Spark 学习笔记之 Streaming Window
Streaming Window:
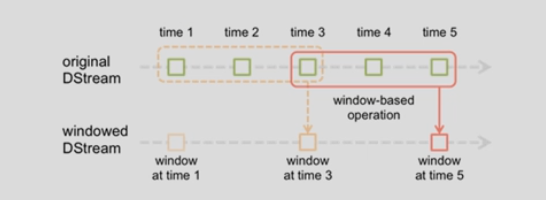
上图意思:每隔2秒统计前3秒的数据
slideDuration: 2
windowDuration: 3
例子:
- import org.apache.kafka.common.serialization.StringDeserializer
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.dstream.DStream
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
- import org.apache.spark.streaming.kafka010.KafkaUtils
- import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
- object WindowStreaming {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("KafkaDirect").setMaster("local[1]")
- val ssc = new StreamingContext(conf, Seconds(1))
- val kafkaMapParams = Map[String, Object](
- "bootstrap.servers" -> "192.168.1.151:9092,192.168.1.152:9092,192.168.1.153:9092",
- "key.deserializer" -> classOf[StringDeserializer],
- "value.deserializer" -> classOf[StringDeserializer],
- "group.id" -> "g1",
- "auto.offset.reset" -> "latest", //earliest|latest
- "enable.auto.commit" -> (false: java.lang.Boolean)
- )
- val topicsSet = Set("ScalaTopic")
- val kafkaStream = KafkaUtils.createDirectStream[String, String](
- ssc,
- PreferConsistent,
- Subscribe[String, String](topicsSet, kafkaMapParams)
- )
- val finalResultRDD: DStream[(Int, String)] = kafkaStream.flatMap(row => row.value().split(" "))
- .map((_, 1)).reduceByKeyAndWindow((x: Int, y: Int) => x + y, Seconds(3), Seconds(2))
- .transform(rdd => rdd.map(tuple => (tuple._2, tuple._1))
- .sortByKey(false).map(tuple => (tuple._1, tuple._2))
- )
- finalResultRDD.print()
- ssc.start()
- ssc.awaitTermination()
- }
- }
运行结果:

Spark 学习笔记之 Streaming Window的更多相关文章
- Spark 学习笔记之 Streaming和Kafka Direct
Streaming和Kafka Direct: Spark version: 2.2.0 Scala version: 2.11 Kafka version: 0.11.0.0 Note: 最新版本感 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
随机推荐
- hdu6219 Empty Convex Polygons (最大空凸包板子
https://vjudge.net/contest/324256#problem/L 题意:给一堆点,求最大空凸包面积. 思路:枚举凸包左下角点O,dp找出以这个点为起始位置能构成的最大空凸包面积, ...
- CodeForces 982 C Cut 'em all!
Cut 'em all! 题意:求删除了边之后,剩下的每一块联通块他的点数都为偶数,求删除的边最多能是多少. 题解:如果n为奇数,直接返回-1,因为不可能成立.如果n为偶数,随意找一个点DFS建树记录 ...
- Special Judge Ⅱ
Problem Description Q:什么是 Special Judge,Special Judge 的题目有什么不同? A:一个题目可以接受多种正确答案,即有多组解的时候,题目就必须被 Spe ...
- CF940A Points on the line 思维
A. Points on the line time limit per test 1 second memory limit per test 256 megabytes input standar ...
- FZU Tic-Tac-Toe -.- FZU邀请赛 FZU 2283
Problem L Tic-Tac-Toe Accept: 94 Submit: 184Time Limit: 1000 mSec Memory Limit : 262144 KB Pr ...
- SQL Server2008 并发数测试
.Net连接SQL Server2008数据库并发数,在默认情况下是100: 上面日志记录当前连接数991,说实话第一次看到还真以为能达到如此高的并发,后头仔细一看其数值都是间隔10,所以算下来是10 ...
- 关于BFC的一些事
BFC的生成 在实现CSS的布局时,假设我们不知道BFC的话,很多地方我们生成了BFC但是不知道.在布局中,一个元素是block元素还是inline元素是必须要知道的.而BFC就是用来格式化块状元素盒 ...
- String对象为什么不可变
转载:https://www.cnblogs.com/leskang/p/6110631.html 一.什么是不可变对象? As we all know, 在Java中, String类对象是不可变的 ...
- hadoop历史服务的启动与停止
a.配置项(在分布式环境中配置) 1.RPC访问地址 mapreduce.jobhistory.address 2.HTTP访问地址 mapreduce.jobhistory.webapp.addre ...
- Python3实战Spark大数据分析及调度 (网盘分享)
Python3实战Spark大数据分析及调度 搜索QQ号直接加群获取其它学习资料:715301384 部分课程截图: 链接:https://pan.baidu.com/s/12VDmdhN4hr7yp ...