【神经网络与深度学习】【计算机视觉】图解YOLO

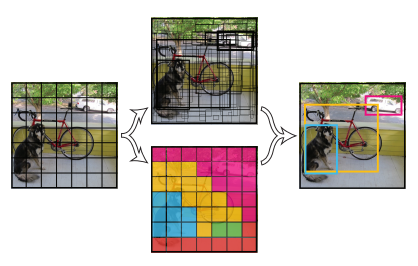
YOLO核心思想:从R-CNN到Fast R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但是速度还不行。 YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
YOLO的主要特点:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
- 泛化能力强。

大致流程:

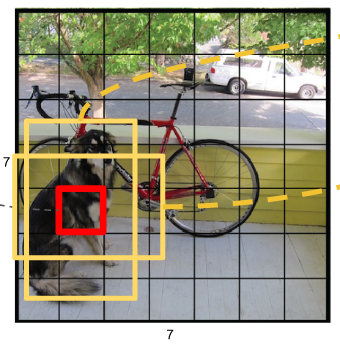
- Resize成448*448,图片分割得到7*7网格(cell)
- CNN提取特征和预测:卷积不忿负责提特征。全链接部分负责预测:a) 7*7*2=98个bounding box(bbox) 的坐标
和是否有物体的confidence
。 b) 7*7=49个cell所属20个物体的概率。 - 过滤bbox(通过nms)
网络设计:
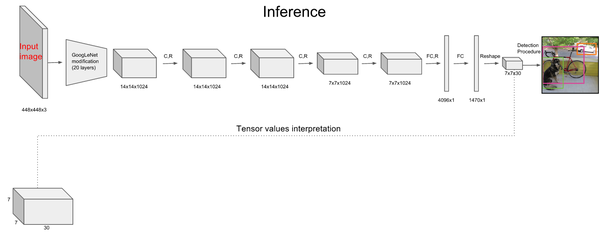
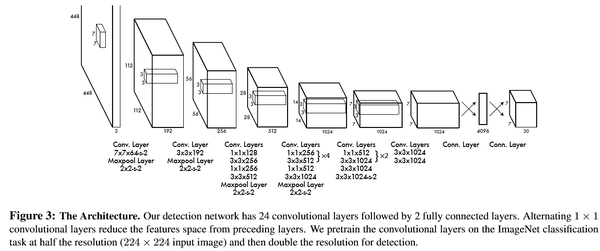
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )
训练:
预训练分类网络: 在 ImageNet 1000-class competition dataset上预训练一个分类网络,这个网络是Figure3中的前20个卷机网络+average-pooling layer+ fully connected layer (此时网络输入是224*224)。
训练检测网络:转换模型去执行检测任务,《Object detection networks on convolutional feature maps》提到说在预训练网络中增加卷积和全链接层可以改善性能。在他们例子基础上添加4个卷积层和2个全链接层,随机初始化权重。检测要求细粒度的视觉信息,所以把网络输入也又224*224变成448*448。见Figure3。
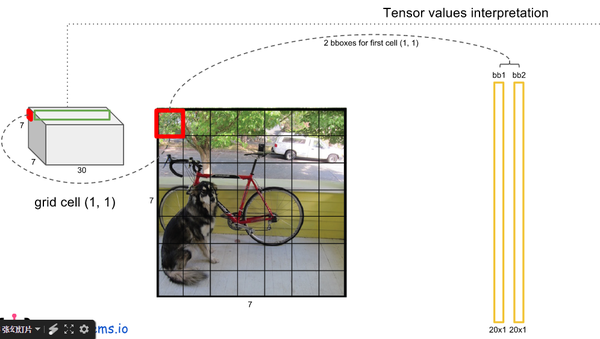
- 一幅图片分成7x7个网格(grid cell),某个物体的中心落在这个网格中此网格就负责预测这个物体。

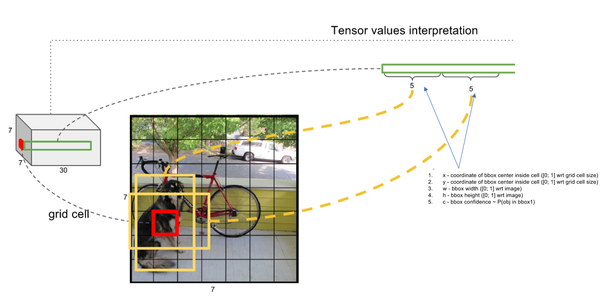
最后一层输出为 (7*7)*30的维度。每个 1*1*30的维度对应原图7*7个cell中的一个,1*1*30中含有类别预测和bbox坐标预测。总得来讲就是让网格负责类别信息,bounding box主要负责坐标信息(部分负责类别信息:confidence也算类别信息)。具体如下:
- 每个网格(1*1*30维度对应原图中的cell)要预测2个bounding box (图中黄色实线框)的坐标(
,w,h)
,其中:中心坐标的
每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息:confidence =。其中如果有ground
true box(人工标记的物体)落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的ground truth box之间的IOU值。即:每个bounding box要预测,共5个值
,2个bounding box共10个值,对应 1*1*30维度特征中的前10个。
- 每个网格(1*1*30维度对应原图中的cell)要预测2个bounding box (图中黄色实线框)的坐标(
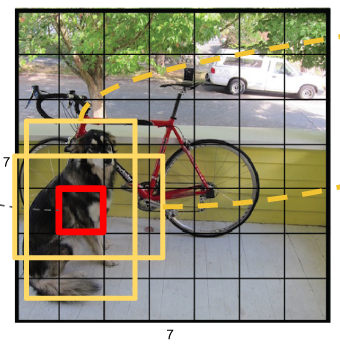
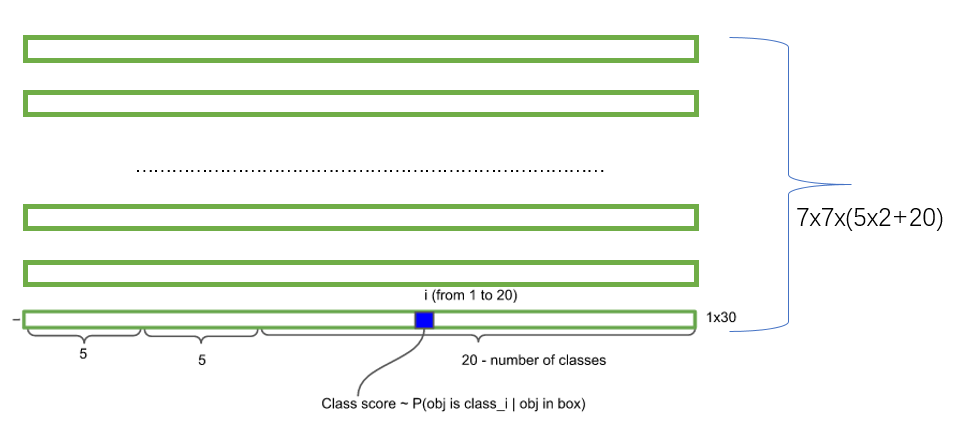
- 每个网格还要预测类别信息,论文中有20类。7x7的网格,每个网格要预测2个 bounding box 和 20个类别概率,输出就是 7x7x(5x2 + 20) 。 (通用公式: SxS个网格,每个网格要预测B个bounding box还要预测C个categories,输出就是S x S x (5*B+C)的一个tensor。 注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的)
损失函数设计:
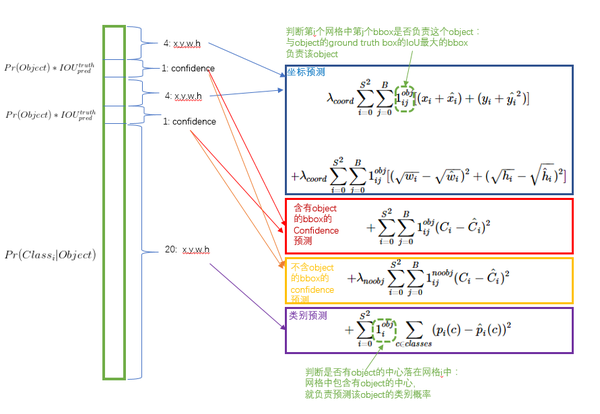
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。简单的全部采用了sum-squared error loss来做这件事会有以下不足: a) 8维的localization error和20维的classification error同等重要显然是不合理的; b) 如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence
push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。 解决方案如下:
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为
,在pascal VOC训练中取5。(上图蓝色框)
- 对没有object的bbox的confidence loss,赋予小的loss weight,记为
,在pascal VOC训练中取0.5。(上图橙色框)
- 有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
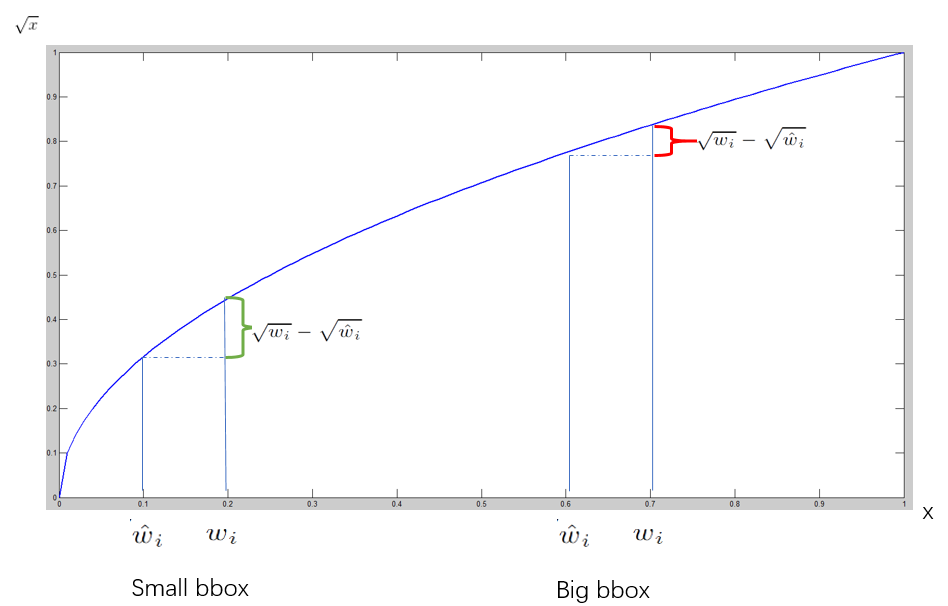
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
一个网格预测多个bounding box,在训练时我们希望每个object(ground true box)只有一个bounding box专门负责(一个object 一个bbox)。具体做法是与ground true box(object)的IOU最大的bounding box 负责该ground true box(object)的预测。这种做法称作bounding box predictor的specialization(专职化)。每个预测器会对特定(sizes,aspect
ratio or classed of object)的ground true box预测的越来越好。(个人理解:IOU最大者偏移会更少一些,可以更快速的学习到正确位置)
测试:
Test的时候,每个网格预测的class信息( )和bounding
box预测的confidence信息( ) 相乘,就得到每个bounding
box的class-specific confidence score。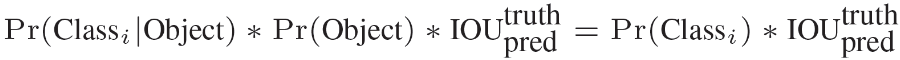
- 等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
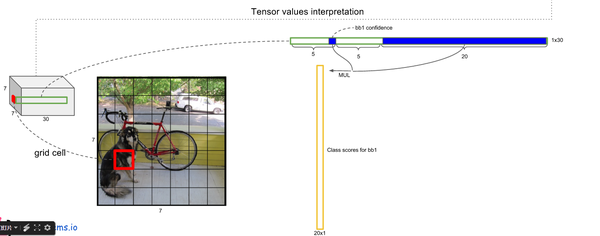
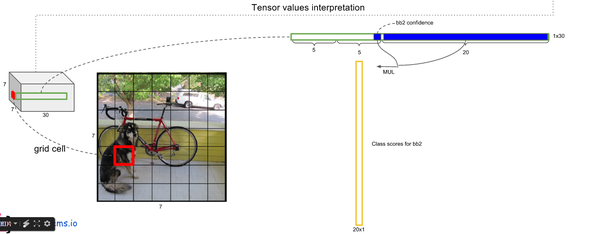
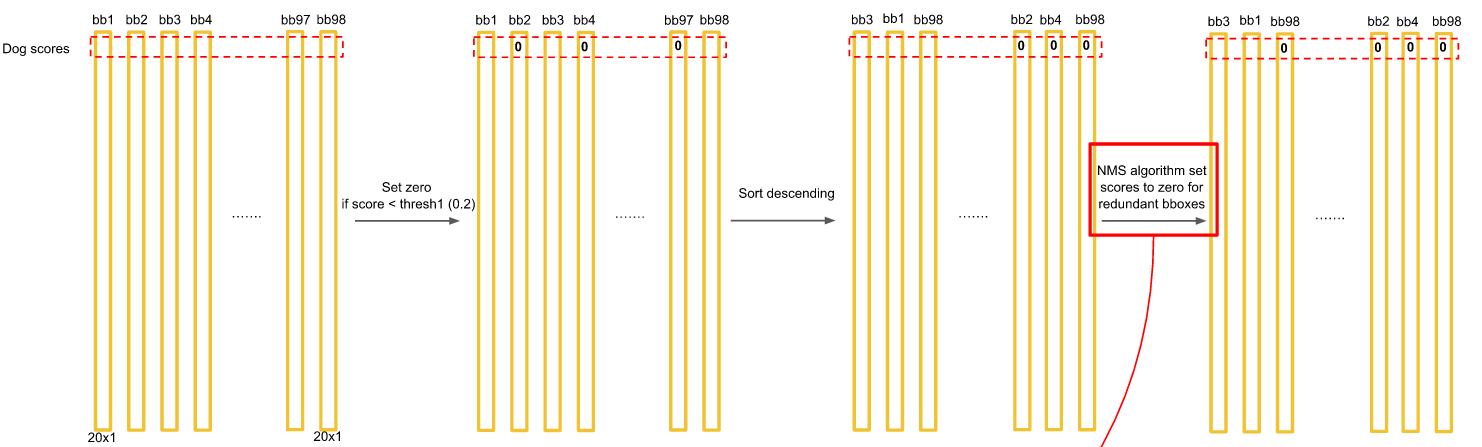
- 对每一个网格的每一个bbox执行同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)


- 等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
- 得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
缺陷:
YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
本文图片很多来自PPT: deepsystems.io
内容主要参考如下博客:
画图不易,如果觉得文章不错欢迎点赞支持一下。
【神经网络与深度学习】【计算机视觉】图解YOLO的更多相关文章
- [神经网络与深度学习][计算机视觉]SSD编译时遇到了json_parser_read.hpp:257:264: error: ‘type name’ declared as function ret
运行make之后出现如下错误: /usr/include/boost/property_tree/detail/json_parser_read.hpp:257:264: error: 'type n ...
- (转)神经网络和深度学习简史(第一部分):从感知机到BP算法
深度|神经网络和深度学习简史(第一部分):从感知机到BP算法 2016-01-23 机器之心 来自Andrey Kurenkov 作者:Andrey Kurenkov 机器之心编译出品 参与:chen ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第二周测验【中英】
[中英][吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第二周测验 第2周测验 - 神经网络基础 神经元节点计算什么? [ ]神经元节点先计算激活函数,再计算线性函数(z = Wx + ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第一周测验【中英】
[吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第一周测验[中英] 第一周测验 - 深度学习简介 和“AI是新电力”相类似的说法是什么? [ ]AI为我们的家庭和办公室的个人设备供电 ...
- 对比《动手学深度学习》 PDF代码+《神经网络与深度学习 》PDF
随着AlphaGo与李世石大战的落幕,人工智能成为话题焦点.AlphaGo背后的工作原理"深度学习"也跳入大众的视野.什么是深度学习,什么是神经网络,为何一段程序在精密的围棋大赛中 ...
- 如何理解归一化(Normalization)对于神经网络(深度学习)的帮助?
如何理解归一化(Normalization)对于神经网络(深度学习)的帮助? 作者:知乎用户链接:https://www.zhihu.com/question/326034346/answer/730 ...
- 【神经网络与深度学习】卷积神经网络(CNN)
[神经网络与深度学习]卷积神经网络(CNN) 标签:[神经网络与深度学习] 实际上前面已经发布过一次,但是这次重新复习了一下,决定再发博一次. 说明:以后的总结,还应该以我的认识进行总结,这样比较符合 ...
- 【神经网络与深度学习】【CUDA开发】caffe-windows win32下的编译尝试
[神经网络与深度学习][CUDA开发]caffe-windows win32下的编译尝试 标签:[神经网络与深度学习] [CUDA开发] 主要是在开发Qt的应用程序时,需要的是有一个使用的库文件也只是 ...
- 【神经网络与深度学习】【Matlab开发】caffe-windows使能Matlab2015b接口
[神经网络与深度学习][Matlab开发]caffe-windows使能Matlab2015b接口 标签:[神经网络与深度学习] [Matlab开发] 主要是想全部来一次,所以使能了Matlab的接口 ...
随机推荐
- QT 子文件的建立(pri)
QT 在做项目的时候有时会有许多不同种类的文件,如果这些文件放在一起会显得特别乱,我们可以将文件用文件夹分类,这样会比较有条理. 1. 在项目文件夹下建立新的文件夹,并在文件夹中添加文本文档将后缀改为 ...
- postgres —— 窗口函数入门
注:测试数据在 postgres —— 分组集与部分聚集 中 聚集将多行转变成较少.聚集的行.而窗口则不同,它把当前行与分组中的所有行对比,并且返回的行数没有变化. 组合当前行与 production ...
- 使用mybatis框架实现带条件查询-多条件(传入Map集合)
我们发现我们可以通过传入javaBean的方式实现我们的需求,但是就两个条件,思考:现在就给他传入一个实体类,对系统性能的开销是不是有点大了. 现在改用传入Map集合的方式: 奥!对了,在创建map集 ...
- 学习:类和对象——对象模型和this指针
成员变量和成员函数分开存储: 在C++中,类内的成员变量和成员函数分开存储 第一点:空对象占用内存空间1个字节 第二点:只有非静态成员变量才属于类的对象上,非静态成员函数和静态成员函数和静态成员变量不 ...
- webpack的loader的原理和实现
想要实现一个loader,需要首先了解loader的基本原理和用法. 1. 使用 loader是处理模块的解析器. module: { rules: [ { test: /\.css$/, use: ...
- 在Modelsim波形窗口复制信号
可以通过张贴复制变量名在Modelsim波形窗口复制信号.
- Mac下Pycharm中升级pip失败,通过终端升级pip
使用 Pycharm 使,需要下载相关的第三方包,结果提示安装失败,提示要升级 pip 版本,但是通过 Pycharm 重新安装却失败,原因可能是出在通过 Pycharm 时升级 pip 是没有权限的 ...
- manjaro系统的回滚操作
作为linux系统的爱好者,自从使用linux后,就喜欢追求新的软件,连系统都换成了滚动升级的版本.manjaro基于arch linux,同时也是kde的支持系统,升级非常频繁.使用了几年,很少碰到 ...
- IT 常用单词表
程序员英语单词册 前言 程序员必备的600个英语词汇(1) 程序员必备的600个英语词汇(2) 程序员必备的600个英语词汇(3) 程序员必备的600个英语词汇(4) 程序员不 ...
- centos7安装mysql8 ERROR! The server quit without updating PID file
原因mysql的安装目录在/etc/my.cnf配置不正确或者目录中的文件没有权限导致的,或者日志目录没有权限导致的 使用chwon -R mysql:mysql mysql的日志目录后重启mysq ...