缓冲器只需做到这种程度。这样可以足够简单。更高级的功能全部留给像缓冲池那样的高层类型去做。缓冲器的接口是这样的:
// FIFO的缓冲器的接口类型
type Buffer interface {
//用于获取本缓冲器的容量
Cap() uint32
//用于获取本缓冲器中数据的数量
Len() uint32
// Put用于向缓冲器放入数据。
//注意!本方法是非阻寒的。
//若缓冲器已关闭,则会直接返回非nil的错误值
Put(datum interface{}) (bool, error)
// Get用于从缓冲器获取器。
//注意!本方法是非阻塞的。
//若缓冲器已关闭,则会直接返回非nil的错误值
Get() (interface{}, error)
// Close用于关闭缓冲器。
//若缓冲器之前已关闭,则返回false,否则返回true
Close() bool
//用于判断缓冲器是否已关闭
Closed() bool
}Cap 方法和 Len 方法分别用于获取当前缓冲器实例的容量和长度。容量代表可以容纳的数据的最大数量,而长度则代表当前容纳的数据的实际数量。
注意,这里的 Put 和 Get 方法与缓冲池的对应方法在行为上有一点不同,即前者是非阻塞的。当缓冲器已满时,Put 方法的第一个结果值就会是 false。当缓冲器已空时,Get 方法的第一个结果值一定会是 nil。这样做也是为了让缓冲器的实现保持足够简单。
你可能会有一个疑问,缓冲器的功能看似用通道类型就可以满足,为什么还要再造一个类型出来呢?在讲通道类型的时候,强调过两个会引发运行时恐慌的操作:向一个已关闭的通道发送值和关闭一个已关闭的通道。
实际上,缓冲器接口及其实现就是为了解决这两个问题而存在的。在 Put 方法中,我会先检查当前缓冲器实例是否已关闭,并且保证只有在检查结果是否的时候才进行存入操作。在 Close 方法中,我仅会在当前缓冲器实例未关闭的情况下进行关闭操作。
另外,我们无法知道一个通道是否已关闭。这也是导致上述第二个引发运行时恐慌的情况发生的最关键的原因。有了 Closed 方法,我们就可以知道缓冲器的关闭状态,问题也就迎刃而解了。
缓冲池和缓冲器的诞生都是为了扩展通道类型的功能,其实我梦想中的通道类型就是这个样子。
多重读取器
如果你知道 io.Reader 接口并且使用过它的实现类型 (bytes.Reader、bufio.Reader 等) 的话,就肯定会知道通过这类读取器只能读取一遍它们持有的底层数据。当读完底层数据时,它们的 Read 方法总会把 io.EOF 变量的值作为错误值返回。
另外,如果你使用 net/http 包中的程序实体编写过 Web 程序的话,还应该知道 http.Response 类型的 Body 字段是 io.ReadCloser 接口类型的,而且该接口的类型声明中嵌入了 io.Reader 接口。
前者只是比后者多声明了一个名为 Close 的方法。相同的是,当 HTTP 响应从远程服务器返回并封装成 *http.Response 类型的值后,你只能通过它的 Body 字段的值读取 HTTP 响应体。
这种特性本身没有什么问题,但是在我对分析器的设计中,这样的读取器会造成一些小麻烦。还记得吗?一个分析器实例可以持有多个响应解析函数。由于 Body 字段值的上述特性,如果第一个函数通过它读取了 HTTP 响应体,那么之后的函数就再也读不到这个 HTTP 响应体了。响应解析函数一个很重要的职责就是分析 HTTP 响应体并从中筛选出可用的部分。所以,如此一来,后面的函数就无法实现主要的功能了。
你也许会想到,分析器可以先读出 HTTP 响应体并赋给一个 []byte 类型的变量,然后把它作为参数直接传给多个响应解析函数。这是可行的,但是我认为这样做会让代码变得丑陋,因为这个值在内容方面与 ParseResponse 函数类型的第一个参数有所重叠。更为关键的是,这会改变 ParseResponse 函数类型的声明,这并不值得。
我们的做法是,设计一个可以多次提供基于同一底层数据(可以是 []byte 类型的)的 io.ReadCloser 类型值的类型。我把这个类型命名为 MultipleReader,意为多重读取器,它的接口声明很简单:
//多重读取器的接口
type MultipleReader interface {
// Reader用于获取一个可关闭读取器的实例。
//后者会持有该多重读取器中的数据
Reader() io.ReadCloser
}在创建这个类型的值时,我们可以把 HTTP 响应的 Body 字段的值作为参数传入。作为产出,我们可以通过它的 Reader 方法多次获取基于同一个 HTTP 响应体的读取器。
这些读取器除了基于同一底层数据之外毫不相干。这样一来,我们就可以让多个响应解析函数中的分析筛选操作完全独立、互不影响了。
之所以让这个 Reader 方法返回 io.ReadCloser 类型的值,是因为我们要用这个值替换 HTTP 响应原有的 Body 字段值,这样做是为了让这一改进对响应解析函数透明。也就是说,不让响应解析函数感知到分析器中所作的改变。
多重读取器的接口相当简单(它的实现类型同样简单),但确实解决掉了一个痛点。
Go语言网络爬虫缓冲器工具的实现
缓冲器的基本结构如下:
//集冲器接口的实现类型
type myBuffer struet {
//存放数据的通道
ch chan interface{}
//缓冲器的关闭状态:0-未关闭;2-已关闭
closed uint32
//为了消除因关闭缓冲器而产生的竞态条件的读写锁
closingLock sync.RWMutex
}显然,缓冲器的实现就是对通道类型的简单封装,只不过增加了两个字段用于解决前面所说的那些问题。字段 closed 用于标识缓冲器的状态。缓冲器自创建之后只有两种状态:未关闭和已关闭。注意,我们需要用原子操作访问该字段的值。
closingLock 字段代表了读写锁。如果你在程序中并发地进行向通道发送值和关闭该通道的操作的话,会产生竞态条件。通过在使用 go 命令(比如 go test)时加入标记 -race,可以检测到这种竞态条件。后面你会看到使用读写锁消除它的正确方法。
NewBuffer 函数用于创建一个缓冲器:
// NewBuffer 用于创建一个缓.冲器。
// 参数size代表缓冲器的容量
func NewBuffer(size uint32) (Buffer, error) {
if size == 0 {
errMsg := fmt.Sprintf("illegal size for buffer: %d", size)
return nil, errors.NewIllegalParameterError(errMsg)
}
return &myBuffer{
ch: make(chan interFace{}, size),
}, nil
}它先检验参数值,然后构造一个 myBuffer 类型的值并返回。显然,在实现接口方法时,接收者的类型都是 myBuffer。
注意,errors.NewIllegalParameterError 用于生成一个代表参数错误的错误值,其中 errors 代表的并不是标准库中的 errors 包,而是代码包中的 gopcp.v2/chapter6/webcrawler/
errors 包。大家可以在我的网盘中下载相关代码包(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)。
Buffer 接口的 Cap 方法和 Len 方法实现起来都相当简单,只需把内建函数 cap 或 len 应用在字段 ch 上就好了。这里也无需使用额外的保证并发安全的措施。
对于 Put 方法,需要注意的是对读写锁的运用和对缓冲器状态的判断。在 Put 方法中,我们应该使用读锁。因为“向通道发送值”的操作会受到“关闭通道”操作的影响。如果不关闭通道,根本无需在进行发送操作时使用锁。另外,如果在进行发送操作前就已经发现通道关闭,就不应该再去尝试发送值了。下面来看 Put 方法的实现:
func (buf *myBuffer) Put(datum interface{}) (ok bool, err error) {
buf.closingLock.RLock()
defer buf.closingLock.RUnlock()
if buf.Closed() {
return false, ErrClosedBuffer
}
select {
case buf.ch <- datum:
ok = true
default:
ok = false
}
return
}在写锁的保护下关闭通道。对应地,在 Put 方法的起始处锁定读锁,然后再去做状态判断。如果反过来,那么通道就有可能在状态判断之后且锁定读锁之前关闭。这时,Put 方法会以为通道未关闭,然后在读锁的所谓保护下向通道发送值,引发运行时恐慌。
接下来的 select 语句主要是为了让 Put 方法永远不会阻塞在发送操作上。在 default 分支中把结果变量 ok 的值设置为 false,加之这时的结果变量 err 必为 nil,就可以告知调用方放入数据的操作未成功,且原因并不是缓冲器已关闭,而是缓冲器已满。
Get 方法的实现要简单一些。因为从通道接收值的操作可以丝毫不受到通道关闭的影响,所以无需加锁。其实现如下:
func (buf *myBuffer) Get() (interface{}, error) {
select {
case datum, ok := <-buf.ch:
if !ok {
return nil, ErrClosedBuffer
}
retum datum, nil
default:
return nil, nil
}
}这里同样使用 select 语句让它变成非阻塞的。顺便提一句,ErrClosedBuffer 是一个变量,表示缓冲器已关闭的错误,它的声明是这样的:
//表示缓冲器已关闭的错误
var ErrClosedBuffer = errors.New("closed buffer")这遵从了 Go语言程序中的惯用法。标准库中的类似变量有 io.EOF、bufio.ErrBufferFull 等。
再来说 Close 方法。在关闭通道之前,先要避免重复操作。因为重复关闭一个通道也会引发运行时恐慌。避免措施就是先检查 closed 字段的值。当然,必须使用原子操作。下面是它的实现:
func (buf *myBuffer) Close() bool {
if atomic.CompareAndSwapUint32(&buf.closed, 0, 1) {
buf.closingLock.Lock()
close(buf.ch)
buf.closingLock.Unlock()
return true
}
return false
}最后,在 Closed 方法中读取 closed 字段的值时,也一定要使用原子操作:
func (buf *myBuffer) Closed() bool {
if atomic.LoadUint32(&buf.closed) == 0 {
return false
}
return true
}千万不要假设读取共享资源就是并发安全的,除非资源本身做出了这种保证。
Go语言网络爬虫缓冲池工具的实现
缓冲池的基本结构如下:
//数据缓冲池接口的实现类型
type myPool struct {
//缓冲器的统一容量
bufferCap uint32
//缓冲器的最大数量
maxBufferNumber uint32
//缓冲器的实际数量
bufferNumber uint32
//池中数据的总数
total uint64
//存放缓冲器的通道
bufCh chan Buffer
//缓冲池的关闭状态:0-未关闭;1-已关闭
closed uint32
//保护内部共享资源的读写锁
rwlock sync.RWMutex
}前两个字段用于记录创建缓冲池时的参数,它们在缓冲池运行期间用到。bufferNumber 和 total 字段用于记录缓冲数据的实时状况。
注意,bufCh 字段的类型是 chan Buffer,一个元素类型为 Buffer 的通道类型。这与缓冲器中同样是通道类型的 ch 字段联合起来看,就是一个双层通道的设计。在放入或获取数据时,我会先从 bufCh 拿到一个缓冲器,再向该缓冲器放入数据或从该缓冲器获取数据,然后再把它发送回 bufCh。这样的设计有如下几点好处。
1) bufCh 中的每个缓冲器一次只会被一个 goroutine 中的程序(以下简称并发程序)拿到。并且,在放回 bufCh 之前,它对其他并发程序都是不可见的。一个缓冲器每次只会被并发程序放入或取走一个数据。即使同一个程序连续调用多次 Put 方法或 Get 方法,也会这样。缓冲器不至于一下被填满或取空。
2) 更进一步看,bufCh 是 FIFO 的。当把先前拿出的缓冲器归还给 bufCh 时,该缓冲器总会被放在队尾。也就是说,池中缓冲器的操作频率可以降到最低,这也有利于池中数据的均匀分布。
3) 在从 bufCh 拿到缓冲器后,我可以判断是否需要缩减缓冲器的数量。如果需要并且该缓冲器已空,就可以直接把它关掉,并且不还给 bufCh。另一方面,如果在放入数据时发现所有缓冲器都已满并且在一段时间内都没有空位,就可以新建一个缓冲器并放入 bufCh。总之,这让缓冲池自动伸缩功能的实现变得简单了。
4) 最后也最重要的是,bufCh 本身就提供了对并发安全的保障。
大家可能会想到,基于标准库的 container 包中的 List 或 Ring 类型也可以编写出并发安全的缓冲器队列。确实可以。不过,用它们来实现会让你不得不编写更多的代码,因为原本一些现成的操作和功能都需要我们自己去实现,尤其是在保证并发安全性方面。并且,这样的缓冲器队列的运行效率可不一定高。
注意,上述设计会导致缓冲池中的数据不是 FIFO 的。不过,对于网络爬虫框架以及调度器来说,这并不会造成问题。
再看最后一个字段 rwlock。之所以不叫它 closingLock,是因为它不仅仅为了消除缓冲器中的那个与关闭通道有关的竞态条件而存在。大家可以思考一下,怎样并发地向 bufCh 放入新的缓冲器,同时避免池中的缓冲器数量超过最大值。
NewPool 函数用于新建一个缓冲池。它会先检查参数的有效性,再创建并初始化一个 *myPool 类型的值并返回。在为它的 bufCh 字段赋值后,我们需要先向该值放入一个缓冲器。这算是对缓冲池的预热。关于该函数的具体实现,你可以直接查看示例项目中的对应代码。
对于 Pool 接口的 BufferCap> MaxBufferNumber> BufferNumber 和 Total 方法的实现,我也不多说了。myPool 类型中都有相对应的字段。不过需要注意的是,对 bufferNumber 和 total 字段的访问需要使用原子操作。
Put 方法有两个主要的功能。第一个功能显然是向缓冲池放入数据。第二个功能是,在发现所有的缓冲器都已满一段时间后,新建一个缓冲器并将其放入缓冲池。当然,如果当前缓冲池持有的缓冲器已达最大数量,就不能这么做了。
所以,这里我们首先需要建立一个发现和触发追加缓冲器操作的机制。我规定当对池中所有缓冲器的操作的失败次数都达到 5 次时,就追加一个缓冲器入池。其实这方面的控制可以做得很细,也可以新增参数并把问题抛给使用方。不过这里先用这个简易版本。如果你觉得这确实有必要,可以自己编写一个改进的版本。
以下是我编写的 Put 方法的实现:
func (pool *myPool) Put(datum interface{}) (err error) {
if pool.Closed() {
return ErrClosedBufferPool
}
var count uint32
maxCount := pool.BufferNumber() * 5
var ok bool
for buf := range pool.bufCh {
ok, err = pool.putData(buf, datum, &count, maxCount)
if ok || err != nil {
break
}
}
return
}实际上,放入操作的核心逻辑在 myPool 类型的 putData 方法中。Put 方法本身做的主要是不断地取岀池中的缓冲器,并持有一个统一的“已满”计数。请注意 count 和 maxCount 变量的初始值,并体会它们的关系。
下面来看 putData 方法,其声明如下:
//用于向给定的缓冲器放入数据,并在必要时把缓冲器归还给池
func (pool *myPool) putData(
buf Buffer, datum interface{}, count *uint32, maxCount uint32) (ok bool, err error) {
//省略部分代码
}由于这个方法比较长,所以会分段讲解。第一段,putData 为了及时响应缓冲池的关闭,需要在一开始就检查缓冲池的状态。并且在方法执行结束前还要检查一次,以便及时释放资源。代码如下所示:
if pool.Closed() {
return false, ErrClosedBufferPool
}
defer func() {
pool.rwlock.RLock()
if pool.Closed() {
atomic.AddUint32(&pool.bufferNumber, ^uint32(O))
err = ErrClosedBufferPool
} else {
pool.bufCh <- buf
}
pool.rwlock.RUnlock()
}()在 defer 语句中,我用到了 rwlock 的读锁,因为这其中包含了向 bufCh 发送值的操作。如果在方法即将执行结束时,发现缓冲池已关闭,那么就不会归还拿到的缓冲器,同时把对应的错误值赋给结果变量 err。注意,不归还缓冲器时,一定要递减 bufferNumber 字段的值。
第二段,执行向拿到的缓冲器放入数据的操作,并在必要时增加“已满”计数:
ok, err = buf.Put(datum)
if ok {
atomic.AddUint64(&pool.total, 1)
return
}
if err != nil {
return
}
//若因缓冲器已满而未放入数据,就递增计数
(*count)++请注意那两条 return 语句以及最后的 (*count)++。在试图向缓冲器放入数据后,我们需要立即判断操作结果。如果 ok 的值是 true,就说明放入成功,此时就可以在递增 total 字段的值后直接返回。
如果 err 的值不为 nil,就是说缓冲器已关闭,这时就不需要再执行后面的语句了。除了这两种情况,我们就需要递增 count 的值。因为这时说明缓冲器已满。如果你忘了 myBuffer 的 Put 方式是怎样实现的,可以现在回顾一下。
这里的 count 值递增操作与第三段代码息息相关,这涉及对追加缓冲器的操作的触发。下面是第三段代码:
//如果尝试向缓冲器放入数据的失败次数达到阈值,
//并且池中缓冲器的数量未达到最大值,
//那么就尝试创建一个新的缓冲器,先放入数据再把它放入池
if *count >= maxCount && pool.BufferNumber() < pool.MaxBufferNumber() {
pool.rwlock.Lock()
if pool.BufferNumber() < pool.MaxBufferNumber() {
if pool.Closed() {
pool.rwlock.Uniock()
return
}
newBuf, _ := NewBuffer(pool.bufferCap)
newBuf.Put(datum)
pool.bufCh <- newBuf
atomic.AddUint32(&pool.bufferNumber, 1)
atomic.AddUint64(&pool.total, 1)
ok = true
}
pool.rwlock.Uniock()
*count = 0
}
return在这段代码中,我用到了双检锁。如果第一次条件判断通过,就会立即再做一次条件判断。不过这之前,我会先锁定 rwlock 的写锁。这有两个作用:
第一:防止向已关闭的缓冲池追加缓冲器。
第二:防止缓冲器的数量超过最大值。在确保这两种情况不会发生后,把一个已放入那个数据的缓冲器追加到缓冲池中。
同样,及时更新计数也很重要。一旦第一次条件判断通过,即使最后没有追加缓冲器也应该清零 count 的值。及时清零“已满”计数可以有效减少不必要的操作和资源消耗。另外,一旦追加缓冲器成功,就一定要递增 bufferNumber 和 total 的值。
Get 方法的总体流程与 Put 方法基本一致:
func (pool *myPool) Get() (datum interfaced, err error) {
if pool.Closed() {
return nil, ErrClosedBufferPool
}
var count uint32
maxCount := pool.BufferNumber() * 10
for buf := range pool.bufCh {
datum, err = pool.getData(buf, &count, maxCount)
if datum != nil || ^rr != nil {
break
}
}
return
}把“已空”计数的上限 maxCount 设为缓冲器数量的 10 倍。也就是说,若在遍历所有缓冲器 10 次之后仍无法获取到数据,Get 方法就会从缓冲池中去掉一个空的缓冲器。getData 方法的声明如下:
//用于从给定的缓冲器获取数据,并在必要时把缓冲器归还给池
func (pool *myPool) getData(
buf Buffer, count *uint32, maxCount uint32) (datum interface!}, err error) {
//省略部分代码
}getData 方法的实现稍微简单一些,可分为两段。第一段代码的关键仍然是状态检查和资源释放:
if pool.Closed() {
return rdl, ErrClosedBufferPool
}
defer func() {
//如果尝试从缓冲器获取数据的失败次数达到阈值,
//同时当前缓冲器已空且池中缓冲器的数量大于1,
//那么就直接关掉当前缓冲器,并不归还给池
if *count >= maxCount &&
buf.Len() == 0 &&
pool.BufferNumber() > 1 {
buf.Close()
atomic.AddUint32(&pool.bufferNumber, ^uint32(0))
*count = 0
return
}
pool.rwlock.RLock()
if pool.Closed() {
atomic.AddUint32(Spool.bufferNumber, ^uint32(0))
err = ErrClosedBufferPool
} else {
pool.bufCh <- buf
}
pool.rwlock.RUnlock()
}()defer 语句中第一条 if 语句的作用是,当不归还当前缓冲器的所有条件都已满足时,我们就在关掉当前缓冲器和更新计数后直接返回。只有条件不满足时,才在确认缓冲池未关闭之后再把它归还给缓冲池。注意,这时候需要锁定 rwlock 的读锁,以避免向已关闭的 bufCh 发送值。
第二段代码的作用是试图从当前缓冲器获取数据。在成功取出数据时,必须递减 total 字段的值。同时,如果取出失败且没有发现错误,就会递增“已空”计数。相关代码如下:
datum, err = buf.Get()
if datum != nil {
atomic.AddUint64(&pool.total, ^uint64(0))
return
}
if err != nil {
return
}
//若因缓冲器已空未取出数据,就递增计数
(*count)++
returnputData 和 getData 方法中对 rwlock 的读锁或写锁的锁定就是为了预防关闭 bufCh 可能引发的运行时恐慌。显然,这些操作能够起作用的前提是 Close 方法对 rwlock 的合理使用,该方法的代码如下:
func (pool *myPool) Close() bool {
if !atomic.CompareAndSwapUint32(&pool.closed, 0, 1) {
return false
}
pool.rwlock.Lock()
defer pool.rwlock.Unlock()
close(pool.bufCh)
for buf := range pool.bufCh {
buf.Close()
}
return true
}以上就是对缓冲池实现主要部分的展示和说明。
Go语言网络爬虫多重读取器的实现
相比前面两节中介绍的缓冲器和缓冲池,多重读取器的实现就简单多了。首先是基本结构:
//多重读取器的实现类型
type myMultipleReader struct {
data []byte
}非常简单和直接,多重读取器只保存要读取的实际数据。NewMultipleReader 用于新建一个多重读取器的实例:
//用于新建并返回一个多重读取器的实例
func NewMultipleReader(reader io.Reader) (MultipleReader, error) {
var data []byte
var err error
if reader != nil {
data, err = ioutil.ReadAll(reader)
if err != nil {
return nil, fmt.Errorf("multipie reader: couldn't create a new one: %s", err)
}
} else {
data = []byte{}
}
return &myMultipleReader{
data: data,
}, nil
}标准库代码包 ioutil 中有一些非常实用的函数。这里用到的 ReadAll 函数的功能是,通过作为参数的读取器读取所有底层数据,并忽略 io.EOF 错误。
实际上,当碰到 io.EOF 错误时,该函数就会返回读到的所有数据,这正是 data 字段所代表的数据。另外,*myMultipleReader 应该作为 MultipleReader 接口的实现类型。对于后者声明的唯一方法,其实现极其简单:
func (rr *myMultipleReader) Reader() io.ReadCloser {
return ioutil.NopCloser(bytes.NewReader(rr.data))
}bytes.NewReader 函数的作用是根据参数生成并返回一个 *bytes.Reader 类型的值。
*bytes.Reader 类型是 io.Reader 接口的一个实现类型,不过我们这里需要的是 io.ReadCloser 接口类型的值。所以,需要使用 ioutil.NopCloser 函数对这个 *bytes.Reader 类型的值进行简单的包装。ioutil.NopCloser 函数会返回一个 io.ReadCloser 类型的值。
之前说过,io.ReadCloser 接口只比 io.Reader 多声明了一个 Close 方法,这个 Close 方法没有参数声明,但有一个 error 类型的结果声明。然而,ioutil.NopCloser 函数的结果值的 Close 方法永远只会返回 nil。也正因为如此,我们常常用这个函数包装无需关闭的读取器,这就是 NopCloser 的含义。
多重读取器的 Reader 方法总是返回一个新的可关闭读取器。因此,我可以利用它多次读取底层数据,并可以用该方法的结果值替代原先的 HTTP 响应的 Body 字段值很多次,这也是“多重”的真正含义。
Go语言网络爬虫内部基础接口
首先要做的是,先为组件通用功能定义一个内部接口,这里把它叫做组件的内部基础接口。内部基础接口及其实现类型存放在了代码包 gopcp.v2/chapter6/webcrawler/module/stub 中,代码包可以在我的网盘中下载(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)。
该接口内嵌了之前讲过的 Module 接口,其声明如下:
//组件的内部基础接口的类型
type ModuleInternal interface {
module.Module
//把调用计数增 1
IncrCalledCount()
//把接受计数增1
IncrAcceptedCount()
//把成功完成计数增 1
IncrCompletedCount()
//把实时处理数增 1
IncrHandlingNumber()
//把实时处理数减 1
DecrHandlingNumber()
//用于清空所有计数
Clear()
}Module 接口中声明的更多的是获取内部状态的方法,比如:获取组件 ID、组件地址、各种计数值,等等。而在 ModuleInternal 接口中,添加的方法都是改变内部状态的方法。
由于通常情况下外部不应该宜接改变组件的内部状态,所以该接口的名字才以 "Internal" 为后缀,以起到提示的作用。并且,在 gopcp.v2/chapter6/webcrawler/module 包中公开的程序实体并没有涉及该接口。
ModuleInternal 接口及其实现类型只是为了方便自行编写组件的人而准备的。在编写组件时也用到了它们。
ModuleInternal 接口是 Module 接口的扩展,前者的实现类型自然也是后者的实现类型。这个实现类型命名为 myModule,它的基本结构如下:
//组件内部基曲接口的实现类型
type myModule struct {
//组件ID
mid module.MID
//组件的网络地址
addr string
//组件评分
score uint64
//评分计算器
scoreCalculator module.CalculateScore
//调用计数
calledCount uint64
//接受计数
acceptedCount uint64
//成功完成计数
completedCount uint64
//实时处理数
handlingNumber uint64
}这些字段都是理所应当存在的,它们分别与 Module 接口(以及 ModuleInternal 口)中声明的方法有直接的对应关系。按照惯例, NewModuleInternal 用于新建一个 ModuleInternal 类型的实例,它的声明如下。
//创建一个组件内部基础类型的实例
func NewModuleInternal(
mid module.MID,
scoreCalculator module.CalculateScore) (ModuleInternal, error) {
parts, err := module.SplitMID(mid)
if err != nil {
return nil, errors.NewIllegalParameterError(
fmt.Sprintf("illegal ID %q: %s", mid, err))
}
return &myModule{
mid: mid,
addr: parts[2],
scoreCalculator: scoreCalculator
}, nil
}myModule 类型中的字段有几个是需要显式初始化的,包括:组件 ID、组件的网络地址(下面简称组件地址)和组件评分计算器。参数 mid 提供了组件 ID,同时也提供了组件地址。因为组件 ID 中可以包含组件地址。
如果组件地址为空,就说明该组件与网络爬虫程序同处在一个进程中。这时的 addr 字段自然就是 ""。module 包的 SplitMID 函数用于分离出组件 ID 的各个部分,并在组件 ID 不符合规范时报错,它是 module 包中众多工具类函数中的一个。
与之相对应,module 包中还有一个 GenMID 函数,用它可以生成组件 ID。调用 GenMID 函数时,需要给定一个序列号。大家可以通过调用 module 包中的 NewSNGenertor 函数创建出一个序列号生成器。强烈建议把序列号生成器的实例赋给一个全局变量。
组件评分计算器理应由外部提供,并且一般会为同一类组件实例设置同一种组件评分计算器,而且一旦设置就不允许更改。所以,即使是 ModuleInternal 接口也没有提供改变它的方法。
再强调一下,NewIllegalParameterError 是 gopcp.v2/chapter6/webcrawler/errors 包中的函数。该包中还有 NewCrawlerError 和 NewCrawlerErrorBy 函数,用于生成爬虫程序运作过程中抛出的错误值。
有了上述的那些字段,实现 ModuleInternal 接口的方法就相当简单了,唯一要注意的就是充分利用原子操作保证它们的并发安全。这里就不展示了。或许大家可以试着编写出来,然后对比看看。
Go语言网络爬虫组件注册器
在讲解下载器接口设计时,我们介绍过组件注册方面的设计和组件注册器接口 Registrar,它声明在 module 包中。根据前面的接口描述,我们会让组件注册器按照类型存储已注册的组件。该接口的声明如下:
//细件注册器的实现类型
type myRegistrar struct {
//组件类型与对应组件实例的映射
moduleTypeMap map[Type]map[MID]Module
//组件注册专用读写锁
rwlock sync.RWMutex
}在组件注册器的实现类型 myRegistrar 中只有两个字段,一个用于分类存储组件实例,另一个用于读写保护。由于注册和注销组件实例的动作肯定不会太频繁,所以这里简单地使用读写锁实施保护就足够了。
moduleTypeMap 表示一个双层的字典结构,其中第一层提供了分类型注册和获取组件实例集合的能力,而第二层则负责存储组件实例集合。
Registrar 接口的 Register 方法只需做两件事:检查参数和注册组件实例。在检查参数时,Register 方法用到了 module 包中的一些工具类方法和变量。该方法的实现如下:
func (registrar *myRegistrar) Register(module Module) (bool, error) {
if module == nil {
return false, errors.NewIllegalParameterError("nil module instance")
}
mid := module.ID()
parts, err := SplitMID(mid)
if err != nil {
return false, err
}
moduleType := legalLetterTypeMap[parts[0]]
if !CheckType(moduleType, module) {
errMsg := fmt.Sprintf("incorrect module type: %s", moduleType)
return false, errors.NewIllegalParameterError(errMsg)
}
//省略部分代码
}前面已经介绍过 NewIllegalParameterError 和 SplitMID 函数。legalLetterTypeMap 变量是一个以组件类型字母为键、以组件类型为元素的字典,是前面介绍的 legalTypeLetterMap 的反向映射。CheckType 函数的功能是检查从组件 ID 解析出来的组件类型与组件实例的实际类型是否相符。
如果所有检查都通过了,那么 Register 方法就会把组件实例存储在 moduleTypeMap 中。当然,肯定会在 rwlock 的保护之下操作 moduleTypeMap。
Unregister 方法会把与给定的组件 ID 对应的组件实例从 moduleTypeMap 删除掉。在真正进行查找和删除操作前,它会先通过调用 SplitMID 函数检查那个组件 ID 的合法性。
Get 方法的实现包含负载均衡的策略,并返回最“空闲”的那个组件实例:
// Get用于获取一个指定类型的组件的实例。
//本函数会基于负载均衡策略返回实例
func (registrar *myRegistrar) Get(moduleType Type) (Module, error) {
modules, err := registrar.GetAllByType(moduleType)
if err != nil {
return nil, err
}
minScore := uint64(0)
var selectedModule Module
for _, module := range modules {
SetScore(module)
if err != nil {
return nil, err
}
score := module.Score()
if minScore == 0 || score < minScore {
selectedModule = module
minScore = score
}
}
return selectedModule, nil
}该方法先调用注册器的 GetAllByType 方法以获得指定类型的组件实例的集合,然后在遍历它们时计算其评分,并找到评分最低者,最后返回。其中 SetScore 是一个工具类函数,它通过组件实例的 ScoreCalculator 方法获得它的评分计算器。若该方法返回 nil,则使用默认的计算函数。计算其评分后,再通过组件实例的 SetScore 方法设置评分。
为了让 *myRegistrar 类型成为 Registrar 接口的实现类型,还需要实现它的 GetAllByType、GetAll 和 Clear 方法。不过这几个方法的实现都非常简单,这里就不展示了。这里需要注意的是对 rwlock 字段的合理运用。
一旦把所有方法都编写好,下面这个函数就可以编译通过了:
//用于创建一个组件注册器的实例
func NewRegistrar() Registrar {
return &myRegistrar{
moduleTypeMap: map[Type]map[MID]Module{},
}
}Go语言网络爬虫下载器接口
与 ModuleInternal 接口一样,下载器接口 Downloader 也内嵌了 Module 接口,它额外声明了一个 Download 方法。有了 ModuleInternal 接口及其实现类型,实现下载器时只需关注它的特色功能,其他的都交给内嵌的 stub.ModuleInternal 就可以了。
下载器的实现类型名为 myDownloader,其声明如下:
//下载器的实现类型
type myDownloader struet {
//组件基础实例
stub.ModuleInternal
//下载用的HTTP客户端
httpClient http.Client
}可以看到,我匿名地嵌入了一个 stub.ModuleInternal 类型的字段,这种只有类型而没有名称的字段称为匿名字段。如此一来,myDownloader 类型的方法集合中就包含了 stub.ModuleInternal 类型的所有方法。因而,*myDownloader 类型已经实现了 Module 接口。
另一个 http.Client 类型的字段用于对目标服务器发送 HTTP 请求并接收响应。http.Client 类型是做 HTTP 客户端程序的必选,它开箱即用,同时又很开放,有很多可定制的地方。
myDownloader 类型的这两个字段的值都需要使用方直接或间接提供。关于第一个字段的值,可以很容易通过 stub.NewModuleInternal 函数生成。而第二个字段的值,可以直接通过复合字面量 http.Client{} 生成。
不过,我强烈建议你对它进行一些定制,如果你想让下载器跑得更快的话。后面讲网络爬虫程序示例的时候,我们会给出一些建议。
代码包 gopcp.v2/chapter6/webcrawler/module/local/downloader 中存放了所有与下载 器实现有关的代码,大家可以从我的网盘中下载相关代码包(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)。为了方便使用方创建下载器的实例,可以在其中编写了一个名为 New 的函数:
//用于创建一个下载器实例
func New(
mid module.MID,
client *http.Client,
scoreCalculator module.CalculateScore) (module.Downloader, error) {
moduleBase, err := stub.NewModuleInternal(mid, scoreCalculator)
if err != nil {
return nil, err
}
if client == nil {
return nil, genParameterError( "nil http client")
}
return &myDownloader{
ModuleInternal: moduleBase,
httpClient: *client,
}, nil
}上述代码中,stub.NewModuleInternal 函数需要组件 ID 和组件评分计算器来生成组件内部基础类型的值,那我就让 New 函数的参数声明列表包含它们。对这两个参数的校验 由 stub.NewModuleInternal 函数全权负责。
注意,这里还隐藏着一个 Go语言的命名惯例。由于下载器的实现代码独占一个代码包,所以可以让这个函数的名称足够简单,只有一个单词 New。这不同于前面提到的函数 NewPool 和 NewMultipleReader,这两个函数所创建的实例的含义无法由其所在代码包的名称 buffer 和 reader 表达。
另外,虽然函数 NewBuffer 所创建的实例的含义可以由其所在的代码包 buffer 表达,但是该包中用于创建实例的函数不止它一个。如果把它们的名称简化为 New,恐怕会造成表达上的不清晰。而 downloader 包中唯一用于创建实例的函数 New,可以让你马上明白它就是用于创建下载器实例的,并不需要过多解释。这就是命名方面的惯用法,也是一种技巧。
下面来看下载器的 Download 方法的实现:
func (downloader *myDownloader) Download(req *module.Request) (*module.Response, error) {
downloader.ModuleInternal.IncrHandlingNumber()
defer downloader.ModuleInternal.DecrHandlingNumber()
downloader.ModuleInternal.IncrCalledCount()
if req == nil {
return nil, genParameterError("nil request")
}
httpReq := req.HTTPReq()
if httpReq == nil {
return nil, genParameterError("nil HTTP request")
}
downloader.ModuleInternal.IncrAcceptedCount()
logger.Infof("Do the request (URL: %s, depth: %d)... \n", httpReq.URL, req.Depth()) httpResp, err := downloader.httpClient.Do(httpReq)
if err != nil {
return nil, err
}
downloader.ModuleInternal.IncrCompletedCount()
return module.NewResponse(httpResp, req.Depth()), nil
}这个方法的功能实现起来很简单,不过要注意对那 4 个组件计数的操作。在方法的开始处,要递增实时处理数,并利用 defer 语句保证方法执行结束时递减这个计数。同时, 还要递增调用计数。
在所有参数检查都通过后,要递增接受计数以表明该方法接受了这次调用。一旦目标服务器发回了 HTTP 响应并且未发生错误,就可以递增成功完成计数 To 这代表当前组件实例又有效地为使用者提供了一次服务。
Go语言网络爬虫分析器接口
分析器的接口包含两个额外的方法 RespParsers 和 Analyze,其中前者会返回当前分析器使用的 HTTP 响应解析函数(以下简称解析函数)的列表因此,分析器的实现类型有用于存储此列表的字段。另外,与下载器的实现类型相同,它也有一个 stub.ModuleInternal 类型的匿名字段。相关代码如下:
//分析器的实现类型
type myAnalyzer struct {
//组件基础实例
stub.ModuleInternal
//响应解析器列表
respParsers []module.ParseResponse
}该类型及其方法存放在 gopcp.v2/chapter6/webcrawler/module/local/analyzer 代码包 中。大家可以从我的网盘(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)中下载相关的代码包。当然,还有 New 函数:
//用于创建一个分析器实例
func New(
mid module.MID,
respParsers []module.ParseResponse,
scoreCalculator module.CalculateScore) (module.Analyzer, error) {
moduleBase, err := stub.NewModuleInternal(mid, scoreCalculator)
if err != nil {
return nil, err
}
if respParsers == nil {
return nil, genParameterError("nil response parsers")
}
if len(respParsers) == 0 {
return nil, genParameterError("empty response parser list")
}
var innerParsers []module.ParseResponse
for i, parser := range respParsers {
if parser == nil {
return nil, genParameterError(fmt.Sprintf("nil response parser[%d]", i))
}
innerParsers = append(innerParsers, parser)
}
return &myAnalyzer{
ModuleInternal: moduleBase,
respParsers: innerParsers,
}, nil
}该函数中的大部分代码都用于参数检查。对参数 respParsers 的检査要尤为仔细,因为它们一定是网络爬虫框架的使用方提供的,属于外来代码。
分析器的 Analyze 方法的功能是,先接收响应并检查,再把 HTTP 响应依次交给它持有的若干解析函数处理,最后汇总并返回从解析函数那里获得的数据列表和错误列表。
由于 Analyze 方法的实现比较长,这里分段讲解。先来看看检查响应的代码:
func (analyzer *myAnalyzer) Analyze(
resp *module.Response) (dataList []module.Data, errorList []error) {
analyzer.ModuleInternal.IncrHandlingNumber()
defer analyzer.ModuleInternal.DecrHandlingNumber()
analyzer.ModuleInternal.IncrCalledCount()
if resp == nil {
errorList = append(errorList,
genParameterError("nil response"))
return
}
httpResp := resp.HTTPResp()
if httpResp == nil {
errorList = append(errorList,
genParameterError("nil HTTP response"))
return
}
httpReq := httpResp.Request
if httpReq == nil {
errorList = append(errorList,
genParameterError("nil HTTP request"))
return
}
var reqURL = httpReq.URL
if reqURL == nil {
errorList = append(errorList,
genParameterError("nil HTTP request URL"))
return
}
analyzer.ModuleInternal.IncrAcceptedCount()
respDepth := resp.Depth()
logger.Infof("Parse the response (URL: %s, depth: %d)... \n",
reqURL, respDepth)
//省略部分代码
}这里的检查非常细,要像庖丁解牛一样检查参数值的内里。因为任何异常都有可能造成解析函数执行失败。我们一定不要给它们造成额外的困扰。一旦检查通过,就可以递增接受计数了。然后打印出一行日志,代表分析器已经开始解析某个响应了。
还记得前面讲的多重读取器吗?现在该用到它了:
func (analyzer *myAnalyzer) Analyze(
resp *module.Response) (dataList []module.Data, errorList []error) {
//省略部分代码
//解析HTTP响应
if httpResp.Body != nil {
defer httpResp.Body.Close()
}
multipleReader, err := reader.NewMultipleReader(httpResp.Body)
if err != nil {
errorList = append(errorList, genError(err.Error()))
return
}
dataList = []module.Data{}
for respParser := range analyzer.respParsers {
httpResp.Body = multipleReader.Reader()
pDataList, pErrorList := respParser(httpResp, respDepth)
if pDataList != nil {
for _, pData := range pDataList {
if pData == nil {
continue
}
dataList = appendDataList(dataList, pData, respDepth)
}
}
if pErrorList I- nil {
for _, pError := range pErrorList {
if pError == nil {
continue
}
errorList = append(errorList, pError)
}
}
}
if len(errorList) == 0 {
analyzer.ModuleInternal.IncrCompletedCount()
}
return dataList, errorList
}这里先依据 HTTP 响应的 Body 字段初始化一个多重读取器,然后在每次调用解析函数之前先从多重读取器那里获取一个新的读取器并对 HTTP 响应的 Body 字段重新赋值,这样就解决了 Body 字段值的底层数据只能读取一遍的问题。
每个解析函数都可以顺利读出 HTTP 响应体。在所有解析都完成之后,如果错误列表为空,就递增成功完成计数。最后,我会返回收集到的数据列表和错误列表。
由于我们把解析 HTTP 响应的任务都交给了解析函数,所以 Analyze 方法的实现还是比较简单的,代码逻辑也很清晰。
Go语言网络爬虫条目处理管道
条目处理管道的接口拥有额外的 ItemProcessors、Send、FailFast 和 SetFailFast 方法,因此其实现类型 myPipeline 的基本结构是这样的:
//条目处理管道的实现类型
type myPipeline struct {
//组件基础实例
stub.ModuleInternal
//条目处理器的列表
itemProcessors []module.ProcessItem
//处理是否需要快速失败
failFast bool
}代码包 gopcp.v2/chapter6/webcrawler/module/local/pipeline 是存放该类型的位置,其中 New 函数与 analyzer 包中的 New 函数在参数声明列表和参数检查方式方面都很类似,这里就省略不讲了。相关代码包的代码大家可以在网盘(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)中下载。
除此之外,分析器中有 HTTP 响应解析函数的列表,而条目处理管道中有条目处理函数(以下简称处理函数)的列表。因此,后者的 Send 方法与前者的 Analyze 方法在实现流程方面也大体一致。只不过由于条目处理管道存在对快速失败的设定,所以在流程细节上它们仍有不同。
另外,还要注意,条目处理管道需要让条目依次经过那几个处理函数的加工。也就是说,第一个处理函数的处理结果要作为第二个处理函数的参数,第二个处理函数的处理结果要作为第三个处理函数的参数,以此类推。这是由条目处理管道的设计决定的,也是“管道” 一词要表达的含义。
相比之下,分析器中的解析函数对 HTTP 响应的解析是相互独立的。下面是 Send 方法的代码片段,体现了上述不同:
func (pipeline *myPipeline) Send(item.module.Item) []error {
//省略部分代码
var errs []error
//省略部分代码
var currentItem = item
for _, processor := range pipeline.itemProcessors {
processedItem, err := processor(currentItem)
if err != nil {
errs = append(errs, err)
if pipeline.failFast {
break
}
}
if processedItem != nil {
currentltem = processedItem
}
}
//省略部分代码
return errs
}ItemProcessors、FailFast和SetFailFast方法的实现都非常简单,在此略过。
至此,我已经讲解了组件相关接口的绝大部分实现,同时阐述了一些我在 Go语言程序编写和软件设计方面的经验,也展示了一些编码技巧。
Go语言网络爬虫调度器的实现
调度器的主要职责是对各个处理模块进行调度,以使它们能够进行良好的协作并共同完成整个爬取流程。调度器相关的实现代码都在 gopcp.v2/chapter6/webcrawler/scheduler 包中。相关代码可以从网盘中下载(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)。
基本结构
依据调度器的职责及其接口声明,可以编写出调度器实现类型的基本结构,这个基本结构中的字段比较多,这里先把它们展示出来,然后再逐一说明:
//调度器的实现类型
type myScheduler struet {
//爬取的最大深度,首次请求的深度为0
maxDepth uint32
//可以接受的URL的主域名的字典
acceptedDomainMap cmap.ConcurrentMap
//组件注册器
registrar module.Registrar
//请求的缓冲池
reqBufferPool buffer.Pool
//响应的缓冲池
respBufferPool buffer.Pool
//条目的缓冲池
itemBufferPool buffer.Pool
//错误的缓冲池
errorBufferPool buffer.Pool
//已处理的URL的字典
urlMap cmap.ConcurrentMap
//上下文,用于感知调度器的停止
ctx context.Context
//取消函数,用于停止调度器
cancelFunc context.CancelFunc
//状态
status Status
//专用于状态的读写锁
statusLock sync.RWMutex
//摘要信息
summary SchedSummary
}下面简要介绍各个字段的含义。
字段 maxDepth 和 acceptedDomainMap 分别用于限定爬取目标的深度和广度。在分析器解析出新的请求后,我会用它们逐一过滤那些请求,不符合要求的请求会直接扔掉。这两个字段的值会从 RequestArgs 类型的参数值中提取。
registrar 字段代表组件注册器。如前文所述,其值可由 module 包的 NewRegistrar 函数直接生成。需要注册到该组件注册器的所有组件实例都由 ModuleArgs 类型的参数值提供。
字段 reqBufferPool、respBufferPool、itemBufferPool 和 errorBufferPool 分别代表针对请求、响应、条目和错误的缓冲池。前面讲调度器接口时介绍过 DataArgs 类型,也提到过这 4 个缓冲池。
初始化它们所需的参数自然要从一个 DataArgs 类型的参数值中得到。调度器使用这些缓冲池在各类组件实例之间传递数据。也正因为如此,调度器才能让数据真正流转起来,各个组件实例才能发挥岀应有的作用。
urlMap 字段的类型是 cmap.ConcurrentMap。还记得我们在第5章最后编写的那个并发安全字典吗?它的代码就在 gopcp.v2/chapter5/cmap 代码包中。由于 urlMap 字段存在的目的是防止对同一个 URL 的重复处理,并且必会并发地操作它,所以把它声明为 cmap.ConcurrentMap 类型再合适不过。在后面,你会看到调度器对它的简单使用。
ctx 字段和 cancelFunc 字段是一对。两者都是由同一个 context.Context 类型值生成出来的。cancelFunc 字段代表的取消函数用于让所有关注 ctx 并会调用其 Done 方法的代码都感知到调度器的停止。
status 字段是 Status 类型的。关于 Status 类型以及调度器状态的转换规则,前面讲调度器接口时已经详细说明过。而 statusLock 字段则代表专门为调度器状态的转换保驾护航的读写锁。
summary 字段是为存储调度器摘要而准备的。与调度器接口中的 Summary 方法的结果一样,它的类型是 SchedSummary,该类型的值可提供两种格式的摘要信息输岀。
虽然上述字段大都需要显式赋值,但是用于创建调度器实例的 NewScheduler 函数仍然非常简单:
//创建调度器实例
func NewScheduler() Scheduler {
return &myScheduler{}
}一切初始化调度器的工作都交给 Init 方法去做。
初始化
调度器接口中声明的第一个方法就是 Init 方法,它的功能是初始化当前调度器。
关于 Init 方法接受的那 3 个参数,前面已经提到多次。Init 方法会对它们进行检查。不过在这之前,它必须先检查调度器的当前状态,请看下面的代码片段:
func (sched *myScheduler) Init(
requestArgs RequestArgs,
dataArgs DataArgs,
moduleArgs ModuleArgs) (err error) {
//检查状态
logger.Info("Check status for initialization...")
var oldStatus Status
oldStatus, err = sched.checkAndSetStatus(SCHED_STATUS_INITIALIZING)
if err != nil {
return
}
defer func() {
sched.statusLock.Lock()
if err 1= nil {
sched.status = oldStatus
} else {
sched.status = SCHED_STATUS_INITIALIZED
}
sched.statusLock.Unlock()
}()
//省略部分代码
}这里有对状态的两次检查。第一次是在开始处,用于确认当前调度器的状态允许我们对它进行初始化,这次检查由调度器的 checkAndSetStatus 方法执行。该方法会在检查通过后按照我们的意愿设置调度器的状态(这里是“正在初始化”状态),它的声明如下:
//用于状态检查,并在条件满足时设置.状态
func (sched *myScheduler) checkAndSetStatus(
wantedStatus Status) (oldStatus Status, err error) {
sched.statusLock.Lock()
defer sched.statusLock.Unlock()
oldStatus = sched.status
err = checkStatus(oldStatus, wantedStatus, nil)
if err == nil {
sched.status = wantedStatus
}
return
}下面是其中调用的 checkStatus 方法声明的片段:
// checkStatus 用于状态检查。
// 参数 currentStatus 代表当前状态。
// 参数 wantedStatus 代表想要的状态。
// 检查规则:
// 1.处于正在初始化、正在启动或正在停止状态时,不能从外部改变状态。
// 2.想要的状态只能是正在初始化、正在启动或正在停止状态中的一个。
// 3.处于未初始化状态时,不能变为正在启动或正在停止状态。
// 4.处于已启动状态时,不能变为正在初始化或正在启动状态。
// 5.只要未处于已启动状态,就不能变为正在停止状态
func checkStatus(
currentStatus Status,
wantedStatus Status,
lock sync.Locker) (err error) {
//省略部分代码
}这个方法的注释详细描述了检查规则,这决定了调度器是否能够从当前状态转换到我们想要的状态。只要欲进行的转换违反了这些规则中的某一条,该方法就会直接返回一个可以说明状况的错误值,而 checkAndSetStatus 方法会检查 checkStatus 方法返回的这个错误值。只有当该值为 nil 时,它才会对调度器状态进行设置。
Init 方法对调度器状态的第二次检查是通过 defer 语句实施的。在该方法执行结束时,它会检查初始化是否成功完成。如果成功,就会把调度器状态设置为“已初始化”状态,否则就会让状态恢复原状。
实际上,在调度器实现类型的 Start 方法和 Stop 方法的开始处,也都有类似的代码,它们共同保证了调度器的动作与状态之间的协同。
如果当前状态允许初始化,那么 Init 方法就会开始做参数检查。这并不麻烦,因为那 3 个参数的类型本身都提供了检查自身的方法 Check。相关代码如下:
func (sched *myScheduler) Init(
requestArgs RequestArgs,
dataArgs DataArgs,
moduleArgs ModuleArgs) (err error) {
//省略部分代码
//检查参数
logger.Info("Check request arguments...")
if err = requestArgs.Check(); err != nil {
return err
}
logger.Info("Check data arguments...")
if err = dataArgs.Check(); err != nil {
return err
}
logger.Info("Data arguments are valid.")
logger.Info("Check module arguments...")
if err = moduleArgs.Check(); err != nil {
return err
}
logger.Info("Module arguments are valid.")
//省略部分代码
}在这之后,Init 方法就要初始化调度器内部的字段了。关于这些字段的初始化方法,之前都陆续讲过,这里就不再展示了。最后,我们来看一下用于组件实例注册的代码:
func (sched *myScheduler) Init(
requestArgs RequestArgs,
dataArgs DataArgs,
moduleArgs ModuleArgs) (err error) {
//省略部分代码
//注册组件
logger.Info("Register modules...")
if err = sched.registerModules(moduleArgs); err != nil {
return err
}
logger.Info("Scheduler has been initialized.")
return nil
}在 registerModules 方法中,利用已初始化的调度器的 registrar 字段注册使用方提供的所有组件实例,并在发现任何问题时直接返回错误值。Init 方法也是类似的,只要在初始化过程中发现问题,就忽略掉后面的步骤并把错误值返回给使用方。
综上所述,Init 方法做了 4 件事:检查调度器状态、检查参数、初始化内部字段以及注册组件实例。一旦这 4 件事都做完,调度器就为启动做好了准备。
启动
调度器接口中用于启动调度器的方法是 Start。它只接受一个参数,这个参数是 *http.Request 类型的,代表调度器在当次启动时需要处理的第一个基于 HTTP/HTTPS 协议的请求。
Start 方法首先要做的是防止启动过程中发生运行时恐慌。其次,它还需要检查调度器的状态和使用方提供的参数值,并把首次请求的主域名添加到可接受的主域名的字典。因此,它的第一个代码片段如下:
func (sched *myScheduler) Start(firstHTTPReq *http.Request) (err error) {
defer func() {
if p := recover(); p != nil {
errMsg := fmt.Sprintf("Fatal scheduler error: %sched", p)
logger.Fatal(errMsg)
err = genError(errMsg)
}
}()
logger.Info("Start scheduler...")
//检查状态
logger.Info("Check status for start...")
var oldStatus Status oldStatus, err =
sched.checkAndSetStatus(SCHED_STATUS_STARTING)
defer func() {
sched.statusLock.Lock()
if err != nil {
sched.status = oldStatus
} else {
sched.status = SCHED_STATUS_STARTED
}
sched.statusLock.Unlock()
}()
if err != nil {
return
}
//检查参数
logger.Info("Check first HTTP request...")
if firstHTTPReq == nil {
err = genParameterError("nil first HTTP request")
return
}
logger.Info("The first HTTP request is valid.")
//获得首次请求的主域名,并将其添加到可接受的主域名的字典
logger.Info("Get the primary domain...")
logger.Infof("-- Host: %s", firstHTTPReq.Host)
var primaryDomain string
primaryDomain, err = getPrimaryDomain(firstHTTPReq.Host)
if err != nil {
return
}
logger.Infof("-- Primary domain: %s", primaryDomain)
sched.acceptedDomainMap.Put(primaryDomain, struet{}{})
//省略部分代码
}大家可以把 Start 方法和 Init 方法中检查调度器状态的代码对照起来看,并想象这是一个状态机在运转。
把首次请求的主域名添加到可接受主域名字典的原因是,网络爬虫程序最起码会爬取首次请求指向的那个网站中的内容。如果不添加这个主域名,那么所有请求(包括首次请求)都不会被调度器受理。Start 方法至此已经做好了准备,可以真正启动调度器了:
func (sched *myScheduler) Start(firstHTTPReq *http.Request) (err error) {
//省略部分代码
//开始调度数据和组件
if err = sched.checkBufferPoolForStart(); err != nil {
return
}
sched.download()
sched.analyze()
sched.pick()
logger.Info("Scheduler has been started.")
//放入第一个请求
firstReq := module.NewRequest(firstHTTPReq, 0)
sched.sendReq(firstReq)
return nil
}把激活各类组件和各类缓冲池的代码分别封装到了调度器的 download、analyze 和 pick 方法中。依次调用这些方法后,通过 sendReq 方法把首次请求发给了请求缓冲池。一旦发送成功,调度器就会运转起来。这些激活的操作以及调度器的运转都是异步的。Start 方法在启动调度器之后,就会立即返回。
以上就是 Start 方法的总体执行流程,下面我们详细介绍几个重要的内部方法。
1) 处理请求
处理请求需要下载器和请求缓冲池,下面先从调度器的 download 方法看起:
//从请求缓冲池取出请求并下载,然后把得到的响应放入响应缓冲池
func (sched *myScheduler) download() {
go func() {
for {
if sched.canceled() {
break
}
datum, err := sched.reqBufferPool.Get()
if err != nil {
logger.Warnln("The request buffer pool was closed. Break request reception.")
break
}
req, ok := datum.(*module.Request)
if !ok {
errMsg := fmt.Sprintf("incorrect request type: %T", datum)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
}
sched.downloadOne(req)
}
}()
}在 download 方法中,新启用了一个 goroutine。在对应的 go 函数中,先通过对 canceled 方法的调用感知调度器的停止。只要发现调度器已停止,download 方法(更确切地说是其中的却函数)就会中止流程执行。canceled 方法的代码如下:
//用于判断调度器的上下文是否已取消
func (sched *myScheduler) canceled() bool {
select {
case <- sched.ctx.Done():
return true
default:
return false
}
}该方法感知调度器停止的手段实际上就是调用 ctx 字段的 Done 方法。回顾一下,这个方法会返回一个通道。一旦那个由 cancelFunc 字段代表的函数被调用,该通道就会关闭,试图从该通道接收值的操作就会立即结束。
回到 download 方法。在 for 语句的开始处,download 方法会从 reqBufferPool 获取一个请求。如果 reqBufferPool 已关闭,这时就会得到一个非 nil 的错误值,这说明在 download 方法获取请求时调度器关闭了。这同样会让流程中止。
在各方并发运行的情况下,这种情况是可能发生的,甚至发生概率还很高。注意,从 reqBufferPool 获取到的请求是 interface{} 类型的,必须先做一下数据类型转换。
万一它的数据类型不对,download 方法就会调用 sendError 函数向 errorBufferPool 字段代表的错误缓冲池发送一个说明此情况的错误值。虽然正常情况下不应该发生这种数据类型的错误,但还是顺便做一下容错处理比较好。
之所以有 sendError 这个方法,是因为在真正向错误缓冲池发送错误值之前还需要对错误值做进一步加工。请看该方法的声明:
//用于向错谋缓冲池发送错误值
func sendError(err error, mid module.MID, errorBufferPool buffer.Pool) bool {
if err == nil || errorBufferPool == nil || errorBufferPool.Closed() {
return false
}
var crawlerError errors.CrawlerError
var ok bool
crawlerError, ok = err.(errors.CrawlerError)
if !ok {
var moduleType module.Type
var errorType errors.ErrorType
ok, moduleType = module.GetType(mid)
if !ok {
errorType = errors.ERROR_TYPE_SCHEDULER
} else {
switch moduleType {
case module.TYPE_DOWNLOADER:
errorType = errors.ERROR_TYPE_DOWNLOADER
case module.TYPE_ANALYZER:
errorType = errors.ERROR_TYPE_ANALYZER
case module.TYPE_PIPELINE:
errorType = errors.ERROR_TYPE_PIPELINE
}
}
crawlerError = errors.NewCrawlerError(errorType, err.Error())
}
if errorBufferPool.Closed() {
return false
}
go func(crawlerError errors .CrawlerEiro]:) {
if err := errorBufferPool.Put(crawlerError); err != nil {
logger.Warnln("The error buffer pool was closed. Ignore error sending.")
}
}(crawlerError)
return true
}在确保参数无误的情况下,sendError 函数会先判断参数 err 的实际类型。如果它不是 errors.CrawlerError 类型的,就需要对它进行加工。sendError 函数依据参数 mid 判断它代表的组件的类型,并以此确定错误类型。
如果判断不出组件类型,就会认为这个错误是调度器抛出来的,并设定错误类型为 errors.ERROR_TYPE_SCHEDULER。从另一个角度讲,如果传给 sendError 函数的错误是由某个组件实例引起的,就把该组件实例的 ID 一同传给该方法,这样 sendError 函数就能正确包装这个错误,从而让它有更明确的错误信息。当然,如果这个错误是由调度器给出的,就只需像 download 方法那样把 "" 作为 sendError 函数的第二个参数值传入。
正确包装错误只是成功的一半。即使包装完成,错误缓冲池关闭了也是枉然。另外请注意 sendError 函数后面的那条 go 语句。依据我之前的设计,调度器的 ErrorChan 方法用于获得错误通道。
调度器的使用方应该在启动调度器之后立即调用 ErrorChan 方法并不断地尝试从其结果值中获取错误值。实际上,这里错误通道中的错误值就是从错误缓冲池那里获得的。那么问题来了,如果使用方不按照上述方式做,那么一旦发生大量错误,错误通道以及错误缓冲池就会很快填满,进而调用 sendError 函数的一方就会被阻塞。别忘了,缓冲池的 Put 方法是阻塞的。
所以,上面那条 go 语句的作用就是:即使调度器的使用方不按规矩办事,爬取流程也不会因此停滞。当然,这并不是说不按规矩办事没有代价,运行中 goroutine 的大量增加会让 Go 运行时系统的负担加重,网络爬虫程序的运行也会趋于缓慢。
再回到 download 方法。处理单个请求的代码都在 downloadOne 方法中,download 方法在 for 语句的最后调用了这个方法。downloadOne 方法的代码如下:
//根据给定的请求执行下载并把响应放入响应缓冲池
func (sched *myScheduler) downloadOne(req *module.Request) {
if req == nil {
return
}
if sched.canceled() {
return
}
m, err := sched.registrar.Get(module.TYPE_DOWNLOADER)
if err != nil || m == nil {
errMsg := fmt.Sprintf("couldn't get a downloader: %s", err)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
sched.sendReq(req)
return
}
downloader, ok := m.(module.Downloader)
if !ok {
errMsg := fmt.Sprintf("incorrect downloader type: %T (MID: %s)", m, m.ID())
sendError(errors.New(errMsg), m.ID(), sched.errorBufferPool)
sched.sendReq(req)
return
}
resp, err := downloader.Download(req)
if resp != nil {
sendResp(resp, sched.respBufferPool)
}
if err != nil {
sendError(err, m.ID(), sched.errorBufferPool)
}
}可以看到,该方法也会在一开始就去感知调度器的停止,这是这些内部方法必做的事情。downloadOne 方法会试图从调度器持有的组件注册器中获取一个下载器。如果获取失败,就没必要去做后面的事情了。如果获取成功,该方法就会去检查并转换下载器的类型,然后把请求作为参数传给下载器的 download 方法,最后获得结果并根据实际情况向响应缓冲池或错误缓冲池发送数据。
注意,一旦下载器获取失败或者下载器的类型不正确,downloadOne 方法就会把请求再放回请求缓冲池。这也是为了避免因局部错误而导致的请求遗失。
sendResp 函数在执行流程上与 sendError 函数很类似,甚至还要简单一些:
//用于向响应缓冲池发送响应
func sendResp(resp *module.Response, respBufferPool buffer.Pool) bool {
if resp == nil || respBufferPool == nil || respBufferPool.Closed() {
return false
}
go func(resp *module.Response) {
if err := respBufferPool.Put(resp); err != nil {
logger.Warnln("The response buffer pool was closed. Ignore response sending.")
}
}(resp)
return true
}它会在确认参数无误后,启用一个 goroutine 并把响应放入响应缓冲池。
调度器的 download 方法只负责不断地获得请求,而 downloadOne 方法则负责获得一个下载器,并让它处理某个请求。这两个方法的分工还是比较明确的。稍后会讲的处理响应和处理条目的流程其实都与之类似。
在编写程序的时候,我们可以让实现类似功能的代码呈现近似甚至一致的总体流程和基本结构。注意,这与编写重复的代码是两码事,而是说在更高的层面上让代码更有规律。如此一来,阅读代码的成本就会低很多,别人可以更容易地理解你的意图和程序逻辑。在编写网络爬虫框架的时候,一直在有意识地这么做。
2) 处理响应
处理响应需要分析器和响应缓冲池,具体的代码在 analyze 和 analyzeOne 方法中。analyze 方法看起来与 download 方法很相似,只不过它处理的是响应,使用的是响应缓冲池,调用的是 analyzeOne 方法。相关代码如下:
//用于从响应集冲池取出响应并解析,热后把将■到的条目或请求放入相应的缓冲池
func (sched *myScheduler) analyze() {
go func() {
for {
if sched.canceled() {
break
}
datum, err := sched.respBufferPool.Get()
if err != nil {
logger.Warnln("The response buffer pool was closed. Break response reception.")
break
}
resp, ok := datum.(*module.Response)
if !ok {
errMsg := fmt.Sprintf("incorrect response type: %T", datum)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
}
sched.analyzeOne(resp)
}
}()
}与 downloadOne 方法相比,analyzeOne 方法除了操纵的对象不同,还要多做一些事情:
//根据给定的响应执行解析并把结果放入相应的缓冲池
func (sched *myScheduler) analyzeOne(resp *module.Response) {
if resp == nil {
return
}
if sched.canceled() {
return
}
m, err := sched.registrar.Get(module.TYPE_ANALYZER)
if err != nil || m == nil {
errMsg := fmt.Sprintf("couldn't get an analyzer: %s", err)
sendError(errors.New(errMsg), "", sched.errorBufferPool)
sendResp(resp, sched.respBufferPool)
return
}
analyzer, ok := m.(module.Analyzer)
if !ok {
errMsg := fmt.Sprintf("incorrect analyzer type: %T (MID: %s)",
m, m.ID())
sendError(errors.New(errMsg), m.ID(), sched.errorBufferPool)
sendResp(resp,sched.respBufferPool)
return
}
dataList, errs := analyzer.Analyze(resp)
if dataList != nil {
for _, data := range dataList {
if data == nil {
continue
}
switch d := data.(type) {
case *module.Request:
sched.sendReq(d)
case module.Item:
sendItem(d, sched.itemBufferPool)
default:
errMsg := fmt.Sprintf("Unsupported data type %T! (data: %#v)", d, d)
sendError(errors.New(errMsg), m.ID(), sched.errorBufferPool)
}
}
}
if errs != nil {
for _, err := range errs {
sendError(err, m.ID(), sched.errorBufferPool)
}
}
}分析器的 Analyze 方法在处理某个响应之后会返回两个结果值:数据列表和错误列表。其中,数据列表中的每个元素既可能是新请求也可能是新条目。analyzeOne 方法需要 对它们进行类型判断,以便把它们放到对应的数据缓冲池中。对于错误列表,analyzeOne 方法也要进行遍历并逐一处理其中的错误值。
3) 处理条目
处理条目需使用条目处理管道,同时也要用到条目缓冲池。调度器的 pick 和 pickOne 方法承载了相关的代码。pick 方法同样与 download 方法很相似,pickOne 方法的实现比 downloadOne 方法还要稍微简单一些,因为条目处理管道的 Send 方法在对条目进行处理之后只返回错误列表。
4) 数据、组件和缓冲池
纵观调度器对它持有的数据、组件和缓冲池的调动方式,我们可以画出一张更加详细的数据流程图,如下所示。

图:更详细的数据流程图
从上图中可以看到,各类数据在各个组件和缓冲池之间的流转方式,以及调度器的一些重要方法在其中起到的作用。
5) 发送请求
前面多次展现过调度器的方法 sendReq,该方法的功能是向请求缓冲池发送请求。与之前讲过的 sendError 函数和 sendResp 函数不同,它会对请求实施很严格的检查和过滤。一旦发现请求不满足某个条件,就立即返回 false。其实现代码如下:
// sendReq会向请求缓冲池发送请求。
//不符合要求的请求会被过滤掉
func (sched *myScheduler) sendReq(req *module.Request) bool {
if req == nil {
return false
}
if sched.canceled() {
return false
}
httpReq := req.HTTPReq()
if httpReq == nil {
logger.Warnln("Ignore the request! Its HTTP request is invalid!")
return false
}
reqURL := httpReq.URL
if reqURL == nil {
logger.Warnln("Ignore the request! Its URL is invalid!")
return false
}
scheme := strings.ToLower(reqURL.Scheme)
if scheme != "http" && scheme != "https" {
logger.Warnf("Ignore the request! Its URL scheme is %q, but should be %q or %q. (URL: %s)\n", scheme, "http", "https", reqURL)
return false
}
if v := sched.urlMap.Get(reqURL.String()); v != nil {
logger.Warnf("Ignore the request! Its URL is repeated. (URL: %s)\n", reqURL)
return false
}
pd, _ := getPrimaryDomain(httpReq.Host)
if sched.acceptedDomainMap.Get(pd) == nil {
if pd == "bing.net" {
panic(httpReq.URL)
}
logger.Warnf("Ignore the request! Its host %q is not in accepted primary domain map.(URL: %s)\n", httpReq.Host, reqURL)
return false
}
if req.Depth() > sched.maxDepth {
logger.Warnf("Ignore the request! Its depth %d is greater than %d.(URL: %s)\n", req.Depth(), sched.maxDepth, reqURL)
return false
}
go func(req *module.Request) {
if err := sched.reqBufferPool.Put(req); err != nil {
logger.Warnln("The request buffer pool was closed. Ignore request sending.")
}
}(req)
sched.urlMap.Put(reqURL.String(), struct{}{})
return true
}诸如请求是否为 nil、请求中代表 HTTP 请求的字段值是否为 nil、HTTP 请求中代表 URL 的字段值是否为 nil 都是最基本的检查。
大家应该已经知道,本章描述的网络爬虫框架是基于 HTTP/HTTPS 协议的,它只能从网络中获取可通过 HTTP/HTTPS 协议访问的内容。因此,检查请求 URL 的 scheme 是必需的。否则,即使把不符合该条件的请求放入缓冲池,也肯定得不到正确的处理,白白浪费了资源。
另一个节省资源的措施是,绝不处理重复的请求。重复的请求是靠调度器的 urlMap 字段值来过滤的。urlMap 字段代表一个已处理 URL 的字典。一旦某个请求通过了所有检查,sendReq 函数就会在把它放入请求缓冲池的同时,把它的 URL 放入这个字典,这就为后续的重复 URL 的检查提供了依据。只要 URL 重复,就可以说它代表的请求是重复的。
最后两项检查是关于请求广度和深度的,讲解调度器接口和调度器实现类型的基本结构时,我们介绍过怎样通过 RequestArgs 类型的参数从这两个维度对有效请求的范围进行限定。这需要用到调度器的 acceptedDomainMap 和 maxDepth 字段。请求的 URL 的主域名不在 acceptedDomainMap 中的肯定会被过滤掉,深度达到或超过 maxDepth 字段值的请求也是如此。
通过上述一系列的检查,我们就判定一个请求是否是可处理的有效请求。当然,请求是否能被下载器转化为响应、响应是否能被分析器解析出有效的条目,还要看后续的处理过程。sendReq 函数是数据在流转过程中要经历的第一道关卡。
停止
停止调度器是 Stop 方法的功能。更具体地说,它做了 3 件事:检查调度器状态、发出调度器停止信号和释放资源。检查调度器状态的方式我在讲调度器初始化的时候详细阐述过。发出调度器停止信号的时候,需要用到调度器的 cancelFunc 字段。一旦该字段代表的函数被调用,调度器中的各个部分就会感知到并停止运行。
纵观调度器实现类型中的所有字段,那 4 个缓冲池算是比较重量级的了,主要是因为它们都包装了若干个通道。在停止调度器时,我们应该及时关闭它们。关闭方式很简单,调用它们的 Close 方法即可。另外,我们没有必要再去重置其他字段的值。调度器重新启动的时候,还会用到它们。
其他方法
除了前文所述的 Init、Start 和 Stop 方法外,调度器接口级别的方法还有 Status、ErrorChan、Idle 和 Summary。后者全是用于获取调度器运行状况的方法,其中最值得一提的就是 ErrorChan 方法。
已知,代表错误缓冲池的 errorBufferPool 字段用于暂存调度器运行过程中发生的错误。虽然我们可以直接从错误缓冲池那里获取错误值,但是 ErrorChan 方法的结果类型却是 <-chan error。
这么做的原因是,我无法对外部使用错误缓冲池的方式进行限制。任何得到错误缓冲池的人都可以随意调用其接口级别的方法,尤其是 Put 方法。而通道就不同了,只要结果类型是 <-chan error,调用 ErrorChan 方法的一方就只能接收值而不能发送值,这可以从根本上消除一个可能影响调度器运行的隐患。
下面我们来看看 ErrorChan 方法是怎样进行从错误缓冲池到错误通道的转换的:
func (sched *myScheduler) ErrorChan() <-chan error {
errBuffer := sched.errorBufferPool
errCh := make(chan error, errBuffer.BufferCap())
go func(errBuffer buffer.Pool, errCh chan error) {
for {
if sched.canceled() {
close(errCh)
break
}
datum, err := errBuffer.Get()
if err != nil {
logger.Warnln("The error buffer pool was closed. Break error reception.")
close(errCh)
break
}
err, ok := datum.(error)
if !ok {
errMsg := fmt.Sprintf("incorrect error type: %T", datum) sendError(errors.New(errMsg), "", sched.errorBufferPool)
continue
}
if sched.canceled() {
close(errCh)
break
}
errCh <- err
}
}(errBuffer, errCh)
return errCh
}该方法在创建了一个错误通道后,就立即专门启用一个 goroutine 去做错误值的搬运工作。然后,直接返回新创建的错误通道。除非发现调度器已关闭,这个 go 函数会一直尝试从错误缓冲池获得错误值,并在检查通过后把它发送给错误通道。一旦发现调度器已关闭,该函数就会立即关闭错误通道。这为 ErrorChan 方法的调用方感知调度器的关闭提供了支持。
注意,与调度器中专用于向缓冲池放入数据的方法一样,这里的 go 函数也不会直接使用任何外部值,所有的外部值均通过参数传入,这主要是为了防止外部值失效。
最后,再简单说一下 Idle 方法。之前讲调度器接口时已经说过判断调度器空闲的条件。判断所有组件实例是否已空闲的方法是,通过调度器持有的组件注册器的 GetAll 方法拿到所有已注册的组件实例,然后逐一调用它们的 HandlingNumber 方法。只要该方法的结果值大于 0,就说明调度器不是空闲的。
另外,还需要检查除错误缓冲池之外的所有缓冲池中的数据总数,只要有缓冲池存有数据,也说明调度器没有空闲。为什么不检查错误缓冲池?不要指望调度器的使用方会像你预期的那样调用 ErrorChan 方法并及时取走错误值。不过别担心,即使关闭了调度器,使用方照样可以从 ErrorChan 方法的结果值那里取走所有已存在的错误值。
总结
调度器实现类型 myScheduler 及其方法,合理运用它持有的缓冲池在各个组件实例之间搬运数据,同时有效地操控所有已注册的组件实例及时地转换数据,最后得到使用方想要的结果。使用方通过提供自定义的条目处理函数生成最终结果,并通过提供自定义的 HTTP 响应解析函数生成新的请求和条目。
当然,使用方也可以提供完全自定义的下载器、分析器和条目处理管道。但是,不论怎样,调度器实现类型都会采取快速失败的策略去检查所有参数,并在运行过程中保证不会因这些自定义组件和函数的异常行为造 成调度器崩溃。
从自身角度讲,调度器程序的运行效率主要取决于各种缓冲池的容量和各类组件实例的处理速度。所以,在初始化调度器时,总应该仔细斟酌传入的那些参数。当然,对 goroutine 的适当使用也让调度器程序在拥有多核 CPU 的计算机中可以展示出更高的效能。同时,这也使调度器程序的功能实现了完全的异步化。
另外,调度器程序自身是并发安全的。为了提供并发安全性,我们直接或间接地用到了通道 (channel),读写锁 (sync.RWMutex)、原子操作 (sync/atomic)、上下文 (context.Context) 以及并发安全字典 (gopcp.v2/chapter5/cmap.ConcurrentMap) 等。不过,这也要得益于并发安全的各类组件的默认实现。在实现自己的组件类型时,一定要注意它们的并发安全性。
以调度器为核心的网络爬虫框架是为了方便我们编写网络爬虫程序而存在的,它本身只提供基础层面的各种支持,而没有实现高层次的功能。后者与你关注的爬取目标、制定的爬取策略以及想要的爬取结果息息相关。
示例:爬取图片小程序
在本节中,我们的主要任务是使用网络爬虫框架编写一个可以下载目标网站中链接图片的爬虫程序。在这个过程中,我们会发现网络爬虫框架的一些不足,并继续为之添砖加瓦。这是一种反哺。在软件开发的过程中,总是应该尽早地为程序编写使用示例(测试程序也可以视为使用示例,而且能达到一举多得的效果),并以此来检查和验证我们的程序。
概述
现在互联网中有不少便捷工具可以自动下载(或者说爬取)小说网站的小说、图片网站的图片或视频网站的视频,这些工具有的以命令方式提供,有的有自己的图形用户界面。下面就带领大家编写一个这样的简单工具,以起到抛砖引玉的作用。
把这个可以爬取图片的小程序命名为 finder,并把它的代码放置在示例项目的 gopcp.v2/chapter6/webcrawler/examples/finder 代码包及其子包中。它以命令的方式为使用者提供功能。大家可以从我的网盘中下载该代码包(链接:https://pan.baidu.com/s/1yzWHnK1t2jLDIcTPFMLPCA 提取码:slm5)。
命令参数
命令参数是指使用者在使用 finder 命令时可以提供的参数。在 Go语言中,这类参数称为 flag。通过 Go 标准库中的 flag 代码包,可以读取和解析这类参数。
finder 可以自动完成很多事情。但是,使用者还需要告知它一些必备的参数,包括:首次请求的 URL、目标 URL 的范围限定(广度和深度),以及爬取来的图片文件存放的目录。这些必备参数的给定就需要通过 flag 来实现。
为了让 finder 成为一个开箱即用的命令,这里为每一个命令参数都提供了默认值。请看下面的代码:
//命令参数
var (
firstURL string
domains string
depth uint
dirPath string
),
func init() {
flag.StringVar(&firstURL, "first", "http://zhihu.sogou.com/zhihu?query=golang+logo",
"The first URL which you want to access.")
flag.StringVar(&domains, "domains", "zhihu.com",
"The primary domains which you accepted. "+
"Please using comma-separated multiple domains.")
flag.UintVar(&depth, "depth", 3,
"The depth for crawling.")
flag.StringVar(&dirPath, "dir", "./pictures",
"The path which you want to save the image files.")
}
func Usage() {
fmt.Fprintf(os.Stderr, "Usage of %s:\n", os.Args[0])
fmt.Fprintf(os.Stderr, "\tfinder [flags] \n")
fmt.Fprintf(os.Stderr, "Flags:\n")
flag.PrintDefaults()
}这些代码以及实现主流程的代码都包含在 finder 的主文件 finder.go 中。
flag 包为了让我们方便地定义命令参数,提供了很多函数,诸如上面的代码调用的函数 flag.StringVar 和 flag.UintVar。针对不同基本类型的参数值,flag 几乎都有一个函数与之相对应。以对 flag.StringVar 函数的第一次调用为例,调用参数的值依次是存放首次请求 URL 的变量 firstURL 的指针、命令参数的名称 first、first 的默认值以及 first 的文字说明。
这里声明一下,命令参数 first 的默认值并不要针对某些网站,而只是我发现的一个比较容易访问的 URL。该默认 URL 所属的网站不需要登录,而且在其链接的页面的源码中也比较容易找到图片。也许它并不是你所知道的最适合的首次请求 URL,但这仅仅是个默认值而已。
我们需要在 main 函数的开始处调用 flag.Parse 函数。只有这样,才能让 firstURL 等变量与 finder 使用者给定的命令参数值绑定。另外,为了让 finder 命令更加友好,需要把上面的 Usage 函数赋给 flag.Usage 变量,以便使用者在敲入 finder --help 和回车之后能看到命令使用提示信息。这个提示信息会包含上面那个 init 函数中声明的内容。
初始化调度器
我们通过操控调度器来使用网络爬虫框架提供的各种功能。在初始化调度器之前,我们需要先准备好 3 类参数:请求相关参数、数据相关参数和组件相关参数。其中,请求相关参数可以由命令参数直接给定,数据相关参数也可以由我们评估后给出。至于组件相关参数,我们会利用网络爬虫框架提供的各类组件的默认实现去创建。
很显然,分析器处理数据的速度肯定是最快的。其次是条目处理管道和下载器。分析器只会利用 CPU 和内存资源做一些计算,条目处理管道会把图片文件存储到计算机的文件系统中,而下载器则需要通过网络访问和下载内容。
虽然网络 I/O 的速度可能会超过磁盘 I/O 的速度,但是条目处理管道需要处理的数据总是最少的,所以我们可以把条目缓冲池的容量设置得更小。
为了简单直观,我们暂时认为,分析器处理数据的总耗时是条目处理管道的 10%,同时是下载器的 1%。注意,这只是一个粗略估计的结果。可以在使用 finder 的时候根据实际情况进行调整。至此,我们可以像下面这样组装一个 DataArgs 类型的值,其中的标识符 sched 代表代码包 gopcp.v2/chapter6/webcrawler/scheduler:
dataArgs := sched.DataArgs{
ReqBufferCap: 50,
ReqMaxBufferNumber: 1000,
RespBufferCap: 50,
RespMaxBufferNumber: 10,
ItemBufferCap: 50,
ItemMaxBufferNumber: 100,
ErrorBufferCap: 50,
ErrorMaxBufferNumber: 1,
}或许可以依据这些调度器参数为 finder 添加一些命令参数,以便让该程序更加灵活。
相比之下,组件相关参数的创建是最烦琐的。为了给出下载器、分析器和条目处理管道的实例列表,我们需要分别自定义 HTTP 客户端、HTTP 响应解析函数和条目处理函数。这部分代码在 gopcp.v2/chapter6/webcrawler/examples/finder/internal 代码包中,并在 finder 的主程序中为该包起个别名——lib。
之前说过,net/http 包中的 Client 类型是做 HTTP 客户端程序的必选,并且有很多可定制的地方。它有一个公开的字段 Transport,是 http.RoundTripper 接口类型的,用于实施对单个 HTTP 请求的处理并输出 HTTP 响应。我们可以不对它进行设置,而让程序自动使用由变量 http.DefaultTransport 代表的默认值。实际上,你可以从 http.Default-Transport 的声明中看到自定义 Transport 字段的方法。
下面是为生成 HTTP 客户端而声明的函数:
//用于生成HTTP客户端
fund genHTTPClient() *http.Client {
return &http.Client{
Transport: &http.Transport{
Proxy: http.ProxyFromEnvironment,
DialContext: (&net・Dialer{
Timeout: 30 * time.Second,
KeepAlive: 30 * time.Second,
DualStack: true,
}).DialContext,
MaxIdleConns: 100,
MaxIdleConnsPerHost: 5,
IdleConnTimeout: 60 * time.Second,
TLSHandshakeTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
},
}
}http.Transport 结构体类型实现了 http.RoundTripper 接口,其中也有很多公开的字段供我们设置。我想在这里解释的是 MaxIdleConns、MaxIdleConnsPerHost 和 IdleConnTimeout,它们与我们要爬取的目标网站以及对目标 URL 的范围限定有很大关系。MaxIdleConns 是对空闲链接的最大数量进行设置。空闲的链接可以理解为已经没有数据在传输但是还未断开的链接。
MaxIdleConns 限制的是通过该 HTTP 客户端访问的所有域名和 IP 地址的空闲链接总量。而 MaxIdleConnsPerHost 就不同了,它限制的是针对某一个域名或 IP 地址的空闲链接最大数量。
对于这两个字段的值,一般需要联动地设置。当然,可能无法预知目标网站的二、三级域名有多少个,以及在爬取过程中会以怎样的频率访问到哪些域名。这显然也需要一个调优的过程。
IdleConnTimeout 字段的含义是指定空闲链接的生存时间。如果说 MaxIdleConns 和 MaxIdleConnsPerHost 设置的是什么情况下应该关闭更多的空闲链接的话,那么 IdleConnTimeout 设置的就是什么时候应该进一步减少现有的空闲链接。
HTTP 响应解析函数用于解析 HTTP 响应并试图找到出新的请求和条目。在 finder 中,我们需要两个这样的函数,一个用于查找新请求,另一个用于查找新条目,这里所说的条目即图片。
为了解析 HTML 格式的 HTTP 响应体,我们需要引入一个第三方代码包:github.com/PuerkitoBio/goquery,后面将其简称为 goquery。
类似地,声明了一个 genResponseParsers 函数用于返回 HTTP 响应解析函数的列表:
//用于生成响应解析器
func genResponseParsers() [[module.PaiseResponse {
parseLink := func(httpResp *http.Response, respDepth uint32) ([]module.Data, []error) {
//省略部分代码
}
parselmg := func(httpResp *http.Response, respDepth uint32) ([[module.Data, []error) {
//省略部分代码
//生成条目
item := make(map[string]interface{})
item["reader"] = httpRespBody
item["name"] = path.Base(reqURL.Path)
item["ext"] = pictureFomat
dataList = append(dataList, module.Item(item))
return dataList, nil
}
return []module.ParseResponse{parseLink, parselmg}
}可以看到, genResponseParsers 函数返回的列表中有两个 HTTP 响应解析函数 parseLink 和 parseImg。parseLink 函数会利用 goquery 在 HTML 格式的 HTTP 响应体中查找新的请求。具体流程如下。
1) 检查响应。检查响应本身以及后面会用到的各个部分的有效性。如果无效,就忽略后面的步骤,并直接返回空的数据列表和包含相应错误值的错误列表。
2) 检查 HTTP 响应头中的内容类型。检查 HTTP 响应的 Header 部分中的 Content-Type 的值。如果它不以 text/html 开头,就忽略后面的步骤,并直接返回空的数据列表和 nil。
3) 解析 HTTP 响应体。在响应体中查找 a 标签,并提取它的 href 属性的值。如果该值是一个 URL,就将其封装成请求并追加到数据列表。再在响应体中查找 img 标签,并提取它的 src 属性的值。如果该值是一个 URL,就将其封装成请求并追加到数据列表。如果在解析过程中发生错误,就把错误值追加到错误列表,最后返回数据列表和错误列表。
parseImg 函数也会先检查响应和 HTTP 响应头中的内容类型。不过,它只会继续处理内容类型以 image 开头的 HTTP 响应。一旦可以继续处理,就说明 HTTP 响应体的内容是一个图片的字节序列,这时就可以生成条目了。
如前面的代码所示,在创建一个条目(实际上是一个字典)之后,会分别依据 HTTP 响应体、图片主文件名以及图片扩展名生成键 - 元素对并放入条目值。然后,把该条目追加到数据列表并返回。
相应地,在条目处理函数中,会根据条目中的这 3 个键 - 元素对在指定的目录中创建一个图片文件。用于生成条目处理函数的 genltemProcessors 函数的声明如下:
//用于生成条目处理器
func genItemProcessors(dirPath string) []module.ProcessItem {
savePicture := func(item module.Item) (resuIt module.Item, err error) {
//省略部分代码
//生成新的条目
result = make(map[string]interface{})
for k, v := range item {
result[k] = v
}
result["file_path"] = filePath
fileInfo, err := file・Stat()
if err != nil {
return nil, err
}
result["file_size"] = fileInfo.Size()
return result, nil
}
recordPicture := func(item module.Item) (result module.Item, err error) {
//省略部分代码
}
return []module.ProcessItem{savePicture, recordPicture}
}该函数返回的列表中有两个条目处理函数 savePicture 和 recordPicture。savePicture 函数用于保存图片文件。值得一提的是,在成功保存文件之后,savePicture 函数会生成新的条目。该条目中除了包含 savePicture 接受的那个参数条目中的所有键 - 元素对外,还放入了用于说明图片文件绝对路径的尺寸的键 - 元素对。这样,recordPicture 函数就可以把已存图片文件的信息完整地记录在日志中了。
有了 genHTTPClient,genResponseParsers 和 genItemProcessors 这 3 个函数,我们就可以着手准备各类组件实例的列表了。首先,来看看下载器列表的生成。
要创建一个下载器,光有 HTTP 客户端是不够的,还需要设置它的组件 ID 和组件评分计算器。不过,对于其余两个参数,gopcp.v2/chapter6/webcrawler/module 代码包已经给予了支持。
组件 ID 的生成需要组件类型、序列号和组件网络地址,这里的组件 ID 不需要包含网络地址,因为我们要生成的组件实例与调度器处于同一进程内。为了统一生成序列号,这里声明了一个包级私有的全局变量:
//组件序列号生成器
var snGen = module.NewSNGenertor(l, 0)至于下载器的组件类型,我们可以直接用 module.TYPE_DOWNLOADERo
在 module 包中有一个极其简单的组件评分计算函数 CalculateScoreSimple,这个函数原本是提供给测试函数使用的。不过对于 finder,我们可以直接使用这个函数,其代码如下:
//简易的组件评分计算函数
func CalculateScoreSimple(counts Counts) uint64 {
return counts.CalledCount +
counts.AcceptedCount<<1 +
counts.CompletedCount<<2 +
counts.HandlingNumber<<4
}有了上述准备,我们可以编写一个用于生成下载器列表的函数。把这个函数命名为 GetDownloaders,并把它存在 gopcp.v2/chapter6/webcrawler/examples/finder/internal 中。注意,与前面描述的那些 internal 包的函数不同,它是公开的。该函数的代码如下:
//用于获取下载器列表
func GetDownloaders(number uint8) ([]module.Downloader, error) {
downloaders := []module.Downloader{}
if number == 0 {
return downloaders, nil
}
for i := uint8(0); i < number; i++ {
mid, err := module.GenMID(
module.TYPE_DOWNLOADER, snGen.Get(), nil)
if err != nil{
return downloaders, err
}
d, err := downloader.New(
mid, genHTTPClient(), module.CalculateScoreSimple)
if err != nil {
return downloaders, err
}
downloaders = append(downloaders, d)
}
return downloaders, nil
}该函数的功能其实就是根据参数值生成一定数量的下载器并返回给调用方,其中的标识符 downloader 代表 gopcp.v2/chapter6/webcrawler/module/local/downloader 代码包。
用于生成并返回分析器列表的 GetAnalyzers 函数在流程上与 GetDownloaders 极其相似。在生成分析器的时候,它用到了 gopcp.v2/chapter6/webcrawler/module/local/analyzer 包的 New 函数和本包的 genResponseParsers 函数。
GetPipelines 函数的写法也是类似的。不过要注意,由于我们前面编写的条目处理函数需要把图片存到指定目录中,所以 GetPipelines 函数的参数除了 number 外,还有一个 string 类型的 dirPath。dirPath 指定图片存放目录。在调用 genItemProcessors 函数时,GetPipelines 函数会把 dirPath 直接传入。
另一个需要注意的地方是,我们在生成一个条目处理管道后,还要决定它是否是快速失败的。在这里,如果 savePicture 函数没能成功存储图片,那么我们就没必要再让 recordPicture 函数去记录日志了。因此,我们要通过调用条目处理管道的 SetFailFast 函数把它设置为快速失败的。
好了,我们现在已经准备好了初始化调度器所需的所有参数。至此,对于 finder.go 中的 main 函数,我们已经可以完成大半了:
func main() {
flag.Usage = Usage
flag.Parse()
//创建调度器
scheduler := sched.NewScheduler()
//准备调度器的初始化参数
domainParts := strings.Split(domains,",")
acceptedDomains := []string{}
for _, domain := range domainParts {
domain = strings.TrimSpace(domain)
if domain != "" {
acceptedDomains = append(acceptedDomains, domain)
}
}
requestArgs := sched.RequestArgs{
AcceptedDomains: acceptedDomains,
MaxDepth: uint32(depth),
}
dataArgs := sched.DataArgs{
ReqBufferCap: 50,
ReqMaxBufferNumber: 1000,
RespBufferCap: 50,
RespMaxBufferNumber:10,
ItemBufferCap: 50,
ItemMaxBufferNumber:100,
ErrorBufferCap: 50,
ErrorMaxBufferNumber:1,
}
downloaders, err := lib.GetDownloaders(1)
if err != nil {
logger.Fatalf("An error occurs when creating downloaders: %s", err)
}
analyzers, err := lib.GetAnalyzers(1)
if err != nil {
logger.Fatalf("An error occurs when creating analyzers: %s", err)
}
pipelines, err := lib.GetPipelines(1, dirPath)
if err != nil {
logger.Fatalf("An error occurs when creating pipelines: %s", err)
}
moduleArgs := sched.ModuleArgs{
Downloaders: downloaders,
Analyzers: analyzers,
Pipelines: pipelines,
}
//初始化调度器
err = scheduler.init(
requestArgs,
dataArgs,
moduleArgs)
if err != nil {
logger.Fatalf("An error occurs when initializing scheduler: %s", err)
}
//省略部分代码
}重申一下,其中的标识符 lib 代表 gopcp.v2/chapter6/webcrawler/examples/finder/ internal 代码包。另外注意,logger.Fatalf 总会在打印日志之后使当前进程非正常终止。所以,一旦调度器初始化失败,finder 就不会再做任何事了。
监控调度器
现在,我们已经可以启动调度器了。不过,或许我们可以准备得更充分一些。任何持续运行的软件服务都应该被监控,不论用什么方式监控。这几乎已经是互联网公司的一条铁律了。虽然 finder 只是一个可以查找并保存图片的工具,但是由于它可能会为了搜遍目标网站而运行很长一段时间,所以我们还是应该提供一种监控方法。
我会把用于监控调度器的代码封装在一个名为 Monitor 的函数里,并把它置于代码包 gopcp.v2/chapter6/webcrawler/examples/finder/monitor 中。
Monitor 函数的功能主要有如下 3 个。
- 在适当的时候停止自身和调度器。
- 实时监控调度器及其中的各个模块的运行状况。
- 一旦调度器及其模块在运行过程中发生错误,及时予以报告。
和其他部分一样,这些功能可以定制。
1) 确定参数
对于第一个功能,我们需要明确一点:只有在调度器空闲一段时间之后,才关闭它。所以,我们应该定时循环地去调用调度器的 Idle 方法,以检查它是否空闲。如果连续若干次的检查结果均为 true,那么就可以断定再没有新的数据需要处理了。
这时,关闭调度器就是安全的。这里有两个可以灵活掌握的环节:一个是检查的间隔时间,另一个是 检查结果连续为 true 的次数。只要给定了这两个可变量,自动关闭调度器的策略就完全 确定了。我们把检查的间隔时间与检査结果连续为 true 的最大次数的乘积称为最长持续 空闲时间,即:
最长持续空闲时间 = 检查间隔时间 x 检查结果连续为 true 的最大次数
一旦调度器空闲的时间达到了最长持续空闲时间,就可以关闭调度器了,不过这个决定应该由监控函数的使用方来做。
监控函数的第二个功能是对调度器的运行状况进行监控。我们在前面编写调度器以及相关模块的时候都留有摘要或统计接口,所以它实现起来并不难。这里也存在两个可变量:摘要获取间隔时间和摘要记录的方式。该函数的第三个功能也需要用到第二个可变量。
经过上述分析,我们已经可以确定调度器监控函数的签名了:
// Monitor用于监控调度器。
//参数 scheduler 代表作为监控目标的调度器。
//参数 checkInterval 代表检查间隔时间,单位:纳秒。
//泰数 summarizeInterval 代表摘要获取间隔时间,单位:纳秒。
//参数 maxIdleCount 代表最大空闲计数。
//参数 autoStop 用来指示该方法是否在调度器空闲足够长的时间之后自行停止调度器。
//参数 record 代表日志记录函数。
//当监控结束之后,该方法会向作为唯一结果值的通道发送一个代表空闲状态检查次数的数值
func Monitor(
scheduler sched.Scheduler,
checkInterval time.Duration,
summarizeInterval time.Duration,
maxIdleCount uint,
autoStop bool,
record Record) <-chan uint64在 Monitor 函数的参数声明列表中,record 就是使用方需要定制的摘要的记录方式。Record 类型的声明如下:
// Record 代表日志记录函数的类型。
//参数 level 代表日志级别。级别设定:0-普通;1-警告;2-错误
type Record func(level uint8, content string)这个函数类型表达的含义是根据指定的日志级别对内容进行记录。
另一方面,Monitor 函数会返回一个接收通道。在它执行结束之时,它还会向该通道发送一个数值,这个数值表示它检査调度器空闲状态的实际次数。使用方可以通过这个实际次数计算出当次爬取流程的总执行时间。不过,这个通道更重要的作用是作为使用方安全关闭调度器的依据。
2) 制定监控流程
大家可能会发现,Monitor 函数的 3 个功能之间实际上并没有交集。因此,我们可以在实现该函数的时候保持这 3 个功能的独立性,以避免它们彼此干扰。Monitor 函数的完整声明是这样的:
func Monitor(
scheduler sched.Scheduler,
checkInterval time.Duration,
summarizeInterval time.Duration,
maxIdleCount uint,
autoStop bool,
record Record) <-chan uint64 {
//防止调度器不可用
if scheduler == nil {
panic(errors.New("The scheduler is invalid!"))
}
//防止过小的检查间隔时间对爬取流程造成不良影响
if checkinterval < time.Millisecond*100 {
checkinterval = time.Millisecond * 100
}
//防止过小的摘要获取间隔时间对爬取流程造成不良影响
if summarizeInterval < time.Second {
summarizeInterval = time.Second
}
//防止过小的最大空闲计数造成调度器的过早停止
if maxIdleCount < 10 {
maxIdleCount = 10
}
logger.Infof("Monitor parameters: checkInterval: %s, summarizeInterval: %s,"+
"maxIdleCount: %d, autoStop: %v",
checkInterval, summarizeInterval, maxIdleCount, autoStop)
//生成监控停止通知器
stopNotifier, stopFunc := context.WithCancel(context.Background())
//接收和报告错误
reportError(scheduler, record, stopNotifier)
//记录摘要信息
recordsummary(scheduler, summarizeInterval, record, stopNotifier)
//检查计数通道
checkCountChan := make(chan uint64, 2)
//检查空闲状态
checkStatus(scheduler,
checkInterval,
maxIdleCount,
autoStop,
checkCountChan,
record,
stopFunc)
return checkCountChan
}这里简要解释一下它体现的监控流程。首先,监控函数必须对传入函数的参数值进行检査,其中最重要的是代表调度器实例的 scheduler。如果它为 nil,那么这个监控流程就完全没有执行的必要了。监控函数在发现此情况时,会把它视为一个致命的错误并引发一个运行时恐慌。
此外,监控函数还需要对检查间隔时间、摘要获取间隔时间和最大空闲计数的值进行检查。这些值既不能是负数,也不能是过小的正数,因为过小的正数会影响到爬取流程的正常执行。所以,在这里分别为它们设定了最小值。
让实现那 3 个功能的代码并发执行。与调度器的实现类似,需要让这些代码知道什么时候需要停止。同样,这里使用一个可取消的 context.Context 类型值来传递停止信号,并由 stopNotifier 变量代表。同时,stopFunc 变量代表触发停止信号的函数。
函数 reportError、recordSummary 和 checkStatus 分别表示 Monitor 函数需要实现的那 3 个功能,它们都会启用一个 goroutine 来执行其中的代码。稍后会分别描述它们的实现细节。
对于 Monitor 函数的函数体,最后要说明的是变量 checkCountChan,它代表的就是用来传递检查调度器空闲状态的实际次数的通道。它的值会被传入 checkStatus 函数,然后 由 Monitor 函数返回给它的调用方。
3) 报告错误
报告错误的功能由 reportError 函数负责实现。一旦调度器启动,就应该通过调用它的 ErrorChan 方法获取错误通道,并不断地尝试从中接收错误值。我们已经在前面详述过这样做的原因。
函数 reportError 接受 3 个参数。除了代表调度器的 scheduler 之外,还有代表日志记录方式的 record,以及代表监控停止通知器的 stopNotifier。下面是它的完整声明:
//用于接收和报告错误
func reportError(
scheduler sched.Scheduler,
record Record,
stopNotifier context.Context) {
go func() {
//等待调度器开启
waitForSchedulerStart(scheduler)
errorChan := scheduler.ErrorChan()
for {
//查看监控停止通知器
select {
case <- stopNotifier.Done():
return
default:
}
err, ok := <- errorChan
if ok {
errMsg := fmt.Sprintf("Received an error from error channel: %s", err)
record(2, errMsg)
}
time.Sleep(time.Microsecond)
}
}()
}这个函数启用了一个 goroutine 来执行其中的代码。在 go 函数中,它首先调用了 waitForSchedulerStart 函数。我们都知道,调度器有一个公开的方法 Status,该方法会返回一个可以表示调度器当前状态的值。因此,该函数要做的就是不断调用调度器的 Status 方法,直到该方法的结果值等于 sched.SCHED_STATUS_STARTED 为止。
当然,在对 Status 方法的多次调用之间,都需要有一个小小的停顿,这个停顿是通过 time.Sleep 函数实现的。这样做是为了避免因 for 循环迭代得太过频繁而可能带来的一些问题,比如挤掉其他 goroutine 运行的机会、致使 CPU 的使用率过高,等等。这是一种保护措施,虽然那些问题不一定会发生。
go 函数中的第 2 条语句,是调用调度器的 ErrorChan 方法并获取到错误通道。还记得 ErrorChan 方法是怎样实现的吗?它在每次调用时,都会创建一个错误通道,并持续从当前调度器持有的错误缓冲池向这个错误通道搬运错误值,直到错误缓冲池被关闭。正因为如此,我们不应该在 for 语句中调用它。
在 for 语句每次迭代开始,go 函数都会尝试用 select 语句从 stopNotifier 获取停止信号。一旦获取到停止信号,它就马上返回以结束当前流程的执行。select 语句中的 default case 意味着这个获取操作只是尝试一下而已。即使没获取到停止信号,select 语句的执行也会立即结束。
之后,go 函数就会试图从错误通道那里接收错误值。一旦接收到一个有效的错误值, 它就调用 record 函数记录下这个错误值。注意,与尝试获取停止信号的方式不同,这里的接收操作是阻塞式的。
在每次迭代的最后,go 函数也会通过调用 time.Sleep 函数实现一个小停顿。
4) 记录摘要信息
recordSummary 函数负责记录摘要信息,它的签名如下:
//用于记录摘要信息
func recordSummary(
scheduler sched.Scheduler,
summarizeInterval time.Duration,
record Record,
stopNotifier context.Context)可以看到,它接受 4 个参数,其中的 3 个参数也是 reportError 函数所接受的。多出的那个参数是 summarizeInterval,即摘要获取间隔时间。
这个函数同样启用了一个 goroutine 来进行相关操作。与 reportError 函数相同,在一开始依然要先调用 waitForSchedulerStart 函数,以等待调度器完全启动。一旦调度器已启动,go 函数就要开始为摘要信息的获取、比对、组装和记录做准备了。这里需要先声明如下几个变量:
var prevSchedSummaryStruct sched.SummaryStruct
var prevNumGoroutine int
var recordCount uint64 = 1
startTime := time.Now()其中,变量 recordCount 和 startTime 的值会参与到最终的摘要信息的组装过程中去。前者代表了记录的次数,而后者则代表开始准备记录时的时间。在它们前面声明的两个变量 prevSchedSummaryStruct 和 prevNumGoroutine 的含义分别是前一次获得的调度器摘要信息和 goroutine 数量,它们是是否需要真正记录当次摘要信息的决定因素。
go 函数每次都会把当前获取到的摘要信息与前一次的做比对。只有确定它们不同,才会对当前的摘要信息予以记录,这主要是为了减少摘要信息对其他日志的干扰。
go 函数应该在停下来之前定时且循环地获取和比对摘要信息。因此,我把后面的代码都放到了一个 for 代码块中。在每次迭代开始时,仍然需要通过 stopNotifier 检查停止信号。如果停止信号还没有发出,那么就开始着手获取摘要信息的各个部分,即:goroutine 数量和调度器摘要信息。goroutine 数量代表的是当前的 Go 运行时系统中活跃的 goroutine 的数量,而调度器摘要信息则体现了调度器当前的状态。获取它们的方式如下:
//获取 goroutine 数量和调度器摘要信息
currNumGoroutine := runtime.NumGoroutine()
currSchedSummaryStruct := scheduler.Summary().Struct()一旦得到它们,就分别把它们与变量 prevNumGoroutine 和 prevSchedSummaryStruct 的值进行比较。这里的比较操作很简单。变量 currNumGoroutine 及 prevNumGoroutine 都是 int 类型的,可以直接比较,而调度器摘要信息的类型 sched.SummaryStruct 也提供了可判断相同性的 Same 方法。如果它们两两相同,就不再进行后面的组装和记录操作了。否则,就开始组装摘要信息:
//比对前后两份摘要信息的一致性,只有不一致时才会记录
if currNumGoroutine != prevNumGoroutine ||
!currSchedSummaryStruct.Same(prevSchedSummaryStruct) {
//记录摘要信息
summay := summary{
NumGoroutine: runtime.NumGoroutine(),
SchedSummary: currSchedSummaryStruct,
EscapedTime: time.Since(startTime).String(),
}
b, err := json.MarshalIndent(summay,""," ")
if err != nil {
logger.Errorf("Occur error when generate scheduler summary: %s\n", err)
continue
}
msg := fmt.Sprintf("Monitor summary[%d]:\n%s", recordCount, b)
record(0, msg)
prevNumGoroutine = currNumGoroutine
prevSchedSummaryStruct = currSchedSummaryStruct
recordCount++
}组装摘要信息用到了当前包中声明的结构体类型 summary,其定义如下:
//代表监控结果摘要的结构
type summary struct {
// goroutine 的数量
NumGoroutine int 'json:"goroutine_number"'
//调度器的摘要信息
SchedSummary sched.SummaryStruct 'json:"sched_summary"'
//从开始监控至今流逝的时间
EscapedTime string 'json:"escaped_time"'
}可以看到,该类型也为 JSON 格式的序列化做好了准备。使用 encoding/json 包中的 MarshalIndent 函数把该类型的值序列化为易读的 JSON 格式字符串,然后通过调用 record 函数记录它们。
紧接着,对 prevNumGoroutine 和 pievSchedSummaryStruct 进行赋值,以便进行后续的比较操作。最后,递增 recordCount 的值也非常必要,因为它是摘要信息的重要组成部分。
函数 recordSummary 中的 go 函数所包含的 for 代码块基本上就是如此。此外,为了让这个 for 循环在迭代之间能有一个小小的停顿,把下面这条语句放在了 for 代码块的最后:
time.Sleep(time.Microsecond)实际上,与 reportError 函数相比,recordSummary 函数更有必要加上这条语句。
与错误的接收和报告一样,对摘要信息的获取、比对、组装和记录也是独立进行的。它由 Monitor 函数启动,并会在接收到停止信号之后结束。发送停止信号的代码存在于 checkstatus 函数中,因为只有它才知道什么时候停止监控。
5) 检查状态
函数 checkstatus 的主要功能是定时检查调度器是否空闲,并在它空闲持续一段时间之后停止监控和调度器。为此,该函数需要适时检查各种计数值,并在必要时发出停止信号。checkstatus 是一个比较重要的辅助函数,职责也较多,它的签名如下:
//用于检查狀态,并在满足持续空闲叶间的条件时采取必要措施
func checkstatus(
scheduler sched.Scheduler,
checkInterval time.Duration,
maxIdleCount uint,
autoStop bool,
checkCountChan chan <- uint64,
record Record,
stopFunc context.CancelFunc)其中的参数前面都介绍过。注意,参数 checkCountChan 的类型是一个发送通道,这是为了限制 checkstatus 函数对它的操作。
checkstatus 函数也把所有代码都放入了 go 函数。go 函数中的第一条语句是:
var checkCount uint64该变量代表的是检查计数值。紧接着是一条 defer 语句:
defer func() {
stopFunc()
checkCountChan <- checkCount
}()它的作用是保证在go函数执行即将结束时发出停止信号和发送检查计数值,这个时 机非常关键。这个go函数总会在调度器空闲的时间达到最长持续空闲时间时结束执行。
在等待调度器开启之后,go函数首先要做的就是准确判定最长持续空闲时间是否到 达。为了让这一判定有据可依,下面这个变量是必需的:
var idleCount uint它的值将会代表监控函数连续发现调度器空闲的计数值。另外,为了记录调度器持续空闲的时间,还需要声明一个这样的变量:
var firstIdleTime time.Time注意,真实的持续空闲时间与理想的持续空闲时间(由参数 checkInterval 和 maxIdleCount 的值相乘得出的那个时间)之间肯定是有偏差的。并且,前者肯定会大于后者,因为执行判定的代码也是需要耗时的。
可以肯定的是,我们需要在一个 for 循环中进行与持续空闲时间判定有关的那些操作。由于这条 for 语句中的条件判断比较多且复杂,所以我先贴出它们然后再进行解释:
for {
//检查调度器的空闲状态
if scheduler.Idle() {
idleCount++
if idleCount == 1 {
firstIdleTime = time.Now()
}
if idleCount >= maxIdleCount {
msg := fmt.Sprintf(msgReachMaxIdleCount, time.Since(firstIdleTime).String())
record(0, msg)
//再次检查调度器的空闲状态,确保它已经可以停止
if scheduler.Idle() {
if autoStop {
var result string
if err := scheduler.Stop(); err == nil {
result = "success" '
} else {
result = fmt.Sprintf("failing(%s)", err)
}
msg = fmt.Sprintf(msgStopScheduler, result)
record(0, msg)
}
break
} else {
if idleCount > 0 {
idleCount = 0
}
}
}
} else {
if idleCount > 0 {
idleCount = 0
}
}
checkCount++
time.Sleep(checkInterval)
}可以看到,总是让 checkCount 的值随着迭代的进行而递增,同时也会依据 checkInterval 让每次迭代之间存在一定的时间间隔。
在此 for 代码块的最开始,通过调用调度器的 Idle 方法来判断它是否已经空闲。如果不是,就及时清零 idleCount 的值。因为一旦发现调度器未空闲,就要重新进行计数。
反过来讲,如果发现调度器已空闲,就需要递增 idleCount 的值。同时,如果发现重新计数刚刚开始,就会把 firstIdleTime 的值设置为当前时间。只有这样才能在 idleCount 的值达到最大空闲计数时,根据 firstIdleTime 的值准确计算出真实的最长持续空闲时间。
在做好计数和起始时间的检查和校正工作之后,会马上把 idleCount 的值与最大空闲计数相比较。如果前者大于或等于后者,就可以初步判定调度器已经空闲了足够长的时间,这时,会立刻记下一条基于模板 msgReachMaxIdleCount 生成的消息。该模板的声明如下:
//已达到最大空闲计数的消息模板
var msgReachMaxIdleCount = "The scheduler has been idle for a period of time" +
"(about %s)." + " Consider to stop it now."这条消息建议网络爬虫框架的使用方关闭调度器。不过,使用方可以通过把参数 autoStop 的值设置为 true,让调度器监控函数自动关闭调度器,这也是后面再次调用调度器的 Idle 方法的原因之一。
如果这里的调用结果值和 autoStop 参数的值均为 true,那么函数就帮助使用方停止调度器。如果调用结果值为 false,那么 idleCount 变量的值也会被及时清零,对调度器空闲的计数将重新开始。这显然是一种比较保守的做法,但却可以有效地避免过早地停止调度器。
实际上,只要对 Idle 方法第二次调用的结果值为 true,不管 autoStop 参数的值是怎样的,都会退出当前的 for 代码块。for 代码块执行结束就意味着 checkstatus 函数异步执行结束。还记得吗?在 checkstatus 中的 go 函数执行结束之际,它会发出停止信号,同时向通道 checkCountChan 发送检查计数值。
至此,已经展示和说明了 checkstatus 函数以及 Monitor 函数涉及的绝大多数代码。
6) 使用监控函数
有了 Monitor 函数,就可以在 finder 的 main 函数中这样使用它来启动对调度器的监控了:
//准备监控参数
checkInterval := time.Second
summarizeInterval := 100 * time.Millisecond
maxIdleCount := uint(5)
//开始监控
checkCountChan := monitor.Monitor(
scheduler,
checkInterval,
summarizeInterval,
maxIdleCount,
tiue,
lib.Record)
//省略部分代码
//等待监控结束
<-checkCountChan把检查间隔时间设置为 10 毫秒,并把最大空闲计数设置为 50 同时,让 Monitor 函数在调度器的持续空闲时间达到最长持续空闲时间后自动关闭调度器。
调用 Monitor 函数的时机是在初始化调度器之后,以及启动调度器之前。因为只有调度器被初始化过,它的大多数方法才能正常执行。另外,只有在调度器启动之前开始监控,才能记录下它启动时的状况。
给予 Monitor 函数的参数值 lib.Record 代表前面所说的日志记录函数,它的声明是这样的:
//记录日志
func Record(level byte, content string) {
if content == "" {
return
}
switch level {
case 0:
logger.Infoln(content)
case 1:
logger.Warnln(content)
case 2:
logger.Infoln(content)
}
}其中 logger 代表 gopcp.v2/helper/log/base 包下 MyLogger 类型的日志记录器。
启动调度器
现在,我们真的可以启动调度器了。做了这么多准备工作,只需区区几行代码就可以启动调度器了,这些代码在 finder 的 main 函数的最后面:
//准备调度器的启动参数
firstHTTPReq, err := http.NewRequest("GET", firstURL, nil)
if err != nil {
logger.Fatalln(err)
return
}
//开启调度器
err = scheduler.Start(firstHTTPReq)
if err != nil {
logger.Fatalf("An error occurs when starting scheduler: %s", err)
}
//等待监控结束
<-checkCountChan基于命令参数 firstURL,我们可以很容易地创建出首次请求。如果启动调度器不成功,就记下一条严重错误级别的日志。还记得吗?这会使当前进程非正常终止。纵观 main 函数的代码你就会发现,它遇到任何错误都会这样做。这是因为一旦主流程出错,finder 就真的无法再运行下去了。
最后,为了让主 goroutine 等待监控和调度器的停止,我们还加入了对检查计数通道 checkCountChan 的接收操作。
到这里,我们讲述了图片爬虫程序 finder 涉及的几乎所有流程的代码。强烈建议大家在自己的计算机上运行 finder,然后试着改变各种参数的值,再去运行它,并且多多试几次。当然,也可以修改 finder 甚至网络爬虫框架的代码。总之,不论在哪个阶段,阅读、理解、修改、试验是学习编程的必经之路。
13. Go 语言网络爬虫的更多相关文章
- R语言网络爬虫学习 基于rvest包
R语言网络爬虫学习 基于rvest包 龙君蛋君:2015年3月26日 1.背景介绍: 前几天看到有人写了一篇用R爬虫的文章,感兴趣,于是自己学习了.好吧,其实我和那篇文章R语言爬虫初尝试-基于RVES ...
- R语言rvest包网络爬虫
R语言网络爬虫初学者指南(使用rvest包) 钱亦欣 发表于 今年 06-04 14:50 5228 阅读 作者 SAURAV KAUSHIK 译者 钱亦欣 引言 网上的数据和信息无穷无尽,如 ...
- iOS—网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- JAVA平台上的网络爬虫脚本语言 CrawlScript
JAVA平台上的网络爬虫脚本语言 CrawlScript 网络爬虫即自动获取网页信息的一种程序,有很多JAVA.C++的网络爬虫类库,但是在这些类库的基础上开发十分繁琐,需要大量的代码才可以完成一 个 ...
- 13个.Net开源的网络爬虫
请点击此处输入图片描述 1:.Net开源的跨平台爬虫框架 DotnetSpider Star:430 DotnetSpider这是国人开源的一个跨平台.高性能.轻量级的爬虫软件,采用 C# 开发.目前 ...
- 推荐13个.Net开源的网络爬虫
1:.Net开源的跨平台爬虫框架 DotnetSpider Star:430 DotnetSpider这是国人开源的一个跨平台.高性能.轻量级的爬虫软件,采用 C# 开发.目前是.Net开源爬虫最为优 ...
- C语言Linix服务器网络爬虫项目(二)项目设计和通过一个http请求抓取网页的简单实现
我们通过上一篇了解了爬虫具体要实现的工作之后,我们分析得出的网络爬虫的基本工作流程如下: 1.首先选取一部分精心挑选的种子URL: 2.将这些URL放入待抓取URL队列: 3.从待抓取URL队列中取出 ...
- C语言Linix服务器网络爬虫项目(一)项目初衷和网络爬虫概述
一.项目初衷和爬虫概述 1.项目初衷 本人的大学毕设就是linux上用c写的一个爬虫,现在我想把它完善起来,让他像一个企业级别的项目.为了重复发明轮子来学习轮子的原理,我们不使用第三方框架(这里是说的 ...
随机推荐
- 浅谈C++虚函数机制
0.前言 在后端面试中语言特性的掌握直接决定面试成败,C++语言一直在增加很多新特性来提高使用者的便利性,但是每种特性都有复杂的背后实现,充分理解实现原理和设计原因,才能更好地掌握这种新特性. 只要出 ...
- 【Flutter】348- 写给前端工程师的 Flutter 教程
点击上方"前端自习课"关注,学习起来~ | 导语 最爱折腾的就是前端工程师了,从 jQuery 折腾到 AngularJs,再折腾到 Vue.React.最爱跨屏的也是前端工程师, ...
- centos7 7.3php编译安装
1.首先更新依赖包. yum -y update 2.安装依赖包 yum -y install libxml2 libxml2-devel openssl openssl-devel bzip2 bz ...
- CCF-CSP题解 201809-4 再卖菜
碎碎念..近视加老花,还以为第二天除了第二家范围在100以内别的都不确定,于是x**算的记搜复杂度超时了.还鼓捣着什么差分区间最长路,虽然有大神用差分区间做出来了,然而自己并没有看懂. 其实就是一个记 ...
- 《Java练习题》习题集三
编程合集: https://www.cnblogs.com/jssj/p/12002760.html Java总结:https://www.cnblogs.com/jssj/p/11146205.ht ...
- 【转载】[C++ STL] deque使用详解
转载自 https://www.cnblogs.com/linuxAndMcu/p/10260124.html 一.概述 deque(双端队列)是由一段一段的定量连续空间构成,可以向两端发展,因此不论 ...
- kuangbin专题 数论基础 part1?
线段树专题太难了,那我来做数学吧! 但数学太难了,我......(扯 这两天想了做了查了整理了几道数学. 除了一些进阶的知识,像莫比乌斯反演,杜教筛,min25学不会我跳了,一些基础的思维还是可以记录 ...
- 3. abp依赖注入的分析.md
abp依赖注入的原理剖析 请先移步参考 [Abp vNext 源码分析] - 3. 依赖注入与拦截器 本文此篇文章的补充和完善. abp的依赖注入最后是通过IConventionalRegister接 ...
- impala-shell导出数据存在中文异常问题
由于查询在impala-shell 中没有问题,在导出数据的时候才有问题,这是impala-shell的客户端是由python编写的,而Python无法自动将unicode对象写入没有设置默认编码的输 ...
- Nginx配置实例-动静分离实例:搭建静态资源服务器
场景 Nginx入门简介和反向代理.负载均衡.动静分离理解: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/102790862 U ...