numba,让python速度提升百倍
python由于它动态解释性语言的特性,跑起代码来相比java、c++要慢很多,尤其在做科学计算的时候,十亿百亿级别的运算,让python的这种劣势更加凸显。
办法永远比困难多,numba就是解决python慢的一大利器,可以让python的运行速度提升上百倍!

什么是numba?
numba是一款可以将python函数编译为机器代码的JIT编译器,经过numba编译的python代码(仅限数组运算),其运行速度可以接近C或FORTRAN语言。
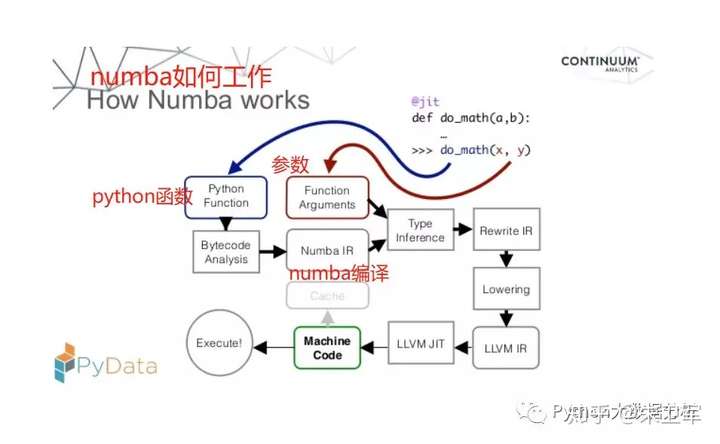
python之所以慢,是因为它是靠CPython编译的,numba的作用是给python换一种编译器。
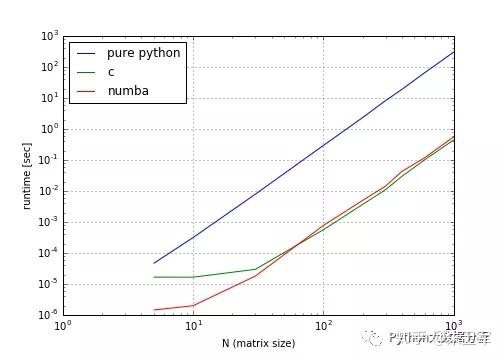
python、c、numba三种编译器速度对比
使用numba非常简单,只需要将numba装饰器应用到python函数中,无需改动原本的python代码,numba会自动完成剩余的工作。
import numpy as np
import numba
from numba import jit @jit(nopython=True) # jit,numba装饰器中的一种
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i])
return a + trace
以上代码是一个python函数,用以计算numpy数组各个数值的双曲正切值,我们使用了numba装饰器,它将这个python函数编译为等效的机器代码,可以大大减少运行时间。
numba适合科学计算
numpy是为面向numpy数组的计算任务而设计的。
在面向数组的计算任务中,数据并行性对于像GPU这样的加速器是很自然的。Numba了解NumPy数组类型,并使用它们生成高效的编译代码,用于在GPU或多核CPU上执行。特殊装饰器还可以创建函数,像numpy函数那样在numpy数组上广播。
什么情况下使用numba呢?
- 使用numpy数组做大量科学计算时
- 使用for循环时
学习使用numba
第一步:导入numpy、numba及其编译器
import numpy as np
import numba
from numba import jit
第二步:传入numba装饰器jit,编写函数
# 传入jit,numba装饰器中的一种
@jit(nopython=True)
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i]) # numba喜欢numpy函数
return a + trace # numba喜欢numpy广播
nopython = True选项要求完全编译该函数(以便完全删除Python解释器调用),否则会引发异常。这些异常通常表示函数中需要修改的位置,以实现优于Python的性能。强烈建议您始终使用nopython = True。
# 因为函数要求传入的参数是nunpy数组
x = np.arange(100).reshape(10, 10)
# 执行函数
go_fast(x)
第四步:经numba加速的函数执行时间
% timeit go_fast(x)
输出:3.63 µs ± 156 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
第五步:不经numba加速的函数执行时间
def go_fast(a): # 首次调用时,函数被编译为机器代码
trace = 0
# 假设输入变量是numpy数组
for i in range(a.shape[0]): # Numba 擅长处理循环
trace += np.tanh(a[i, i]) # numba喜欢numpy函数
return a + trace # numba喜欢numpy广播 x = np.arange(100).reshape(10, 10)
%timeit go_fast(x)
输出:136 µs ± 1.09 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
结论:
在numba加速下,代码执行时间为3.63微秒/循环。不经过numba加速,代码执行时间为136微秒/循环,两者相比,前者快了40倍。
numba让python飞起来
前面已经对比了numba使用前后,python代码速度提升了40倍,但这还不是最快的。
这次,我们不使用numpy数组,仅用for循环,看看nunba对for循环到底有多钟爱!
# 不使用numba的情况
def t():
x = 0
for i in np.arange(5000):
x += i
return x
%timeit(t())
输出:408 µs ± 9.73 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
# 使用numba的情况
@jit(nopython=True)
def t():
x = 0
for i in np.arange(5000):
x += i
return x
%timeit(t())
输出:1.57 µs ± 53.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
使用numba前后分别是408微秒/循环、1.57微秒/循环,速度整整提升了200多倍!
结语
numba对python代码运行速度有巨大的提升,这极大的促进了大数据时代的python数据分析能力,对数据科学工作者来说,这真是一个lucky tool !
当然numba不会对numpy和for循环以外的python代码有很大帮助,你不要指望numba可以帮你加快从数据库取数,这点它真的做不到哈。
如果大家想要学习更多的python数据分析知识,请关注我的公众号:pydatas
回复:数据分析,可领取《利用python进行数据分析 第二版》电子书

numba,让python速度提升百倍的更多相关文章
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- 如何将 iOS 工程打包速度提升十倍以上
如何将 iOS 工程打包速度提升十倍以上 过慢的编译速度有非常明显的副作用.一方面,程序员在等待打包的过程中可能会分心,比如刷刷朋友圈,看条新闻等等.这种认知上下文的切换会带来很多隐形的时间浪费. ...
- 阿里云maven仓库地址,速度提升100倍
参照:https://www.cnblogs.com/xxt19970908/p/6685777.html maven仓库用过的人都知道,国内有多么的悲催.还好有比较好用的镜像可以使用,尽快记录下来. ...
- 多伦多大学&NVIDIA最新成果:图像标注速度提升10倍!
图像标注速度提升10倍! 这是多伦多大学与英伟达联合公布的一项最新研究:Curve-GCN的应用结果. Curve-GCN是一种高效交互式图像标注方法,其性能优于Polygon-RNN++.在自动模式 ...
- Elasticsearch聚合优化 | 聚合速度提升5倍
https://blog.csdn.net/laoyang360/article/details/79253294 1.聚合为什么慢?大多数时候对单个字段的聚合查询还是非常快的, 但是当需要同时聚合多 ...
- 从 Webpack 到 Snowpack, 编译速度提升十倍以上——TRPG Engine迁移小记
动机 TRPG Engine经过长久以来的迭代,项目已经显得非常臃肿了.数分钟的全量编译, 每次按下保存都会触发一次10s到1m不等的增量编译让我苦不堪言, 庞大的依赖使其每一次编译都会涉及很多文件和 ...
- 使用 Apache Spark 让 MySQL 查询速度提升 10 倍以上
转: https://coyee.com/article/11012-how-apache-spark-makes-your-slow-mysql-queries-10x-faster-or-more ...
- 数据库 | SQL 诊断优化套路包,套路用的对,速度升百倍
本文出自头条号老王谈运维,转载请说明出处. 前言 在DBA的日常工作中,调整个别性能较差的SQL语句是一项富有挑战性的工作.面对慢SQL,一些DBA会心烦,会沮丧,会束手无措,也会沉着冷静.斗智斗勇! ...
- Java动态编译优化——提升编译速度(N倍)
一.前言 最近一直在研究Java8 的动态编译, 并且也被ZipFileIndex$Entry 内存泄漏所困扰,在无意中,看到一个第三方插件的动态编译.并且编译速度是原来的2-3倍.原本打算直接用这个 ...
随机推荐
- 用Python和Pandas以及爬虫技术统计历史天气
背景 最近在计划明年从北京rebase到深圳去,所以最近在看深圳的各个方面.去年在深圳呆过一段时间,印象最深的是,深圳总是突然就下雨,还下好大的雨.对于我这种从小在南方长大但是后面又在北京呆了2年多的 ...
- Excel催化剂开源第38波-json字符串转多个表格结构
作为开发者来说,面对json字符一点不陌生,但对于普通用户来说,更合适的是数据表结构的数据,最好数据已经躺在Excel表格内,不用到处导入导出操作.所以开发者和用户之间是有不同的数据使用思维和需求的. ...
- 哥们,B/S了解吗?——啥玩意,我是敲代码的
了解B/S和C/S 前言:......“学好长时间编程了,JavaSE学完了,前端也简单学了”.....“那你学这么多,讲讲B/S吧”......“B/S?这是个啥玩意?没听过”......“靠,牛逼 ...
- 十九、表添加字段的SQL语句写法
通用式: alter table [表名] add [字段名] 字段属性 default 缺省值 default 是可选参数增加字段: alter table [表名] add 字段名 smallin ...
- 解密Kafka吞吐量高的原因
众所周知kafka的吞吐量比一般的消息队列要高,号称the fastest,那他是如何做到的,让我们从以下几个方面分析一下原因. 生产者(写入数据) 生产者(producer)是负责向Kafka提交数 ...
- Oculus Rift 没有声音的解决方法
If you do not hear any audio when using Rift, please try the following steps: Check the Rift audio s ...
- linux初学者-系统日志(二)
linux初学者-系统日志(二) 先前在(一)中介绍到在不同主机间日志同步的方法,在一台主机上可以看到另一台主机的日志.这里会介绍系统日志方面的一些其他内容. 1.日志的采集格式 在日志的采集中,由图 ...
- 安装win10体验
没事干了,心血来潮弄了个win10专业版. 讲硬盘重新分区了,没办法,原来分的太少了. 使用winpe启动,直接将下载的win10还原到c盘,成功启动,设置的时候让提示输入id,没有啊?研究发现可以先 ...
- springboot-rabbitMQ
作者:纯洁的微笑出处:http://www.ityouknow.com/ 版权所有,欢迎保留原文链接进行转载:) RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息 ...
- PyCharm字体大小调整
1.点击左上角File----settings----keymap----------搜索increase,选中,increase font size--------再选择enter mouse sh ...