【深度学习】Focal Loss 与 GHM——解决样本不平衡问题
Focal Loss 与 GHM
Focal Loss
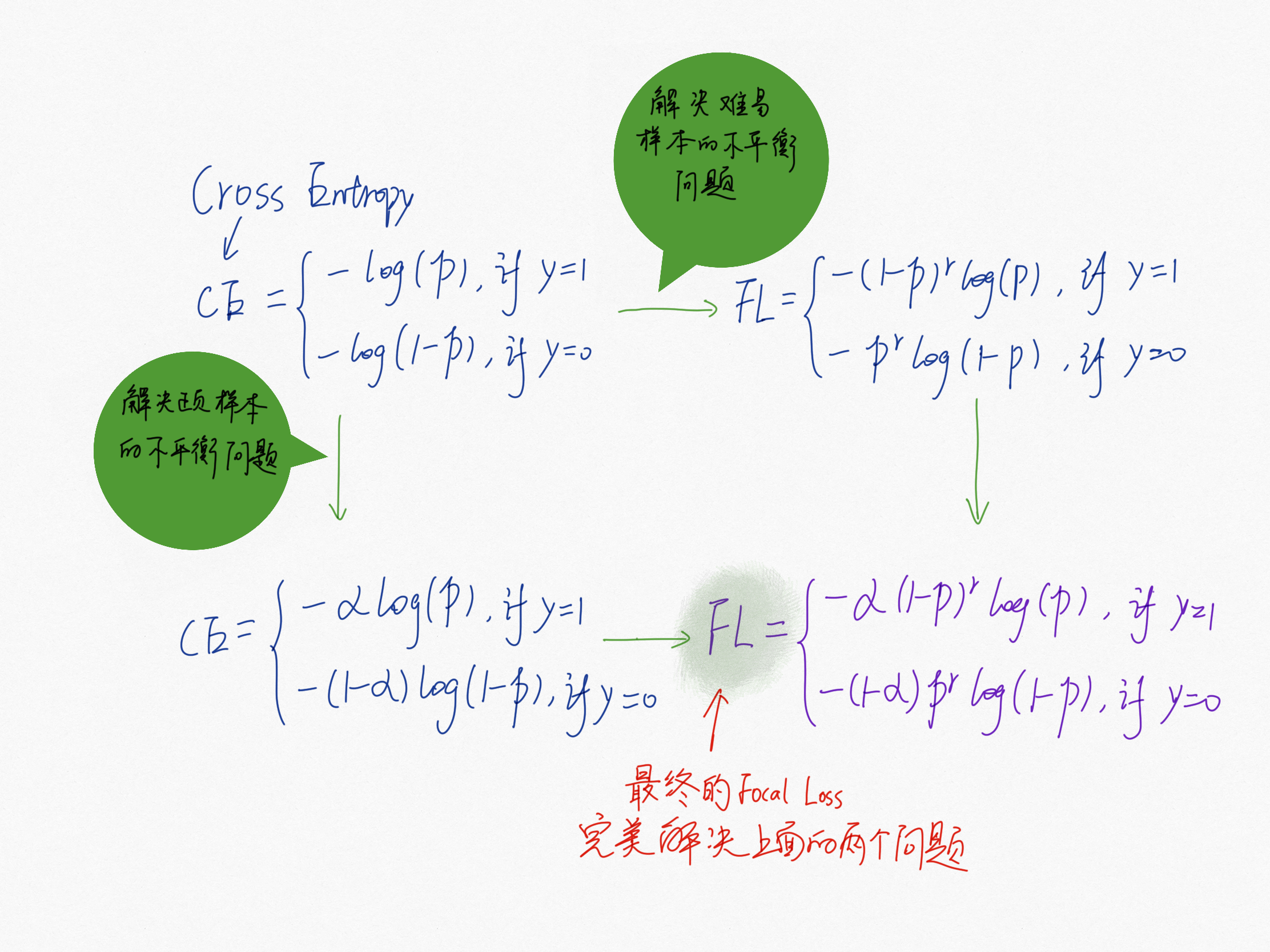
Focal Loss 的提出主要是为了解决难易样本数量不平衡(注意:这有别于正负样本数量不均衡问题)问题。下面以目标检测应用场景来说明。
一些 one-stage 的目标检测器通常会产生很多数量的 anchor box,但是只有极少数是正样本,导致正负样本数量不均衡。这里假设我们计算分类损失函数为交叉熵公式。
由于在目标检测中,大量的候选目标都是易分样本,这些样本的损失很低,但是由于数量极不平衡,易分样本数量相对来说太多,最终主导了总的损失,但是模型也应该关注那些难分样本(难分样本又分为普通难分样本和特别难分样本,后面即将讲到的GHM就是为了解决特别难分样本的问题)。
基于以上两个场景中的问题,Focal Loss 给出了很好的解决方法:
GHM
Focal Loss存在一些问题:
- 如果让模型过多关注
难分样本会引发一些问题,比如样本中的离群点(outliers),已经收敛的模型可能会因为这些离群点还是被判别错误,总而言之,我们不应该过多关注易分样本,但也不应该过多关注难分样本; - \(\alpha\) 与 \(\gamma\) 的取值全从实验得出,且两者要联合一起实验,因为它们的取值会相互影响。
几个概念:
梯度模长g:\(g\) 正比于检测的难易程度,\(g\) 越大则检测难度越大,\(g\) 从交叉熵损失求梯度得来
\[
g=|p-p^*|=
\begin{cases}
1-p, & \text{if p* = 1} \\
p, & \text{if p* = 0}
\end{cases}
\]
\(p\) 是模型预测的概率,\(p^*\) 是 Ground-Truth 的标签(取值为1或者0);\(g\) 正比于检测的难易程度,\(g\) 越大则检测难度越大;
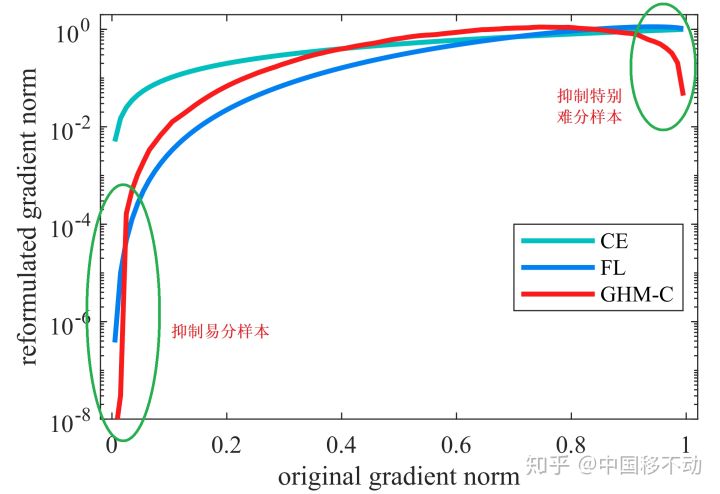
梯度模长与样本数量的关系:梯度模长接近于 0 时样本数量最多(这些可归类为易分样本),随着梯度模长的增长,样本数量迅速减少,但是当梯度模长接近于 1 时样本数量也挺多(这些可归类为难分样本)。如果过多关注难分样本,由于其梯度模长比一般样本大很多,可能会降低模型的准确度。因此,要同时抑制易分样本和难分样本!

抑制方法之梯度密度 \(G(D)\): 因为易分样本和特别难分样本数量都要比一般样本多一些,而我们要做的就是衰减
单位区间数量多的那类样本,也就是物理学上的密度概念。
\[
GD(g) = \frac{1}{l_{\epsilon}}\sum_{k=1}^{N}\delta_{\epsilon}(g_k, g)
\]
\(\delta_{\epsilon}(g_k, g)\) 表示样本 \(1 \sim N(样本数量)\) 中,梯度模长分布在 \((g-\frac{\epsilon}{2}, g+\frac{\epsilon}{2} )\) 范围内的样本个数,\(l_{\epsilon}(g)\) 代表了 \((g-\frac{\epsilon}{2}, g+\frac{\epsilon}{2} )\) 区间的长度;最后对每个样本,用交叉熵 \(CE\) \(\times\) 该样本梯度密度的倒数即可。
分类问题的GHM损失:
\[
L_{GHM-C} = \sum_{i=1}^{N}\frac{L_{CE}(p_i, p_i^*)}{GD(g_i)}
\]
回归问题的GHM损失:
\[
L_{GHM-R} = \sum_{i=1}^N \frac{ASL_1(d_i)}{GD(gr_i)}
\]
其中,\(ASL_1(d_i)\) 为修正的 smooth L1 Loss。
抑制效果:
参考资料:
5分钟理解Focal Loss与GHM-解决样本不平衡利器——知乎
【深度学习】Focal Loss 与 GHM——解决样本不平衡问题的更多相关文章
- 焦点损失函数 Focal Loss 与 GHM
文章来自公众号[机器学习炼丹术] 1 focal loss的概述 焦点损失函数 Focal Loss(2017年何凯明大佬的论文)被提出用于密集物体检测任务. 当然,在目标检测中,可能待检测物体有10 ...
- 从极大似然估计的角度理解深度学习中loss函数
从极大似然估计的角度理解深度学习中loss函数 为了理解这一概念,首先回顾下最大似然估计的概念: 最大似然估计常用于利用已知的样本结果,反推最有可能导致这一结果产生的参数值,往往模型结果已经确定,用于 ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 深度学习中loss总结
一.分类损失 1.交叉熵损失函数 公式: 交叉熵的原理 交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近.假设概率分布p为期望输出,概率分布q为实际输 ...
- 论文阅读|Focal loss
原文标题:Focal Loss for Dense Object Detection 概要 目标检测主要有两种主流框架,一级检测器(one-stage)和二级检测器(two-stage),一级检测器, ...
- 处理样本不平衡的LOSS—Focal Loss
0 前言 Focal Loss是为了处理样本不平衡问题而提出的,经时间验证,在多种任务上,效果还是不错的.在理解Focal Loss前,需要先深刻理一下交叉熵损失,和带权重的交叉熵损失.然后我们从样本 ...
- Focal Loss 损失函数简述
Focal Loss 摘要 Focal Loss目标是解决样本类别不平衡以及样本分类难度不平衡等问题,如目标检测中大量简单的background,很少量较难的foreground样本.Focal Lo ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
随机推荐
- gradle引jar包,引工程
gradle引jar包有直接引mvn仓库的,也有引本地的,引本地jar包需要: compile files("xxxxxx.jar")
- Spring学习之旅(十三)--使用NoSQL数据库
除了关系型数据库之外,现在还有一种 NoSQL 数据库非常流行,而 Spring 自然也没有放过对它的支持. NoSQL 数据库有很多种,如: MongoDBGenericJackson2JsonRe ...
- CocosBuilder 学习笔记(1) CCBReader 解析.ccbi文件流程
1. 简介 CocosBuilder是免费开源的Cocos2d UI编辑器. .ccb文件是CCB项目的原始文件. .ccbi文件是CCB项目发布后的生成的二进制文件.CCBReader可以快速通过该 ...
- MSIL实用指南-返回结果
一个方法体执行完指令后,必须要完成调用并返回,这是要使用Ret指令.Ret指令的详细解释是从当前方法返回,并将返回值(如果存在)从被调用方的计算堆栈推送到调用方的计算堆栈上.就是说如果计算堆栈上没有变 ...
- Asp.net之MsChart控件动态绑定温度曲线图
<div> <div style="position: absolute; z-index: 200; background-color: #FFFFFF; height: ...
- 机器学习性能度量指标:ROC曲线、查准率、查全率、F1
错误率 在常见的具体机器学习算法模型中,一般都使用错误率来优化loss function来保证模型达到最优. \[错误率=\frac{分类错误的样本}{样本总数}\] \[error=\frac{1} ...
- JavaScript label语句
使用label 语句可以在代码中添加标签,以便将来使用. 以下是label 语句的语法: label: statement 下面是一个示例: start: for (var i=0; i < c ...
- [python]通过微信公众号“Python程序员”,编写python代码
今天发现微信公众号中,居然可以编写python代码,很是惊喜,觉得蛮有趣的. 步骤如下: 1.关注微信公众号“Python程序员” 2.关注成功后,点击右下角的“潘多拉”->"Pyth ...
- POJ - 3436 ACM Computer Factory 网络流
POJ-3436:http://poj.org/problem?id=3436 题意 组配计算机,每个机器的能力为x,只能处理一定条件的计算机,能输出特定的计算机配置.进去的要求有1,进来的计算机这个 ...
- CodeForces - 534B-Covered Path+思路
CodeForces - 534B 题意:给定初始和末尾的速度,和最大加速度和总时间,求出走的最长路程: 我一开始以为代码写起来会很繁琐... #include <iostream> #i ...