scrapy学习笔记(二)框架结构工作原理
scrapy结构图:
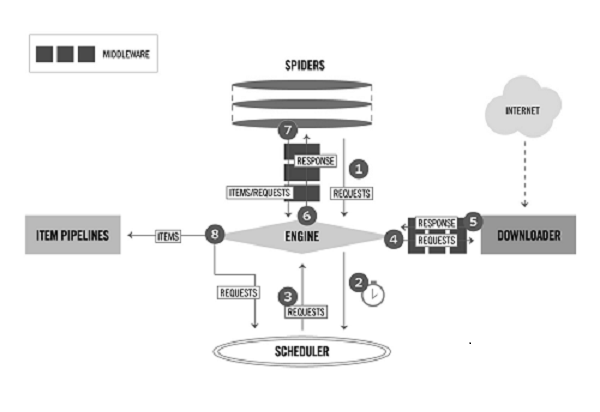
scrapy组件:
- ENGINE:引擎,框架的核心,其它所有组件在其控制下协同工作。
- SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度。
- DOWNLOADER:下载器,负责下载页面(发送HTTP请求/接收HTTP响应)。
- SPIDER:爬虫,负责提取页面中的数据,并产生对新页面的下载请求。
- MIDDLEWARE:中间件,负责对Request对象和Response对象进行处理。
- ITEM PIPELINE:数据管道,负责对爬取到的数据进行处理。
对于用户来说,Spider是最核心的组件,Scrapy爬虫开发是围绕实现Spider展开的。
框架中的数据流:
- REQUEST:scrapy中的HTTP请求对象。
- RESPONSE:scrapy中的HTTP响应对象。
- ITEM:从页面中爬取的一项数据。
Request和Response是HTTP协议中的术语,即HTTP请求和HTTP响应,Scrapy框架中定义了相应的Request和Response类,这里的Item代表Spider从页面中爬取的一项数据。
scrapy大致工作流程:
- 当SPIDER要爬取某URL地址的页面时,需使用该URL构造一个Request对象,提交给ENGINE。
- ENGINE将Request对象传给SCHEDULER,SCHEDULER对URL进行去重,按某种算法进行排队,之后的某个时刻SCHEDULER将其出队,将处理好的Request对象返回给ENGINE。
- ENGINE将SCHEDULER处理后的Request对象发送给DOWNLOADER下载页面。
- DOWNLOADER根据MIDDLEWARE的规则,使用Request对象中的URL地址发送一次HTTP请求到网站服务器,之后用服务器返回的HTTP响应构造出一个Response对象,其中包含页面的HTML文本。DOWNLOADER将结果Resopnse对象传给ENGINE。
- ENGINE将Response对象发送给SPIDER的页面解析函数(构造Request对象时指定)进行处理,页面解析函数从页面中提取数据,封装成Item后提交给ENGINE。
- ENGINE将Item送往ITEMPIPELINES进行处理,最终以某种数据格式写入文件(csv,json)或者存储到数据库中。
整个流程的核心都是围绕着ENGINE进行的。
Request对象
Request对象用来描述一个HTTP请求,下面是其构造器方法的参数列表。
Request(url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None) # url(必选):请求页面的url地址,bytes或str类型,如'http://www.baidu.com'。
# callback:页面解析函数, Callable类型,Request对象请求的页面下载完成后,由该参数指定的页面解析函数被调用。如果未传递该参数,默认调用Spider的parse方法。
# method:HTTP请求的方法,默认为'GET'。
# headers:HTTP请求的头部字典,dict类型,例如{'Accept':'text/html', 'User-Agent':Mozilla/5.0'}。如果其中某项的值为None,就表示不发送该项HTTP头部,例如{'Cookie':None},禁止发送Cookie。
# body:HTTP请求的正文,bytes或str类型。
# cookies:Cookie信息字典,dict类型,例如{'currency': 'USD','country': 'UY'}。
# meta:Request的元数据字典,dict类型,用于给框架中其他组件传递信息,比如中间件Item Pipeline。其他组件可以使用Request对象的meta属性访问该元数据字典(request.meta),也用于给响应处理函数传递信息,
# 详见Response的meta属性。
# encoding:url和body参数的编码默认为'utf-8'。如果传入的url或body参数是str类型,就使用该参数进行编码。
# priority:请求的优先级默认值为0,优先级高的请求优先下载。
# dont_filter:默认情况下(dont_filter=False),对同一个url地址多次提交下载请求,后面的请求会被去重过滤器过滤(避免重复下载)。如果将该参数置为True,可以使请求避免被过滤,强制下载。例如,在多次爬取
# 一个内容随时间而变化的页面时(每次使用相同的url),可以将该参数置为True。
# errback:请求出现异常或者出现HTTP错误时(如404页面不存在)的回调函数。
虽然参数很多,但除了url参数外,其他都带有默认值。在构造Request对象时,通常我们只需传递一个url参数或再加一个callback参数,其他使用默认值即可。
Response对象:
Response对象用来描述一个HTTP响应,Response只是一个基类,根据响应内容的不同有如下子类:
- TextResponse
- HtmlResponse
- XmlResponse
当一个页面下载完成时,下载器依据HTTP响应头部中的Content-Type信息创建某个Response的子类对象。我们通常爬取的网页,其内容是HTML文本,创建的便是HtmlResponse对象,其中HtmlResponse和XmlResponse是TextResponse的子类。实际上,这3个子类只有细微的差别,这里以HtmlResponse为例进行讲解。
下面是HtmlResponse对象的属性及方法。
url:HTTP响应的url地址,str类型。
status:HTTP响应的状态码,int类型,例如200,404。
headers:HTTP响应的头头部,类字典类型,可以调用get或getlist方法对其进行访问,例如:response.headers.get('Content-Type') response.headers.getlist('Set-Cookie')
body:HTTP响应正文,bytes类型。
text:文本形式的HTTP响应正文,str类型,它是由response.body使用response.encoding解码得到的,即reponse.text = response.body.decode(response.encoding)
encoding:HTTP响应正文的编码,它的值可能是从HTTP响应头部或正文中解析出来的。
request:产生该HTTP响应的Request对象。
meta:即response.request.meta,在构造Request对象时,可将要传递给响应处理函数的信息通过meta参数传入;响应处理函数处理响应时,通过response.meta将信息取出。
selector:Selector对象用于在Response中提取数据。
xpath(query):使用XPath选择器在Response中提取数据,实际上它是response.selector.xpath方法的快捷方式。
css(query):使用CSS选择器在Response中提取数据,实际上它是response.selector.css方法的快捷方式。
urljoin(url):用于构造绝对url。当传入的url参数是一个相对地址时,根据response.url计算出相应的绝对url。例如: response.url为http://www.example.com/a,url为b/index.html,调用response.urljoin(url)的结果为http://www.example.com/a/b/index.html。
虽然HtmlResponse对象有很多属性,但最常用的是以下的3个方法:
- xpath(query)
- css(query)
- urljoin(url)
前两个方法用于提取数据,后一个方法用于构造绝对url。
spied开发流程
实现一个Spider子类的过程很像是完成一系列填空题,Scrapy框架提出以下问题让用户在Spider子类中作答:
- 爬虫从哪个或哪些页面开始爬取?
- 对于一个已下载的页面,提取其中的哪些数据?
- 爬取完当前页面后,接下来爬取哪个或哪些页面?
实现一个Spider只需要完成下面4个步骤:
- 继承scrapy.Spider。
- 为Spider取名。
- 设定起始爬取点。
- 实现页面解析函数。
scrapy.Spider基类实现了以下内容:
- 供Scrapy引擎调用的接口,例如用来创建Spider实例的类方法from_crawler。
- 供用户使用的实用工具函数,例如可以调用log方法将调试信息输出到日志。
- 供用户访问的属性,例如可以通过settings属性访问配置文件中的配置。
关于起始URL start_urls:
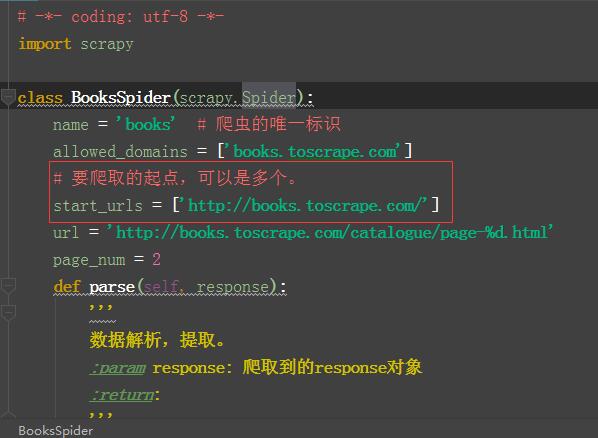
start_urls通常被实现成一个列表,其中放入所有起始爬取点的url(例子中只有一个起始点)。看到这里,大家可能会想,请求页面下载不是一定要提交Request对象么?而我们仅定义了url列表,是谁
暗中构造并提交了相应的Request对象呢?
- 我们将起始URL提交给ENGINE。
- ENGINE调用start_requests方法,我们没有实现整个方法,所以调用了基类的start_requests方法。
- 通过阅读Spider基类的源码可以看到如下内容:

- 基类的start_requests将我们的URL封装成Request对象。
由此我们知道Request对象是调用基类start_requests方法产生的,因此我们也可以自己定义start_requests方法(覆盖基类Spider的start_requests方法),直接构造并提交起始爬取点的Request对象。在某些场景下使用这种方式更加灵活,例如有时想为Request添加特定的HTTP请求头部,或想为Request指定特定的页面解析函数。
页面解析函数parse:
页面解析函数也就是构造Request对象时通过callback参数指定的回调函数(或默认的parse方法)。页面解析函数是实现Spider中最核心的部分,它需要完成以下两项工作:
- 使用选择器提取页面中的数据,将数据封装后(Item或字典)提交给Scrapy引擎。
- 使用选择器或LinkExtractor提取页面中的链接,用其构造新的Request对象并提交给Scrapy引擎(下载链接页面)。
一个页面中可能包含多项数据以及多个链接,因此页面解析函数被要求返回一个可迭代对象(通常被实现成一个生成器函数),每次迭代返回一项数据(Item或字典)或一个Request对象。
内容小结:
- 了解scrapy的六个组件的功能。
- 理解scrapy工作流程。
scrapy学习笔记(二)框架结构工作原理的更多相关文章
- Android学习笔记View的工作原理
自定义View,也可以称为自定义控件,通过自定义View可以使得控件实现各种定制的效果. 实现自定义View,需要掌握View的底层工作原理,比如View的测量过程.布局流程以及绘制流程,除此之外,还 ...
- 西门子PLC学习笔记二-(工作记录)
今天师傅给讲了讲做自己主动化控制的总体的思路,特进行一下记录,做个备忘. 1.需求分析 本次的项目是对楼宇循环供水的控制,整个项目须要完毕压力.压差.温度等的获取及显示.同一时候完毕电机的控制. 2. ...
- tensorflow学习笔记——模型持久化的原理,将CKPT转为pb文件,使用pb模型预测
由题目就可以看出,本节内容分为三部分,第一部分就是如何将训练好的模型持久化,并学习模型持久化的原理,第二部分就是如何将CKPT转化为pb文件,第三部分就是如何使用pb模型进行预测. 一,模型持久化 为 ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- Java IO学习笔记:概念与原理
Java IO学习笔记:概念与原理 一.概念 Java中对文件的操作是以流的方式进行的.流是Java内存中的一组有序数据序列.Java将数据从源(文件.内存.键盘.网络)读入到内存 中,形成了 ...
- python3.4学习笔记(二) 类型判断,异常处理,终止程序
python3.4学习笔记(二) 类型判断,异常处理,终止程序,实例代码: #idle中按F5可以运行代码 #引入外部模块 import xxx #random模块,randint(开始数,结束数) ...
- Linux学习笔记(二) 文件管理
了解 Linux 系统基本的文件管理命令可以帮助我们更好的使用 Linux 系统,以下介绍几个常用的文件管理命令 1.pwd pwd 是 Print Working Directory 的简写,用于显 ...
- amazeui学习笔记二(进阶开发4)--JavaScript规范Rules
amazeui学习笔记二(进阶开发4)--JavaScript规范Rules 一.总结 1.注释规范总原则: As short as possible(如无必要,勿增注释):尽量提高代码本身的清晰性. ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
随机推荐
- Ubuntu的系统应用
1:最近在苹果笔记本做了双系统,启动电脑后还是蛮酷的,但是ubuntu系统安好后,没有wifi图标,于是必须连接有线网络,更新数据包才可以. 2: 常用命令 查看软件xxx安装内容#dpkg ...
- FCC---Animate Elements Continually Using an Infinite Animation Count---设置animation-iteration-count的次数为无限,让小球一直跳动
The previous challenges covered how to use some of the animation properties and the @keyframes rule. ...
- Python之dict(或对象)与json之间转化
在Python语言中,json数据与dict字典以及对象之间的转化,是必不可少的操作. 在Python中自带json库.通过import json导入. 在json模块有2个方法, loads():将 ...
- NumPy实现数组的拼接和分裂
一.数组的拼接 import numpy as np x=np.array([,,]) x2=np.array([,,])np.concatenate([x,x2]) 输出:array([1, 2, ...
- 8.python3实用编程技巧进阶(三)
3.1.如何实现可迭代对象和迭代器对象 #3.1 如何实现可迭代对象和迭代器对象 import requests from collections.abc import Iterable,Iterat ...
- bayaim_今晚打老虎
bayaim_2018年11月22日11:01:14 <<<--- 再牛逼的肖邦,也尼玛弹奏不出我内心的悲伤.--->>> 艹,今天想骂人,艹TMD自己,不小心把自 ...
- [日常] gocron源码阅读-使用go mod管理依赖源码启动gocron
从 Go1.11 开始,golang 官方支持了新的依赖管理工具go modgo mod download: 下载依赖的 module 到本地 cachego mod edit: 编辑 go.modg ...
- itest(爱测试) 3.5.0 发布,开源BUG 跟踪管理& 敏捷测试管理软件
v3.5.0 下载地址 :itest下载 itest 简介:查看简介 V3.5.0 增加了 9个功能增强,和17个BUG修复 ,详情如下所述. 9个功能增强 : (1)增加xmind(思维导图) 转E ...
- 平方,立方,n次方,上标/下标
选种你需要的上标,如2,右键设置单元格格式:选择上标,确定即可: 最终效果:
- github配置ssh及多ssh key问题处理
一.生成ssh公私钥 用ssh-keygen生成公私钥. $ssh-keygen -t rsa -C "你的邮箱" -f ~/.ssh/id_rsa_mult 在~/./ssh目录 ...