【转】高性能网络编程2----TCP消息的发送
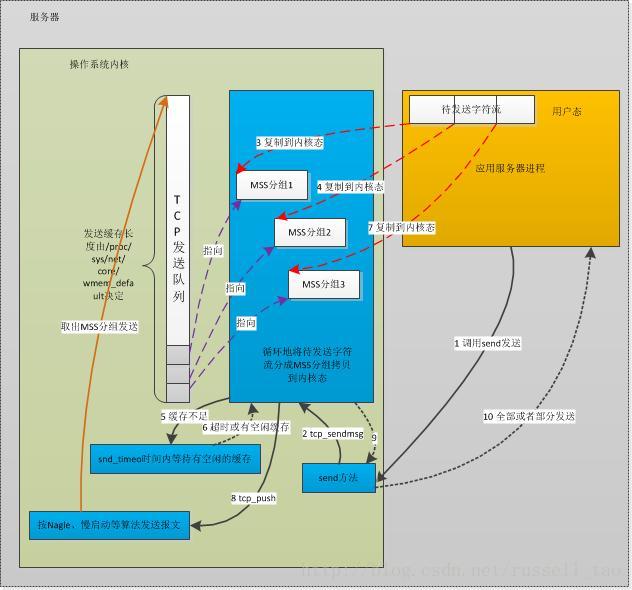
1、MSS与TCP的分片

2、发送方法返回成功后,数据一定发送到了TCP的另一端吗?
- wait_for_memory:
- if (copied)
- tcp_push(sk, tp, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH);
- if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
- goto do_error;
这里的sk_stream_wait_memory方法接受一个参数timeo,就是等待超时的时间。这个时间是tcp_sendmsg方法刚开始就拿到的,如下:
- timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
看看其实现:
- static inline long sock_sndtimeo(const struct sock *sk, int noblock)
- {
- return noblock ? 0 : sk->sk_sndtimeo;
- }
也就是说,当这个套接字是阻塞套接字时,timeo就是SO_SNDTIMEO选项指定的发送超时时间。如果这个套接字是非阻塞套接字, timeo变量就会是0。
3、Nagle算法、滑动窗口、拥塞窗口对发送方法的影响
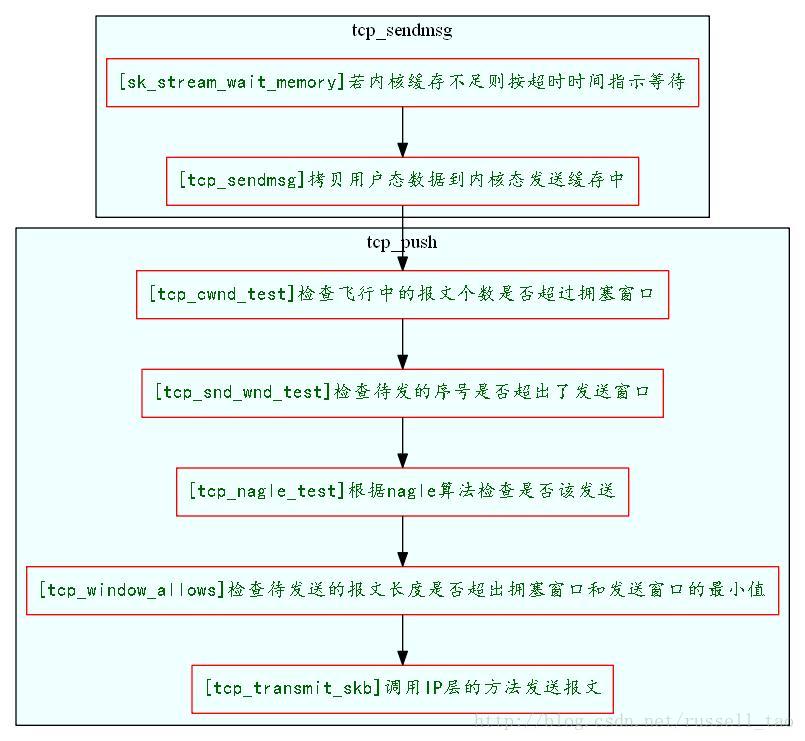
- //检查这一次要发送的报文最大序号是否超出了发送滑动窗口大小
- static inline int tcp_snd_wnd_test(struct tcp_sock *tp, struct sk_buff *skb, unsigned int cur_mss)
- {
- //end_seq待发送的最大序号
- u32 end_seq = TCP_SKB_CB(skb)->end_seq;
- if (skb->len > cur_mss)
- end_seq = TCP_SKB_CB(skb)->seq + cur_mss;
- //snd_una是已经发送过的数据中,最小的没被确认的序号;而snd_wnd就是发送窗口的大小
- return !after(end_seq, tp->snd_una + tp->snd_wnd);
- }
- static inline unsigned int tcp_cwnd_test(struct tcp_sock *tp, struct sk_buff *skb)
- {
- u32 in_flight, cwnd;
- /* Don't be strict about the congestion window for the final FIN. */
- if (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN)
- return 1;
- //飞行中的数据,也就是没有ACK的字节总数
- in_flight = tcp_packets_in_flight(tp);
- cwnd = tp->snd_cwnd;
- //如果拥塞窗口允许,需要返回依据拥塞窗口的大小,还能发送多少字节的数据
- if (in_flight < cwnd)
- return (cwnd - in_flight);
- return 0;
- }
再通过tcp_window_allows方法获取拥塞窗口与滑动窗口的最小长度,检查待发送的数据是否超出:
- static unsigned int tcp_window_allows(struct tcp_sock *tp, struct sk_buff *skb, unsigned int mss_now, unsigned int cwnd)
- {
- u32 window, cwnd_len;
- window = (tp->snd_una + tp->snd_wnd - TCP_SKB_CB(skb)->seq);
- cwnd_len = mss_now * cwnd;
- return min(window, cwnd_len);
- }
- static inline int tcp_nagle_test(struct tcp_sock *tp, struct sk_buff *skb,
- unsigned int cur_mss, int nonagle)
- {
- //nonagle标志位设置了,返回1表示允许这个分组发送出去
- if (nonagle & TCP_NAGLE_PUSH)
- return 1;
- //如果这个分组包含了四次握手关闭连接的FIN包,也可以发送出去
- if (tp->urg_mode ||
- (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN))
- return 1;
- //检查Nagle算法
- if (!tcp_nagle_check(tp, skb, cur_mss, nonagle))
- return 1;
- return 0;
- }
再来看看tcp_nagle_check方法,它与上一个方法不同,返回0表示可以发送,返回非0则不可以,正好相反。
- static inline int tcp_nagle_check(const struct tcp_sock *tp,
- const struct sk_buff *skb,
- unsigned mss_now, int nonagle)
- {
- //先检查是否为小分组,即报文长度是否小于MSS
- return (skb->len < mss_now &&
- ((nonagle&TCP_NAGLE_CORK) ||
- //如果开启了Nagle算法
- (!nonagle &&
- //若已经有小分组发出(packets_out表示“飞行”中的分组)还没有确认
- tp->packets_out &&
- tcp_minshall_check(tp))));
- }
最后看看tcp_minshall_check做了些什么:
- static inline int tcp_minshall_check(const struct tcp_sock *tp)
- {
- //最后一次发送的小分组还没有被确认
- return after(tp->snd_sml,tp->snd_una) &&
- //将要发送的序号是要大于等于上次发送分组对应的序号
- !after(tp->snd_sml, tp->snd_nxt);
- }
想象一种场景,当对请求的时延非常在意且网络环境非常好的时候(例如同一个机房内),Nagle算法可以关闭,这实在也没必要。使用TCP_NODELAY套接字选项就可以关闭Nagle算法。看看setsockopt是怎么与上述方法配合工作的:
- static int do_tcp_setsockopt(struct sock *sk, int level,
- int optname, char __user *optval, int optlen)
- ...
- switch (optname) {
- ...
- case TCP_NODELAY:
- if (val) {
- //如果设置了TCP_NODELAY,则更新nonagle标志
- tp->nonagle |= TCP_NAGLE_OFF|TCP_NAGLE_PUSH;
- tcp_push_pending_frames(sk, tp);
- } else {
- tp->nonagle &= ~TCP_NAGLE_OFF;
- }
- break;
- }
- }
可以看到,nonagle标志位就是这么更改的。
【转】高性能网络编程2----TCP消息的发送的更多相关文章
- 高性能网络编程2----TCP消息的发送
转 陶辉 taohui.org.cn 在上一篇中,我们已经建立好的TCP连接,对应着操作系统分配的1个套接字.操作TCP协议发送数据时,面对的是数据流.通常调用诸如send或者write方法来发送数据 ...
- 【转】高性能网络编程3----TCP消息的接收
这篇文章将试图说明应用程序如何接收网络上发送过来的TCP消息流,由于篇幅所限,暂时忽略ACK报文的回复和接收窗口的滑动. 为了快速掌握本文所要表达的思想,我们可以带着以下问题阅读: 1.应用程序调用r ...
- 高效的TCP消息发送组件
目前的.net 架构下缺乏高效的TCP消息发送组件,而这种组件是构建高性能分布式应用所必需的.为此我结合多年的底层开发经验开发了一个.net 下的高效TCP消息发送组件.这个组件在异步发送时可以达到每 ...
- 高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少
高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少 阅读(81374) | 评论(9)收藏16 淘帖1 赞3 JackJiang Lv.9 1 年前 | 前言 曾几何时我 ...
- NTCPMSG 开源高性能TCP消息发送组件
https://www.cnblogs.com/eaglet/archive/2013/01/07/2849010.html 目前的.net 架构下缺乏高效的TCP消息发送组件,而这种组件是构建高性能 ...
- 高性能网络编程3----TCP消息的接收
高性能网络编程3----TCP消息的接收 http://blog.csdn.net/russell_tao/article/details/9950615 http://blog.csdn.net/c ...
- android发送udp,tcp消息
发送方创建步骤: 1. 创建一个DatagramSocket对象 DatagramSocket socket = new DatagramSocket (4567); 2. 创建一个 InetA ...
- 深入delphi编程理解之消息(二)发送消息函数及消息编号、消息结构体的理解
一.delphi发送消息的函数主要有以下三个: (一).SendMessage函数,其原型如下: function SendMessage( hWnd: HWND; {目标句柄} Msg: UINT; ...
- 【转】高性能网络编程7--tcp连接的内存使用
当服务器的并发TCP连接数以十万计时,我们就会对一个TCP连接在操作系统内核上消耗的内存多少感兴趣.socket编程方法提供了SO_SNDBUF.SO_RCVBUF这样的接口来设置连接的读写缓存,li ...
随机推荐
- 使用draw.io桌面版代替visio制作流程图
前言 draw.io是一款在github上的开源产品,由于需要构建在线文档,需要插入画图类型, 对比多款开源产品,最终选择了draw.io. draw.io图标资源非常的丰富,方便导入图标资源,基本上 ...
- NazoHell 攻略
http://hell.one-story.cn/hell-start.html Level 0: http://nazohell.one-story.cn/nazohell-start.html 跳 ...
- GoLand 2019.1 激活破解
链接://https://blog.csdn.net/hi_liuxiansheng/article/details/89078405
- charles安装和使用(转)
转发链接:https://blog.csdn.net/zhangxiang_1102/article/details/77855548
- Jenkenis报错:该jenkins实例似乎已离线
使用运行war的形式安装jenkins,因为伟大的墙出现,“该jenkins实例似乎已离线” 问题 解决方法: 1. 保留此离线页面,重新开启一个浏览器tab标签页 2.输入输入网址http://lo ...
- .Net Core 定时任务TimeJob
转载自:https://blog.csdn.net/u013711462/article/details/53449799 定时任务 Pomelo.AspNetCore.TimedJob Pomelo ...
- 高级UI-UI绘制流程
UI的绘制流程和事件分发,属于Android里面的重点内容,在做自定义UI的时候,更是应该了解UI的绘制流程是如何的,此篇文章就是说明UI的绘制流程,事件分发前面已经详细讲过了 UI绘制流程探索 这里 ...
- k8s 修改节点角色和删除节点
修改节点角色: kubectl label nodes cn-thin05 node-role.kubernetes.io/node= 卸载节点: kubectl drain jupiter --de ...
- java的Array和List相互转换
1.Array转List,通过java.util.Arrays.asList(T... a)参数是可变泛型参数 注意,Arrays.asList返回的类型是不可变长度的集合,底层是final修饰的泛型 ...
- python递归函数(10)
一个函数在函数体内部调用自己,这样的函数称为递归函数,递归的次数在python是有限制的,默认递归次数是997次,超过997次会报错:RecursionError. 一.递归函数案例 案例一:计算数字 ...