Linux中自旋锁
传统的spinlock
Linux的的内核最常见的锁是自旋锁。自旋锁最多只能被一个可执行线程持有。如果一个执行线程试图获得一个被已经持有(争用)的自旋锁,那么该线程就会一直进行忙循环-旋转-等待锁重新可用要是锁未被争用,请求锁的执行线程就可以立即得到它,继续执行。在任意时间,自旋锁都可以防止多于一个的执行线程同时进入临界区。同一个锁可以用在多个位置,例如,对于给定数据的所有访问都可以得到保护和同步。
自旋锁在同一时刻至多被一个执行线程持有,所以一个时刻只有一个线程位于临界区内,这就为多处理器机器提供了防止并发访问所需的保护机制。在单处理机器上,编译的时候不会加入自旋锁,仅会被当作一个设置内核抢占机制是否被启用的开关。如果禁止内核抢占,那么在编译时自旋锁就会被剔除出内核。
传统的自旋锁本质上用一个整数来表示,值为1代表锁未被占用, 为0或者为负数表示被占用。
在单处理机环境中可以使用特定的原子级汇编指令swap和test_and_set实现进程互斥,(Swap指令:交换两个内存单元的内容;test_and_set指令取出内存某一单元(位)的值,然后再给该单元(位)赋一个新值) 这些指令涉及对同一存储单元的两次或两次以上操作,这些操作将在几个指令周期内完成,但由于中断只能发生在两条机器指令之间,而同一指令内的多个指令周期不可中断,从而保证swap指令或test_and_set指令的执行不会交叉进行.
在多处理机环境中情况有所不同,例如test_and_set指令包括“取”、“送”两个指令周期,两个CPU执行test_and_set(lock)可能发生指令周期上的交叉,假如lock初始为0, CPU1和CPU2可能分别执行完前一个指令周期并通过检测(均为0),然后分别执行后一个指令周期将lock设置为1,结果都取回0作为判断临界区空闲的依据,从而不能实现互斥.
为在多CPU环境中利用test_and_set指令实现进程互斥,硬件需要提供进一步的支持,以保证test_and_set指令执行的原子性. 这种支持目前多以“锁总线”(bus locking)的形式提供的,由于test_and_set指令对内存的两次操作都需要经过总线,在执行test_and_set指令之前锁住总线,在执行test_and_set指令后开放总线,即可保证test_and_set指令执行的原子性。
typedef struct {
/**
* 该字段表示自旋锁的状态,值为1表示未加锁,任何负数和0都表示加锁
*/
volatile unsigned int slock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned magic;
#endif
#ifdef CONFIG_PREEMPT
/**
* 表示进程正在忙等待自旋锁。
* 只有内核支持SMP和内核抢占时才使用本标志。
*/
unsigned int break_lock;
#endif
} spinlock_t;
加锁
/**
* 当内核不可抢占时,spin_lock的实现过程。
*/
#define _spin_lock(lock) \
do { \
/**
* 调用preempt_disable禁用抢占。
*/
preempt_disable(); \
/**
* _raw_spin_lock对自旋锁的slock字段执行原子性的测试和设置操作。
*/
_raw_spin_lock(lock); \
__acquire(lock); \
} )
#define _raw_spin_lock(x) \
do { \
CHECK_LOCK(x); \
if ((x)->lock&&(x)->babble) { \
(x)->babble--; \
printk("%s:%d: spin_lock(%s:%p) already locked by %s/%d\n", \
__FILE__,__LINE__, (x)->module, \
(x), (x)->owner, (x)->oline); \
} \
(x)->; \
(x)->owner = __FILE__; \
(x)->oline = __LINE__; \
} )
解锁
#define _spin_unlock(lock) \
do { \
_raw_spin_unlock(lock); \
preempt_enable(); \
__release(lock); \
} )
static inline void _raw_spin_unlock(spinlock_t *lock)
{
#ifdef CONFIG_DEBUG_SPINLOCK
BUG_ON(lock->magic != SPINLOCK_MAGIC);
BUG_ON(!spin_is_locked(lock));
#endif
__asm__ __volatile__(
spin_unlock_string
);
}
//在spin_unlock_string中,%0即为锁 - > s 锁,movb指令将锁 - > s 锁定为1,movb指令本身就是原子操作,所以不需要锁总线。
#define spin_unlock_string \
"movb $1,%0" \
:"=m" (lock->slock) : : "memory"
ticket spinlock
Linux 内核 2.6.25 版本中引入了排队自旋锁:通过保存执行线程申请锁的顺序信息来解决“不公平”问题。
排队自旋锁仍然使用原有的 raw_spinlock_t 数据结构,但是赋予 slock 域新的含义。为了保存顺序信息,slock 域被分成两部分,分别保存锁持有者和未来锁申请者的票据序号(Ticket Number),如下图所示:
只有 Next 域与 Owner 域相等时,才表明锁处于未使用状态(此时也无人申请该锁)。排队自旋锁初始化时 slock 被置为 0,即 Owner 和 Next 置为 0。内核执行线程申请自旋锁时,原子地将 Next 域加 1,并将原值返回作为自己的票据序号。如果返回的票据序号等于申请时的 Owner 值,说明自旋锁处于未使用状态,则直接获得锁;否则,该线程忙等待检查 Owner 域是否等于自己持有的票据序号,一旦相等,则表明锁轮到自己获取。线程释放锁时,原子地将 Owner 域加 1 即可,下一个线程将会发现这一变化,从忙等待状态中退出。线程将严格地按照申请顺序依次获取排队自旋锁,从而完全解决了“不公平”问题。
ticket spinlock数据结构
typedef struct arch_spinlock {
union {
__ticketpair_t head_tail;
struct __raw_tickets {
__ticket_t head, tail;
} tickets;
};
} arch_spinlock_t;
申请自旋锁时,原子地将tail加1,释放时,head加1。只有head域和tail域的值相等时,才表明锁处于未使用的状态。
加锁
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
asm volatile("\n1:\t"
LOCK_PREFIX " ; decb %0\n\t"
"jns 3f\n"
"2:\t"
"rep;nop\n\t"
"cmpb $0,%0\n\t"
"jle 2b\n\t"
"jmp 1b\n"
"3:\n\t"
: "+m" (lock->slock) : : "memory");
}
解锁
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
asm volatile("movb $1,%0" : "+m" (lock->slock) :: "memory");
}
不足:
在大规模多处理器系统和 NUMA系统中,排队自旋锁(包括传统自旋锁)存在一个比较严重的性能问题:由于执行线程均在同一个共享变量 slock 上自旋,申请和释放锁的时候必须对 slock 进行修改,这将导致所有参与排队自旋锁操作的处理器的缓存变得无效。如果排队自旋锁竞争比较激烈的话,频繁的缓存同步操作会导致繁重的系统总线和内存的流量,从而大大降低了系统整体的性能。
mcs spinlock
核心思想是:每个锁的申请者(处理器)只在一个本地变量上自旋。MCS Spinlock是其中一种基于链表结构的自旋锁。
MCS Spinlock的设计目标如下:
- 保证自旋锁申请者以先进先出的顺序获取锁(FIFO Ordering)。
- 只在本地可访问的标志变量上自旋。
- 在处理器个数较少的系统中或锁竞争并不激烈的情况下,保持较高性能。
- 自旋锁的空间复杂度(即锁数据结构和锁操作所需的空间开销)为常数。
- 在没有处理器缓存一致性协议保证的系统中也能很好地工作。
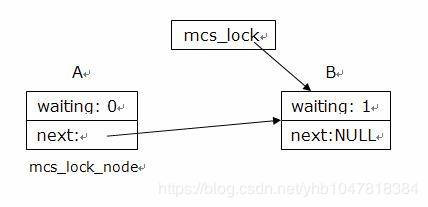
MCS Spinlock采用链表结构将全体锁申请者的信息串成一个单向链表,如图 1 所示。每个锁申请者必须提前分配一个本地结构 mcs_lock_node,其中至少包括 2 个域:本地自旋变量 waiting 和指向下一个申请者 mcs_lock_node 结构的指针变量 next。waiting 初始值为 1,申请者自旋等待其直接前驱释放锁;为 0 时结束自旋。而自旋锁数据结构 mcs_lock 是一个永远指向最后一个申请者 mcs_lock_node 结构的指针,当且仅当锁处于未使用(无任何申请者)状态时为 NULL 值。MCS Spinlock 依赖原子的“交换”(swap)和“比较-交换”(compare_and_swap)操作,缺乏后者的话,MCS Spinlock 就不能保证以先进先出的顺序获取锁,从而可能造成“饥饿”(Starvation)。
版本1:每个锁有NR_CPUS大的node数组, mcs_lock_node 结构可以在处理器所处节点的内存中分配,从而加快访问速度.
typedef struct _mcs_lock_node {
volatile int waiting;
struct _mcs_lock_node *volatile next;
} ____cacheline_aligned_in_smp mcs_lock_node;
typedef mcs_lock_node *volatile mcs_lock;
typedef struct {
mcs_lock slock;
mcs_lock_node nodes[NR_CPUS];
} raw_spinlock_t;
spin_lock(&lock)
spin_unlock(&lock)
版本2:
spin_lock(&lock, &node);
spin_unlock(&lock, &node);
加锁
static __always_inline void __raw_spin_lock(raw_spinlock_t *lock)
{
int cpu;
mcs_lock_node *me;
mcs_lock_node *tmp;
mcs_lock_node *pre;
cpu = raw_smp_processor_id(); (a)
me = &(lock->nodes[cpu]);
tmp = me;
me->next = NULL;
pre = xchg(&lock->slock, tmp); (b)
if (pre == NULL) {
/* mcs_lock is free */
return; (c)
}
me->waiting = ; (d)
smp_wmb(); (e)
pre->next = me; (f)
while (me->waiting) { (g)
asm volatile (“pause”);
}
}
static __always_inline int __raw_spin_trylock(raw_spinlock_t *lock)
{
int cpu;
mcs_lock_node *me;
cpu = raw_smp_processor_id();
me = &(lock->nodes[cpu]);
me->next = NULL;
if (cmpxchg(&lock->slock, NULL, me) == NULL) (a)
;
else
;
}
解锁
static __always_inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
int cpu;
mcs_lock_node *me;
mcs_lock_node *tmp;
cpu = raw_smp_processor_id();
me = &(lock->nodes[cpu]);
tmp = me;
if (me->next == NULL) { (a)
if (cmpxchg(&lock->slock, tmp, NULL) == me) { (b)
/* mcs_lock I am the last. */
return;
}
while (me->next == NULL) (c)
continue;
}
/* mcs_lock pass to next. */
me->next->waiting = ; (d)
}
不足:
版本1的mcs spinlock 锁占用空间大
版本二的mcs spinlock 使用时需要传入mode, 和之前的spinlock api不兼容,无法替换ticket spinlock.
qspinlock
qspinlock 是内核4.2引入的,主要基于mcs spinlock的设计思想,解决了mcs spinlock接口不一致或空间太大的问题。它的数据结构体比mcs lock大大减小, 同ticket spinlock一样大小。qspinlock的等待变量是全局变量。
qspinlock的数据结构定义在kernel/qspinlock.c中
struct __qspinlock {
union {
atomic_t val;
#ifdef __LITTLE_ENDIAN
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
#else
struct {
u16 tail;
u16 locked_pending;
};
struct {
u8 reserved[];
u8 pending;
u8 locked;
};
#endif
具体位域
/* * Bitfields in the atomic value: * * When NR_CPUS < 16K * 0- 7: locked byte * 8: pending * 9-15: not used * 16-17: tail index * 18-31: tail cpu (+1) * * When NR_CPUS >= 16K * 0- 7: locked byte * 8: pending * 9-10: tail index * 11-31: tail cpu (+1) */
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
u32 val;
val = atomic_cmpxchg_acquire(&, _Q_LOCKED_VAL);
))
return;
queued_spin_lock_slowpath(lock, val);
}
qspinlock采用mcs lock的机制, 每一个cpu都定义有一个strcut mcs spinlock的数据结构在大规模多处理器系统和 NUMA系统中, 使用qspinlock 可以较好的提高锁的性能。
Linux中自旋锁的更多相关文章
- linux内核--自旋锁的理解
http://blog.chinaunix.net/uid-20543672-id-3252604.html 自旋锁:如果内核配置为SMP系统,自旋锁就按SMP系统上的要求来实现真正的自旋等待,但是对 ...
- linux内核自旋锁API
我们大概都了解,锁这种机制其实是为了保护临界区代码的,关于使用和定义,我总结的API如下: #include <linux/spinlock.h> 定义自旋锁 spinlock_t loc ...
- LINUX内核笔记:自旋锁
目录 自旋锁作用与基本使用方法? 在SMP和UP上的不同表现? 自旋锁与上下文 使用spin_lock()后为什么不能睡眠? 强调:锁什么? 参考 1.自旋锁作用与基本使用方法? 与其他锁一样,自 ...
- Linux内核同步:自旋锁
linux内核--自旋锁的理解 自旋锁:如果内核配置为SMP系统,自旋锁就按SMP系统上的要求来实现真正的自旋等待,但是对于UP系统,自旋锁仅做抢占和中断操作,没有实现真正的“自旋”.如果配置了CON ...
- linux 自旋锁和信号量【转】
转自:http://blog.csdn.net/xu_guo/article/details/6072823 版权声明:本文为博主原创文章,未经博主允许不得转载. 自旋锁最多只能被一个可执行线程持有( ...
- 浅谈Linux中的各种锁及其基本原理
本文首发于:https://mp.weixin.qq.com/s/Ahb4QOnxvb2RpCJ3o7RNwg 微信公众号:后端技术指南针 0.概述 通过本文将了解到如下内容: Linux系统的并行性 ...
- Linux中的各种锁及其基本原理
Linux中的各种锁及其基本原理 1.概述 通过本文将了解到如下内容: Linux系统的并行性特征 互斥和同步机制 Linux中常用锁的基本特性 互斥锁和条件变量 2.Linux的并行性特征 Linu ...
- Linux组件封装(一)中互斥锁MutexLock的封装
本文对Linux中的pthread_mutex_t做一个简易的封装. 互斥锁主要用于互斥,互斥是一种竞争关系,主要是某一个系统资源或一段代码,一次做多被一个线程访问. 条件变量主要用于同步,用于协调线 ...
- 菜鸟nginx源代码剖析数据结构篇(十) 自旋锁ngx_spinlock
菜鸟nginx源代码剖析数据结构篇(十) 自旋锁ngx_spinlock Author:Echo Chen(陈斌) Email:chenb19870707@gmail.com Blog:Blog.cs ...
随机推荐
- 线性代数笔记24——微分方程和exp(At)
原文:https://mp.weixin.qq.com/s/COpYKxQDMhqJRuMK2raMKQ 微分方程指含有未知函数及其导数的关系式,解微分方程就是找出未知函数.未知函数是一元函数的,叫常 ...
- Pymysql的常见使用方法
cursor.fetchone()与cursor.fetchall()的区别: cursor.fetchone():只能显示一个数据 cursor.fetchall():才能显示查出来的所有数据 P ...
- JUC-1-volatile
什么是volatile关键字 volatile是轻量级同步机制,与synchronized相比,他的开销更小一些,同时安全性也有所降低,在一些特定的场景下使用它可以在完成并发目标的基础上有一 ...
- 使用STS4新建springboot项目
1.配置maven,自定义setting文件和仓库,一定要用阿里云镜像地址下载依赖,官方太坑了,整了半天都没弄好,原来是下载太慢文件损坏 <mirror> <id>alimav ...
- SpringCloud学习笔记(二、SpringCloud Config)
目录: 配置中心简介 SpringCloud Config服务端 SpringCloud Config客户端 动态配置属性bean 一些补充(源码分析):Spring事件监听.健康检查health() ...
- AcWing 154. 滑动窗口 单调队列
地址 https://www.acwing.com/problem/content/description/156/ 输入格式 输入包含两行. 第一行包含两个整数n和k,分别代表数组长度和滑动窗口的长 ...
- 2019-2020-1 20199305《Linux内核原理与分析》第一周作业
进入Linux的世界 1.何为Linux? Linux是一个操作系统. 2.Linux的由来 芬兰赫尔辛基大学的研究生 Linus Torvalds接触Unix时认为其费用不友好,决定自己开发一个操作 ...
- shell 下
一句话来概括shell shell是一个基于Linux内核和应用程序之间的一个解释器 Shell解释器 /bin/sh /bin/bash 目前多用的是bash /sbin/ ...
- Ubuntu 16.04 + Realsense D435i + ROS 环境配置
参考: [1] Realsense-Ros: https://github.com/IntelRealSense/realsense-ros#installation-instructions [2] ...
- Mybatis框架增删改查
一.recourses中核心配置文件mybatis-config.xml 二. recourse中jdbc.properties 三.entity实体类 四.ISmbmsUserDao层 五.ISmb ...