web scraper——爬取知乎|微博用户数据模板【三】
前言
在这里呢,我就只给模板,不写具体的教程啦,具体的可以参考我之前写的博文。
https://www.cnblogs.com/wangyang0210/p/10338574.html
模板
进入微博选择粉丝较多的博主
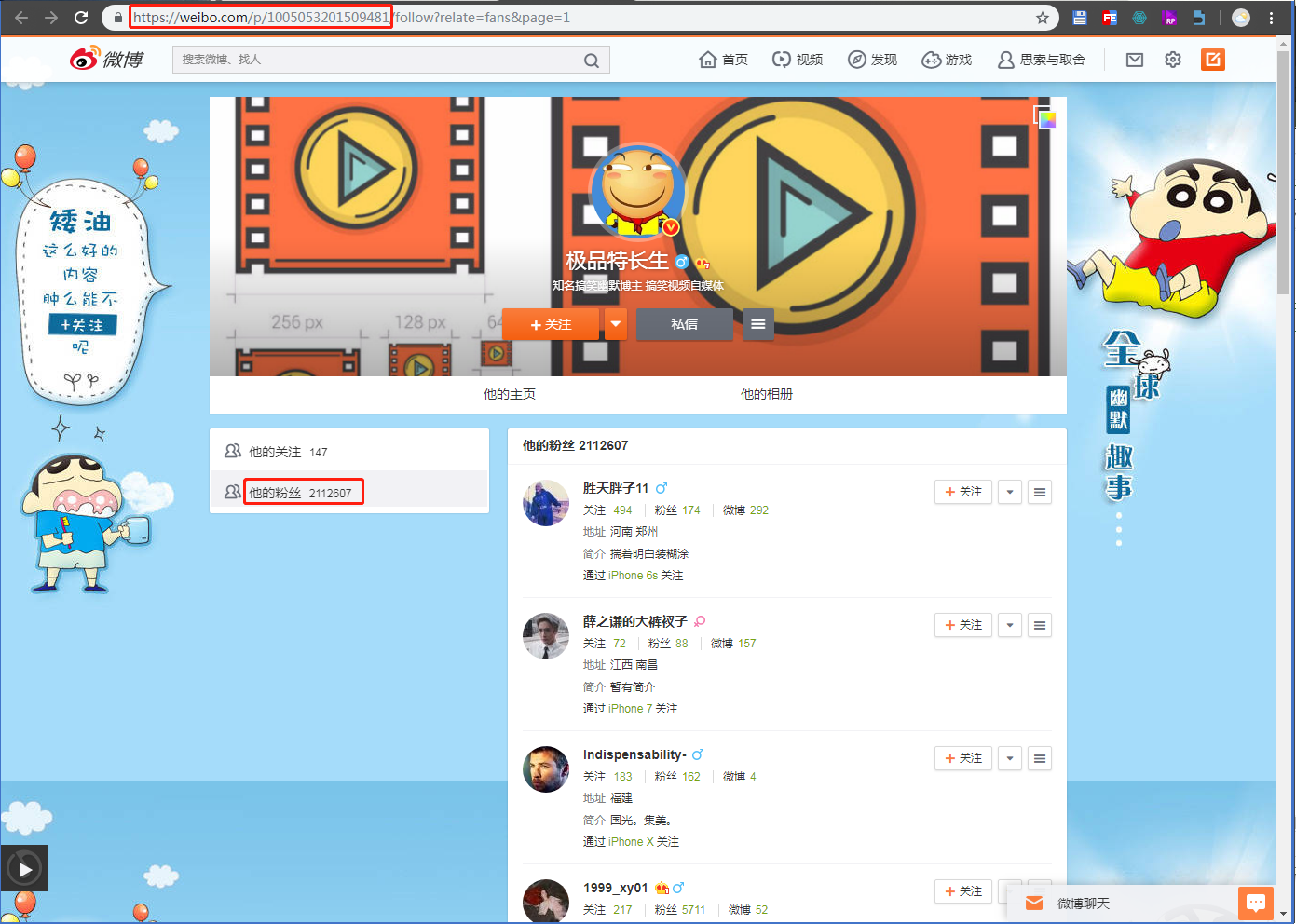
复制下面的模板导入站点即可
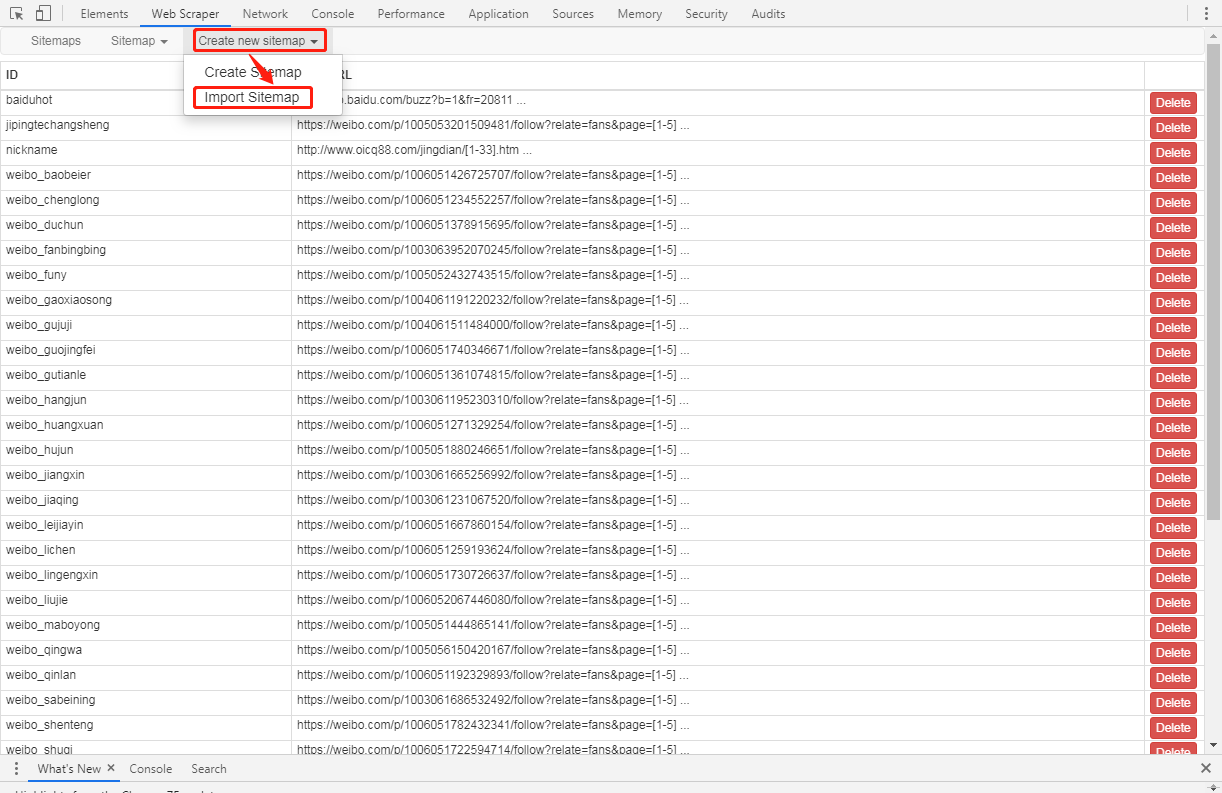
修改地址,编辑好名称,点击
Import Sitemap即可
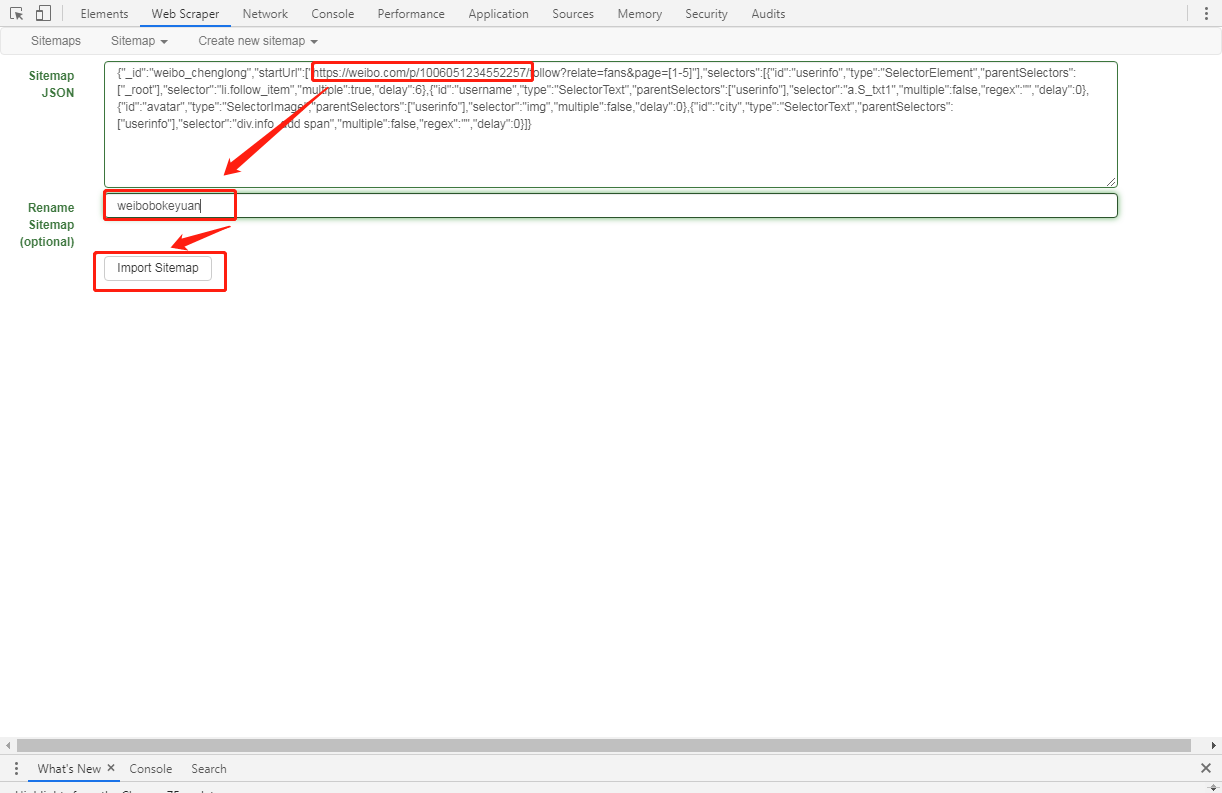
微博
{"_id":"weibo_chenglong","startUrl":["https://weibo.com/p/1006051234552257/follow?relate=fans&page=[1-5]"],"selectors":[{"id":"userinfo","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.follow_item","multiple":true,"delay":6},{"id":"username","type":"SelectorText","parentSelectors":["userinfo"],"selector":"a.S_txt1","multiple":false,"regex":"","delay":0},{"id":"avatar","type":"SelectorImage","parentSelectors":["userinfo"],"selector":"img","multiple":false,"delay":0},{"id":"city","type":"SelectorText","parentSelectors":["userinfo"],"selector":"div.info_add span","multiple":false,"regex":"","delay":0}]}
知乎
{"_id":"zhihuranqiqigongzuoshi","startUrl":["https://www.zhihu.com/people/xie-ling-520/followers?page=[1-45]"],"selectors":[{"id":"list","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.List-item","multiple":true,"delay":0},{"id":"username","type":"SelectorText","parentSelectors":["list"],"selector":"div.UserItem-title","multiple":false,"regex":"","delay":0},{"id":"avatar","type":"SelectorImage","parentSelectors":["list"],"selector":"img","multiple":false,"delay":0}]}
web scraper——爬取知乎|微博用户数据模板【三】的更多相关文章
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- Web Scraper爬取就是这么简单
这应该是最全的一个文档了 https://www.jianshu.com/p/e4c1561a3ea7 所以我就不介绍了,大家直接看就可以了,有问题可以提出来,我会针对问题对文章进行补充~
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- python 爬取知乎图片
先上完整代码 import requests import time import datetime import os import json import uuid from pyquery im ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # 爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # URL https://www.zhihu.co ...
随机推荐
- 使用Android SDK卸载厂家程序
ADB下载: 官网翻墙比较慢,这里推荐使用国内网站:https://www.androiddevtools.cn/ 下载 SDK Tools 和 SDK Platform-Tools: 两者分别 ...
- PowerDNS + PowerDNS-Admin
一.基础配置 1.1 环境说明 Centos 7.5.1804 PDNS MariaDB 1.2 关闭防火墙和 selinux setenforce sed -i 's/SELINUX=enforci ...
- python3.5+tornado学习
python3.5的安装 python官网下载地址:https://www.python.org/ 自行下载最新版本 下载pip包或者easy_install 后缀为.gz格式 地址:https:// ...
- 手撕面试官系列(十一):BAT面试必备之常问85题
JVM专题 (面试题+答案领取方式见侧边栏) Java 类加载过程? 描述一下 JVM 加载 Class 文件的原理机制? Java 内存分配. GC 是什么? 为什么要有 GC? 简述 Java ...
- DS 红黑树详解
通过上篇博客知道,二叉搜索树的局限在于不能完成自平衡,从而导致不能一直保持高性能. AVL树则定义了平衡因子绝对值不能大于1,使二叉搜索树达到了严格的高度平衡. 还有一种能自我调整的二叉搜索树, 红黑 ...
- SpringBoot使用mybatis,发生:Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured
最近,配置项目,使用SpringBoot2.2.1,配置mybatis访问db,配好后,使用自定义的数据源.启动发生: APPLICATION FAILED TO START ************ ...
- VMware学习笔记之在虚拟机中使用Ghost系统盘安装xp黑屏卡在光标闪无法进入系统
使用ghost安装后,无法进入系统,卡在光标闪动,请参考如下: https://www.cnblogs.com/mq0036/p/3588058.html https://wenku.baidu.co ...
- 玩转dockerfile
镜像的缓存特性 Docker 会缓存已有镜像的镜像层,构建新镜像时,如果某镜像层已经存在,就直接使用,无需重新创建. 举例说明.在前面的 Dockerfile 中添加一点新内容,往镜像中复制一个文件: ...
- loj#10067 构造完全图(最小生成树)
题目 loj#10067 构造完全图 解析 和kruscal类似,我们要构造一个完全图,考虑往这颗最小生成树里加边 我们先把每一条边存下来, 把两个端点分别放在不同的集合内,记录每个集合的大小,然后做 ...
- python二维数组切片
python中list切片的使用非常简洁.但是list不支持二维数组.仔细研究了一下发现,因为list不是像nampy数组那么规范.list非常灵活.所以没办法进行切片操作. 后来想了两个办法来解决: ...