Go语言调度器之创建main goroutine(13)
本文是《Go语言调度器源代码情景分析》系列的第13篇,也是第二章的第3小节。
上一节我们分析了调度器的初始化,这一节我们来看程序中的第一个goroutine是如何创建的。
创建main goroutine
接上一节,schedinit完成调度系统初始化后,返回到rt0_go函数中开始调用newproc() 创建一个新的goroutine用于执行mainPC所对应的runtime·main函数,看下面的代码:
runtime/asm_amd64.s : 197
# create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX# entry,mainPC是runtime.main
# newproc的第二个参数入栈,也就是新的goroutine需要执行的函数
PUSHQ AX # AX = &funcval{runtime·main}, # newproc的第一个参数入栈,该参数表示runtime.main函数需要的参数大小,因为runtime.main没有参数,所以这里是0
PUSHQ $
CALL runtime·newproc(SB) # 创建main goroutine
POPQ AX
POPQ AX # start this M
CALL runtime·mstart(SB) # 主线程进入调度循环,运行刚刚创建的goroutine # 上面的mstart永远不应该返回的,如果返回了,一定是代码逻辑有问题,直接abort
CALL runtime·abort(SB)// mstart should never return
RET DATA runtime·mainPC+(SB)/,$runtime·main(SB)
GLOB Lruntime·mainPC(SB),RODATA,$
在后面的分析过程中我们会看到这个runtime.main最终会调用我们写的main.main函数,在分析runtime·main之前我们先把重点放在newproc这个函数上。
newproc函数用于创建新的goroutine,它有两个参数,先说第二个参数fn,新创建出来的goroutine将从fn这个函数开始执行,而这个fn函数可能也会有参数,newproc的第一个参数正是fn函数的参数以字节为单位的大小。比如有如下go代码片段:
func start(a, b, c int64) {
......
}
func main() {
go start(1, 2, 3)
}
编译器在编译上面的go语句时,就会把其替换为对newproc函数的调用,编译后的代码逻辑上等同于下面的伪代码
func main() {
push 0x3
push 0x2
push 0x1
runtime.newproc(24, start)
}
编译器编译时首先会用几条指令把start函数需要用到的3个参数压栈,然后调用newproc函数。因为start函数的3个int64类型的参数共占24个字节,所以传递给newproc的第一个参数是24,表示start函数需要24字节大小的参数。
那为什么需要传递fn函数的参数大小给newproc函数呢?原因就在于newproc函数将创建一个新的goroutine来执行fn函数,而这个新创建的goroutine与当前这个goroutine会使用不同的栈,因此就需要在创建goroutine的时候把fn需要用到的参数先从当前goroutine的栈上拷贝到新的goroutine的栈上之后才能让其开始执行,而newproc函数本身并不知道需要拷贝多少数据到新创建的goroutine的栈上去,所以需要用参数的方式指定拷贝多少数据。
了解完这些背景知识之后,下面我们开始分析newproc的代码。newproc函数是对newproc1的一个包装,这里最重要的准备工作有两个,一个是获取fn函数第一个参数的地址(代码中的argp),另一个是使用systemstack函数切换到g0栈,当然,对于我们这个初始化场景来说现在本来就在g0栈,所以不需要切换,然而这个函数是通用的,在用户的goroutine中也会创建goroutine,这时就需要进行栈的切换。
runtime/proc.go : 3232
// Create a new g running fn with siz bytes of arguments.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
// Cannot split the stack because it assumes that the arguments
// are available sequentially after &fn; they would not be
// copied if a stack split occurred.
//go:nosplit
func newproc(siz int32, fn *funcval) {
//函数调用参数入栈顺序是从右向左,而且栈是从高地址向低地址增长的
//注意:argp指向fn函数的第一个参数,而不是newproc函数的参数
//参数fn在栈上的地址+8的位置存放的是fn函数的第一个参数
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp:= getg() //获取正在运行的g,初始化时是m0.g0 //getcallerpc()返回一个地址,也就是调用newproc时由call指令压栈的函数返回地址,
//对于我们现在这个场景来说,pc就是CALLruntime·newproc(SB)指令后面的POPQ AX这条指令的地址
pc := getcallerpc() //systemstack的作用是切换到g0栈执行作为参数的函数
//我们这个场景现在本身就在g0栈,因此什么也不做,直接调用作为参数的函数
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, gp, pc)
})
}
newproc1函数的第一个参数fn是新创建的goroutine需要执行的函数,注意这个fn的类型是funcval结构体类型,其定义如下:
type funcval struct{
fn uintptr
// variable-size, fn-specific data here
}
newproc1的第二个参数argp是fn函数的第一个参数的地址,第三个参数是fn函数的参数以字节为单位的大小,后面两个参数我们不用关心。这里需要注意的是,newproc1是在g0的栈上执行的。该函数很长也很重要,所以我们分段来看。
runtime/proc.go : 3248
// Create a new g running fn with narg bytes of arguments starting
// at argp. callerpc is the address of the go statement that created
// this. The new g is put on the queue of g's waiting to run.
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
//因为已经切换到g0栈,所以无论什么场景都有 _g_ = g0,当然这个g0是指当前工作线程的g0
//对于我们这个场景来说,当前工作线程是主线程,所以这里的g0 = m0.g0
_g_ := getg() ...... _p_ := _g_.m.p.ptr() //初始化时_p_ = g0.m.p,从前面的分析可以知道其实就是allp[0]
newg := gfget(_p_) //从p的本地缓冲里获取一个没有使用的g,初始化时没有,返回nil
if newg == nil {
//new一个g结构体对象,然后从堆上为其分配栈,并设置g的stack成员和两个stackgard成员
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead) //初始化g的状态为_Gdead
//放入全局变量allgs切片中
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
} ...... //调整g的栈顶置针,无需关注
totalSize := 4*sys.RegSize+uintptr(siz) +sys.MinFrameSize// extra space in case of reads slightly beyond frame
totalSize += -totalSize&(sys.SpAlign-1) // align to spAlign
sp := newg.stack.hi-totalSize
spArg := sp ...... if narg > 0 {
//把参数从执行newproc函数的栈(初始化时是g0栈)拷贝到新g的栈
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
// ......
}
这段代码主要从堆上分配一个g结构体对象并为这个newg分配一个大小为2048字节的栈,并设置好newg的stack成员,然后把newg需要执行的函数的参数从执行newproc函数的栈(初始化时是g0栈)拷贝到newg的栈,完成这些事情之后newg的状态如下图所示:
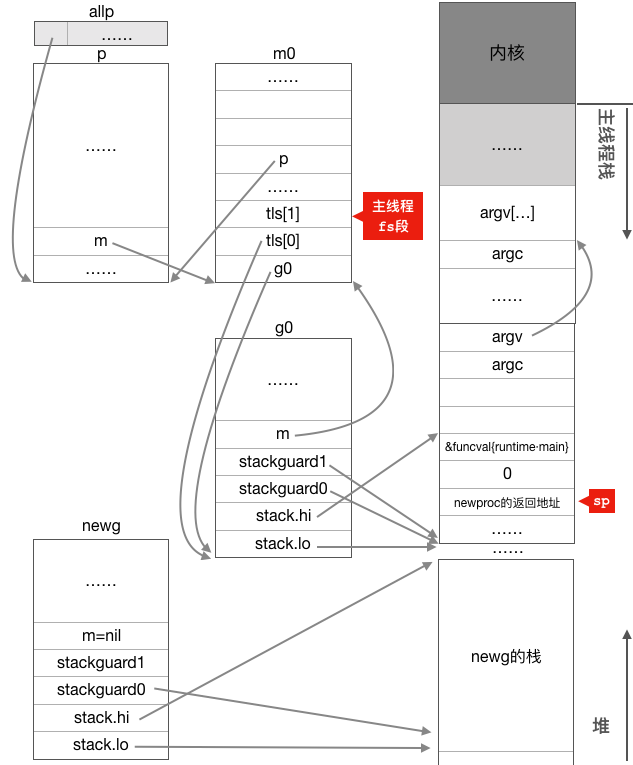
我们可以看到,经过前面的代码之后,程序中多了一个我们称之为newg的g结构体对象,该对象也已经获得了从堆上分配而来的2k大小的栈空间,newg的stack.hi和stack.lo分别指向了其栈空间的起止位置。
接下来我们继续分析newproc1函数。
runtime/proc.go : 3314
//把newg.sched结构体成员的所有成员设置为0
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) //设置newg的sched成员,调度器需要依靠这些字段才能把goroutine调度到CPU上运行。
newg.sched.sp = sp //newg的栈顶
newg.stktopsp = sp
//newg.sched.pc表示当newg被调度起来运行时从这个地址开始执行指令
//把pc设置成了goexit这个函数偏移1(sys.PCQuantum等于1)的位置,
//至于为什么要这么做需要等到分析完gostartcallfn函数才知道
newg.sched.pc = funcPC(goexit) + sys.PCQuantum// +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn)//调整sched成员和newg的栈
这段代码首先对newg的sched成员进行了初始化,该成员包含了调度器代码在调度goroutine到CPU运行时所必须的一些信息,其中sched的sp成员表示newg被调度起来运行时应该使用的栈的栈顶,sched的pc成员表示当newg被调度起来运行时从这个地址开始执行指令,然而从上面的代码可以看到,new.sched.pc被设置成了goexit函数的第二条指令的地址而不是fn.fn,这是为什么呢?要回答这个问题,必须深入到gostartcallfn函数中做进一步分析。
// adjust Gobuf as if it executed a call to fn
// and then did an immediate gosave.
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn) //fn: gorotine的入口地址,初始化时对应的是runtime.main
} else {
fn = unsafe.Pointer(funcPC(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
gostartcallfn首先从参数fv中提取出函数地址(初始化时是runtime.main),然后继续调用gostartcall函数。
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then did an immediate gosave.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp//newg的栈顶,目前newg栈上只有fn函数的参数,sp指向的是fn的第一参数
if sys.RegSize > sys.PtrSize {
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = 0
}
sp -= sys.PtrSize//为返回地址预留空间,
//这里在伪装fn是被goexit函数调用的,使得fn执行完后返回到goexit继续执行,从而完成清理工作
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc//在栈上放入goexit+1的地址
buf.sp = sp//重新设置newg的栈顶寄存器
//这里才真正让newg的ip寄存器指向fn函数,注意,这里只是在设置newg的一些信息,newg还未执行,
//等到newg被调度起来运行时,调度器会把buf.pc放入cpu的IP寄存器,
//从而使newg得以在cpu上真正的运行起来
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}
gostartcall函数的主要作用有两个:
调整newg的栈空间,把goexit函数的第二条指令的地址入栈,伪造成goexit函数调用了fn,从而使fn执行完成后执行ret指令时返回到goexit继续执行完成最后的清理工作;
重新设置newg.buf.pc 为需要执行的函数的地址,即fn,我们这个场景为runtime.main函数的地址。
调整完成newg的栈和sched成员之后,返回到newproc1函数,我们继续往下看,
newg.gopc = callerpc //主要用于traceback
newg.ancestors = saveAncestors(callergp)
//设置newg的startpc为fn.fn,该成员主要用于函数调用栈的traceback和栈收缩
//newg真正从哪里开始执行并不依赖于这个成员,而是sched.pc
newg.startpc = fn.fn ...... //设置g的状态为_Grunnable,表示这个g代表的goroutine可以运行了
casgstatus(newg, _Gdead, _Grunnable) ...... //把newg放入_p_的运行队列,初始化的时候一定是p的本地运行队列,其它时候可能因为本地队列满了而放入全局队列
runqput(_p_, newg, true) ......
}
newproc1函数最后这点代码比较直观,首先设置了几个与调度无关的成员变量,然后修改newg的状态为_Grunnable并把其放入了运行队列,到此程序中第一个真正意义上的goroutine已经创建完成。
这时newg也就是main goroutine的状态如下图所示:
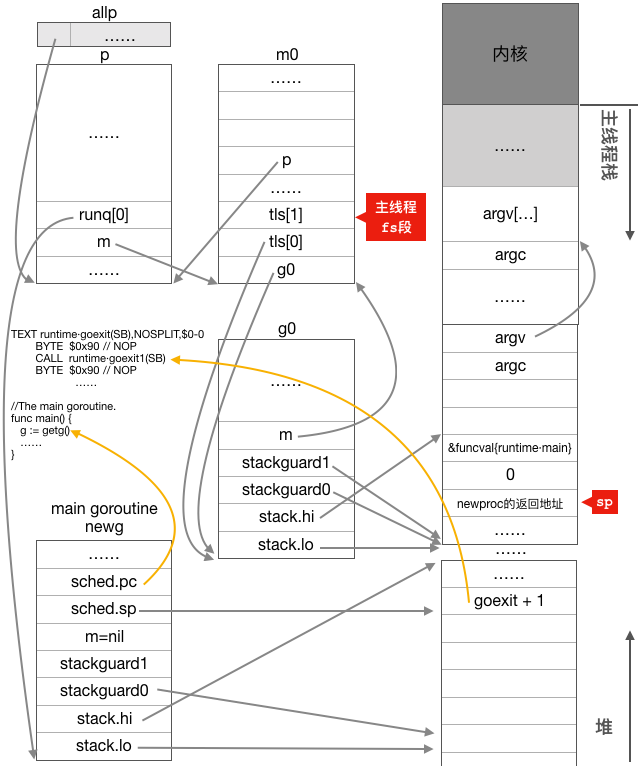
这个图看起来比较复杂,因为表示指针的箭头实在是太多了,这里对其稍作一下解释。
首先,main goroutine对应的newg结构体对象的sched成员已经完成了初始化,图中只显示了pc和sp成员,pc成员指向了runtime.main函数的第一条指令,sp成员指向了newg的栈顶内存单元,该内存单元保存了runtime.main函数执行完成之后的返回地址,也就是runtime.goexit函数的第二条指令,预期runtime.main函数执行完返回之后就会去执行runtime.exit函数的CALL runtime.goexit1(SB)这条指令;
其次,newg已经放入与当前主线程绑定的p结构体对象的本地运行队列,因为它是第一个真正意义上的goroutine,还没有其它goroutine,所以它被放在了本地运行队列的头部;
最后,newg的m成员为nil,因为它还没有被调度起来运行,也就没有跟任何m进行绑定。
这一节我们分析了程序中第一个goroutine也就是main goroutine的创建,下一节我们继续分析它是怎么被主工作线程调度到CPU上去执行的。
Go语言调度器之创建main goroutine(13)的更多相关文章
- Go语言调度器之调度main goroutine(14)
本文是<Go语言调度器源代码情景分析>系列的第14篇,也是第二章的第4小节. 上一节我们通过分析main goroutine的创建详细讨论了goroutine的创建及初始化流程,这一节我们 ...
- Go语言调度器之盗取goroutine(17)
本文是<Go语言调度器源代码情景分析>系列的第17篇,也是第三章<Goroutine调度策略>的第2小节. 上一小节我们分析了从全局运行队列与工作线程的本地运行队列获取goro ...
- Go语言调度器之主动调度(20)
本文是<Go语言调度器源代码情景分析>系列的第20篇,也是第五章<主动调度>的第1小节. Goroutine的主动调度是指当前正在运行的goroutine通过直接调用runti ...
- Golang源码学习:调度逻辑(二)main goroutine的创建
接上一篇继续分析一下runtime.newproc方法. 函数签名 newproc函数的签名为 newproc(siz int32, fn *funcval) siz是传入的参数大小(不是个数):fn ...
- 详解Go语言调度循环源码实现
转载请声明出处哦~,本篇文章发布于luozhiyun的博客: https://www.luozhiyun.com/archives/448 本文使用的go的源码15.7 概述 提到"调度&q ...
- go语言调度器源代码情景分析之一:开篇语
专题简介 本专题以精心设计的情景为线索,结合go语言最新1.12版源代码深入细致的分析了goroutine调度器实现原理. 适宜读者 go语言开发人员 对线程调度器工作原理感兴趣的工程师 对计算机底层 ...
- go语言之行--golang核武器goroutine调度原理、channel详解
一.goroutine简介 goroutine是go语言中最为NB的设计,也是其魅力所在,goroutine的本质是协程,是实现并行计算的核心.goroutine使用方式非常的简单,只需使用go关键字 ...
- [GO语言的并发之道] Goroutine调度原理&Channel详解
并发(并行),一直以来都是一个编程语言里的核心主题之一,也是被开发者关注最多的话题:Go语言作为一个出道以来就自带 『高并发』光环的富二代编程语言,它的并发(并行)编程肯定是值得开发者去探究的,而Go ...
- 非main goroutine的退出及调度循环(15)
本文是<Go语言调度器源代码情景分析>系列的第15篇,也是第二章的第5小节. 上一节我们说过main goroutine退出时会直接执行exit系统调用退出整个进程,而非main goro ...
随机推荐
- javaagent的实现
实现javaagent功能的是一个叫做instrument的JVMTIAgent(linux下对应的动态库是libinstrument.so),另外instrument agent还有个别名叫JPLI ...
- DRF--验证器
前戏 在之前我们对前端妹子传来的数据进行校验,使用的是序列化类来进行校验的,但这里面往往满足不了我们的需求,更多的时候我们希望自己定义校验规则.这里介绍三种自定义校验的方式.分别是单一字段校验,多个字 ...
- Git& GitHub常用的操作
Git是目前世界上最先进的分布式版本控制系统. 创始人:Linus Torvalds林纳斯·托瓦兹 经典的集中管理型(CVS.VSS.SVN) 版本管理系统: 1.版本管理的服务器一旦崩溃,硬盘损坏, ...
- A1047 Student List for Course (25 分)
一.技术总结 首先题目要看清湖,提出的条件很关键,比如for循环的终止条件,特别注意. 还有这个题目主要考虑到vector的使用,还有注意一定要加上using namespace std; 输出格式, ...
- 10.12 csp-s模拟测试70 木板+打扫卫生+骆驼
T1 木板 求$[\sqrt{n},n)$间有多少个数的平方是n的倍数 通过打表可以发现(我没带脑子我看不出来),符合条件的数构成一个等差数列,公差为首项 而首项就是将n质因数分解后每个质因数出现次数 ...
- MyEclipse清除所有断点的方法
今天调试网站时遇到点奇怪的问题,于是在宠大的代码段里加了N处断点,但从其它项目代码段链接代码加入断点后,关闭标签再次打开时发现断点看不到了,但运行到那段代码时依然会被中断.没有断点标记,不能手动取消怎 ...
- Java内存泄漏的排查总结
Java内存泄漏的排查总结 https://blog.csdn.net/fishinhouse/article/details/80781673(缺图见下一条)内存泄漏的解决方案(转载)https:/ ...
- APP兼容性测试 (二) 最新 iPhone 机型分辨率总结
iPhone手机发布时间及iOS发布 iPhone是美国苹果公司研发的智能手机系列,搭载苹果公司研发的iOS操作系统. 第一代iPhone于2007年1月9日由苹果公司前首席执行官史蒂夫·乔布斯发布, ...
- win10每次开机都会自检系统盘(非硬件故障)——解决方案2019.07.12
1.最近反复遇到了这个问题,之前遇到这个问题就把系统重装了,没想到今天又遇到了,目前系统东西太多了,重装太麻烦了,就下决心解决一下. 2.不要使用网络上流传的修改注册表的方案,把注册表的那个键值删除那 ...
- S-T-E-A-M Science Technology Engineering Art Mathematics 五种思维模式
S-T-E-A-M五个英文字母分别代表 Science 科学,Technology 技术,Engineering 工程,Art 艺术以及 Mathematics 数学.它们并不是简单地整合原来的分科体 ...