用链表和数组实现HASH表,几种碰撞冲突解决方法
Hash算法中要解决一个碰撞冲突的办法,后文中描述了几种解决方法。下面代码中用的是链式地址法,就是用链表和数组实现HASH表。
he/*hash table max size*/
#define HASH_TABLE_MAX_SIZE 40 /*hash table大小*/
int hash_table_size=; /*.BH-----------------------------------------------------------------
** 结构体定义
**.EH-----------------------------------------------------------------
*/
/*hashTable结构*/
typedef int HashKeyType;
typedef struct{
OMS_TYPE__CurrFaultReport curr_fault_report;
unsigned int begin_time[SYS_FAULT_REPORT_MAX_NUM];
unsigned int end_time[SYS_FAULT_REPORT_MAX_NUM];
unsigned int report_valid[SYS_FAULT_REPORT_MAX_NUM];
}HashValueType; typedef struct HashNode_Struct HashNode;
struct HashNode_Struct
{
HashKeyType sKey;
HashValueType nValue;
HashNode* pNext;
};
HashNode* hashTable[HASH_TABLE_MAX_SIZE]; //hash table data strcutrue /*=================hash table function======================*/
/*.BH-----------------------------------------------------------------
**
**函数名:
**
**功能:string hash function
**
**参数: 无
**
**返回值:无
**
**设计注记:
**
**.EH-----------------------------------------------------------------
*/
unsigned int hash_table_hash_str(const char* skey)
{
const signed char *p = (const signed char*)skey;
unsigned int h = *p;
if(h)
{
for(p += ; *p != '\0'; ++p){
h = (h << ) - h + *p;
}
}
return h;
} /*.BH-----------------------------------------------------------------
**
**函数名:
**
**功能:insert key-value into hash table
**
**参数: 无
**
**返回值:无
**
**设计注记:
**
**.EH-----------------------------------------------------------------
*/
int hash_table_insert(const HashKeyType skey, HashValueType nvalue)
{
unsigned int pos = ;
HashNode* pHead = NULL;
HashNode* pNewNode = NULL; if (hash_table_size >= HASH_TABLE_MAX_SIZE)
{
printf("out of hash table memory!\n");
return ;
} pos = hash_table_hash_str(skey) % HASH_TABLE_MAX_SIZE;
pHead = hashTable[pos];
while (pHead)
{
if (pHead->sKey == skey)
{
printf("hash_table_insert: key %d already exists!\n", skey);
return ;
}
pHead = pHead->pNext;
} pNewNode = (HashNode*)malloc(sizeof(HashNode));
memset(pNewNode, , sizeof(HashNode));
pNewNode->sKey = skey;
memcpy(&pNewNode->nValue, &nvalue, sizeof(HashValueType)); pNewNode->pNext = hashTable[pos];
hashTable[pos] = pNewNode; hash_table_size++;
return ;
} /*.BH-----------------------------------------------------------------
**
**函数名:
**
**功能:lookup a key in the hash table
**
**参数: 无
**
**返回值:无
**
**设计注记:
**
**.EH-----------------------------------------------------------------
*/
HashNode* hash_table_find(const HashKeyType skey)
{
unsigned int pos = ; pos = hash_table_hash_str(skey) % HASH_TABLE_MAX_SIZE;
if (hashTable[pos])
{
HashNode* pHead = hashTable[pos];
while (pHead)
{
if (skey == pHead->sKey)
return pHead;
pHead = pHead->pNext;
}
}
return NULL;
} /*.BH-----------------------------------------------------------------
**
**函数名:
**
**功能:free the memory of the hash table
**
**参数: 无
**
**返回值:无
**
**设计注记:
**
**.EH-----------------------------------------------------------------
*/
void hash_table_release()
{
int i;
for (i = ; i < HASH_TABLE_MAX_SIZE; ++i)
{
if (hashTable[i])
{
HashNode* pHead = hashTable[i];
while (pHead)
{
HashNode* pTemp = pHead;
pHead = pHead->pNext;
if (pTemp)
{
free(pTemp);
} }
}
}
} //remove key-value frome the hash table
/*.BH-----------------------------------------------------------------
**
**函数名:
**
**功能:string hash function
**
**参数: 无
**
**返回值:无
**
**设计注记:
**
**.EH-----------------------------------------------------------------
*/
void hash_table_remove(const HashKeyType skey)
{
unsigned int pos = hash_table_hash_str(skey) % HASH_TABLE_MAX_SIZE;
if (hashTable[pos])
{
HashNode* pHead = hashTable[pos];
HashNode* pLast = NULL;
HashNode* pRemove = NULL;
while (pHead)
{
if (skey == pHead->sKey)
{
pRemove = pHead;
break;
}
pLast = pHead;
pHead = pHead->pNext;
}
if (pRemove)
{
if (pLast)
pLast->pNext = pRemove->pNext;
else
hashTable[pos] = NULL; free(pRemove);
}
}
hash_table_size--;
} /*.BH-----------------------------------------------------------------
**
**函数名:
**
**功能:print the content in the hash table
**
**参数: 无
**
**返回值:无
**
**设计注记:
**
**.EH-----------------------------------------------------------------
*/
void hash_table_print()
{
int i;
printf("===========content of hash table===========\n");
for (i = ; i < HASH_TABLE_MAX_SIZE; ++i){
if (hashTable[i])
{
HashNode* pHead = hashTable[i];
printf("%d=>", i);
while (pHead)
{
printf("%d:%d ", pHead->sKey, pHead->nValue.begin_time);
pHead = pHead->pNext;
}
printf("\n");
}
}
} /*.BH-----------------------------------------------------------------
**
**函数名:
**
**功能:初始化系统名称的hashTable,插入所有系统名称
**
**参数: 无
**
**返回值:无
**
**设计注记:
**
**.EH-----------------------------------------------------------------
*/
void Common_InitHashTable()
{ hash_table_size = ;
memset(hashTable, , sizeof(HashNode*) * HASH_TABLE_MAX_SIZE);
}
Hash碰撞冲突
Hash函数的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突。如下将介绍如何处理冲突,当然其前提是一致性hash。
1.开放地址法
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,…k*k,-k*k(k<=m/2),称二次探测再散列。
如果di取值可能为伪随机数列。称伪随机探测再散列。
2.再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止
3.链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中。如下:
因此这种方法,可以近似的认为是筒子里面套筒子
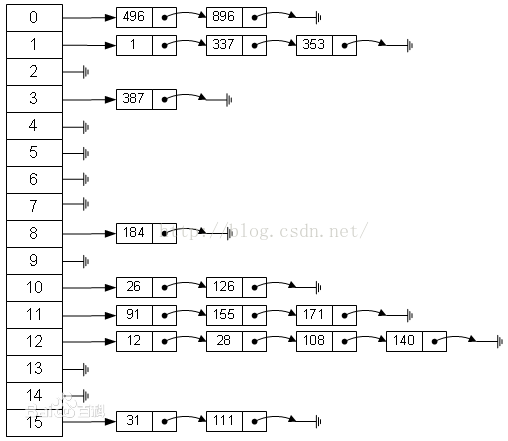
4.建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
优缺点:
优点:
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
缺点:
指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
开放地址法和拉链法是比较常用的两种,各有优缺点,开放地址法的过程可以参考以下链接。
参考链接:HASH碰撞
用链表和数组实现HASH表,几种碰撞冲突解决方法的更多相关文章
- [转]Hash碰撞冲突解决方法总结
我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突.如下将介绍 ...
- 数组和Hash表
数组和Hash表 当显示多条结果时,存储在变量中非常智能,变量类型会自动转换为一个数组. 在下面的例子中,使用GetType()可以看到$a变量已经不是我们常见的string或int类型,而是Obje ...
- 问题-[Access]“无法打开工作组信息文件中的表 'MSysAccounts'”的问题的解决方法
问题现象:ado.net oledb方式访问Access数据库文件时报错“无法打开工作组信息文件中的表 'MSysAccounts'”的问题的解决方法 问题处理:1.数据库名称不能命名为:Syste ...
- Oracle system表空间满的暂定解决方法
Oracle system表空间满的暂定解决方法 数据库用的是Oracle Express 10.2版本的.利用Oracle Text做全文检索应用,创建用户yxl时没有初始化默认表空间,在系统开发过 ...
- django.db.utils.OperationalError: (1050, "Table '表名' already exists)解决方法
django.db.utils.OperationalError: (1050, "Table '表名' already exists)解决方法 找到解决方案,执行: python mana ...
- 6.数组和Hash表
当显示多条结果时,存储在变量中非常智能,变量类型会自动转换为一个数组. 在下面的例子中,使用GetType()可以看到$a变量已经不是我们常见的string或int类型,而是Object类型,使用-i ...
- C语言实现顺序表的基本操作(从键盘输入 生成线性表,读txt文件生成线性表和数组生成线性表----三种写法)
经过三天的时间终于把顺序表的操作实现搞定了.(主要是在测试部分停留了太长时间) 1. 线性表顺序存储的概念:指的是在内存中用一段地址连续的存储单元依次存储线性表中的元素. 2. 采用的实现方式:一段地 ...
- 【java基础 10】hash算法冲突解决方法
导读:今天看了java里面关于hashmap的相关源码(看了java6和java7),尤其是resize.transfer.put.get这几个方法,突然明白了,为什么我之前考数据结构死活考不过,就差 ...
- 解决Hash碰撞冲突的方法
Hash碰撞冲突 我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰 ...
随机推荐
- WPF中获取鼠标相对于屏幕的位置
原文:WPF中获取鼠标相对于屏幕的位置 WPF中获取鼠标相对于屏幕的位置 周银辉WPF编程时,我们经常使用Mouse.GetPosi ...
- 在云中生成和模拟 iOS
原文:在云中生成和模拟 iOS 1.原文地址 https://msdn.microsoft.com/zh-cn/library/vs/alm/dn858446.aspx
- Microsoft Enterprise Library 5.0 系列(四)
企业库日志应用程序模块工作原理图: 从上图我们可以看清楚企业库日志应用程序模块的工作原理,其中LogFilter,Trace Source,Trace Listener,Log Formatter的信 ...
- epplus输出成thml
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...
- 在UWP的XAML中使用原始类型
问题: I'm trying to access the system namespace for StaticResource variables in XAML on UWP. Here's (m ...
- css的双飞翼布局
双飞翼布局的大概意思就是左右两边的内容是固定的,大小是固定的, 而中间的布局的随着页面的大小变化而自动变化的. 通过代码来解析: 1.四个div,也可以使用section,其中main,left.ri ...
- CSS3 GENERATOR可以同时为一个元素完成border-radius、box-shadow、gradient和opacity多项属性的设置
CSS3 GENERATOR可以同时为一个元素完成border-radius.box-shadow.gradient和opacity多项属性的设置 CSS3 GENERATOR 彩蛋爆料直击现场 CS ...
- C#每天进步一点--引用类型和值类型
在刚参加工作面试时,我们经常会遇到有关值类型和引用类型的问题,你回答的怎么样直接影响你在别人心目中的印象,你回答的不好说明你对C#没有深入的了解学习,今天我带大家回顾下C#中的引用类型和值类型. CL ...
- 最近公共祖先(least common ancestors algorithm)
lca问题是最近公共祖先问题,一般是针对树结构的.现在有两种方法来解决这样的问题 1. On-line algorithm 用比较长的时间做预处理.然后对每次询问进行回答. 思路:对于一棵树中的两个节 ...
- C语言实现常用数据结构——图
#include<stdio.h> #include<stdlib.h> #define SIZE 20 #define LENGTH(a) (sizeof(a)/sizeof ...