关于CDH集群spark的三种安装方式简述
一、spark的命令行模式
1.第一种进入方式:执行 pyspark进入,执行exit()退出
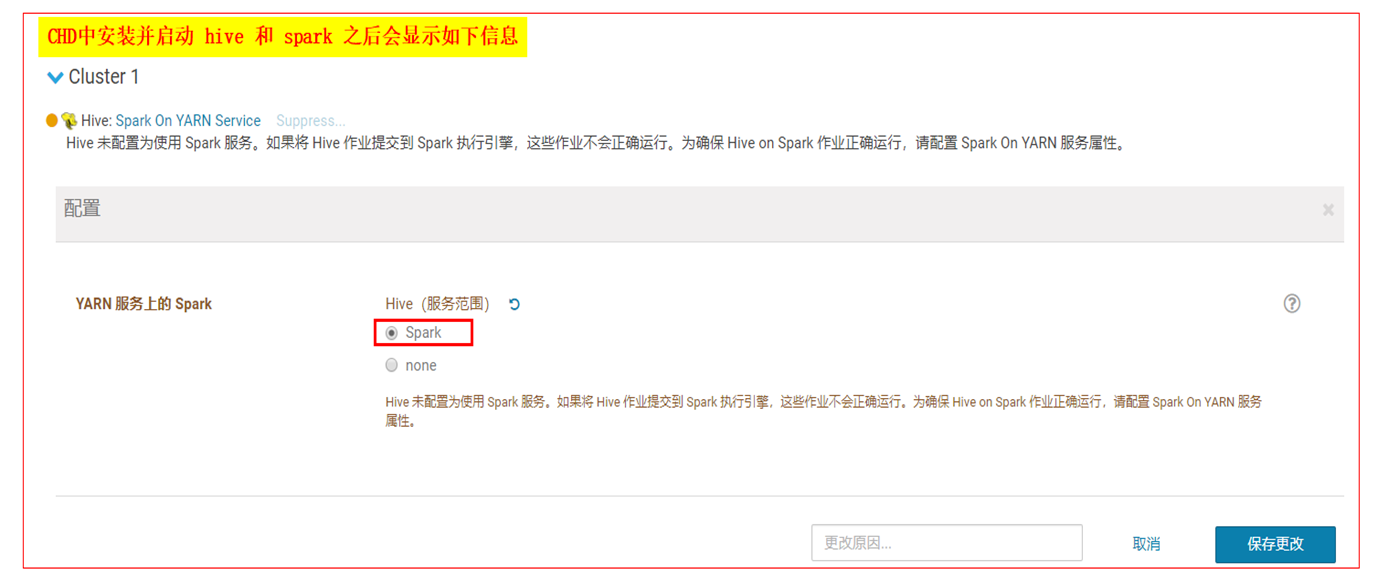
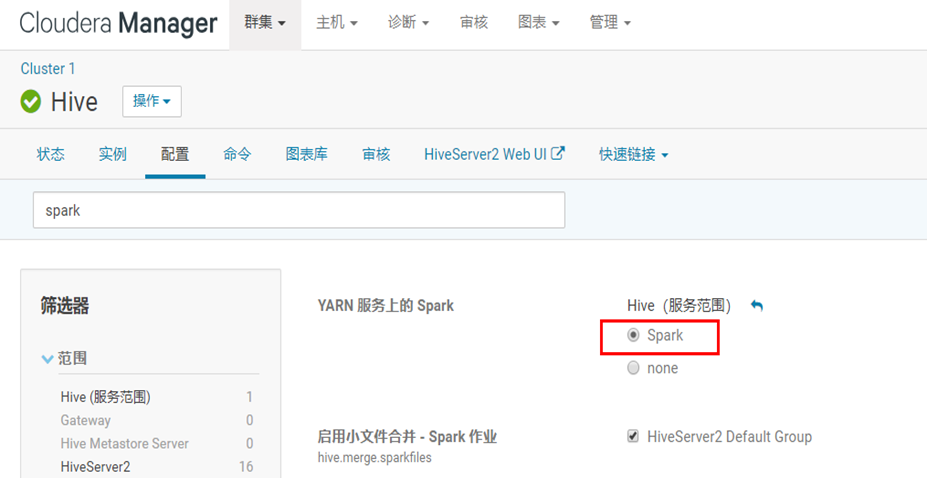
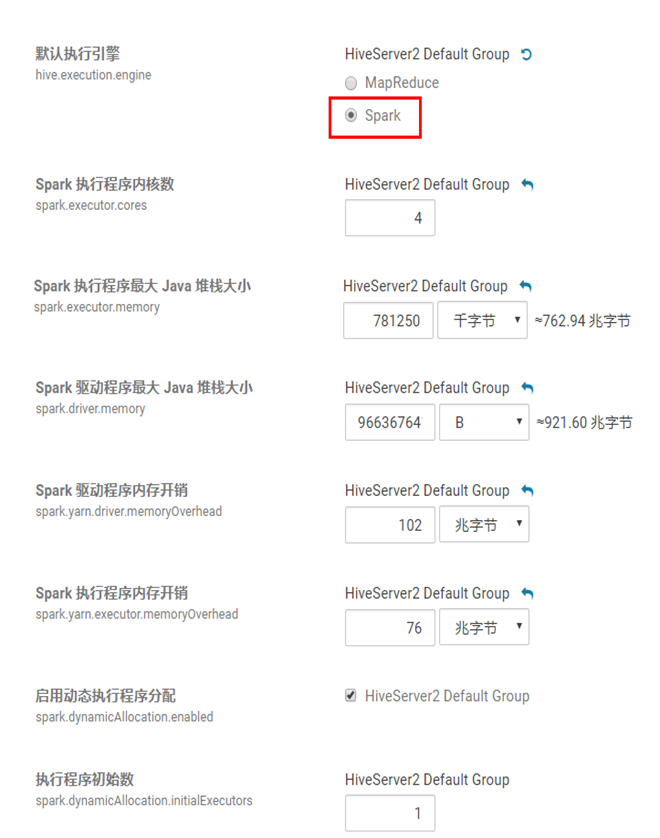
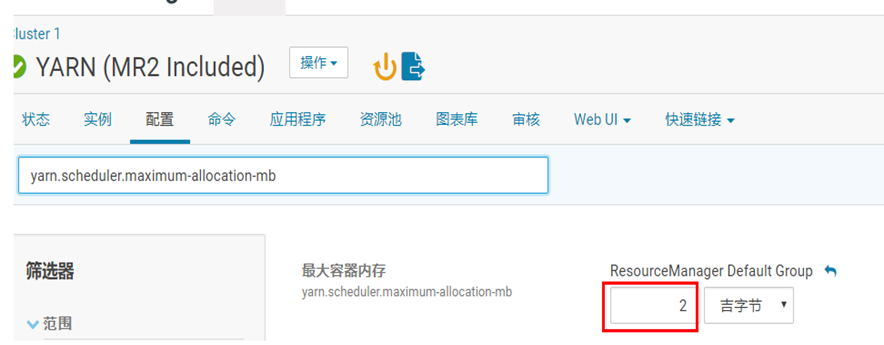
注意报错信息:java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the (最大阈值)max threshold (1024 MB) of this cluster!
表示 执行器的内存(1024+384 MB) 大于最大阈值(1024 MB)
Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'

2.初始化RDD的方法
本地内存中已经有一份序列数据(比如python的list),可以通过sc.parallelize去初始化一个RDD。
当执行这个操作以后,list中的元素将被自动分块(partitioned),并且把每一块送到集群上的不同机器上。
import pyspark
from pyspark import SparkContext as sc
from pyspark import SparkConf
conf=SparkConf().setAppName("miniProject").setMaster("local[*]")
#任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数(比如主节点的URL)。
#初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量。
#Spark shell会自动初始化一个SparkContext(在Scala和Python下可以,但不支持Java)。
#getOrCreate表明可以视情况新建session或利用已有的session
sc=SparkContext.getOrCreate(conf)
# 利用list创建一个RDD;使用sc.parallelize可以把Python list,NumPy array或者Pandas Series,Pandas DataFrame转成Spark RDD。
rdd = sc.parallelize([1,2,3,4,5])
rdd 打印 ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:195
# getNumPartitions() 方法查看list被分成了几部分
rdd.getNumPartitions() 打印结果:2
# glom().collect()查看分区状况
rdd.glom().collect() 打印结果: [[1, 2], [3, 4, 5]]
二、可直接执行 spark-shell,也可以执行 spark-shell --master local[2]
多线程方式:运行 spark-shell --master local[N] 读取 linux本地文件数据 。通过本地 N 个线程跑任务,只运行一个 SparkSubmit 进程,利用 spark-shell --master local[N] 读取本地数据文件实现单词计数master local[N]:采用本地单机版的来进行任务的计算,N是一个正整数,它表示本地采用N个线程来进行任务的计算,会生成一个SparkSubmit进程
关于CDH集群spark的三种安装方式简述的更多相关文章
- 减轻集群负载、三种k8s 替代openstack的解决方案
减轻集群负载.三种k8s 替代openstack的解决方案 待办 https://news.ycombinator.com/item?id=17013779 kubevirt https://host ...
- grub安装的 三种安装方式
1. 引言 grub是什么?最常态的理解,grub是一个bootloader或者是一个bootmanager,通过grub可以引导种类丰富的系统,如linux.freebsd.windows等.但一旦 ...
- 【转】vue.js三种安装方式
Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的渐进式框架.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件.它不仅易于上手 ...
- vue.js三种安装方式
Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的渐进式框架.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件.它不仅易于上手 ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- C++的三种继承方式简述
C++对父类(也称基类)的继承有三种方式,分别为:public继承.protected继承.private继承.三种继承方式的不同在于继承之后子类的成员函数的"可继承性质". 在说 ...
- 第1节 yarn:14、yarn集群当中的三种调度器
yarn当中的调度器介绍: 第一种调度器:FIFO Scheduler (队列调度器) 把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源 ...
- Mongodb集群搭建的三种方式
转自:http://blog.csdn.net/luonanqin/article/details/8497860 MongoDB是时下流行的NoSql数据库,它的存储方式是文档式存储,并不是Key- ...
- Redis集群搭建的三种方式
一.Redis主从 1.1 Redis主从原理 和MySQL需要主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生性能瓶颈,特别是在读压力上,为了分担压力,Redis支持主从复制. ...
随机推荐
- python入门(三)列表、元组、range()、字典
列表(list) 列表简介:列表(list)是处理一组有序项目的数据结构.用方括号[]表示.可以进行添加,删除,替换,搜索操作.是可变的数据类型.列表可以嵌套和支持索引. name=[12," ...
- Linux基础命令和文件权限
Linux命令与文件权限 Linux基础命令 reboot 重启 cd 切换目录 cd .. 回到上一级目录 cd ~ 回到主目录 cd / ...
- yield 实现range()函数
def range(*args,step= 1): args = list(args) if len(args) == 2: yield args[0] while args[0]<args[1 ...
- hdu-6621 K-th Closest Distance
题目链接 K-th Closest Distance Problem Description You have an array: a1, a2, , an and you must answer ...
- codeforce617E-XOR and Favorite Number莫队+异或前缀和
传送门:http://codeforces.com/contest/617/problem/E 参考:https://blog.csdn.net/keyboarderqq/article/detail ...
- Codeforces-450D-Jzzhu and Cities+dji
参考:https://blog.csdn.net/corncsd/article/details/38235973 传送门:http://codeforces.com/problemset/probl ...
- codeforces 14E. Camels(多维dp)
题目链接:http://codeforces.com/problemset/problem/14/E 题意:就是给出n个点要求画出t个波峰和t-1个波谷 很显然要t个波峰和t-1个波谷开始是波动一定是 ...
- 天梯杯 L2-023 图着色问题
L2-023. 图着色问题 时间限制 300 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 图着色问题是一个著名的NP完全问题.给定无向图 G ...
- php preg_match pcre回溯绕过
原理需要知识:正则NFA回溯原理,php的pcre.backtrack_limit设置. 正则NFA回溯原理正则表达式是一个可以被"有限状态自动机"接受的语言类."有限状 ...
- Postgresql-rman
联机程序. 并且目标数据库必须处于归档模式. 支持在线全备, 增量备份, 归档备份 增量备份基于已经存在的一个全库备份 rman 本身使用pg_start_backup(), copy, pg_sto ...