浅谈HDFS(二)之NameNode与SecondaryNameNode
NN与2NN工作机制
思考:NameNode中的元数据是存储在哪里的?
- 假设存储在NameNode节点的硬盘中,因为经常需要随机访问和响应客户请求,必然效率太低,所以是存储在内存中的
- 但是,如果存储在内存中,一旦断电,元数据丢失,整个集群便无法工作,因此会在硬盘中产生备份元数据的Fsimage
- 但是这样又会有新的问题出现,当内存中的元数据更新时,需要同时更新Fsimage,否则会发生一致性的问题;
- 但要更新的话,又会导致效率过低
- 因此,又引入了Edits文件,用来记录客户端更新元数据的每一步操作(只进行追加操作,效率很高),每当元数据有更新时,就把更新的操作记录到Edits中,Edits也存放在硬盘中
- 这样,一旦NameNode节点断电,可以通过Fsimage和Edits合并,生成最新的元数据
- 如果长时间一直添加操作数据到Edits,会导致文件数据过大,效率降低,而一旦断电会造成恢复时间过长,因此需要对Fsimage与Edits定期合并
- 而如果这些操作都交给NameNode节点完成,则又会造成效率降低
- 因此引入了一个辅助NameNode的新的节点SecondaryNameNode,专门用于Fsimage和Edits的合并
NN与2NN工作机制
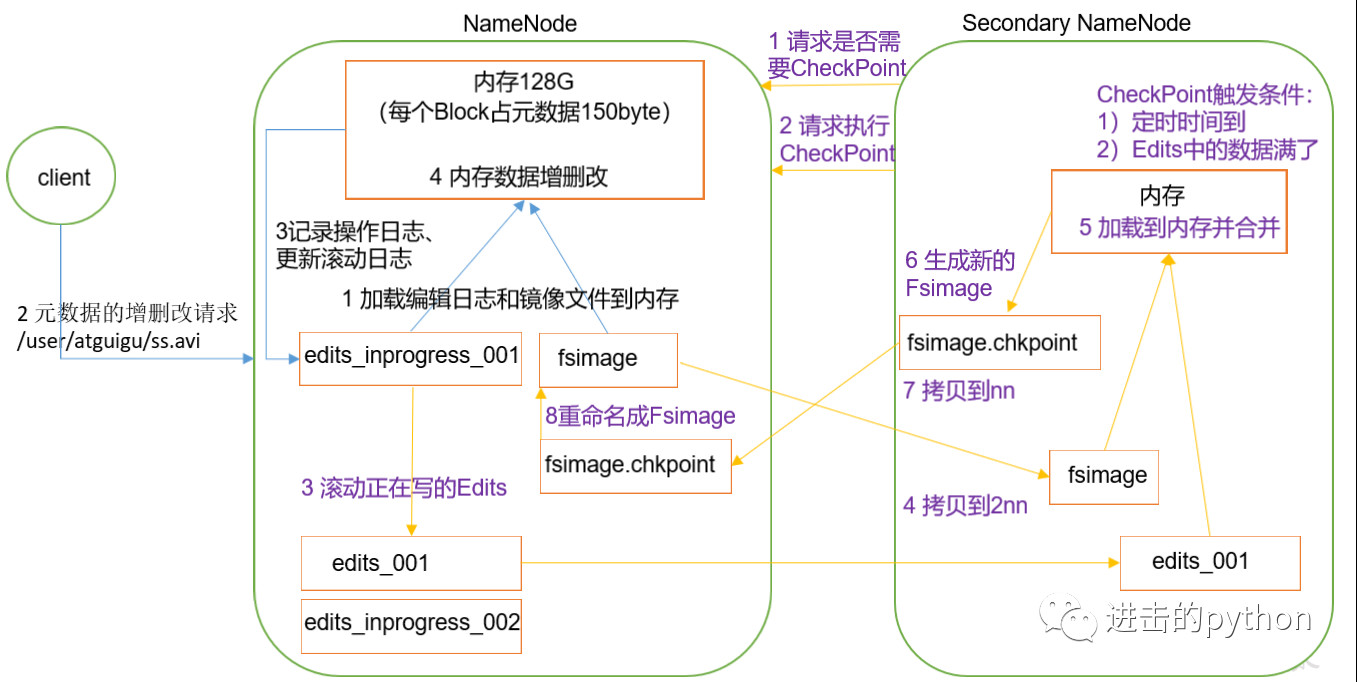
- 第一阶段:NameNode启动
- 第一次启动NameNode格式化之后,创建Fsimage,Edits文件实在启动NameNode时生成的;如果不是第一次创建,会直接加载Edits和Fsimage到内存,在HDFS启动时会有一次Edits和Fsimage的合并操作,此时NameNode内存就持有最新的元数据信息
- 客户端对元数据发送增删改(不记录查询操作,因为查询不改变元数据)的请求
- NameNode会首先记录操作日志,,更新滚动日志
- NameNode在内存中对元数据进行增删改操作
- 第二阶段:SecondaryNameNode工作
- SecondaryNameNode定期询问NameNode是否需要CheckPoint,直接带回NameNode是否检查的结果
- 当CheckPoint定时时间到了或者Edits中的数据满了,SecondaryNameNode请求执行CheckPoint
- NameNode滚动正在写的Edits,并生成新的空的edits.inprogress_002,滚动的目的是给Edits打个标记,以后所有更新操作都写入edits.inprogress_002中
- 原来的Fsimage和Edits文件会拷贝到SecondaryNameNode节点,SecondaryNameNode会将它们加载到内存合并,生成新的镜像文件fsimage.chkpoint
- 然后将新的镜像文件fsimage.chkpoint拷贝给NameNode,重命名为Fsimage,替换原来的镜像文件
- 因此,最后当NameNode启动时,只需要加载之前未合并的Edits和Fsimage即可更新到最新的元数据信息
Fsimage与Edits解析
- NameNode在格式化之后,将在
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current/目录下产生如下文件:
-rw-rw-r--. 1 kocdaniel kocdaniel 945 9月 25 20:27 fsimage_0000000000000000000
-rw-rw-r--. 1 kocdaniel kocdaniel 62 9月 25 20:27 fsimage_0000000000000000000.md5
-rw-rw-r--. 1 kocdaniel kocdaniel 4 9月 25 20:27 seen_txid
-rw-rw-r--. 1 kocdaniel kocdaniel 205 9月 25 10:25 VERSION
- fsimage:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息
- Edits(启动NameNode时生成):存放HDFS文件系统所有更新操作,文件系统客户端执行的写操作首先会被记录到Edits文件中
- seen_txis:保存的时一个数字,是最新的edits_后的数字
- 每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits文件里的更新操作,保证内存中元数据的内容是最新的,同步的
- oiv查看Fsimage文件
- 基本语法:
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
- oev查看Edits文件
- 基本语法:
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径
Checkpoint时间设置
默认情况下,SecondaryNameNode每隔一个小时或者当操作次数超过100万次时执行一次,但是操作次数的统计SecondaryNameNode自己做不到,需要借助NameNode,所以还有一个参数设置是namenode每隔一分钟检查一次操作次数,当操作次数达到100万时SecondaryNameNode开始执行Checkpoint,三个参数的设置都在hdfs_site.xml配置文件中,配置如下:
# SecondaryNameNode每隔一个小时执行一次
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
# SecondaryNameNode当操作次数超过100万次时执行一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
# NameNode一分钟检查一次操作次数
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
NameNode故障处理
NameNode故障后有两种处理方式:
NameNode故障处理方式一:直接将SecondaryNameNode目录下的数据直接拷贝到NameNode目录下,然后重新启动NameNode
NameNode故障处理方式二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode目录下的数据直接拷贝到NameNode目录下
- 首先需要在hdfs_site.xml文件中添加如下配置
# SecondaryNameNode每隔两分钟执行一次
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
# 指定namenode生成的文件目录
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
- 然后,如果SecondaryNameNode和NameNode不在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
- 最后导入检查点数据(等待一会儿ctrl + c结束掉)
[kocdaniel@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint
注意:执行完该命令后,观察namenode已经启动(临时启动),而且每2分钟检查一次,如果确定已经恢复了数据,我们ctrl+c停止,然后自己手动起namenode
ctrl+c之后,重启namenode即可恢复数据,但是并不能完全恢复,可能会将最新的Edits文件中的操作丢失
集群安全模式
什么是安全模式
- NameNode启动时,首先将Fsimage载入内存,再执行Edits中的各项操作,一旦在内存中成功建立文件系统元数据的映像,则创建一个新的Fsimage文件和一个空的编辑日志,然后开始监听DataNode请求,在这个过程期间,NameNode一直运行在安全模式下,也就是NameNode对于客户端是只读的
- DataNode启动时,系统中的数据块的位置并不是由NameNode维护的,而是由块列表的形式存储在DataNode中,在系统的正常操作期间,NameNode会在内存中保留所有块的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解足够多的块列表信息后,即可高效运行文件系统
- 安全模式退出判断:如果满足最小副本条件,NameNode会在30秒之后退出安全模式。最小副本条件是指在整个文件系统中99.9%的块满足最小副本级别(默认为1),即99.9%的块至少有一个副本存在。
- 在启动一个刚刚格式化的HDFS集群时,由于系统中还没有任何块,所以NameNode不会进入安全模式
基本语法
- 集群处于安全模式时,不能执行任何重要操作(写操作)。
- 集群启动完成后,自动退出安全模式
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
# wait是指,如果在脚本中写入此命令,则脚本将等待安全模式退出后自动执行
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
NameNode多目录配置
- NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性,提高高可用性
- 具体需要在hdfs_site.xml中加入如下配置:
# 指定目录的路径
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
欢迎关注下方公众号,获取更多文章信息

浅谈HDFS(二)之NameNode与SecondaryNameNode的更多相关文章
- 浅谈HDFS(一)
产生背景及定义 HDFS:分布式文件系统,用于存储文件,主要特点在于其分布式,即有很多服务器联合起来实现其功能,集群中的服务器各有各的角色 随着数据量越来越大,一个操作系统存不下所有的数据,那么就分配 ...
- Android开发-浅谈架构(二)
写在前面的话 我记得有一期罗胖的<罗辑思维>中他提到 我们在这个碎片化 充满焦虑的时代该怎么学习--用30%的时间 了解70%该领域的知识然后迅速转移芳草鲜美的地方 像游牧民族那样.原话应 ...
- 浅谈HDFS(三)之DataNote
DataNode工作机制 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳. DataNode启动后向Nam ...
- Qt浅谈之二十七进程间通信之QtDBus
一.简介 DBus的出现,使得Linux进程间通信更加便捷,不仅可以和用户空间应用程序进行通信,而且还可以和内核的程序进行通信,DBus使得Linux变得更加智能,更加具有交互性. DB ...
- Qt浅谈之二十App自动重启及关闭子窗口
一.简介 最近因项目需求,Qt程序一旦检测到错误,要重新启动,自己是每次关闭主窗口的所有子窗口但有些模态框会出现问题,因此从网上总结了一些知识点,以备以后的应用. 二.详解 1.Qt结构 int ma ...
- Qt浅谈之二十App自动重启及关闭子窗口(六种方法)
一.简介 最近因项目需求,Qt程序一旦检测到错误,要重新启动,自己是每次关闭主窗口的所有子窗口但有些模态框会出现问题,因此从网上总结了一些知识点,以备以后的应用. 二.详解 1.Qt结构 int ma ...
- 浅谈Struts2(二)
一.struts2的跳转 1.action跳转JSP a.默认为forward <action name="action1" class="com.liquidxu ...
- 浅谈JSP(二)
一.EL表达式 作用:从作用域(pageContext,request,session,application)中取值,并显示在页面中. 本质:用于替换输出脚本(<%= %>). 1.从作 ...
- 浅谈DevExpress<二>:设计一个完整界面(1)
昨天谈了界面的换肤问题,今天拿一个简单的界面来介绍一下怎么设计一个五脏俱全的界面,总体效果如下图(种类的图片随便找的^^):
随机推荐
- 【Python3爬虫】快就完事了--使用Celery加速你的爬虫
一.写在前面 在上一篇博客中提到过对于网络爬虫这种包含大量网络请求的任务,是可以用Celery来做到加速爬取的,那么,这一篇博客就要具体说一下怎么用Celery来对我们的爬虫进行一个加速! 二.知识补 ...
- go 学习笔记之万万没想到宠物店竟然催生出面向接口编程?
到底是要猫还是要狗 在上篇文章中,我们编撰了一则简短的小故事用于讲解了什么是面向对象的继承特性以及 Go 语言是如何实现这种继承语义的,这一节我们将继续探讨新的场景,希望能顺便讲解面向对象的接口概念. ...
- MSIL实用指南-创建对象
创建对象用Newobj指令,它的操作是创建一个新的对象或值类型,并将对象引用的新实例到计算堆栈上.格式是Newobj <构造函数>实例: ilGenerator.Emit(OpCodes. ...
- Python Web Flask源码解读(三)——模板渲染过程
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- mybatis 源码分析(八)ResultSetHandler 详解
本篇博客就是 myabtis 系列的最后一篇了,还剩 ResultSetHandler 没有分析:作为整个 mybatis 最复杂最繁琐的部分,我不打算按步骤一次详解,因为里面的主要内容就是围绕 re ...
- 阿里云(ecs服务器)使用1-安装Mongdb数据库以及远程部署
1.下载mongodb 百度云盘连接 :链接:https://pan.baidu.com/s/1b-hTS0XHQKpatecFoumLxw 提取码:z9ax 并送上可视化工具:链接:https:/ ...
- E-Explorer_2019牛客暑期多校训练营(第八场)
题意 n个点,m条边,u,v,l,r表示点u到点v有一条边,且只有编号为\([l,r]\)的人能通过,问从点1到点n有哪些编号的人能通过 题解 先对\(l,r\)离散化,用第七场找中位数那题同样的形式 ...
- POJ-1469 COURSES ( 匈牙利算法 dfs + bfs )
题目链接: http://poj.org/problem?id=1469 Description Consider a group of N students and P courses. Each ...
- 题解 bzoj 2151 种树
题意 传送门 手写堆大法好啊,题解貌似没有结构体堆的做法,思路有些像配对堆,关于配对堆请自行百度,因为本蒟蒻不会.. 以下是蒟蒻的做法:建立一个大根堆a维护最大价值里面存入它的编号以及价值.听说配对堆 ...
- XML的相关基础知识分享
XML和Json是两种最常用的在网络中数据传输的数据序列化格式,随着时代的变迁,XML序列化用于网络传输也逐渐被Json取代,前几天,单位系统集成开发对接接口时,发现大部分都用的WebService技 ...