初探内核之《Linux内核设计与实现》笔记上
内核简介
本篇简单介绍内核相关的基本概念。
主要内容:
- 单内核和微内核
- 内核版本号
1. 单内核和微内核
|
原理 |
优势 |
劣势 |
|
|
单内核 |
整个内核都在一个大内核地址空间上运行。 | 1. 简单。 2. 高效:所有内核都在一个大的地址空间上,所以内核各个功能之间的调用和调用函数类似,几乎没有性能开销。 |
一个功能的崩溃会导致整个内核无法使用。 |
|
微内核 |
内核按功能被划分成各个独立的过程。每个过程独立的运行在自己的地址空间上。 | 1. 安全:内核的各种服务独立运行,一种服务挂了不会影响其他服务。 | 内核各个服务之间的调用涉及进程间的通信,比较复杂且效率低。 |
Linux的内核虽然是基于单内核的,但是经过这么多年的发展,也具备微内核的一些特征。(体现了Linux实用至上的原则)
主要有以下特征:
- 支持动态加载内核模块
- 支持对称多处理(SMP)
- 内核可以抢占(preemptive),允许内核运行的任务有优先执行的能力
- 不区分线程和进程
2. 内核版本号
内核的版本号主要有四个数组组成。比如版本号:2.6.26.1 其中,
2 - 主版本号
6 - 从版本号或副版本号
26 - 修订版本号
1 - 稳定版本号
副版本号表示这个版本是稳定版(偶数)还是开发版(奇数),上面例子中的版本号是稳定版。
稳定的版本可用于企业级环境。
修订版本号的升级包括BUG修正,新的驱动以及新的特性的追加。
稳定版本号主要是一些关键性BUG的修改。
内核开发者的准备
在尝试内核开发之前,需要对内核有个整体的了解。
主要内容:
- 获取内核源码
- 内核源码的结构
- 编译内核的方法
- 内核开发的特点
1. 获取内核源码
内核是开源的,所有获取源码特别方便,参照以下的网址,可以通过git或者直接下载压缩好的源码包。
2. 内核源码的结构
| 目录 | 说明 |
| arch | 特定体系结构的代码 |
| block | 块设备I/O层 |
| crypo | 加密API |
| Documentation | 内核源码文档 |
| drivers | 设备驱动程序 |
| firmware | 使用某些驱动程序而需要的设备固件 |
| fs | VFS和各种文件系统 |
| include | 内核头文件 |
| init | 内核引导和初始化 |
| ipc | 进程间通信代码 |
| kernel | 像调度程序这样的核心子系统 |
| lib | 同样内核函数 |
| mm | 内存管理子系统和VM |
| net | 网络子系统 |
| samples | 示例,示范代码 |
| scripts | 编译内核所用的脚本 |
| security | Linux 安全模块 |
| sound | 语音子系统 |
| usr | 早期用户空间代码(所谓的initramfs) |
| tools | 在Linux开发中有用的工具 |
| virt | 虚拟化基础结构 |
3. 编译内核的方法
还未实际尝试过手动编译内核,只是用yum更新过内核。这部分等以后手动编译过再补上。
安装新的内核后,重启时会提示进入哪个内核。当多次安装新的内核后,启动列表会很长(因为有很多版本的内核),显得不是很方便。
下面介绍3种删除那些不用的内核的方法:(是如何安装的就选择相应的删除方法)
3.1 rpm 删除法
rpm -qa | grep kernel* (查找所有linux内核版本)
rpm -e kernel-(想要删除的版本)
3.2 yum 删除法
yum remove kernel-(要删除的版本)
3.3 手动删除
删除/lib/modules/目录下不需要的内核库文件
删除/usr/src/kernel/目录下不需要的内核源码
删除/boot目录下启动的核心档案禾内核映像
更改grub的配置,删除不需要的内核启动列表
4. 内核开发的特点
4.1 无标准C库
为了保证内核的小和高效,内核开发中不能使用C标准库,所以连最常用的printf函数也没有,但是还好有个printk函数来代替。
4.2 使用GNU C,推荐用gcc 4.4或以后的版本来编译内核
因为使用GNU C,所有内核中常使用GNU C中的一些扩展:
4.2.1 内联函数
内联函数在编译时会在它被调用的地方展开,减少了函数调用的开销,性能较好。但是,频繁的使用内联函数也会使代码变长,从而在运行时占用更多的内存。
所以内联函数使用时最好要满足以下几点:函数较小,会被反复调用,对程序的时间要求比较严格。
内联函数示例:static inline void sample();
4.2.2 内联汇编
内联汇编用于偏近底层或对执行时间严格要求的地方。示例如下:
unsigned int low, high;
asm volatile("rdtsc" : "=a" (low), "=d" (high));
/* low 和 high 分别包含64位时间戳的低32位和高32位 */
4.2.3 分支声明
如果能事先判断一个if语句时经常为真还是经常为假,那么可以用unlikely和likely来优化这段判断的代码。

/* 如果error在绝大多数情况下为0(假) */
if (unlikely(error)) {
/* ... */
} /* 如果success在绝大多数情况下不为0(真) */
if (likely(success)) {
/* ... */
}
4.3 没有内存保护
因为内核是最低层的程序,所以如果内核访问的非法内存,那么整个系统都会挂掉!!所以内核开发的风险比用户程序开发的风险要大。
而且,内核中的内存是不分页的,每用一个字节的内存,物理内存就少一个字节。所以内核中使用内存一定要谨慎。
4.4 不使用浮点数
内核不能完美的支持浮点操作,使用浮点数时,需要人工保存和恢复浮点寄存器及其他一些繁琐的操作。
4.5 内核栈容积小且固定
内核栈的大小有编译内核时决定的,对于不用的体系结构,内核栈的大小虽然不一样,但都是固定的。
查看内核栈大小的方法:
ulimit -a | grep "stack size"
4.6 同步和并发
Linux是多用户的操作系统,所以必须处理好同步和并发操作,防止因竞争而出现死锁。
4.7 可移植性
Linux内核可用于不用的体现结构,支持多种硬件。所以开发时要时刻注意可移植性,尽量使用体系结构无关的代码。
Linux进程
进程是所有操作系统的核心概念,同样在linux上也不例外。
主要内容:
- 进程和线程
- 进程的生命周期
- 进程的创建
- 进程的终止
1. 进程和线程
进程和线程是程序运行时状态,是动态变化的,进程和线程的管理操作(比如,创建,销毁等)都是有内核来实现的。
Linux中的进程于Windows相比是很轻量级的,而且不严格区分进程和线程,线程不过是一种特殊的进程。
所以下面只讨论进程,只有当线程与进程存在不一样的地方时才提一下线程。
进程提供2种虚拟机制:虚拟处理器和虚拟内存
每个进程有独立的虚拟处理器和虚拟内存,
每个线程有独立的虚拟处理器,同一个进程内的线程有可能会共享虚拟内存。
内核中进程的信息主要保存在task_struct中(include/linux/sched.h)
进程标识PID和线程标识TID对于同一个进程或线程来说都是相等的。
Linux中可以用ps命令查看所有进程的信息:
ps -eo pid,tid,ppid,comm
2. 进程的生命周期
进程的各个状态之间的转化构成了进程的整个生命周期。

3. 进程的创建
Linux中创建进程与其他系统有个主要区别,Linux中创建进程分2步:fork()和exec()。
fork: 通过拷贝当前进程创建一个子进程
exec: 读取可执行文件,将其载入到内存中运行
创建的流程:
- 调用dup_task_struct()为新进程分配内核栈,task_struct等,其中的内容与父进程相同。
- check新进程(进程数目是否超出上限等)
- 清理新进程的信息(比如PID置0等),使之与父进程区别开。
- 新进程状态置为 TASK_UNINTERRUPTIBLE
- 更新task_struct的flags成员。
- 调用alloc_pid()为新进程分配一个有效的PID
- 根据clone()的参数标志,拷贝或共享相应的信息
- 做一些扫尾工作并返回新进程指针
创建进程的fork()函数实际上最终是调用clone()函数。
创建线程和进程的步骤一样,只是最终传给clone()函数的参数不同。
比如,通过一个普通的fork来创建进程,相当于:clone(SIGCHLD, 0)
创建一个和父进程共享地址空间,文件系统资源,文件描述符和信号处理程序的进程,即一个线程:clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0)
在内核中创建的内核线程与普通的进程之间还有个主要区别在于:内核线程没有独立的地址空间,它们只能在内核空间运行。
这与之前提到的Linux内核是个单内核有关。
4. 进程的终止
和创建进程一样,终结一个进程同样有很多步骤:
子进程上的操作(do_exit)
- 设置task_struct中的标识成员设置为PF_EXITING
- 调用del_timer_sync()删除内核定时器, 确保没有定时器在排队和运行
- 调用exit_mm()释放进程占用的mm_struct
- 调用sem__exit(),使进程离开等待IPC信号的队列
- 调用exit_files()和exit_fs(),释放进程占用的文件描述符和文件系统资源
- 把task_struct的exit_code设置为进程的返回值
- 调用exit_notify()向父进程发送信号,并把自己的状态设为EXIT_ZOMBIE
- 切换到新进程继续执行
子进程进入EXIT_ZOMBIE之后,虽然永远不会被调度,关联的资源也释放掉了,但是它本身占用的内存还没有释放,
比如创建时分配的内核栈,task_struct结构等。这些由父进程来释放。
父进程上的操作(release_task)
父进程受到子进程发送的exit_notify()信号后,将该子进程的进程描述符和所有进程独享的资源全部删除。
从上面的步骤可以看出,必须要确保每个子进程都有父进程,如果父进程在子进程结束之前就已经结束了会怎么样呢?
子进程在调用exit_notify()时已经考虑到了这点。
如果子进程的父进程已经退出了,那么子进程在退出时,exit_notify()函数会先调用forget_original_parent(),然后再调用find_new_reaper()来寻找新的父进程。
find_new_reaper()函数先在当前线程组中找一个线程作为父亲,如果找不到,就让init做父进程。(init进程是在linux启动时就一直存在的)
进程的调度
主要内容:
- 什么是调度
- 调度实现原理
- Linux上调度实现的方法
- 调度相关的系统调用
1. 什么是调度
现在的操作系统都是多任务的,为了能让更多的任务能同时在系统上更好的运行,需要一个管理程序来管理计算机上同时运行的各个任务(也就是进程)。
这个管理程序就是调度程序,它的功能说起来很简单:
- 决定哪些进程运行,哪些进程等待
- 决定每个进程运行多长时间
此外,为了获得更好的用户体验,运行中的进程还可以立即被其他更紧急的进程打断。
总之,调度是一个平衡的过程。一方面,它要保证各个运行的进程能够最大限度的使用CPU(即尽量少的切换进程,进程切换过多,CPU的时间会浪费在切换上);另一方面,保证各个进程能公平的使用CPU(即防止一个进程长时间独占CPU的情况)。
2. 调度实现原理
前面说过,调度功能就是决定哪个进程运行以及进程运行多长时间。
决定哪个进程运行以及运行多长时间都和进程的优先级有关。为了确定一个进程到底能持续运行多长时间,调度中还引入了时间片的概念。
2.1 关于进程的优先级
进程的优先级有2种度量方法,一种是nice值,一种是实时优先级。
nice值的范围是-20~+19,值越大优先级越低,也就是说nice值为-20的进程优先级最大。
实时优先级的范围是0~99,与nice值的定义相反,实时优先级是值越大优先级越高。
实时进程都是一些对响应时间要求比较高的进程,因此系统中有实时优先级高的进程处于运行队列的话,它们会抢占一般的进程的运行时间。
进程的2种优先级会让人不好理解,到底哪个优先级更优先?一个进程同时有2种优先级怎么办?
其实linux的内核早就有了解决办法。
对于第一个问题,到底哪个优先级更优先?
答案是实时优先级高于nice值,在内核中,实时优先级的范围是 0~MAX_RT_PRIO-1 MAX_RT_PRIO的定义参见 include/linux/sched.h
1611 #define MAX_USER_RT_PRIO 100
1612 #define MAX_RT_PRIO MAX_USER_RT_PRIO
nice值在内核中的范围是 MAX_RT_PRIO~MAX_RT_PRIO+40 即 MAX_RT_PRIO~MAX_PRIO
1614 #define MAX_PRIO (MAX_RT_PRIO + 40)
第二个问题,一个进程同时有2种优先级怎么办?
答案很简单,就是一个进程不可能有2个优先级。一个进程有了实时优先级就没有Nice值,有了Nice值就没有实时优先级。
我们可以通过以下命令查看进程的实时优先级和Nice值:(其中RTPRIO是实时优先级,NI是Nice值)
$ ps -eo state,uid,pid,ppid,rtprio,ni,time,comm
S UID PID PPID RTPRIO NI TIME COMMAND
S 0 1 0 - 0 00:00:00 systemd
S 0 2 0 - 0 00:00:00 kthreadd
S 0 3 2 - 0 00:00:00 ksoftirqd/0
S 0 6 2 99 - 00:00:00 migration/0
S 0 7 2 99 - 00:00:00 watchdog/0
S 0 8 2 99 - 00:00:00 migration/1
S 0 10 2 - 0 00:00:00 ksoftirqd/1
S 0 12 2 99 - 00:00:00 watchdog/1
S 0 13 2 99 - 00:00:00 migration/2
S 0 15 2 - 0 00:00:00 ksoftirqd/2
S 0 16 2 99 - 00:00:00 watchdog/2
S 0 17 2 99 - 00:00:00 migration/3
S 0 19 2 - 0 00:00:00 ksoftirqd/3
S 0 20 2 99 - 00:00:00 watchdog/3
S 0 21 2 - -20 00:00:00 cpuset
S 0 22 2 - -20 00:00:00 khelper
2.2 关于时间片
有了优先级,可以决定谁先运行了。但是对于调度程序来说,并不是运行一次就结束了,还必须知道间隔多久进行下次调度。
于是就有了时间片的概念。时间片是一个数值,表示一个进程被抢占前能持续运行的时间。
也可以认为是进程在下次调度发生前运行的时间(除非进程主动放弃CPU,或者有实时进程来抢占CPU)。
时间片的大小设置并不简单,设大了,系统响应变慢(调度周期长);设小了,进程频繁切换带来的处理器消耗。默认的时间片一般是10ms
2.3 调度实现原理(基于优先级和时间片)
下面举个直观的例子来说明:
假设系统中只有3个进程ProcessA(NI=+10),ProcessB(NI=0),ProcessC(NI=-10),NI表示进程的nice值,时间片=10ms
1) 调度前,把进程优先级按一定的权重映射成时间片(这里假设优先级高一级相当于多5msCPU时间)。
假设ProcessA分配了一个时间片10ms,那么ProcessB的优先级比ProcessA高10(nice值越小优先级越高),ProcessB应该分配10*5+10=60ms,以此类推,ProcessC分配20*5+10=110ms
2) 开始调度时,优先调度分配CPU时间多的进程。由于ProcessA(10ms),ProcessB(60ms),ProcessC(110ms)。显然先调度ProcessC
3) 10ms(一个时间片)后,再次调度时,ProcessA(10ms),ProcessB(60ms),ProcessC(100ms)。ProcessC刚运行了10ms,所以变成100ms。此时仍然先调度ProcessC
4) 再调度4次后(4个时间片),ProcessA(10ms),ProcessB(60ms),ProcessC(60ms)。此时ProcessB和ProcessC的CPU时间一样,这时得看ProcessB和ProcessC谁在CPU运行队列的前面,假设ProcessB在前面,则调度ProcessB
5) 10ms(一个时间片)后,ProcessA(10ms),ProcessB(50ms),ProcessC(60ms)。再次调度ProcessC
6) ProcessB和ProcessC交替运行,直至ProcessA(10ms),ProcessB(10ms),ProcessC(10ms)。
这时得看ProcessA,ProcessB,ProcessC谁在CPU运行队列的前面就先调度谁。这里假设调度ProcessA
7) 10ms(一个时间片)后,ProcessA(时间片用完后退出),ProcessB(10ms),ProcessC(10ms)。
8) 再过2个时间片,ProcessB和ProcessC也运行完退出。
这个例子很简单,主要是为了说明调度的原理,实际的调度算法虽然不会这么简单,但是基本的实现原理也是类似的:
1)确定每个进程能占用多少CPU时间(这里确定CPU时间的算法有很多,根据不同的需求会不一样)
2)占用CPU时间多的先运行
3)运行完后,扣除运行进程的CPU时间,再回到 1)
3. Linux上调度实现的方法
Linux上的调度算法是不断发展的,在2.6.23内核以后,采用了“完全公平调度算法”,简称CFS。
CFS算法在分配每个进程的CPU时间时,不是分配给它们一个绝对的CPU时间,而是根据进程的优先级分配给它们一个占用CPU时间的百分比。
比如ProcessA(NI=1),ProcessB(NI=3),ProcessC(NI=6),在CFS算法中,分别占用CPU的百分比为:ProcessA(10%),ProcessB(30%),ProcessC(60%)
因为总共是100%,ProcessB的优先级是ProcessA的3倍,ProcessC的优先级是ProcessA的6倍。
Linux上的CFS算法主要有以下步骤:(还是以ProcessA(10%),ProcessB(30%),ProcessC(60%)为例)
1)计算每个进程的vruntime(注1),通过update_curr()函数更新进程的vruntime。
2)选择具有最小vruntime的进程投入运行。(注2)
3)进程运行完后,更新进程的vruntime,转入步骤2) (注3)
注1. 这里的vruntime是进程虚拟运行的时间的总和。vruntime定义在:kernel/sched_fair.c 文件的 struct sched_entity 中。
注2. 这里有点不好理解,根据vruntime来选择要运行的进程,似乎和每个进程所占的CPU时间百分比没有关系了。
1)比如先运行ProcessC,(vr是vruntime的缩写),则10ms后:ProcessA(vr=0),ProcessB(vr=0),ProcessC(vr=10)
2)那么下次调度只能运行ProcessA或者ProcessB。(因为会选择具有最小vruntime的进程)
长时间来看的话,ProcessA、ProcessB、ProcessC是公平的交替运行的,和优先级没有关系。
而实际上vruntime并不是实际的运行时间,它是实际运行时间进行加权运算后的结果。
比如上面3个进程中ProcessA(10%)只分配了CPU总的处理时间的10%,那么ProcessA运行10ms的话,它的vruntime会增加100ms。
以此类推,ProcessB运行10ms的话,它的vruntime会增加(100/3)ms,ProcessC运行10ms的话,它的vruntime会增加(100/6)ms。
实际的运行时,由于ProcessC的vruntime增加的最慢,所以它会获得最多的CPU处理时间。
上面的加权算法是我自己为了理解方便简化的,Linux对vruntime的加权方法还得去看源码^-^
注3.Linux为了能快速的找到具有最小vruntime,将所有的进程的存储在一个红黑树中。这样树的最左边的叶子节点就是具有最小vruntime的进程,新的进程加入或有旧的进程退出时都会更新这棵树。
其实Linux上的调度器是以模块方式提供的,每个调度器有不同的优先级,所以可以同时存在多种调度算法。
每个进程可以选择自己的调度器,Linux调度时,首先按调度器的优先级选择一个调度器,再选择这个调度器下的进程。
4. 调度相关的系统调用
调度相关的系统调用主要有2类:
1) 与调度策略和进程优先级相关 (就是上面的提到的各种参数,优先级,时间片等等) - 下表中的前8个
2) 与处理器相关 - 下表中的最后3个
|
系统调用 |
描述 |
|
nice() |
设置进程的nice值 |
|
sched_setscheduler() |
设置进程的调度策略,即设置进程采取何种调度算法 |
|
sched_getscheduler() |
获取进程的调度算法 |
|
sched_setparam() |
设置进程的实时优先级 |
|
sched_getparam() |
获取进程的实时优先级 |
|
sched_get_priority_max() |
获取实时优先级的最大值,由于用户权限的问题,非root用户并不能设置实时优先级为99 |
|
sched_get_priority_min() |
获取实时优先级的最小值,理由与上面类似 |
|
sched_rr_get_interval() |
获取进程的时间片 |
|
sched_setaffinity() |
设置进程的处理亲和力,其实就是保存在task_struct中的cpu_allowed这个掩码标志。该掩码的每一位对应一个系统中可用的处理器,默认所有位都被设置,即该进程可以再系统中所有处理器上执行。 用户可以通过此函数设置不同的掩码,使得进程只能在系统中某一个或某几个处理器上运行。 |
|
sched_getaffinity() |
获取进程的处理亲和力 |
|
sched_yield() |
暂时让出处理器 |
系统调用
主要内容:
- 什么是系统调用
- Linux上的系统调用实现原理
- 一个简单的系统调用的实现
1. 什么是系统调用
简单来说,系统调用就是用户程序和硬件设备之间的桥梁。
用户程序在需要的时候,通过系统调用来使用硬件设备。
系统调用的存在,有以下重要的意义:
1)用户程序通过系统调用来使用硬件,而不用关心具体的硬件设备,这样大大简化了用户程序的开发。
比如:用户程序通过write()系统调用就可以将数据写入文件,而不必关心文件是在磁盘上还是软盘上,或者其他存储上。
2)系统调用使得用户程序有更好的可移植性。
只要操作系统提供的系统调用接口相同,用户程序就可在不用修改的情况下,从一个系统迁移到另一个操作系统。
3)系统调用使得内核能更好的管理用户程序,增强了系统的稳定性。
因为系统调用是内核实现的,内核通过系统调用来控制开放什么功能及什么权限给用户程序。
这样可以避免用户程序不正确的使用硬件设备,从而破坏了其他程序。
4)系统调用有效的分离了用户程序和内核的开发。
用户程序只需关心系统调用API,通过这些API来开发自己的应用,不用关心API的具体实现。
内核则只要关心系统调用API的实现,而不必管它们是被如何调用的。
用户程序,系统调用,内核,硬件设备的调用关系如下图:

2. Linux上的系统调用实现原理
要想实现系统调用,主要实现以下几个方面:
- 通知内核调用一个哪个系统调用
- 用户程序把系统调用的参数传递给内核
- 用户程序获取内核返回的系统调用返回值
下面看看Linux是如何实现上面3个功能的。
2.1 通知内核调用一个哪个系统调用
每个系统调用都有一个系统调用号,系统调用发生时,内核就是根据传入的系统调用号来知道是哪个系统调用的。
在x86架构中,用户空间将系统调用号是放在eax中的,系统调用处理程序通过eax取得系统调用号。
系统调用号定义在内核代码:arch/alpha/include/asm/unistd.h 中,可以看出linux的系统调用不是很多。
2.2 用户程序把系统调用的参数传递给内核
系统调用的参数也是通过寄存器传给内核的,在x86系统上,系统调用的前5个参数放在ebx,ecx,edx,esi和edi中,如果参数多的话,还需要用个单独的寄存器存放指向所有参数在用户空间地址的指针。
一般的系统调用都是通过C库(最常用的是glibc库)来访问的,Linux内核提供一个从用户程序直接访问系统调用的方法。
参见内核代码:arch/cris/include/arch-v10/arch/unistd.h
里面定义了6个宏,分别可以调用参数个数为0~6的系统调用
_syscall0(type,name)
_syscall1(type,name,type1,arg1)
_syscall2(type,name,type1,arg1,type2,arg2)
_syscall3(type,name,type1,arg1,type2,arg2,type3,arg3)
_syscall4(type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4)
_syscall5(type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4,type5,arg5)
_syscall6(type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4,type5,arg5,type6,arg6)
超过6个参数的系统调用很罕见,所以这里只定义了6个。
2.3 用户程序获取内核返回的系统调用返回值
获取系统调用的返回值也是通过寄存器,在x86系统上,返回值放在eax中。
3. 一个简单的系统调用的实现
了解了Linux上系统调用的原理,下面就可以自己来实现一个简单的系统调用。
3.1 环境准备
为了不破坏现有系统,我是用虚拟机来实验的。
主机:fedora16 x86_64系统 + kvm(一种虚拟技术,就像virtualbox,vmware等)
虚拟机: 也是安装fedora16 x86_64系统(通过virt-manager很容易安装一个系统)
下载内核源码:www.kernel.org 下载最新的就行
3.2 修改内核源码中的相应文件
主要修改以下文件:
arch/x86/ia32/ia32entry.S
arch/x86/include/asm/unistd_32.h
arch/x86/include/asm/unistd_64.h
arch/x86/kernel/syscall_table_32.S
include/asm-generic/unistd.h
include/linux/syscalls.h
kernel/sys.c
我在sys.c中追加了2个函数:sys_foo和sys_bar
如果是在x86_64的内核中增加一个系统调用,只需修改 arch/x86/include/asm/unistd_64.h,比如sys_bar。
修改内容参见下面的diff文件:
diff -r new/arch/x86/ia32/ia32entry.S old/arch/x86/ia32/ia32entry.S
855d854
< .quad sys_foo
diff -r new/arch/x86/include/asm/unistd_32.h old/arch/x86/include/asm/unistd_32.h
357d356
< #define __NR_foo 349
361c360
< #define NR_syscalls 350
---
> #define NR_syscalls 349
diff -r new/arch/x86/include/asm/unistd_64.h old/arch/x86/include/asm/unistd_64.h
689,692d688
< #define __NR_foo 312
< __SYSCALL(__NR_foo, sys_foo)
< #define __NR_bar 313
< __SYSCALL(__NR_bar, sys_bar)
diff -r new/arch/x86/kernel/syscall_table_32.S old/arch/x86/kernel/syscall_table_32.S
351d350
< .long sys_foo
diff -r new/include/asm-generic/unistd.h old/include/asm-generic/unistd.h
694,695d693
< #define __NR_foo 272
< __SYSCALL(__NR_foo, sys_foo)
698c696
< #define __NR_syscalls 273
---
> #define __NR_syscalls 272
diff -r new/kernel/sys.c old/kernel/sys.c
1920,1928d1919
<
< asmlinkage long sys_foo(void)
< {
< return 1112223334444555;
< }
< asmlinkage long sys_bar(void)
< {
< return 1234567890;
< }
3.3 编译内核
#cd linux-3.2.28
#make menuconfig (选择要编译参数,如果不熟悉内核编译,用默认选项即可)
#make all (这一步真的时间很长......)
#make modules_install
#make install (这一步会把新的内核加到启动项中)
#reboot (重启系统进入新的内核)
3.4 编写调用的系统调用的代码
#include <unistd.h>
#include <sys/syscall.h>
#include <string.h>
#include <stdio.h>
#include <errno.h> #define __NR_foo 312
#define __NR_bar 313 int main()
{
printf ("result foo is %ld\n", syscall(__NR_foo));
printf("%s\n", strerror(errno));
printf ("result bar is %ld\n", syscall(__NR_bar));
printf("%s\n", strerror(errno));
return 0;
}
编译运行上面的代码:
#gcc test.c -o test
#./test
运行结果如下:
result foo is 1112223334444555
Success
result bar is 1234567890
Success
内核数据结构
内核数据结构贯穿于整个内核代码中,这里介绍4个基本的内核数据结构。
利用这4个基本的数据结构,可以在编写内核代码时节约大量时间。
主要内容:
- 链表
- 队列
- 映射
- 红黑树
1. 链表
链表是linux内核中最简单,同时也是应用最广泛的数据结构。
内核中定义的是双向链表。
1.1 头文件简介
内核中关于链表定义的代码位于: include/linux/list.h
list.h文件中对每个函数都有注释,这里就不详细说了。
其实刚开始只要先了解一个常用的链表操作(追加,删除,遍历)的实现方法,
其他方法基本都是基于这些常用操作的。
1.2 链表代码的注意点
在阅读list.h文件之前,有一点必须注意:linux内核中的链表使用方法和一般数据结构中定义的链表是有所不同的。
一般的双向链表一般是如下的结构,
- 有个单独的头结点(head)
- 每个节点(node)除了包含必要的数据之外,还有2个指针(pre,next)
- pre指针指向前一个节点(node),next指针指向后一个节点(node)
- 头结点(head)的pre指针指向链表的最后一个节点
- 最后一个节点的next指针指向头结点(head)
具体见下图:

传统的链表有个最大的缺点就是不好共通化,因为每个node中的data1,data2等等都是不确定的(无论是个数还是类型)。
linux中的链表巧妙的解决了这个问题,linux的链表不是将用户数据保存在链表节点中,而是将链表节点保存在用户数据中。
linux的链表节点只有2个指针(pre和next),这样的话,链表的节点将独立于用户数据之外,便于实现链表的共同操作。
具体见下图:

linux链表中的最大问题是怎样通过链表的节点来取得用户数据?
和传统的链表不同,linux的链表节点(node)中没有包含用户的用户data1,data2等。
整个list.h文件中,我觉得最复杂的代码就是获取用户数据的宏定义
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
这个宏没什么特别的,主要是container_of这个宏
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
这里面的type一般是个结构体,也就是包含用户数据和链表节点的结构体。
ptr是指向type中链表节点的指针
member则是type中定义链表节点是用的名字
比如:
struct student
{
int id;
char* name;
struct list_head list;
};
- type是struct student
- ptr是指向stuct list的指针,也就是指向member类型的指针
- member就是 list
下面分析一下container_of宏:
// 步骤1:将数字0强制转型为type*,然后取得其中的member元素
((type *)0)->member // 相当于((struct student *)0)->list // 步骤2:定义一个临时变量__mptr,并将其也指向ptr所指向的链表节点
const typeof(((type *)0)->member)*__mptr = (ptr); // 步骤3:计算member字段距离type中第一个字段的距离,也就是type地址和member地址之间的差
// offset(type, member)也是一个宏,定义如下:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) // 步骤4:将__mptr的地址 - type地址和member地址之间的差
// 其实也就是获取type的地址
步骤1,2,4比较容易理解,下面的图以sturct student为例进行说明步骤3:
首先需要知道 ((TYPE *)0) 表示将地址0转换为 TYPE 类型的地址
由于TYPE的地址是0,所以((TYPE *)0)->MEMBER 也就是 MEMBER的地址和TYPE地址的差,如下图所示:

1.3 使用示例
构造了一个内核模块来实际使用一下内核中的链表,代码在CentOS6.3 x64上运行通过。
C代码:
#include<linux/init.h>
#include<linux/slab.h>
#include<linux/module.h>
#include<linux/kernel.h>
#include<linux/list.h> MODULE_LICENSE("Dual BSD/GPL");
struct student
{
int id;
char* name;
struct list_head list;
}; void print_student(struct student*); static int testlist_init(void)
{
struct student *stu1, *stu2, *stu3, *stu4;
struct student *stu; // init a list head
LIST_HEAD(stu_head); // init four list nodes
stu1 = kmalloc(sizeof(*stu1), GFP_KERNEL);
stu1->id = 1;
stu1->name = "wyb";
INIT_LIST_HEAD(&stu1->list); stu2 = kmalloc(sizeof(*stu2), GFP_KERNEL);
stu2->id = 2;
stu2->name = "wyb2";
INIT_LIST_HEAD(&stu2->list); stu3 = kmalloc(sizeof(*stu3), GFP_KERNEL);
stu3->id = 3;
stu3->name = "wyb3";
INIT_LIST_HEAD(&stu3->list); stu4 = kmalloc(sizeof(*stu4), GFP_KERNEL);
stu4->id = 4;
stu4->name = "wyb4";
INIT_LIST_HEAD(&stu4->list); // add the four nodes to head
list_add (&stu1->list, &stu_head);
list_add (&stu2->list, &stu_head);
list_add (&stu3->list, &stu_head);
list_add (&stu4->list, &stu_head); // print each student from 4 to 1
list_for_each_entry(stu, &stu_head, list)
{
print_student(stu);
}
// print each student from 1 to 4
list_for_each_entry_reverse(stu, &stu_head, list)
{
print_student(stu);
} // delete a entry stu2
list_del(&stu2->list);
list_for_each_entry(stu, &stu_head, list)
{
print_student(stu);
} // replace stu3 with stu2
list_replace(&stu3->list, &stu2->list);
list_for_each_entry(stu, &stu_head, list)
{
print_student(stu);
} return 0;
} static void testlist_exit(void)
{
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "testlist is exited!\n");
printk(KERN_ALERT "*************************\n");
} void print_student(struct student *stu)
{
printk (KERN_ALERT "======================\n");
printk (KERN_ALERT "id =%d\n", stu->id);
printk (KERN_ALERT "name=%s\n", stu->name);
printk (KERN_ALERT "======================\n");
} module_init(testlist_init);
module_exit(testlist_exit);
Makefile:
obj-m += testlist.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
安装,卸载内核模块以及查看内核模块的运行结果:
insmod testlist.ko
rmmod testlist
dmesg | tail -100
2. 队列
内核中的队列是以字节形式保存数据的,所以获取数据的时候,需要知道数据的大小。
如果从队列中取得数据时指定的大小不对的话,取得数据会不完整或过大。
2.1 头文件简介
内核中关于队列定义的头文件位于:<linux/kfifo.h> include/linux/kfifo.h
头文件中定义的函数的实现位于:kernel/kfifo.c
2.2 队列代码的注意点
内核队列编程需要注意的是:
- 队列的size在初始化时,始终设定为2的n次方
- 使用队列之前将队列结构体中的锁(spinlock)释放
2.3 使用示例
构造了一个内核模块来实际使用一下内核中的队列,代码在CentOS6.3 x64上运行通过。
C代码:
#include "kn_common.h"
MODULE_LICENSE("Dual BSD/GPL");
struct student
{
int id;
char* name;
};
static void print_student(struct student*);
static int testkfifo_init(void)
{
struct kfifo *fifo;
struct student *stu1, *stu2, *stu3, *stu4;
struct student *stu_tmp;
char* c_tmp;
int i;
// !!importent init a unlocked lock
spinlock_t sl = SPIN_LOCK_UNLOCKED;
// init kfifo
fifo = kfifo_alloc(4*sizeof(struct student), GFP_KERNEL, &sl);
stu1 = kmalloc(sizeof(struct student), GFP_KERNEL);
stu1->id = 1;
stu1->name = "wyb1";
kfifo_put(fifo, (char *)stu1, sizeof(struct student));
stu2 = kmalloc(sizeof(struct student), GFP_KERNEL);
stu2->id = 1;
stu2->name = "wyb2";
kfifo_put(fifo, (char *)stu2, sizeof(struct student));
stu3 = kmalloc(sizeof(struct student), GFP_KERNEL);
stu3->id = 1;
stu3->name = "wyb3";
kfifo_put(fifo, (char *)stu3, sizeof(struct student));
stu4 = kmalloc(sizeof(struct student), GFP_KERNEL);
stu4->id = 1;
stu4->name = "wyb4";
kfifo_put(fifo, (char *)stu4, sizeof(struct student));
c_tmp = kmalloc(sizeof(struct student), GFP_KERNEL);
printk(KERN_ALERT "current fifo length is : %d\n", kfifo_len(fifo));
for (i=0; i < 4; i++) {
kfifo_get(fifo, c_tmp, sizeof(struct student));
stu_tmp = (struct student *)c_tmp;
print_student(stu_tmp);
printk(KERN_ALERT "current fifo length is : %d\n", kfifo_len(fifo));
}
printk(KERN_ALERT "current fifo length is : %d\n", kfifo_len(fifo));
kfifo_free(fifo);
kfree(c_tmp);
return 0;
}
static void print_student(struct student *stu)
{
printk(KERN_ALERT "=========================\n");
print_current_time(1);
printk(KERN_ALERT "id = %d\n", stu->id);
printk(KERN_ALERT "name = %s\n", stu->name);
printk(KERN_ALERT "=========================\n");
}
static void testkfifo_exit(void)
{
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "testkfifo is exited!\n");
printk(KERN_ALERT "*************************\n");
}
module_init(testkfifo_init);
module_exit(testkfifo_exit);
其中引用的kn_common.h文件:
#include<linux/init.h>
#include<linux/slab.h>
#include<linux/module.h>
#include<linux/kernel.h>
#include<linux/kfifo.h>
#include<linux/time.h> void print_current_time(int);
kn_common.h对应的kn_common.c:
#include "kn_common.h" void print_current_time(int is_new_line)
{
struct timeval *tv;
struct tm *t;
tv = kmalloc(sizeof(struct timeval), GFP_KERNEL);
t = kmalloc(sizeof(struct tm), GFP_KERNEL); do_gettimeofday(tv);
time_to_tm(tv->tv_sec, 0, t); printk(KERN_ALERT "%ld-%d-%d %d:%d:%d",
t->tm_year + 1900,
t->tm_mon + 1,
t->tm_mday,
(t->tm_hour + 8) % 24,
t->tm_min,
t->tm_sec); if (is_new_line == 1)
printk(KERN_ALERT "\n"); kfree(tv);
kfree(t);
}
Makefile:
obj-m += fifo.o
fifo-objs := testkfifo.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
安装,卸载内核模块以及查看内核模块的运行结果:
insmod fifo.ko
rmmod fifo
dmesg | tail -40
3. 映射
映射的有点想其他语言(C#或者python)中的字典类型,每个唯一的id对应一个自定义的数据结构。
3.1 头文件简介
内核中关于映射定义的头文件位于:<linux/idr.h> include/linux/idr.h
头文件中定义的函数的实现位于:lib/idr.c
3.2 映射代码的注意点
映射的使用需要注意的是,给自定义的数据结构申请一个id的时候,不能直接申请id,先要分配id(函数idr_pre_get),分配成功后,在获取一个id(函数idr_get_new)。
idr的结构比较复杂,我也没有很好的理解,但是csdn上有篇介绍linux idr结构的博客写的挺好,图文并茂:http://blog.csdn.net/paomadi/article/details/8539794
3.3 使用示例
构造了一个内核模块来实际使用一下内核中的映射,代码在CentOS6.3 x64上运行通过。
C代码:
#include<linux/idr.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL");
struct student
{
int id;
char* name;
}; static int print_student(int, void*, void*); static int testidr_init(void)
{
DEFINE_IDR(idp);
struct student *stu[4];
// struct student *stu_tmp;
int id, ret, i; // init 4 struct student
for (i=0; i<4; i++) { stu[i] = kmalloc(sizeof(struct student), GFP_KERNEL);
stu[i]->id = i;
stu[i]->name = "wyb";
} // add 4 student to idr
print_current_time(0);
for (i=0; i < 4; i++) { do {
if (!idr_pre_get(&idp, GFP_KERNEL))
return -ENOSPC;
ret = idr_get_new(&idp, stu[i], &id);
printk(KERN_ALERT "id=%d\n", id);
} while(ret == -EAGAIN);
} // display all student in idr
idr_for_each(&idp, print_student, NULL); idr_destroy(&idp);
kfree(stu[0]);
kfree(stu[1]);
kfree(stu[2]);
kfree(stu[3]);
return 0;
} static int print_student(int id, void *p, void *data)
{
struct student* stu = p; printk(KERN_ALERT "=========================\n");
print_current_time(0);
printk(KERN_ALERT "id = %d\n", stu->id);
printk(KERN_ALERT "name = %s\n", stu->name);
printk(KERN_ALERT "=========================\n"); return 0;
} static void testidr_exit(void)
{
printk(KERN_ALERT "*************************\n");
print_current_time(0);
printk(KERN_ALERT "testidr is exited!\n");
printk(KERN_ALERT "*************************\n");
} module_init(testidr_init);
module_exit(testidr_exit);
注:其中用到的kn_common.h和kn_common.c文件与队列的示例中一样。
Makefile:
obj-m += idr.o
idr-objs := testidr.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
安装,卸载内核模块以及查看内核模块的运行结果:
insmod idr.ko
rmmod idr
dmesg | tail -30
4. 红黑树
红黑树由于节点颜色的特性,保证其是一种自平衡的二叉搜索树。
红黑树的一系列规则虽然实现起来比较复杂,但是遵循起来却比较简单,而且红黑树的插入,删除性能也还不错。
所以红黑树在内核中的应用非常广泛,掌握好红黑树,即有利于阅读内核源码,也可以在自己的代码中借鉴这种数据结构。
红黑树必须满足的规则:
- 所有节点都有颜色,要么红色,要么黑色
- 根节点是黑色,所有叶子节点也是黑色
- 叶子节点中不包含数据
- 非叶子节点都有2个子节点
- 如果一个节点是红色,那么它的父节点和子节点都是黑色的
- 从任何一个节点开始,到其下叶子节点的路径中都包含相同数目的黑节点
红黑树中最长的路径就是红黑交替的路径,最短的路径是全黑节点的路径,再加上根节点和叶子节点都是黑色,
从而可以保证红黑树中最长路径的长度不会超过最短路径的2倍。
4.1 头文件简介
内核中关于红黑树定义的头文件位于:<linux/rbtree.h> include/linux/rbtree.h
头文件中定义的函数的实现位于:lib/rbtree.c
4.2 红黑树代码的注意点
内核中红黑树的使用和链表(list)有些类似,是将红黑树的节点放入自定义的数据结构中来使用的。
首先需要注意的一点是红黑树节点的定义:
struct rb_node
{
unsigned long rb_parent_color;
#define RB_RED 0
#define RB_BLACK 1
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
刚开始看到这个定义的时候,我觉得很奇怪,等到看懂了之后,才知道原来作者巧妙的利用内存对齐来将2个内容存入到一个字段中(不服不行啊^_^!)。
字段 rb_parent_color 中保存了2个信息:
- 父节点的地址
- 本节点的颜色
这2个信息是如何存入一个字段的呢?主要在于 __attribute__((aligned(sizeof(long))));
这行代码的意思就是 struct rb_node 在内存中的地址需要按照4 bytes或者8 bytes对齐。
注:sizeof(long) 在32bit系统中是4 bytes,在64bit系统中是8 bytes
struct rb_node的地址按4 bytes对齐,意味着分配的地址都是4的倍数。
4 的二进制为 100 ,所以申请分配的 struct rb_node 的地址的最后2位始终是零,
struct rb_node 的字段 rb_parent_color 就是利用最后一位来保存节点的颜色信息的。
明白了这点之后,rb_tree.h 中很多宏的定义也就很好懂了。
/* rb_parent_color 保存了父节点的地址和本节点的颜色 */ /* 将 rb_parent_color 的最后2位置成0,即将颜色信息去掉,剩下的就是parent节点的地址 */
#define rb_parent(r) ((struct rb_node *)((r)->rb_parent_color & ~3)) /* 取得 rb_parent_color 二进制表示的最后一位,即用于保存颜色信息的那一位 */
#define rb_color(r) ((r)->rb_parent_color & 1) /* 将 rb_parent_color 二进制表示的最后一位置为0,即置为红色 */
#define rb_set_red(r) do { (r)->rb_parent_color &= ~1; } while (0) /* 将 rb_parent_color 二进制表示的最后一位置为1,即置为黑色 */
#define rb_set_black(r) do { (r)->rb_parent_color |= 1; } while (0)
还有需要重点看的就是rb_tree.c中的5个函数,下面对这5个函数进行一些注释:
函数1:左旋操作,当右子树的长度过大导致树不平衡时,进行左旋操作
/*
* 左旋操作其实就3个动作:见图left
* 1. node的右子树关联到right的左子树
* 2. right的左子树关联到node
* 3. right取代node的位置
* 其他带代码都是一些相应的parent指针的变化
*/
static void __rb_rotate_left(struct rb_node *node, struct rb_root *root)
{
/* 初始化相对于node节点的父节点(图中的P)和右节点(图中的R) */
struct rb_node *right = node->rb_right;
struct rb_node *parent = rb_parent(node); /* 步骤1 */
if ((node->rb_right = right->rb_left))
rb_set_parent(right->rb_left, node); /* 步骤2 */
right->rb_left = node;
rb_set_parent(right, parent); /* node的parent NOT NULL 时,right取代原先的node的位置 */
if (parent)
{
if (node == parent->rb_left)
parent->rb_left = right;
else
parent->rb_right = right;
} /* node的parent NULL 时,说明node原先时root节点,将新的root指向root即可 */
else
root->rb_node = right;
rb_set_parent(node, right);
}
左旋操作图解:

函数2:右旋操作,和左旋操作类似。
函数3:追加节点后,设置此节点的颜色。
/*
* 本函数没有插入节点的功能,只是在插入新节点后,设置新节点的颜色,从而保证红黑树的平衡性。
* 新插入的节点默认都是红色的。
*
* 下面的代码看着复杂,其实只要时时记住红黑树的几个重要特性,就会发现下面的都是在尽量保持住红黑树的这些特性。
* 1. 无论从哪个节点开始,到其叶子节点的路径中包含的黑色节点个数时一样的
* 2. 不能有连续的2个红色节点,即父节点和子节点不能同时为红色
* 所以最简单的情况就是:插入节点的父节点是黑色的。那么插入一个红节点后不会有任何影响。
* 3. 左旋操作有减少右子树高度的作用
* 4. 同理,右旋操作有减少左子树高度的作用
*/
void rb_insert_color(struct rb_node *node, struct rb_root *root)
{
struct rb_node *parent, *gparent; while ((parent = rb_parent(node)) && rb_is_red(parent))
{
gparent = rb_parent(parent); /* parent 是 gparent的左子树时 */
if (parent == gparent->rb_left)
{
{
/* gparent的左右子树的黑色节点都增加一个,仍然平衡 */
register struct rb_node *uncle = gparent->rb_right;
if (uncle && rb_is_red(uncle))
{
rb_set_black(uncle);
rb_set_black(parent);
rb_set_red(gparent);
node = gparent;
continue;
}
} /* node为parent右子树时 */
if (parent->rb_right == node)
{
register struct rb_node *tmp;
/* 左旋后,parent的位置被node取代,然后再交换parent和node的位置,
* 相当于node是parent的左子树
* 由于node和parent都是红色(否则到不了这一步),parent左右子树的黑色节点数仍然是相等的
*/
__rb_rotate_left(parent, root);
tmp = parent;
parent = node;
node = tmp;
} /* parent 红->黑,gparent左子树比右子树多一个黑色节点
* 右旋后,gparent左子树高度减一,减少的节点即parent,减少了一个黑色节点,parent变为新的gparent。
* 所以右旋后,新的gparent的左右子树的黑色节点数再次平衡了
*/
rb_set_black(parent);
rb_set_red(gparent);
__rb_rotate_right(gparent, root);
/* parent 是 gparent的右子树时,和上面的过程类似 */
} else {
{
register struct rb_node *uncle = gparent->rb_left;
if (uncle && rb_is_red(uncle))
{
rb_set_black(uncle);
rb_set_black(parent);
rb_set_red(gparent);
node = gparent;
continue;
}
} if (parent->rb_left == node)
{
register struct rb_node *tmp;
__rb_rotate_right(parent, root);
tmp = parent;
parent = node;
node = tmp;
} rb_set_black(parent);
rb_set_red(gparent);
__rb_rotate_left(gparent, root);
}
} rb_set_black(root->rb_node);
}
函数4:删除一个节点,并且调整删除后各节点的颜色。其中调整节点颜色其实是另一个单独的函数。
/* 删除节点时,如果被删除的节点左子树==NULL或右子树==NULL或左右子树都==NULL
* 那么只要把被删除节点的左子树或右子树直接关联到被删节点的父节点上即可,剩下的就是调整各节点颜色。
* 只有被删节点是黑色才需要调整颜色,因为删除红色节点不影响红黑树的特性。
*
* 被删节点左右子树都存在的情况下,其实就是用中序遍历中被删节点的下一个节点来替代被删节点。
* 代码中的操作只是将各个指针指向新的位置而已。
*/
void rb_erase(struct rb_node *node, struct rb_root *root)
{
struct rb_node *child, *parent;
int color; if (!node->rb_left)
child = node->rb_right;
else if (!node->rb_right)
child = node->rb_left;
else
{
struct rb_node *old = node, *left; /* 寻找中序遍历中被删节点的下一个节点 */
node = node->rb_right;
while ((left = node->rb_left) != NULL)
node = left; /* 替换要删除的节点old */
if (rb_parent(old)) {
if (rb_parent(old)->rb_left == old)
rb_parent(old)->rb_left = node;
else
rb_parent(old)->rb_right = node;
} else
root->rb_node = node; child = node->rb_right;
parent = rb_parent(node);
color = rb_color(node); if (parent == old) {
parent = node;
} else {
if (child)
rb_set_parent(child, parent);
parent->rb_left = child; node->rb_right = old->rb_right;
rb_set_parent(old->rb_right, node);
} node->rb_parent_color = old->rb_parent_color;
node->rb_left = old->rb_left;
rb_set_parent(old->rb_left, node); goto color;
} parent = rb_parent(node);
color = rb_color(node); if (child)
rb_set_parent(child, parent);
if (parent)
{
if (parent->rb_left == node)
parent->rb_left = child;
else
parent->rb_right = child;
}
else
root->rb_node = child; color:
if (color == RB_BLACK)
__rb_erase_color(child, parent, root);
}
函数5:删除一个黑色节点后,重新调整相关节点的颜色。
/* 这里的node就是上面函数中的child,所有node节点的左右子树肯定都是NULL
* 不满足红黑树规则的就是从parent节点开始的子树,只要给从parent开始的子树增加一个黑色节点就行
* 如果从parent节点开始的节点全是黑色,node和parent都继续向上移动
*/
static void __rb_erase_color(struct rb_node *node, struct rb_node *parent,
struct rb_root *root)
{
struct rb_node *other; /* (node不为NULL 且 node是黑色的) 或者 node == NULL */
while ((!node || rb_is_black(node)) && node != root->rb_node)
{
if (parent->rb_left == node)
{
other = parent->rb_right;
if (rb_is_red(other))
{
rb_set_black(other);
rb_set_red(parent);
__rb_rotate_left(parent, root);
other = parent->rb_right;
}
/* 如果从parent节点开始的节点全是黑色,node和parent都继续向上移动 */
if ((!other->rb_left || rb_is_black(other->rb_left)) &&
(!other->rb_right || rb_is_black(other->rb_right)))
{
rb_set_red(other);
node = parent;
parent = rb_parent(node);
}
else
{
if (!other->rb_right || rb_is_black(other->rb_right))
{
rb_set_black(other->rb_left);
rb_set_red(other);
__rb_rotate_right(other, root);
other = parent->rb_right;
}
rb_set_color(other, rb_color(parent));
rb_set_black(parent);
rb_set_black(other->rb_right);
__rb_rotate_left(parent, root);
node = root->rb_node;
break;
}
}
else
{
other = parent->rb_left;
if (rb_is_red(other))
{
rb_set_black(other);
rb_set_red(parent);
__rb_rotate_right(parent, root);
other = parent->rb_left;
}
if ((!other->rb_left || rb_is_black(other->rb_left)) &&
(!other->rb_right || rb_is_black(other->rb_right)))
{
rb_set_red(other);
node = parent;
parent = rb_parent(node);
}
else
{
if (!other->rb_left || rb_is_black(other->rb_left))
{
rb_set_black(other->rb_right);
rb_set_red(other);
__rb_rotate_left(other, root);
other = parent->rb_left;
}
rb_set_color(other, rb_color(parent));
rb_set_black(parent);
rb_set_black(other->rb_left);
__rb_rotate_right(parent, root);
node = root->rb_node;
break;
}
}
}
if (node)
rb_set_black(node);
}
4.3 使用示例
构造了一个内核模块来实际使用一下内核中的红黑树,代码在CentOS6.3 x64上运行通过。
C代码:
#include<linux/rbtree.h>
#include <linux/string.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL");
struct student
{
int id;
char* name;
struct rb_node node;
}; static int insert_student(struct student*, struct rb_root*);
static int remove_student(struct student*, struct rb_root*);
static int display_student(struct rb_root*, int);
static void display_student_from_small(struct rb_node*);
static void display_student_from_big(struct rb_node*);
static void print_student(struct student*); static int testrbtree_init(void)
{
#define N 10
struct rb_root root = RB_ROOT;
struct student *stu[N];
char tmp_name[5] = {'w', 'y', 'b', '0', '\0'};
int i; // init N struct student
for (i=0; i<N; i++)
{
stu[i] = kmalloc(sizeof(struct student), GFP_KERNEL);
stu[i]->id = i;
stu[i]->name = kmalloc(sizeof(char)*5, GFP_KERNEL);
tmp_name[3] = (char)(i+48);
strcpy(stu[i]->name, tmp_name);
// stu_name[3] = (char)(i+48);
stu[i]->node.rb_left = NULL;
stu[i]->node.rb_right = NULL;
} for (i=0; i < N; ++i)
{
printk(KERN_ALERT "id=%d name=%s\n", stu[i]->id, stu[i]->name);
} // add N student to rbtree
print_current_time(0);
for (i=0; i < N; i++)
insert_student(stu[i], &root); // display all students
printk(KERN_ALERT "print from small to big!\n");
display_student(&root, -1);
printk(KERN_ALERT "print from big to small!\n");
display_student(&root, 1); // delete student 8
remove_student(stu[7], &root);
display_student(&root, -1); // free all student
for (i=0; i<N; ++i)
{
kfree(stu[i]->name);
kfree(stu[i]);
} return 0;
} static int insert_student(struct student* stu, struct rb_root* root)
{
struct rb_node* parent;
struct rb_node* tmp_rb;
struct student* tmp_stu; /* first time to insert node */
if (!root->rb_node)
{
root->rb_node = &(stu->node);
rb_set_parent(&(stu->node), NULL);
rb_set_black(&(stu->node));
return 0;
} /* find where to insert node */
tmp_rb = root->rb_node;
while(tmp_rb)
{
parent = tmp_rb;
tmp_stu = rb_entry(tmp_rb, struct student, node); if (tmp_stu->id > stu->id)
tmp_rb = parent->rb_left;
else if (tmp_stu->id < stu->id)
tmp_rb = parent->rb_right;
else
break;
} /* the student's id is already in the rbtree */
if (tmp_rb)
{
printk(KERN_ALERT "this student has been inserted!\n");
return 1;
} if (tmp_stu->id > stu->id)
parent->rb_left = &(stu->node);
else
parent->rb_right = &(stu->node); rb_set_parent(&(stu->node), parent);
rb_insert_color(&(stu->node), root); return 0;
} static int remove_student(struct student* stu, struct rb_root* root)
{
rb_erase(&(stu->node), root); return 0;
} static int display_student(struct rb_root *root, int order)
{
if (!root->rb_node)
return 1;
if (order < 0)
display_student_from_small(root->rb_node);
else
display_student_from_big(root->rb_node); return 0;
} static void display_student_from_small(struct rb_node* node)
{
struct student *tmp_stu; if (node)
{
display_student_from_small(node->rb_left);
tmp_stu = rb_entry(node, struct student, node);
print_student(tmp_stu);
display_student_from_small(node->rb_right);
}
} static void display_student_from_big(struct rb_node* node)
{
struct student *tmp_stu; if (node)
{
display_student_from_big(node->rb_right);
tmp_stu = rb_entry(node, struct student, node);
print_student(tmp_stu);
display_student_from_big(node->rb_left);
}
} static void print_student(struct student* stu)
{
printk(KERN_ALERT "=========================\n");
print_current_time(0);
printk(KERN_ALERT "id=%d\tname=%s\n", stu->id, stu->name);
printk(KERN_ALERT "=========================\n");
} static void testrbtree_exit(void)
{
printk(KERN_ALERT "*************************\n");
print_current_time(0);
printk(KERN_ALERT "testrbtree is exited!\n");
printk(KERN_ALERT "*************************\n"); } module_init(testrbtree_init);
module_exit(testrbtree_exit);
注:其中用到的kn_common.h和kn_common.c文件与队列的示例中一样。
Makefile:
obj-m += rbtree.o
rbtree-objs := testrbtree.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
安装,卸载内核模块以及查看内核模块的运行结果:
insmod rbtree.ko
rmmod rbtree
dmesg | tail -135
中断处理
中断处理一般不是纯软件来实现的,需要硬件的支持。通过对中断的学习有助于更深入的了解系统的一些底层原理,特别是驱动程序的开发。
主要内容:
- 什么是中断
- 中断类型
- 中断相关函数
- 中断处理机制
- 中断控制方法
- 总结
1. 什么是中断
为了提高CPU和外围硬件(硬盘,键盘,鼠标等等)之间协同工作的性能,引入了中断的机制。
没有中断的话,CPU和外围设备之间协同工作可能只有轮询这个方法:CPU定期检查硬件状态,需要处理时就处理,否则就跳过。
当硬件忙碌的时候,CPU很可能会做许多无用功(每次轮询都是跳过不处理)。
中断机制是硬件在需要的时候向CPU发出信号,CPU暂时停止正在进行的工作,来处理硬件请求的一种机制。
2. 中断类型
中断一般分为异步中断(一般由硬件引起)和同步中断(一般由处理器本身引起)。
异步中断:CPU处理中断的时间过长,所以先将硬件复位,使硬件可以继续自己的工作,然后在适当时候处理中断请求中耗时的部分。
举个例子:网卡的工作原理
- 网卡收到数据包后,向CPU发出中断信号,请求处理接收到的数据包
- CPU将收到的数据包拷贝到内存后,即通知网卡继续工作
- 至于数据包拷贝至内存后的处理会在适当的时候进行
这样做避免了处理数据包时间过长导致网卡接收数据包速度变慢。
同步中断:CPU处理完中断请求的所有工作后才反馈硬件
举个例子:系统异常处理(比如运算中的除0操作)
- 应用程序出现异常后,需要内核来处理
- 内核调用相应的异常处理函数来处理异常
- 处理完后终了应用程序或者给出message
同步中断应该处理能很快完成的一种中断。
3. 中断相关函数
实现一个中断,主要需要知道3个函数:
- 注册中断的函数
- 释放中断的函数
- 中断处理程序的声明
3.1 注册中断的函数
位置:<linux/interrupt.h> include/linux/interrupt.h
定义如下:
/*
* irg - 表示要分配的中断号
* handler - 实际的中断处理程序
* flags - 标志位,表示此中断的具有特性
* name - 中断设备名称的ASCII 表示,这些会被/proc/irq和/proc/interrupts文件使用
* dev - 用于共享中断线,多个中断程序共享一个中断线时(共用一个中断号),依靠dev来区别各个中断程序
* 返回值:
* 执行成功:0
* 执行失败:非0
*/
int request_irq(unsigned int irq,
irq_handler_t handler,
unsigned long flags,
const char* name,
void *dev)
3.2 释放中断的函数
定义比较简单:
void free_irq(unsigned int irq, void *dev)
如果不是共享中断线,则直接删除irq对应的中断线。
如果是共享中断线,则判断此中断处理程序是否中断线上的最后一个中断处理程序,
是最后一个中断处理程序 -> 删除中断线和中断处理程序
不是最后一个中断处理程序 -> 删除中断处理程序
3.3 中断处理程序的声明
声明格式如下:
/*
* 中断处理程序的声明
* @irp - 中断处理程序(即request_irq()中handler)关联的中断号
* @dev - 与 request_irq()中的dev一样,表示一个设备的结构体
* 返回值:
* irqreturn_t - 执行成功:IRQ_HANDLED 执行失败:IRQ_NONE
*/
static irqreturn_t intr_handler(int, irq, void *dev)
4. 中断处理机制
中断处理的过程主要涉及3函数:
- do_IRQ 与体系结构有关,对所接收的中断进行应答
- handle_IRQ_event 调用中断线上所有中断处理
- ret_from_intr 恢复寄存器,将内核恢复到中断前的状态
处理流程可以参见书中的图,如下:

5. 中断控制方法
常用的中断控制方法见下表:
|
函数 |
说明 |
| local_irq_disable() | 禁止本地中断传递 |
| local_irq_enable() | 激活本地中断传递 |
| local_irq_save() | 保存本地中断传递的当前状态,然后禁止本地中断传递 |
| local_irq_restore() | 恢复本地中断传递到给定的状态 |
| disable_irq() | 禁止给定中断线,并确保该函数返回之前在该中断线上没有处理程序在运行 |
| disable_irq_nosync() | 禁止给定中断线 |
| enable_irq() | 激活给定中断线 |
| irqs_disabled() | 如果本地中断传递被禁止,则返回非0;否则返回0 |
| in_interrupt() | 如果在中断上下文中,则返回非0;如果在进程上下文中,则返回0 |
| in_irq() | 如果当前正在执行中断处理程序,则返回非0;否则返回0 |
总结
中断处理对处理时间的要求很高,如果一个中断要花费较长时间,那么中断处理一般分为2部分。
上半部只做一些必要的工作后,立即通知硬件继续自己的工作。
中断处理中耗时的部分,也就是下半部的工作,CPU会在适当的时候去完成。
中断下半部的处理
在前一章也提到过,之所以中断会分成上下两部分,是由于中断对时限的要求非常高,需要尽快的响应硬件。
主要内容:
- 中断下半部处理
- 实现中断下半部的机制
- 总结中断下半部的实现
- 中断实现示例
1. 中断下半部处理
那么对于一个中断,如何划分上下两部分呢?哪些处理放在上半部,哪些处理放在下半部?
这里有一些经验可供借鉴:
- 如果一个任务对时间十分敏感,将其放在上半部
- 如果一个任务和硬件有关,将其放在上半部
- 如果一个任务要保证不被其他中断打断,将其放在上半部
- 其他所有任务,考虑放在下半部
2. 实现中断下半部的机制
实现下半部的方法很多,随着内核的发展,产生了一些新的方法,也淘汰了一些旧方法。
目前使用最多的是以下3中方法
- 2.1 软中断
- 2.2 tasklet
- 2.3 工作队列
2.1 软中断
软中断的代码在:kernel/softirq.c
软中断的流程如下:
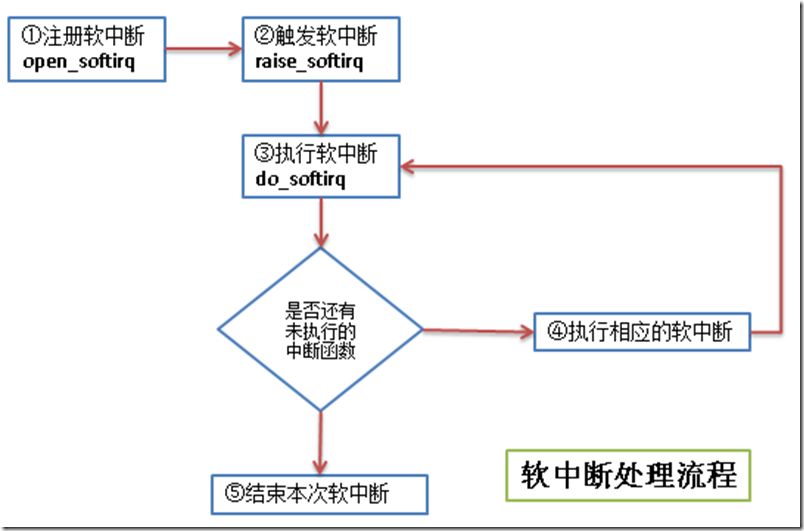
流程图中几个步骤的说明:
① 注册软中断的函数 open_softirq参见 kernel/softirq.c文件)
/*
* 将软中断类型和软中断处理函数加入到软中断序列中
* @nr - 软中断类型
* @(*action)(struct softirq_action *) - 软中断处理的函数指针
*/
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
/* softirq_vec是个struct softirq_action类型的数组 */
softirq_vec[nr].action = action;
}
软中断类型目前有10个,其定义在 include/linux/interrupt.h 文件中:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ NR_SOFTIRQS
};
struct softirq_action 的定义也在 include/linux/interrupt.h 文件中
/*
* 这个结构体的字段是个函数指针,字段名称是action
* 函数指针的返回指是void型
* 函数指针的参数是 struct softirq_action 的地址,其实就是指向 softirq_vec 中的某一项
* 如果 open_softirq 是这样调用的: open_softirq(NET_TX_SOFTIRQ, my_tx_action);
* 那么 my_tx_action 的参数就是 softirq_vec[NET_TX_SOFTIRQ]的地址
*/
struct softirq_action
{
void (*action)(struct softirq_action *);
};
② 触发软中断的函数 raise_softirq 参见 kernel/softirq.c文件
/*
* 触发某个中断类型的软中断
* @nr - 被触发的中断类型
* 从函数中可以看出,在处理软中断前后有保存和恢复寄存器的操作
*/
void raise_softirq(unsigned int nr)
{
unsigned long flags; local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
③ 执行软中断 do_softirq 参见 kernel/softirq.c文件
asmlinkage void do_softirq(void)
{
__u32 pending;
unsigned long flags; /* 判断是否在中断处理中,如果正在中断处理,就直接返回 */
if (in_interrupt())
return; /* 保存当前寄存器的值 */
local_irq_save(flags); /* 取得当前已注册软中断的位图 */
pending = local_softirq_pending(); /* 循环处理所有已注册的软中断 */
if (pending)
__do_softirq(); /* 恢复寄存器的值到中断处理前 */
local_irq_restore(flags);
}
④ 执行相应的软中断 - 执行自己写的中断处理
linux中,执行软中断有专门的内核线程,每个处理器对应一个线程,名称ksoftirqd/n (n对应处理器号)
通过top命令查看我的单核虚拟机,CentOS系统中的ksoftirqd线程如下:
[root@vbox ~]# top | grep ksoftirq
4 root 20 0 0 0 0 S 0.0 0.0 0:00.02 ksoftirqd/0
2.2 tasklet
tasklet也是利用软中断来实现的,但是它提供了比软中断更好用的接口(其实就是基于软中断又封装了一下),
所以除了对性能要求特别高的情况,一般建议使用tasklet来实现自己的中断。
tasklet对应的结构体在 <linux/interrupt.h> 中
struct tasklet_struct
{
struct tasklet_struct *next; /* 链表中的下一个tasklet */
unsigned long state; /* tasklet状态 */
atomic_t count; /* 引用计数器 */
void (*func)(unsigned long); /* tasklet处理函数 */
unsigned long data; /* tasklet处理函数的参数 */
};
tasklet状态只有3种值:
- 值 0 表示该tasklet没有被调度
- 值 TASKLET_STATE_SCHED 表示该tasklet已经被调度
- 值 TASKLET_STATE_RUN 表示该tasklet已经运行
引用计数器count 的值不为0,表示该tasklet被禁止。
tasklet使用流程如下:
1. 声明tasklet (参见<linux/interrupt.h>)
/* 静态声明一个tasklet */
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data } #define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data } /* 动态声明一个tasklet 传递一个tasklet_struct指针给初始化函数 */
extern void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data);
2. 编写处理程序
参照tasklet处理函数的原型来写自己的处理逻辑
void tasklet_handler(unsigned long date)
3. 调度tasklet
中断的上半部处理完后调度tasklet,在适当时候进行下半部的处理
tasklet_schedule(&my_tasklet) /* my_tasklet就是之前声明的tasklet_struct */
2.3 工作队列
工作队列子系统是一个用于创建内核线程的接口,通过它可以创建一个工作者线程来专门处理中断的下半部工作。
工作队列和tasklet不一样,不是基于软中断来实现的。
缺省的工作者线程名称是 events/n (n对应处理器号)。
通过top命令查看我的单核虚拟机,CentOS系统中的events线程如下:
[root@vbox ~]# top | grep event
7 root 20 0 0 0 0 S 0.0 0.0 0:03.71 events/0
工作队列主要用到下面3个结构体,弄懂了这3个结构体的关系,也就知道工作队列的处理流程了。
/* 在 include/linux/workqueue.h 文件中定义 */
struct work_struct {
atomic_long_t data; /* 这个并不是处理函数的参数,而是表示此work是否pending等状态的flag */
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; /* 中断下半部处理函数的链表 */
work_func_t func; /* 处理中断下半部工作的函数 */
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
}; /* 在 kernel/workqueue.c文件中定义
* 每个工作者线程对应一个 cpu_workqueue_struct ,其中包含要处理的工作的链表
* (即 work_struct 的链表,当此链表不空时,唤醒工作者线程来进行处理)
*/
/*
* The per-CPU workqueue (if single thread, we always use the first
* possible cpu).
*/
struct cpu_workqueue_struct { spinlock_t lock; /* 锁保护这种结构 */ struct list_head worklist; /* 工作队列头节点 */
wait_queue_head_t more_work;
struct work_struct *current_work; struct workqueue_struct *wq; /* 关联工作队列结构 */
struct task_struct *thread; /* 关联线程 */
} ____cacheline_aligned; /* 也是在 kernel/workqueue.c 文件中定义的
* 每个 workqueue_struct 表示一种工作者类型,系统默认的就是 events 工作者类型
* 每个工作者类型一般对应n个工作者线程,n就是处理器的个数
*/
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq; /* 工作者线程 */
struct list_head list;
const char *name;
int singlethread;
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
使用工作者队列的方法见下图:

① 创建推后执行的工作 - 有静态创建和动态创建2种方法
/* 静态创建一个work_struct
* @n - work_struct结构体,不用事先定义
* @f - 下半部处理函数
*/
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f) /* 动态创建一个 work_struct
* @_work - 已经定义好的一个 work_struct
* @_func - 下半部处理函数
*/
#ifdef CONFIG_LOCKDEP
#define INIT_WORK(_work, _func) \
do { \
static struct lock_class_key __key; \
\
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
lockdep_init_map(&(_work)->lockdep_map, #_work, &__key, 0);\
INIT_LIST_HEAD(&(_work)->entry); \
PREPARE_WORK((_work), (_func)); \
} while (0)
#else
#define INIT_WORK(_work, _func) \
do { \
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
INIT_LIST_HEAD(&(_work)->entry); \
PREPARE_WORK((_work), (_func)); \
} while (0)
#endif
工作队列处理函数的原型:
typedef void (*work_func_t)(struct work_struct *work);
② 刷新现有的工作,这个步骤不是必须的,可以直接从第①步直接进入第③步
刷新现有工作的意思就是在追加新的工作之前,保证队列中的已有工作已经执行完了。
/* 刷新系统默认的队列,即 events 队列 */
void flush_scheduled_work(void); /* 刷新用户自定义的队列
* @wq - 用户自定义的队列
*/
void flush_workqueue(struct workqueue_struct *wq);
③ 调度工作 - 调度新定义的工作,使之处于等待处理器执行的状态
/* 调度第一步中新定义的工作,在系统默认的工作者线程中执行此工作
* @work - 第一步中定义的工作
*/
schedule_work(struct work_struct *work); /* 调度第一步中新定义的工作,在系统默认的工作者线程中执行此工作
* @work - 第一步中定义的工作
* @delay - 延迟的时钟节拍
*/
int schedule_delayed_work(struct delayed_work *work, unsigned long delay); /* 调度第一步中新定义的工作,在用户自定义的工作者线程中执行此工作
* @wq - 用户自定义的工作队列类型
* @work - 第一步中定义的工作
*/
int queue_work(struct workqueue_struct *wq, struct work_struct *work); /* 调度第一步中新定义的工作,在用户自定义的工作者线程中执行此工作
* @wq - 用户自定义的工作队列类型
* @work - 第一步中定义的工作
* @delay - 延迟的时钟节拍
*/
int queue_delayed_work(struct workqueue_struct *wq,
struct delayed_work *work, unsigned long delay);
3. 总结中断下半部的实现
下面对实现中断下半部工作的3种机制进行总结,便于在实际使用中决定使用哪种机制
|
下半部机制 |
上下文 |
复杂度 |
执行性能 |
顺序执行保障 |
| 软中断 | 中断 | 高 (需要自己确保软中断的执行顺序及锁机制) |
好 (全部自己实现,便于调优) |
没有 |
| tasklet | 中断 | 中 (提供了简单的接口来使用软中断) |
中 | 同类型不能同时执行 |
| 工作队列 | 进程 | 低 (在进程上下文中运行,与写用户程序差不多) |
差 | 没有 (和进程上下文一样被调度) |
4. 中断实现示例
4.1 软中断的实现
本来想用内核模块的方法来测试一下软中断的流程,但是编译时发现软中断注册函数(open_softirq)和触发函数(raise_softirq)
并没有用EXPORT_SYMBOL导出,所以自定义的内核模块中无法使用。
测试的代码如下:
#include <linux/interrupt.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL"); static void my_softirq_func(struct softirq_action*); static int testsoftirq_init(void)
{
// 注册softirq,这里注册的是定时器的下半部
open_softirq(TIMER_SOFTIRQ, my_softirq_func); // 触发softirq
raise_softirq(TIMER_SOFTIRQ); return 0; } static void testsoftirq_exit(void)
{
printk(KERN_ALERT "*************************\n");
print_current_time(0);
printk(KERN_ALERT "testrbtree is exited!\n");
printk(KERN_ALERT "*************************\n"); } static void my_softirq_func(struct softirq_action* act)
{
printk(KERN_ALERT "=========================\n");
print_current_time(0);
printk(KERN_ALERT "my softirq function is been called!....\n");
printk(KERN_ALERT "=========================\n");
} module_init(testsoftirq_init);
module_exit(testsoftirq_exit);
其中头文件 kn_common.h 的相关内容参见之前的博客《Linux内核设计与实现》读书笔记(六)- 内核数据结构
由于内核没有用EXPORT_SYMBOL导出open_softirq和raise_softirq函数,所以编译时有如下警告:
WARNING: "open_softirq" [/root/chap08/mysoftirq.ko] undefined!
WARNING: "raise_softirq" [/root/chap08/mysoftirq.ko] undefined!
注:编译用的系统时centos6.3 (uname -r结果 - 2.6.32-279.el6.x86_64)
没办法,只能尝试修改内核代码(将open_softirq和raise_softirq用EXPORT_SYMBOL导出),再重新编译内核,然后再尝试能否测试软中断。
主要修改2个文件,(既然要修改代码,干脆加了一种软中断类型):
/* 修改 kernel/softirq.c */
// ... 略 ...
char *softirq_to_name[NR_SOFTIRQS] = {
"HI", "TIMER", "NET_TX", "NET_RX", "BLOCK", "BLOCK_IOPOLL",
"TASKLET", "SCHED", "HRTIMER", "RCU", "WYB"
}; /* 追加了一种新的softirq,即 "WYB",我名字的缩写 ^_^ */ // ... 略 ... void raise_softirq(unsigned int nr)
{
unsigned long flags; local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
EXPORT_SYMBOL(raise_softirq); /* 追加的代码 */ void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
EXPORT_SYMBOL(open_softirq); /* 追加的代码 */ // ... 略 ... /* 还修改了 include/linux/interrupt.h */
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ WYB_SOFTIRQS, /* 追加的一种中断类型 */
NR_SOFTIRQS
};
重新编译内核后,在新的内核上再次实验软中断代码:
(编译内核方法参见:《Linux内核设计与实现》读书笔记(五)- 系统调用 3.3节)
测试软中断的代码:testsoftirq.c
#include <linux/interrupt.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL"); static void my_softirq_func(struct softirq_action*); static int testsoftirq_init(void)
{
printk(KERN_ALERT "interrupt's top half!\n"); // 注册softirq,这里注册的是自定义的软中断类型
open_softirq(WYB_SOFTIRQS, my_softirq_func); // 触发softirq
raise_softirq(WYB_SOFTIRQS); return 0; } static void testsoftirq_exit(void)
{
printk(KERN_ALERT "*************************\n");
print_current_time(0);
printk(KERN_ALERT "testsoftirq is exited!\n");
printk(KERN_ALERT "*************************\n"); } static void my_softirq_func(struct softirq_action* act)
{
printk(KERN_ALERT "=========================\n");
print_current_time(0);
printk(KERN_ALERT "my softirq function is been called!....\n");
printk(KERN_ALERT "=========================\n");
} module_init(testsoftirq_init);
module_exit(testsoftirq_exit);
Makefile:
obj-m += mysoftirq.o
mysoftirq-objs := testsoftirq.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
测试软中断的方法如下:
make
insmod mysoftirq.ko
rmmod mysoftirq
dmesg | tail -9 # 运行结果
interrupt's top half!
=========================
2013-4-22 14:4:57
my softirq function is been called!....
=========================
*************************
2013-4-22 14:5:2
testsoftirq is exited!
*************************
4.2 tasklet的实现
tasklet的实验用默认的内核即可,我们切换到centos6.3的默认内核(uname -r: 2.6.32-279.el6.x86_64)
从中我们也可以看出,内核之所以没有导出open_softirq和raise_softirq函数,可能还是因为提倡我们尽量用tasklet来实现中断的下半部工作。
tasklet测试代码:testtasklet.c
#include <linux/interrupt.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL"); static void my_tasklet_func(unsigned long); /* mytasklet 必须定义在testtasklet_init函数的外面,否则会出错 */
DECLARE_TASKLET(mytasklet, my_tasklet_func, 1000); static int testtasklet_init(void)
{
printk(KERN_ALERT "interrupt's top half!\n"); // 如果在这里定义的话,那么 mytasklet是函数的局部变量,
// 后面调度的时候会找不到 mytasklet
// DECLARE_TASKLET(mytasklet, my_tasklet_func, 1000); // 调度tasklet, 处理器会在适当时候执行这个tasklet
tasklet_schedule(&mytasklet); return 0; } static void testtasklet_exit(void)
{
printk(KERN_ALERT "*************************\n");
print_current_time(0);
printk(KERN_ALERT "testtasklet is exited!\n");
printk(KERN_ALERT "*************************\n"); } static void my_tasklet_func(unsigned long data)
{
printk(KERN_ALERT "=========================\n");
print_current_time(0);
printk(KERN_ALERT "my tasklet function is been called!....\n");
printk(KERN_ALERT "parameter data is %ld\n", data);
printk(KERN_ALERT "=========================\n");
} module_init(testtasklet_init);
module_exit(testtasklet_exit);
Makefile:
obj-m += mytasklet.o
mytasklet-objs := testtasklet.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
测试tasklet的方法如下:
make
insmod mytasklet.ko
rmmod mytasklet
dmesg | tail -10 # 运行结果
interrupt's top half!
=========================
2013-4-22 14:53:14
my tasklet function is been called!....
parameter data is 1000
=========================
*************************
2013-4-22 14:53:20
testtasklet is exited!
*************************
4.3 工作队列的实现
workqueue的例子的中静态定义了一个工作,动态定义了一个工作。
静态定义的工作由系统工作队列(events/n)调度,
动态定义的工作由自定义的工作队列(myworkqueue)调度。
测试工作队列的代码:testworkqueue.c
#include <linux/workqueue.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL"); static void my_work_func(struct work_struct *);
static void my_custom_workqueue_func(struct work_struct *); /* 静态创建一个工作,使用系统默认的工作者线程,即 events/n */
DECLARE_WORK(mywork, my_work_func); static int testworkqueue_init(void)
{
/*自定义的workqueue */
struct workqueue_struct *myworkqueue = create_workqueue("myworkqueue"); /* 动态创建一个工作 */
struct work_struct *mywork2;
mywork2 = kmalloc(sizeof(struct work_struct), GFP_KERNEL);
INIT_WORK(mywork2, my_custom_workqueue_func); printk(KERN_ALERT "interrupt's top half!\n"); /* 刷新系统默认的队列 */
flush_scheduled_work();
/* 调度工作 */
schedule_work(&mywork); /* 刷新自定义的工作队列 */
flush_workqueue(myworkqueue);
/* 调度自定义工作队列上的工作 */
queue_work(myworkqueue, mywork2); return 0;
} static void testworkqueue_exit(void)
{
printk(KERN_ALERT "*************************\n");
print_current_time(0);
printk(KERN_ALERT "my workqueue test is exited!\n");
printk(KERN_ALERT "*************************\n"); } static void my_work_func(struct work_struct *work)
{
printk(KERN_ALERT "=========================\n");
print_current_time(0);
printk(KERN_ALERT "my workqueue function is been called!....\n");
printk(KERN_ALERT "=========================\n");
} static void my_custom_workqueue_func(struct work_struct *work)
{
printk(KERN_ALERT "=========================\n");
print_current_time(0);
printk(KERN_ALERT "my cutomize workqueue function is been called!....\n");
printk(KERN_ALERT "=========================\n");
kfree(work);
} module_init(testworkqueue_init);
module_exit(testworkqueue_exit);
Makefile:
obj-m += myworkqueue.o
myworkqueue-objs := testworkqueue.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
测试workqueue的方法如下:
make
insmod myworkqueue.ko
rmmod myworkqueue
dmesg | tail -13 # 运行结果
interrupt's top half!
=========================
2013-4-23 9:55:29
my workqueue function is been called!....
=========================
=========================
2013-4-23 9:55:29
my cutomize workqueue function is been called!....
=========================
*************************
2013-4-23 9:55:29
my workqueue is exited!
*************************
内核同步介绍
存在共享资源(共享一个文件,一块内存等等)的时候,为了防止并发访问时共享资源的数据不一致,引入了同步机制。
主要内容:
- 同步的概念
- 同步的方法-加锁
- 死锁
- 锁的粒度
1. 同步的概念
了解同步之前,先了解另外2个概念:
- 临界区 - 也称为临界段,就是访问和操作共享数据的代码段。
- 竞争条件 - 2个或2个以上线程在临界区里同时执行的时候,就构成了竞争条件。
所谓同步,其实防止在临界区中形成竞争条件。
如果临界区里是原子操作(即整个操作完成前不会被打断),那么自然就不会出竞争条件。
但在实际应用中,临界区中的代码往往不会那么简单,所以为了保持同步,引入了锁机制。
2. 同步的方法-加锁
为了给临界区加锁,保证临界区数据的同步,首先了解一下内核中哪些情况下会产生并发。
内核中造成竞争条件的原因:
|
竞争原因 |
说明 |
| 中断 | 中断随时会发生,也就会随时打断当前执行的代码。如果中断和被打断的代码在相同的临界区,就产生了竞争条件 |
| 软中断和tasklet | 软中断和tasklet也会随时被内核唤醒执行,也会像中断一样打断正在执行的代码 |
| 内核抢占 | 内核具有抢占性,发生抢占时,如果抢占的线程和被抢占的线程在相同的临界区,就产生了竞争条件 |
| 睡眠及用户空间的同步 | 用户进程睡眠后,调度程序会唤醒一个新的用户进程,新的用户进程和睡眠的进程可能在同一个临界区中 |
| 对称多处理 | 2个或多个处理器可以同时执行相同的代码 |
为了在编写内核代码时避免出现竞争条件,在编写代码之前就要考虑好临界区在哪,以及怎么加锁。
在编写完代码后再加锁是非常困难的,很可能还会导致部分代码重写。
编写内核代码时,时时记着下面这些问题:
- 这个数据是不是全局的?除了当前线程以外,其他线程能不能访问它?
- 这个数据会不会在进程上下文或者中断上下文中共享?它是不是要在两个不同的中断处理程序中共享?
- 进程在访问数据时可不可能被抢占?被调度的新程序会不会访问同一数据?
- 当前进程会不会睡眠(或者阻塞)在某些资源上,如果是,它会让共享数据处于何种状态?
- 怎样防止数据失控?
- 如果这个函数又在另一个处理器上被调度将会发生什么?
3. 死锁
死锁就是所有线程都在相互等待释放资源,导致谁也无法继续执行下去。
下面一些简单的规则可以帮助我们避免死锁:
- 如果有多个锁的话,尽量确保每个线程都是按相同的顺序加锁,按加锁相反的顺序解锁。(即加锁a->b->c,解锁c->b->a)
- 防止发生饥饿。即设置一个超时时间,防止一直等待下去。
- 不要重复请求同一个锁。
- 设计应力求简单。加锁的方案越复杂就越容易出现死锁。
4. 锁的粒度
在加锁的时候,不仅要避免死锁,还需要考虑加锁的粒度。
锁的粒度对系统的可扩展性有很大影响,在加锁的时候,要考虑一下这个锁是否会被多个线程频繁的争用。
如果锁有可能会被频繁争用,就需要将锁的粒度细化。
细化后的锁在多处理器的情况下,性能会有所提升。
举个例子说明一下:比如给一个链表加锁,同时有A,B,C 3个线程频繁访问这个链表。
那么当A,B,C 3个线程同时访问这个链表时,如果A获得了锁,那么B,C线程只能等待A释放了锁后才能访问这个链表。
如果A,B,C 3个线程访问的是这个链表的不同节点(比如A是修改节点listA,B是删除节点listB,C是追加节点listC),
并且这3个节点不是连续的,那么3个线程同时运行是不会有问题的。
这种情况下就可以细化这个锁,把加在链表上的锁去掉,改成把锁加在链表的每个节点上。(也就是锁粒度的细化)
那么,上述的情况下,A,B,C 3个线程就可以同时访问各自的节点,特别是在多处理器的情况下,性能会有显著提高。
最后还有一点需要提醒的是,锁的粒度越细,系统开销越大,程序也越复杂,所以对于争用不是很频繁的锁,就没有必要细化了。
内核同步方法
内核中提供了多种方法来防止竞争条件,理解了这些方法的使用场景有助于我们在编写内核代码时选用合适的同步方法,
从而即可保证代码中临界区的安全,同时也让性能的损失降到最低。
主要内容:
- 原子操作
- 自旋锁
- 读写自旋锁
- 信号量
- 读写信号量
- 互斥体
- 完成变量
- 大内核锁
- 顺序锁
- 禁止抢占
- 顺序和屏障
- 总结
1. 原子操作
原子操作是由编译器来保证的,保证一个线程对数据的操作不会被其他线程打断。
原子操作有2类:
- 原子整数操作,有32位和64位。头文件分别为<asm/atomic.h>和<asm/atomic64.h>
- 原子位操作。头文件 <asm/bitops.h>
原子操作的api很简单,参见相应的头文件即可。
原子操作头文件与具体的体系结构有关,比如x86架构的相关头文件在 arch/x86/include/asm/*.h
2. 自旋锁
原子操作只能用于临界区只有一个变量的情况,实际应用中,临界区的情况要复杂的多。
对于复杂的临界区,linux内核中也提供了多种同步方法,自旋锁就是其中一种。
自旋锁的特点就是当一个线程获取了锁之后,其他试图获取这个锁的线程一直在循环等待获取这个锁,直至锁重新可用。
由于线程实在一直循环的获取这个锁,所以会造成CPU处理时间的浪费,因此最好将自旋锁用于能很快处理完的临界区。
自旋锁的实现与体系结构有关,所以相应的头文件 <asm/spinlock.h> 位于相关体系结构的代码中。
自旋锁使用时有2点需要注意:
- 自旋锁是不可递归的,递归的请求同一个自旋锁会自己锁死自己。
- 线程获取自旋锁之前,要禁止当前处理器上的中断。(防止获取锁的线程和中断形成竞争条件)
比如:当前线程获取自旋锁后,在临界区中被中断处理程序打断,中断处理程序正好也要获取这个锁,
于是中断处理程序会等待当前线程释放锁,而当前线程也在等待中断执行完后再执行临界区和释放锁的代码。
中断处理下半部的操作中使用自旋锁尤其需要小心:
- 下半部处理和进程上下文共享数据时,由于下半部的处理可以抢占进程上下文的代码,
所以进程上下文在对共享数据加锁前要禁止下半部的执行,解锁时再允许下半部的执行。 - 中断处理程序(上半部)和下半部处理共享数据时,由于中断处理(上半部)可以抢占下半部的执行,
所以下半部在对共享数据加锁前要禁止中断处理(上半部),解锁时再允许中断的执行。 - 同一种tasklet不能同时运行,所以同类tasklet中的共享数据不需要保护。
- 不同类tasklet中共享数据时,其中一个tasklet获得锁后,不用禁止其他tasklet的执行,因为同一个处理器上不会有tasklet相互抢占的情况
- 同类型或者非同类型的软中断在共享数据时,也不用禁止下半部,因为同一个处理器上不会有软中断互相抢占的情况
自旋锁方法列表如下:
|
方法 |
描述 |
| spin_lock() | 获取指定的自旋锁 |
| spin_lock_irq() | 禁止本地中断并获取指定的锁 |
| spin_lock_irqsave() | 保存本地中断的当前状态,禁止本地中断,并获取指定的锁 |
| spin_unlock() | 释放指定的锁 |
| spin_unlock_irq() | 释放指定的锁,并激活本地中断 |
| spin_unlock_irqstore() | 释放指定的锁,并让本地中断恢复到以前状态 |
| spin_lock_init() | 动态初始化指定的spinlock_t |
| spin_trylock() | 试图获取指定的锁,如果未获取,则返回0 |
| spin_is_locked() | 如果指定的锁当前正在被获取,则返回非0,否则返回0 |
3. 读写自旋锁
- 读写自旋锁除了和普通自旋锁一样有自旋特性以外,还有以下特点:
读锁之间是共享的
即一个线程持有了读锁之后,其他线程也可以以读的方式持有这个锁 - 写锁之间是互斥的
即一个线程持有了写锁之后,其他线程不能以读或者写的方式持有这个锁 - 读写锁之间是互斥的
即一个线程持有了读锁之后,其他线程不能以写的方式持有这个锁
注:读写锁要分别使用,不能混合使用,否则会造成死锁。
正常的使用方法:
DEFINE_RWLOCK(mr_rwlock); read_lock(&mr_rwlock);
/* 临界区(只读).... */
read_unlock(&mr_rwlock); write_lock(&mr_lock);
/* 临界区(读写)... */
write_unlock(&mr_lock);
混合使用时:
/* 获取一个读锁 */
read_lock(&mr_lock);
/* 在获取写锁的时候,由于读写锁之间是互斥的,
* 所以写锁会一直自旋等待读锁的释放,
* 而此时读锁也在等待写锁获取完成后继续下面的代码。
* 因此造成了读写锁的互相等待,形成了死锁。
*/
write_lock(&mr_lock);
读写锁相关文件参照 各个体系结构中的 <asm/rwlock.h>
读写锁的相关函数如下:
|
方法 |
描述 |
| read_lock() | 获取指定的读锁 |
| read_lock_irq() | 禁止本地中断并获得指定读锁 |
| read_lock_irqsave() | 存储本地中断的当前状态,禁止本地中断并获得指定读锁 |
| read_unlock() | 释放指定的读锁 |
| read_unlock_irq() | 释放指定的读锁并激活本地中断 |
| read_unlock_irqrestore() | 释放指定的读锁并将本地中断恢复到指定前的状态 |
| write_lock() | 获得指定的写锁 |
| write_lock_irq() | 禁止本地中断并获得指定写锁 |
| write_lock_irqsave() | 存储本地中断的当前状态,禁止本地中断并获得指定写锁 |
| write_unlock() | 释放指定的写锁 |
| write_unlock_irq() | 释放指定的写锁并激活本地中断 |
| write_unlock_irqrestore() | 释放指定的写锁并将本地中断恢复到指定前的状态 |
| write_trylock() | 试图获得指定的写锁;如果写锁不可用,返回非0值 |
| rwlock_init() | 初始化指定的rwlock_t |
4. 信号量
信号量也是一种锁,和自旋锁不同的是,线程获取不到信号量的时候,不会像自旋锁一样循环的去试图获取锁,
而是进入睡眠,直至有信号量释放出来时,才会唤醒睡眠的线程,进入临界区执行。
由于使用信号量时,线程会睡眠,所以等待的过程不会占用CPU时间。所以信号量适用于等待时间较长的临界区。
信号量消耗的CPU时间的地方在于使线程睡眠和唤醒线程,
如果 (使线程睡眠 + 唤醒线程)的CPU时间 > 线程自旋等待的CPU时间,那么可以考虑使用自旋锁。
信号量有二值信号量和计数信号量2种,其中二值信号量比较常用。
二值信号量表示信号量只有2个值,即0和1。信号量为1时,表示临界区可用,信号量为0时,表示临界区不可访问。
二值信号量表面看和自旋锁很相似,区别在于争用自旋锁的线程会一直循环尝试获取自旋锁,
而争用信号量的线程在信号量为0时,会进入睡眠,信号量可用时再被唤醒。
计数信号量有个计数值,比如计数值为5,表示同时可以有5个线程访问临界区。
信号量相关函数参照: <linux/semaphore.h> 实现方法参照:kernel/semaphore.c
使用信号量的方法如下:
/* 定义并声明一个信号量,名字为mr_sem,用于信号量计数 */
static DECLARE_MUTEX(mr_sem); /* 试图获取信号量...., 信号未获取成功时,进入睡眠
* 此时,线程状态为 TASK_INTERRUPTIBLE
*/
down_interruptible(&mr_sem);
/* 这里也可以用:
* down(&mr_sem);
* 这个方法把线程状态置为 TASK_UNINTERRUPTIBLE 后睡眠
*/ /* 临界区 ... */ /* 释放给定的信号量 */
up(&mr_sem);
一般用的比较多的是down_interruptible()方法,因为以 TASK_UNINTERRUPTIBLE 方式睡眠无法被信号唤醒。
对于 TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE 补充说明一下:
- TASK_INTERRUPTIBLE - 可打断睡眠,可以接受信号并被唤醒,也可以在等待条件全部达成后被显式唤醒(比如wake_up()函数)。
- TASK_UNINTERRUPTIBLE - 不可打断睡眠,只能在等待条件全部达成后被显式唤醒(比如wake_up()函数)。
信号量方法如下:
|
方法 |
描述 |
| sema_init(struct semaphore *, int) | 以指定的计数值初始化动态创建的信号量 |
| init_MUTEX(struct semaphore *) | 以计数值1初始化动态创建的信号量 |
| init_MUTEX_LOCKED(struct semaphore *) | 以计数值0初始化动态创建的信号量(初始为加锁状态) |
| down_interruptible(struct semaphore *) | 以试图获得指定的信号量,如果信号量已被争用,则进入可中断睡眠状态 |
| down(struct semaphore *) | 以试图获得指定的信号量,如果信号量已被争用,则进入不可中断睡眠状态 |
| down_trylock(struct semaphore *) | 以试图获得指定的信号量,如果信号量已被争用,则立即返回非0值 |
| up(struct semaphore *) | 以释放指定的信号量,如果睡眠队列不空,则唤醒其中一个任务 |
信号量结构体具体如下:
/* Please don't access any members of this structure directly */
struct semaphore {
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
可以发现信号量结构体中有个自旋锁,这个自旋锁的作用是保证信号量的down和up等操作不会被中断处理程序打断。
5. 读写信号量
读写信号量和信号量之间的关系 与 读写自旋锁和普通自旋锁之间的关系 差不多。
读写信号量都是二值信号量,即计数值最大为1,增加读者时,计数器不变,增加写者,计数器才减一。
也就是说读写信号量保护的临界区,最多只有一个写者,但可以有多个读者。
读写信号量的相关内容参见:<asm/rwsem.h> 具体实现与硬件体系结构有关。
6. 互斥体
互斥体也是一种可以睡眠的锁,相当于二值信号量,只是提供的API更加简单,使用的场景也更严格一些,如下所示:
- mutex的计数值只能为1,也就是最多只允许一个线程访问临界区
- 在同一个上下文中上锁和解锁
- 不能递归的上锁和解锁
- 持有个mutex时,进程不能退出
- mutex不能在中断或者下半部中使用,也就是mutex只能在进程上下文中使用
- mutex只能通过官方API来管理,不能自己写代码操作它
在面对互斥体和信号量的选择时,只要满足互斥体的使用场景就尽量优先使用互斥体。
在面对互斥体和自旋锁的选择时,参见下表:
|
需求 |
建议的加锁方法 |
| 低开销加锁 | 优先使用自旋锁 |
| 短期锁定 | 优先使用自旋锁 |
| 长期加锁 | 优先使用互斥体 |
| 中断上下文中加锁 | 使用自旋锁 |
| 持有锁需要睡眠 | 使用互斥体 |
互斥体头文件:<linux/mutex.h>
常用的互斥体方法如下:
|
方法 |
描述 |
| mutex_lock(struct mutex *) | 为指定的mutex上锁,如果锁不可用则睡眠 |
| mutex_unlock(struct mutex *) | 为指定的mutex解锁 |
| mutex_trylock(struct mutex *) | 试图获取指定的mutex,如果成功则返回1;否则锁被获取,返回0 |
| mutex_is_locked(struct mutex *) | 如果锁已被争用,则返回1;否则返回0 |
7. 完成变量
完成变量的机制类似于信号量,
比如一个线程A进入临界区之后,另一个线程B会在完成变量上等待,线程A完成了任务出了临界区之后,使用完成变量来唤醒线程B。
完成变量的头文件:<linux/completion.h>
完成变量的API也很简单:
|
方法 |
描述 |
| init_completion(struct completion *) | 初始化指定的动态创建的完成变量 |
| wait_for_completion(struct completion *) | 等待指定的完成变量接受信号 |
| complete(struct completion *) | 发信号唤醒任何等待任务 |
使用完成变量的例子可以参考:kernel/sched.c 和 kernel/fork.c
一般在2个任务需要简单同步的情况下,可以考虑使用完成变量。
8. 大内核锁
大内核锁已经不再使用,只存在与一些遗留的代码中。
9. 顺序锁
顺序锁为读写共享数据提供了一种简单的实现机制。
之前提到的读写自旋锁和读写信号量,在读锁被获取之后,写锁是不能再被获取的,
也就是说,必须等所有的读锁释放后,才能对临界区进行写入操作。
顺序锁则与之不同,读锁被获取的情况下,写锁仍然可以被获取。
使用顺序锁的读操作在读之前和读之后都会检查顺序锁的序列值,如果前后值不符,则说明在读的过程中有写的操作发生,
那么读操作会重新执行一次,直至读前后的序列值是一样的。
do
{
/* 读之前获取 顺序锁foo 的序列值 */
seq = read_seqbegin(&foo);
...
} while(read_seqretry(&foo, seq)); /* 顺序锁foo此时的序列值!=seq 时返回true,反之返回false */
顺序锁优先保证写锁的可用,所以适用于那些读者很多,写者很少,且写优于读的场景。
顺序锁的使用例子可以参考:kernel/timer.c和kernel/time/tick-common.c文件
10. 禁止抢占
其实使用自旋锁已经可以防止内核抢占了,但是有时候仅仅需要禁止内核抢占,不需要像自旋锁那样连中断都屏蔽掉。
这时候就需要使用禁止内核抢占的方法了:
|
方法 |
描述 |
| preempt_disable() | 增加抢占计数值,从而禁止内核抢占 |
| preempt_enable() | 减少抢占计算,并当该值降为0时检查和执行被挂起的需调度的任务 |
| preempt_enable_no_resched() | 激活内核抢占但不再检查任何被挂起的需调度的任务 |
| preempt_count() | 返回抢占计数 |
这里的preempt_disable()和preempt_enable()是可以嵌套调用的,disable和enable的次数最终应该是一样的。
禁止抢占的头文件参见:<linux/preempt.h>
11. 顺序和屏障
对于一段代码,编译器或者处理器在编译和执行时可能会对执行顺序进行一些优化,从而使得代码的执行顺序和我们写的代码有些区别。
一般情况下,这没有什么问题,但是在并发条件下,可能会出现取得的值与预期不一致的情况
比如下面的代码:
/*
* 线程A和线程B共享的变量 a和b
* 初始值 a=1, b=2
*/
int a = 1, b = 2; /*
* 假设线程A 中对 a和b的操作
*/
void Thread_A()
{
a = 5;
b = 4;
} /*
* 假设线程B 中对 a和b的操作
*/
void Thread_B()
{
if (b == 4)
printf("a = %d\n", a);
}
由于编译器或者处理器的优化,线程A中的赋值顺序可能是b先赋值后,a才被赋值。
所以如果线程A中 b=4; 执行完,a=5; 还没有执行的时候,线程B开始执行,那么线程B打印的是a的初始值1。
这就与我们预期的不一致了,我们预期的是a在b之前赋值,所以线程B要么不打印内容,如果打印的话,a的值应该是5。
在某些并发情况下,为了保证代码的执行顺序,引入了一系列屏障方法来阻止编译器和处理器的优化。
|
方法 |
描述 |
| rmb() | 阻止跨越屏障的载入动作发生重排序 |
| read_barrier_depends() | 阻止跨越屏障的具有数据依赖关系的载入动作重排序 |
| wmb() | 阻止跨越屏障的存储动作发生重排序 |
| mb() | 阻止跨越屏障的载入和存储动作重新排序 |
| smp_rmb() | 在SMP上提供rmb()功能,在UP上提供barrier()功能 |
| smp_read_barrier_depends() | 在SMP上提供read_barrier_depends()功能,在UP上提供barrier()功能 |
| smp_wmb() | 在SMP上提供wmb()功能,在UP上提供barrier()功能 |
| smp_mb() | 在SMP上提供mb()功能,在UP上提供barrier()功能 |
| barrier() | 阻止编译器跨越屏障对载入或存储操作进行优化 |
为了使得上面的小例子能正确执行,用上表中的函数修改线程A的函数即可:
/*
* 假设线程A 中对 a和b的操作
*/
void Thread_A()
{
a = 5;
mb();
/*
* mb()保证在对b进行载入和存储值(值就是4)的操作之前
* mb()代码之前的所有载入和存储值的操作全部完成(即 a = 5;已经完成)
* 只要保证a的赋值在b的赋值之前进行,那么线程B的执行结果就和预期一样了
*/
b = 4;
}
12. 总结
本节讨论了大约11种内核同步方法,除了大内核锁已经不再推荐使用之外,其他各种锁都有其适用的场景。
了解了各种同步方法的适用场景,才能正确的使用它们,使我们的代码在安全的保障下达到最优的性能。
同步的目的就是为了保障数据的安全,其实就是保障各个线程之间共享资源的安全,下面根据共享资源的情况来讨论一下10种同步方法的选择。
10种同步方法在图中分别用蓝色框标出。

初探内核之《Linux内核设计与实现》笔记上的更多相关文章
- 【原创】解BUG-xenomai内核与linux内核时间子系统之间存在漂移
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ 一.问题起源 何为漂移?举个例子两颗32.768kH ...
- Android内核和Linux内核的区别
1.Android系统层面的底层是Linux,并且在中间加上了一个叫做Dalvik的Java虚拟机,从表面层看是Android运行库.每个Android应用都运行在自己的进程上,享有Dalvik虚拟机 ...
- 【内核】linux内核启动流程详细分析
Linux内核启动流程 arch/arm/kernel/head-armv.S 该文件是内核最先执行的一个文件,包括内核入口ENTRY(stext)到start_kernel间的初始化代码, 主要作用 ...
- 【内核】linux内核启动流程详细分析【转】
转自:http://www.cnblogs.com/lcw/p/3337937.html Linux内核启动流程 arch/arm/kernel/head-armv.S 该文件是内核最先执行的一个文件 ...
- 内核操作系统Linux内核变迁杂谈——感知市场的力量
本篇文章个人在青岛游玩的时候突然想到的...今天就有想写几篇关于内核操作系统的博客,所以回家到以后就奋笔疾书的写出来发表了 Jack:什么是操作系统? 我:你买了一台笔记本,然后把整块硬盘彻底格式化, ...
- 【内核】Linux内核Initrd机制解析,内核更新步骤,grub配置说明
什么是Initrd initrd的英文含义是 boot loader initialized RAM disk,就是由boot loader初始化的内存盘.在 linux内核启动前, boot loa ...
- Linux内核分析——Linux内核学习总结
马悦+原创作品转载请注明出处+<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 Linux内核学习总结 一 ...
- 《Linux内核--分析Linux内核创建一个新进程的过程 》 20135311傅冬菁
20135311傅冬菁 分析Linux内核创建一个新进程的过程 一.学习内容 进程控制块——PCB task_struct数据结构 PCB task_struct中包含: 进程状态.进程打开的文件. ...
- [内核同步]Linux内核同步机制之completion
转自:http://blog.csdn.net/bullbat/article/details/7401688 内核编程中常见的一种模式是,在当前线程之外初始化某个活动,然后等待该活动的结束.这个活动 ...
- Linux内核分析-Linux内核如何装载和启动一个可执行程序
ID:fuchen1994 实验要求: 理解编译链接的过程和ELF可执行文件格式,详细内容参考本周第一节: 编程使用exec*库函数加载一个可执行文件,动态链接分为可执行程序装载时动态链接和运行时动态 ...
随机推荐
- R语言基础入门
请先安装好R和RStudio 如果不干别的,控制台就是一个内置计算器 2 * 3 #=> 6 sqrt(36) #=> 6, square root log10(100) #=> 2 ...
- 个推TechDay参会感悟
上周六去参加了个推和FCC联合在梦想小镇举办的TechDay,当然是作为台下听讲选手参与的,想上去讲可惜实力他不允许啊,吹牛逼我在行,讲技术可就有点虚了,老老实实的坐在台下听大佬们的分享,当然由于买了 ...
- 1、pytest中文文档--安装和入门
目录 安装和入门 安装pytest 创建你的第一个测试用例 执行多个测试用例 检查代码是否触发一个指定的异常 在一个类中组织多个测试用例 申请一个唯一的临时目录用于功能测试 安装和入门 Python版 ...
- 【Offer】[3-2] 【不修改数组找出重复的数字】
题目描述 思路分析 Java代码 代码链接 题目描述 在一个长度为n+1的数组里的所有数字都在1~n的范围内,所以数组中至少有一个数字是重复的. 请找出数组中任意一个重复的数字,但不能修改输入的数组. ...
- 【LeetCode】34-在排序数组中查找元素的第一个和最后一个位置
题目描述 给定一个按照升序排列的整数数组 nums,和一个目标值 target.找出给定目标值在数组中的开始位置和结束位置. 你的算法时间复杂度必须是 O(log n) 级别. 如果数组中不存在目标值 ...
- 连接池你用对了吗?一次Unexpected end of stream异常的排查
能收获什么? 更加了解TCP协议 Redis与客户端关闭连接的机制 基于Apache Common连接池的参数调优 Linux网络抓包 情况简介 近期迁移了部分应用到K8s中,业务开发人员反馈说,会发 ...
- Mybatis使用入门,这一篇就够了
mybatis中,封装了一个sqlsession 对象(里面封装有connection对象),由此对象来对数据库进行CRUD操作. 运行流程 mybatis有一个配置的xml,用于配置数据源.映射Ma ...
- CSS——段落处理
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 61 (OC)* 代理 block 通知 代理 kvo
1.从源头上理解和区别block和delegate delegate运行成本低,block的运行成本高. block出栈需要将使用的数据从栈内存拷贝到堆内存,当然对象的话就是加计数,使用完或者bloc ...
- Nginx限流
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 在当今流量徒增的互联网时代,很多业务场景都会涉及到高并发.这个时候接口进行限流是非常有必要的,而限流是Ngin ...