flask实战-个人博客-编写博客前台
编写博客前台
博客前台需要开放给所有用户,这里包括显示文章列表、博客信息、文章内容和评论等功能功能。
分页显示文章列表
为了在主页显示文章列表,我们要先在渲染主页模板的index视图的数据库中获取所有文章记录并传入模板:
blueprints\blog.py:
from personalBlog.models import Post
@blog_bp.route('/')
def index():
posts = Post.query.order_by(Post, timestamp.desc()).all()
return render_template('blog/index.html', posts = posts)
在主页模板中,我们使用for语句迭代所有文章记录,一次渲染文章标题、发表时间和正文,如下所示:
personalBlog/templates/blog/index.html:渲染文章列表
{% block content %}
<div class="page-header">
<h1 class="display-3">{{ admin.blog_title|default('Blog Title') }}</h1>
<h4 class="text-muted"> {{ admin.blog_sub_title|default('Blog Subtitle' }}</h4>
</div>
<div class="row">
<div class="col-sm-8">
{% if posts %}
{% for post in posts %}
<h3 class="text-primary"><a href="{{ url_for('.show_post', post_id=post.id) }}">{{ post.title }}</a></h3>
<P>
{{ post.body|striptags|truncate }}
<small><a href="{{ url_for('.show_post', post_id=post.id) }}">Read More</a></small>
</P>
<small>
Comments:<a href="{{ url_for('.show_post', post_id=post.id) }}#comments">{{ post.comments|length }}</a>  
Category:<a
href="{{ url_for('.show_category', category_id=post.category.id }}">{{ post.category.name }}</a>
<span class="float-right">{{ moment(post.timestamp).format('LL') }}</span>
</small>
{% if not loop.last %}
<hr>
{% endif %}
{% endfor %}
{% else %}
<div class="tip">
<h5>No posts yet.</h5>
{% if current_user.is_authenticated %}
<a href="{{ url_for('admin.new_post') }}">Write Now</a>
{% endif %}
</div>
{% endif %}
</div>
这里的.show_post是指blog蓝本下的.show_post视图函数,在蓝本内部,是可以简写的(省略蓝本名称)
在for循环的外层,我们添加一个if判断,如果posts不包含文章,就显示一个“No posts”提示。如果当前用户已经登录,还会在提示文字下面显示一个指向新建文章页面的链接。a标签将文章标题渲染为链接,链接中包含文章正文对应的URL。
我们队文章正文使用了truncate过滤器,它会截取正文开头一部分(默认为255个字符)作为文章摘要。在truncate过滤器中,默认的结束符号为“...”,你可以使用end关键字指定为中文省略号“……”。为了让排版更统一,文章的正文摘要没有使用safe过滤器,默认显示无样式的文章HTML源码。我们附加了striptags过滤器以滤掉文章正文中的HTML标签。
在文章摘要后面,我们还添加了一个指向文章页面(show_post视图)的Read More按钮,同样的,文章标题也添加了指向文章页面的链接。另外,每一个文章摘要下方会使用<hr>添加分隔线,我们通过判断loop.last的值来避免在最后一个条目后添加分隔线。
flask run命令执行时就会执行app.run(),所以在脚本中可以不写app.run()。
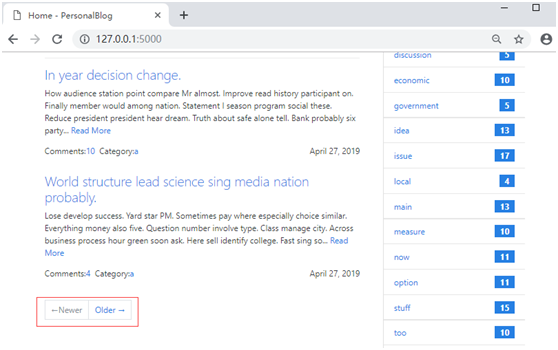
因为已经生成了虚拟数据,包含50篇文章。现在运行程序,首页会显示一个很长的文章列表,根据创建的随机日期排序,最新发表的排在上面,如下所示:
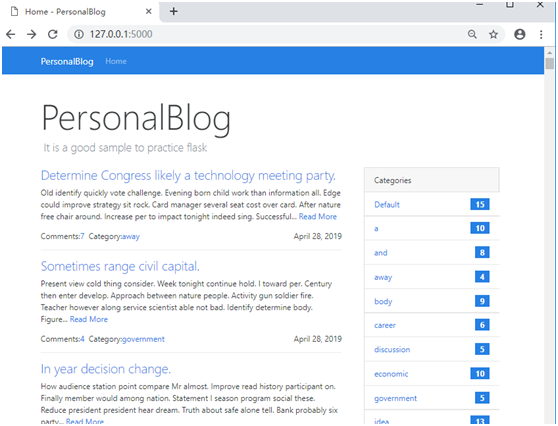
开始时提示404错误,是因为创建app的时候,没有正确注册blog蓝本,导致blog/index.html没有被正确的路由
如果所有的文章都在主页显示,无疑将会延长页面加载时间。而且用户需要拖动滚动条来浏览文章,太长的网页会让人感到沮丧,从而降低用户体验度。更好的做法是对文章数据进行分页处理,每一页值显示少量的文章,并在页面底部显示一个分页导航条,用户通过单击分页导航上的页数按钮来访问其他页面的文章。Flask-SQLAlchemy提供了简单的分页功能,使用paginate()查询方法可以分页获取文章记录,下面来学习如何使用。
1、获取分页记录
添加分页支持后的index视图,如下所示
personalBlog/blueprints/blog.py:对文章记录进行分页处理
@blog_bp.route('/')
def index():
page = request.args.get('page', 1, type = int) #从查询字符串获取当前页数
per_page = current_app.config['PERSONALBLOG_POST_PER_PAGE'] #每页数量
pagination = Post.query.order_by(Post.timestamp.desc()).paginate(page, per_page = per_page) #分页对象
posts = pagination.items #当前页数的记录列表
return render_template('blog/index.html', pagination = pagination, posts = posts)
为了实现分页,我们把之前的查询执行函数all()换成了paginate(),它接收的两个最主要的参数分别用来决定把记录分成几页(per_page),返回哪一页的记录(page)。page参数代表当前请求的页数,我们从请求的查询字符串(request.args)中获取,如果没有设置则使用默认值1,指定int类型可以保证在参数类型错误时使用默认值;per_page参数设置每页返回的记录数量,为了方便统一修改,这个值从配置变量PERSONAL_POST_PER_PAGE获取。
另外,可选的error_out参数用于设置当查询的页数超出总页数时的行为。当error_out设为True时,如果页面超过最大值,page或per_page为负数或非整数会返回404错误(默认值);如果设为False则返回空记录。可选的max_per_page参数则用来设置每页数量的最大值。
如果没有指定page和per_page参数,Flask-SQLAlchemy会自动从查询字符串中获取对应查询参数(page和per_page)的值,如果没有获取到,默认的page值为1,默认的per_page值为20。
调用查询方法paginate()会返回一个Pagination类实例,它包含分页的信息,我们将其称为分页对象。
对这个pagination对象调用items属性会以列表的形式返回对应页数(默认为第一页)的记录。在访问这个URL时,如果在URL后附加了查询参数page来指定页数,例如127.0.0.1:5000/?page=2,这时发起请求调用items变量将会获得第二个10条记录。
除了通过查询字符串获取页数,还可以直接将页数作为URL的一部分。下面的视图函数就是将page作为URL变量:
@blog_bp.route('/', defaults={'page':1})
@blog_bp.route('/page/<int:page>')
def index(page):
pagination = Post.query.order_by(Post.timestamp.desc()).paginate(page, per_page=current_app.config['PERSONALBLOG_POST_PER_PAGE'])
posts = pagination.items #当前页数的记录列表
return render_template('blog/index.html', pagination = pagination, posts = posts)
第一个路由使用defaults字典为page变量指定默认值,当访问127.0.0.1:5000/时,page取默认值1,返回第一页的记录;当访问127.0.0.1:5000/page/2时则会返回第2页的记录。注意,我们为URL规则中的page变量使用了int转换器,以便接收正确的整形页数值。
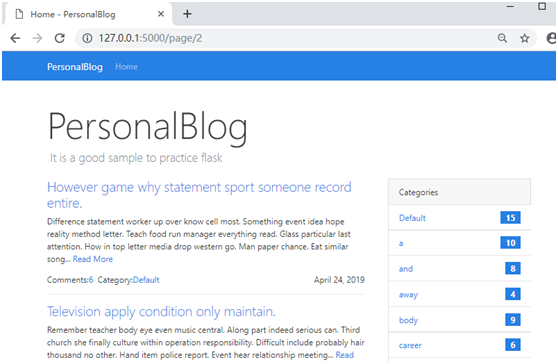
1、 渲染分页导航部件
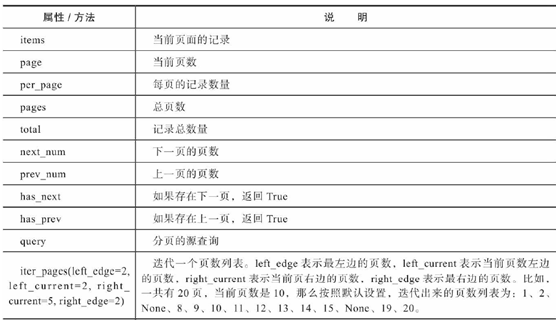
我们不能让用户通过在URL中附加查询字符串来实现分页浏览,而是应该在页面底部提供一个导航部件。这个分页导航部件应该包含上一页、下一页、以及跳转到每一页的按钮,每个按钮都包含指向主页的URL,而且URL中都添加了对应的查询参数page的值。使用paginate()方法时,它会返回一个Pagination类对象,这个类包含很多用于实现分页导航的方法和属性,我们可以用它来获取所有关于分页的信息,如下所示
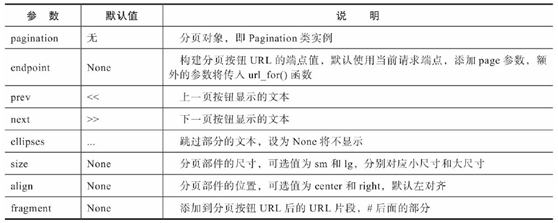
Pagination类属性:

对于博客来说,设置一个简单的包含上一页、下一页按钮的分页部件就足够了。
在视图函数中,我们将分页对象pagination传入模板,然后在模板中使用它提供的方法和属性来构建分页部件。为了便于重用,我们可以创建一个pager()宏:
{% macro pager(pagination, fragment='') %}
<nav aria-label="Page navigation">
<ul class="pagination">
<li class="page-item {% if not pagination.has_prev %}disabled{% endif %}">
<a class="page-link" href="{{ url_for(request.endpoint, page=pagination.prev_num, **kwargs) + fragment if pagination.has_prev }}">
<span aria-hidden="true">←</span>Newer
</a>
</li>
<li class="page-item {% if not pagination.has_next %}disabled{% endif %}">
<a class="page-link" href="{{ url_for(request.endpoint, page=pagination.next_num, **kwargs) + fragment if pagination.has_next }}">
Older <span aria-hidden="true">→</span>
</a>
</li>
</ul>
</nav>
{% endmacro %}
这个宏接收分页对象pagination和URL片段以及其他附加的关键字参数作为参数。我们根据pagination.has_prev和pagination.has_next属性来选择渲染按钮的禁用状态,如果这两个属性返回False,那么就为按钮添加disabled类,同时会用#作为a标签中的URL。分页按钮中的URL使用request.endpoint获取当前请求的端点,而查询参数page的值从pagination.prev_num(上一页的页数)和pagination.next_num(下一页的页数)属性获取。
在使用时,从macros.html模板中导入并在需要显示分页导航的位置调用即可,传入分页对象作为参数:
templates/blog/index.html:
{% from "macros.html" import pager %}
{% if posts %}
{% for post in posts %}
…
{% endfor %}
<div class="page-footer">{{ pager(pagination) }}</div>
把settings.py文件中的PERSONALBLOG_POST_PER_PAGE变量从10改为4
访问127.0.0.1:5000
实际上,Bootstrap-Flask已经内置了一个包含同样功能,而且提供更多自定义设置的render_pager()宏。除此之外,他还提供了一个render_pagination()宏,可以用来渲染一个标准的Bootstrap Pagination分页导航部件。这两个宏的用法和我们上面编写的pager()宏基本相同,render_pagination()宏支持的常用参数如下表所示,唯一的区别是render_pager()宏没有ellipses参数。
render_pagination()宏的常用参数:
在程序中我们将使用这两个宏来渲染分页导航部件,他们要从boostrap/pagination.html模板中导入,比如:
index.html:
{% from 'bootstrap/pagination.html' import render_pagination %}
{% for post in posts %}
…
{% endfor %}
<div class="page-footer">{{ render_pagination(pagination) }}</div>
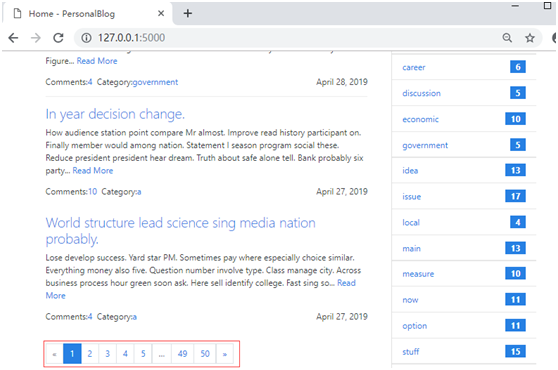
使用render_pagination()宏渲染后的标准分页导航部件如下所示:
flask实战-个人博客-编写博客前台的更多相关文章
- 用Python编写博客导出工具
用Python编写博客导出工具 罗朝辉 (http://kesalin.github.io/) CC 许可,转载请注明出处 写在前面的话 我在 github 上用 octopress 搭建了个人博 ...
- Bootstrap 实战之响应式个人博客 (二)
阅读本博文前请参考:Bootstrap 实战之响应式个人博客 (一) 一.博客 1.结构 整体博客详情页的结构共包括四部分: 导航栏 博客主体内容 右侧栏:全局搜索框,广告位,推荐阅读 页尾 其中导航 ...
- Bootstrap 实战之响应式个人博客 (一)
一.示例 1.主页 2.博客详情页 3.在线地址 在线地址:入口 Addition:这里使用github-page将自己的静态项目免费部署到线上. 如果你只是做一些简单的静态项目做展示,付出这么大的时 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(二)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(三)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(四)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(五)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- Scribefire离线编写博客的方法
用Firefox下载Scribefire next插件www.scribefire.com cnblogs添加方法: URL:http://www.cnblogs.com/[你的博客名] API为ht ...
- 利用Hexo搭建个人博客-博客初始化篇
上一篇博文 <利用Hexo搭建个人博客-环境搭建篇> 中,我们讲解了利用Hexo搭建个人博客应该要配置哪些环境.相信大家已经迫不及待的想要知道接下来应该要怎么把自己的博客搭起来了,下面,让 ...
随机推荐
- [LeetCode] 525. Contiguous Array 相连的数组
Given a binary array, find the maximum length of a contiguous subarray with equal number of 0 and 1. ...
- 多线程下的HashMap竟然绕环了
导读:早就听说过HashMap不是线程安全的,在多线程情况下可能会出问题,自己一直是一知半解,正好五一有时间就抽时间来研究一下. 关键词:线程安全,HashMap 直接上图 总结 看过的知识点不一定属 ...
- Redis学习之intset整数集合源码分析
1.整数集合:整数的集合,升序排序,无重复元素 2.整数集合intset是集合键的底层实现之一,当一个集合只包含整数值的元素,并且这个集合的元素数量不多时,redis会使用整数集合作为集合键的底层实现 ...
- 转 Pytorch 教学资料
本文收集了大量PyTorch项目(备查) 转自:https://blog.csdn.net/fuckliuwenl/article/details/80554182 目录: 入门系列教程 入门实例 图 ...
- day05——字典
day05 字典 字典-- dict: 字典无序的,可变的数据类型 用于存储大量数据,字典要比列表快,将数据和数据之间进行关联 lst1 = ['常鑫','李文虎','张宇'] # 姓名 lst2 = ...
- JavaScript 加减危机——为什么会出现这样的结果?
在日常工作计算中,我们如履薄冰,但是 JavaScript 总能给我们这样那样的 surprise~ 0.1 + 0.2 = ? 1 - 0.9 = ? 如果小伙伴给出内心的结果: 0.1 + 0.2 ...
- sql server 中取前n行字段最大值问题
例子 取前三行最大ID ID from Students)AS A 这样写得到的却是整个表的最大ID值,并不是我们需要的值 要在句中加入order by ID ID from Students ord ...
- Delphi - TIdFTP 两个重要函数
TIdFTP 两个重要函数 项目开发过程中发现,直接对于服务器上的文件/路径进行处理,是很危险的事情,因为一旦文件/路径不存在,程序就会抛异常,影响客户体验.所以在对服务器上的文件/路径进行访问之前, ...
- Java NIO学习系列一:Buffer
前面三篇文章中分别总结了标准Java IO系统中的File.RandomAccessFile.I/O流系统,对于I/O系统从其继承体系入手,力求对类数量繁多的的I/O系统有一个清晰的认识,然后结合一些 ...
- 初识DP
写在前面的话: 其实在去年寒假奥赛集训的时候,就已经接触DP了,但自己是真得对那时的自己很无语,不会,想不通,记不住就不管了,也没想过要一定把它吃透--但该来的总还是要来的. 所以现在就来玩好玩的DP ...