【机器学习之一】python开发spark环境搭建
环境
spark-1.6
python3.5
一、python开发spark原理
使用python api编写pyspark代码提交运行时,为了不破坏spark原有的运行架构,会将写好的代码首先在python解析器中运行(cpython),Spark代码归根结底是运行在JVM中的,这里python借助Py4j实现Python和Java的交互,即通过Py4j将pyspark代码“解析”到JVM中去运行。例如,在pyspark代码中实例化一个SparkContext对象,那么通过py4j最终在JVM中会创建scala的SparkContext对象及后期对象的调用、在JVM中数据处理消息的日志会返回到python进程中、如果在代码中会回收大量结果数据到Driver端中,也会通过socket通信返回到python进程中。这样在python进程和JVM进程之间就有大量通信。
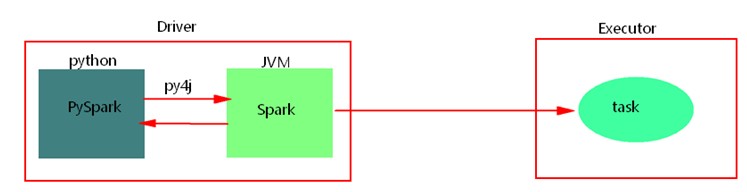
python开发spark,需要进行大量的进程间的通信,如果通信量过大,会出现“socket write error”错误,应尽量少使用回收数据类算子,也可以调节回收日志的级别,降低进程之间的通信。
二、搭建
这里使用Spark1.6版本,由于Spark2.1以下版本不支持python3.6版本,所以我们使用兼容性比较好的Python3.5版本。
步骤一:搭建python3.5环境
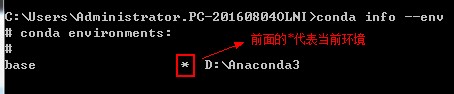
(1)conda info --env可以看到所有python环境,前面有个‘*’的代表当前环境
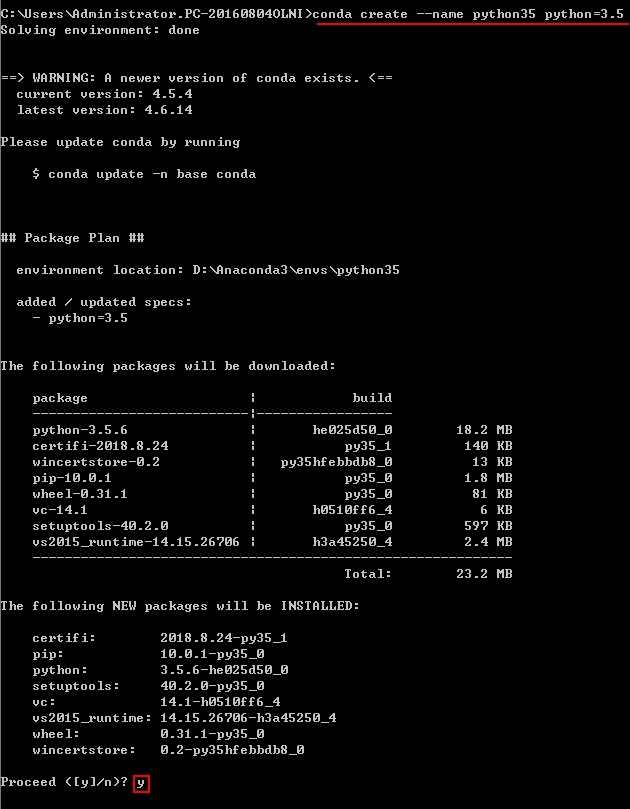
(2)创建Python3.5环境
conda create --name python35 python=3.5
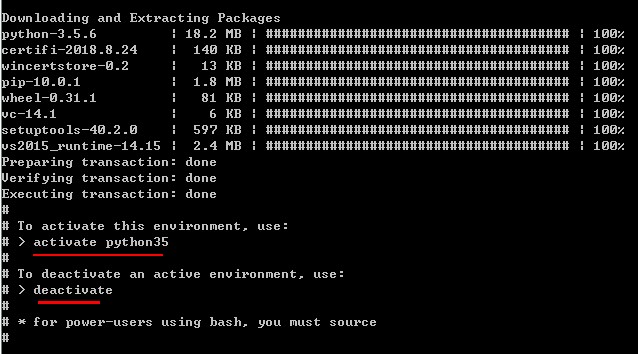
创建成功之后:

(3)激活python35:

步骤二:安装spark
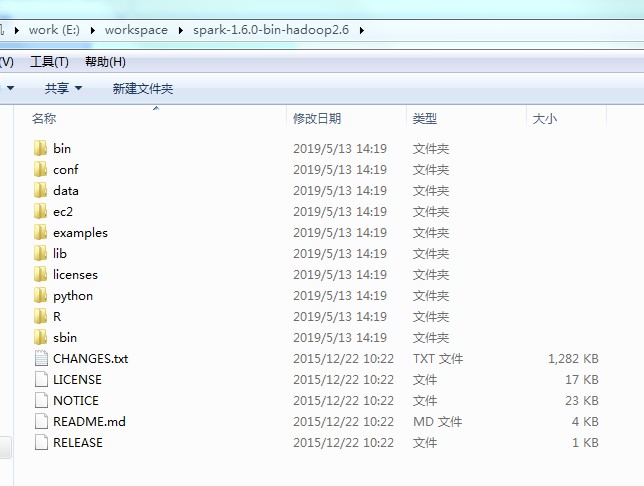
(1)下载spark-1.6.0-bin-hadoop2.6

官网下载:https://archive.apache.org/dist/spark/spark-1.6.3/

(2)解压到本地目录下,这里是:E:\workspace\spark-1.6.0-bin-hadoop2.6
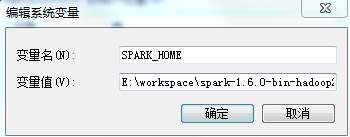
(3)配置环境变量:SPARK_HOME
步骤三:安装py4j、pyspark
★py4j是一个用Python和Java编写的库。通过Py4J,Python程序能够动态访问Java虚拟机中的Java对象,Java程序也能够回调Python对象。
★pyspark是Spark为Python开发者提供的 API。
方式一:可以通过pip安装,但是默认安装最新版本,我们这里需要的是和spark1.6相匹配的版本(不推荐)
安装:
pip install py4j
pip install pyspark
卸载:
pip uninstall py4j
pip uninstall pyspark
方式二:通过spark安装包拷贝(推荐)
进入目录:E:\workspace\spark-1.6.0-bin-hadoop2.6\python\lib,将py4j-0.9-src.zip、pyspark.zip解压后将py4j、pyspark拷贝到:D:\Anaconda3\envs\python35\Lib\site-packages
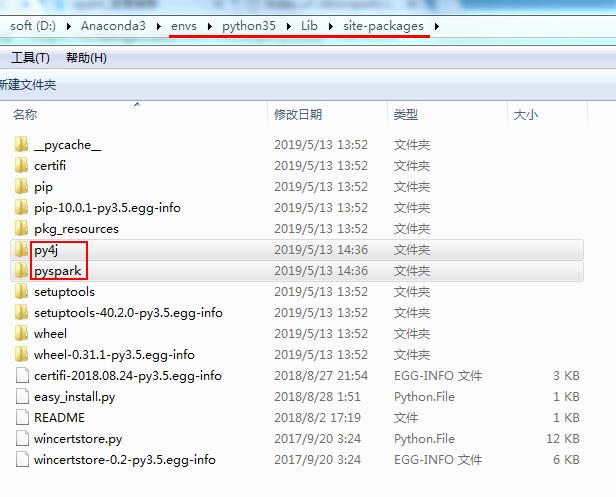
验证:导入包 不报错就OK

否则,会报错:
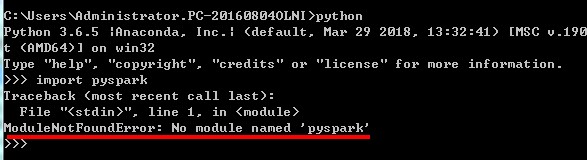
三、IDE搭建
1、eclipse
(1)eclipse中开发python程序,需要安装pydev插件。eclipse要求4.7以上,下载python插件包PyDev.zip(http://www.pydev.org/download.html),解压后加压拷贝到eclipse的dropins中,重启即可。
(2)配置python35解释器

(3)配置SPARK_HOME,设置环境变量,需要重启eclipse
否则报错:KeyError: 'SPARK_HOME'
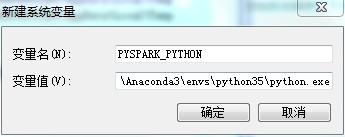
(4)配置PYSPARK_PYTHON
如果使用的anaconda更换了python3.5.x版本,之后在开发工具中指定了python解析器为3.5.x版本之后,运行python spark 代码时spark默认的使用的python版本可能使环境变量中指定的版本。会导致与指定的python解析器的python版本不一致。这时需要在环境变量中指定下PYSPARK_PYTHON环境变量即可,值为指定的python3.5.x python解析器。
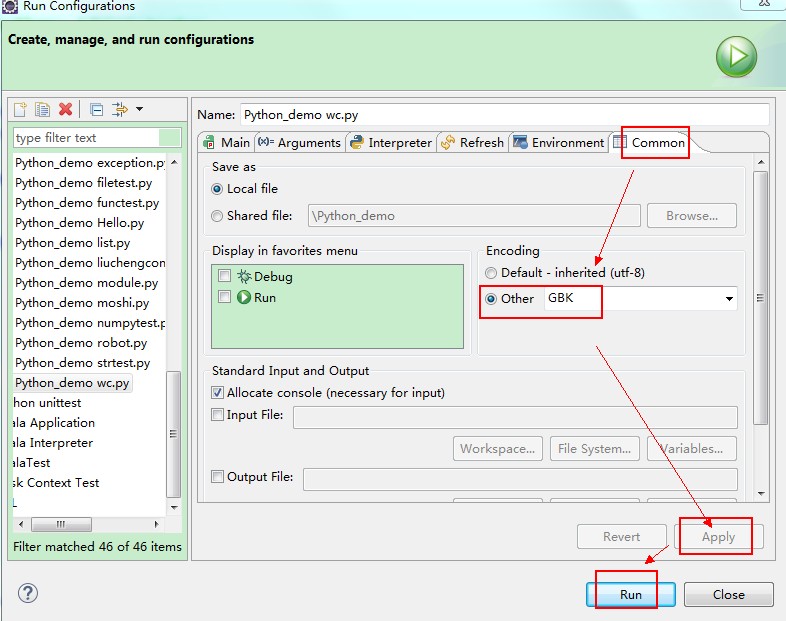
(5)配置控制台编码
eclipse控制台只支持GBK编码。运行时需要修改编码,运行python文件时,右键->Run As->Run Configurations->Common->Encoding 改为GBK
乱码:
�ɹ�: ����ֹ PID (���� PID �ӽ���)�Ľ��̡�
�ɹ�: ����ֹ PID (���� PID �ӽ���)�Ľ��̡�
�ɹ�: ����ֹ PID (���� PID �ӽ���)�Ľ��̡�
设置:
修正后:
成功: 已终止 PID (属于 PID 子进程)的进程。
成功: 已终止 PID (属于 PID 子进程)的进程。
成功: 已终止 PID (属于 PID 子进程)的进程。
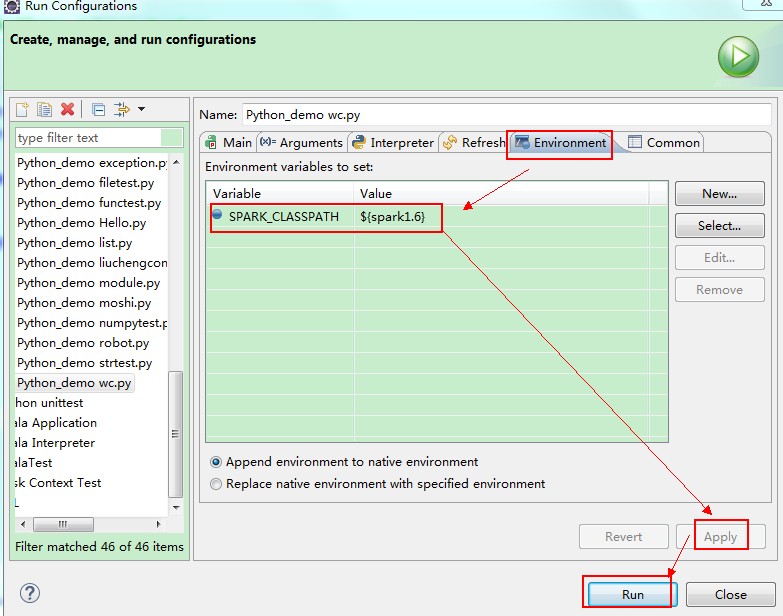
(6)python开发spark设置外部依赖包
<1>本地测试可以通过Run As -> Run Configuration->Environment来设置SPARK_CLASSPATH 指定依赖的jar包:
<2>集群中提交任务,需要指定依赖的jar包,可以通过--jars或者—driver-class-path来指定依赖的jar包。也可以在集群spark中../conf/spark-defaults.conf中设置变量spark.driver.extraClassPath或者spark.executor.extraClassPath来指定pySpark依赖的jar包。
例如:如果使用python来开发SparkStreaming Application 还需要在进行如下配置:
在conf目录的spark-default.conf目录下添加两行配置信息
spark.driver.extraClassPath F:/spark-1.6.-bin-hadoop2./lib/spark-streaming-kafka-assembly_2.-1.6..jar
spark.executor.extraClassPath F:/spark-1.6.-bin-hadoop2./lib/spark-streaming-kafka-assembly_2.-1.6..jar
2、PyCharm
PyCharm2018破解:https://blog.csdn.net/u012278016/article/details/81738676
(1)创建新的python项目
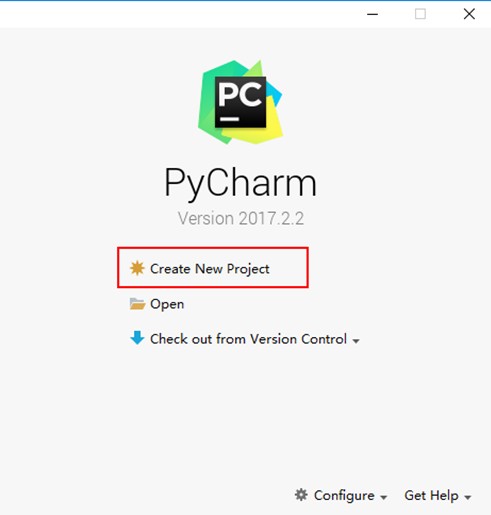

(2)使用PyCharm创建python3.5环境
不同的python项目,可能需要不同的python版本
第一种:使用conda创建新环境
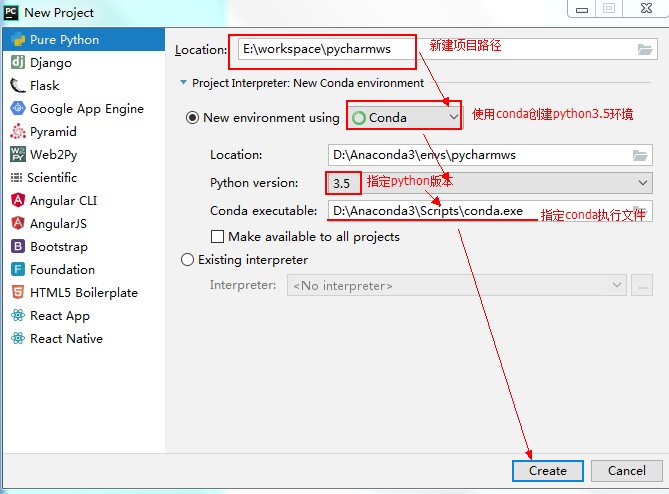
第二种:使用已有虚拟环境
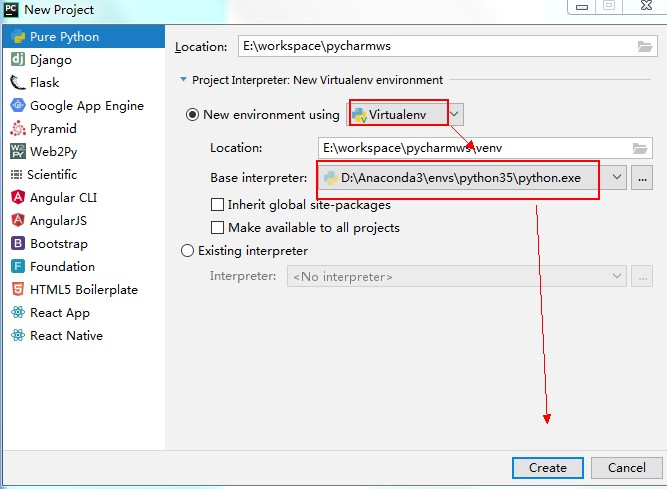
第三种:使用已有其他的环境
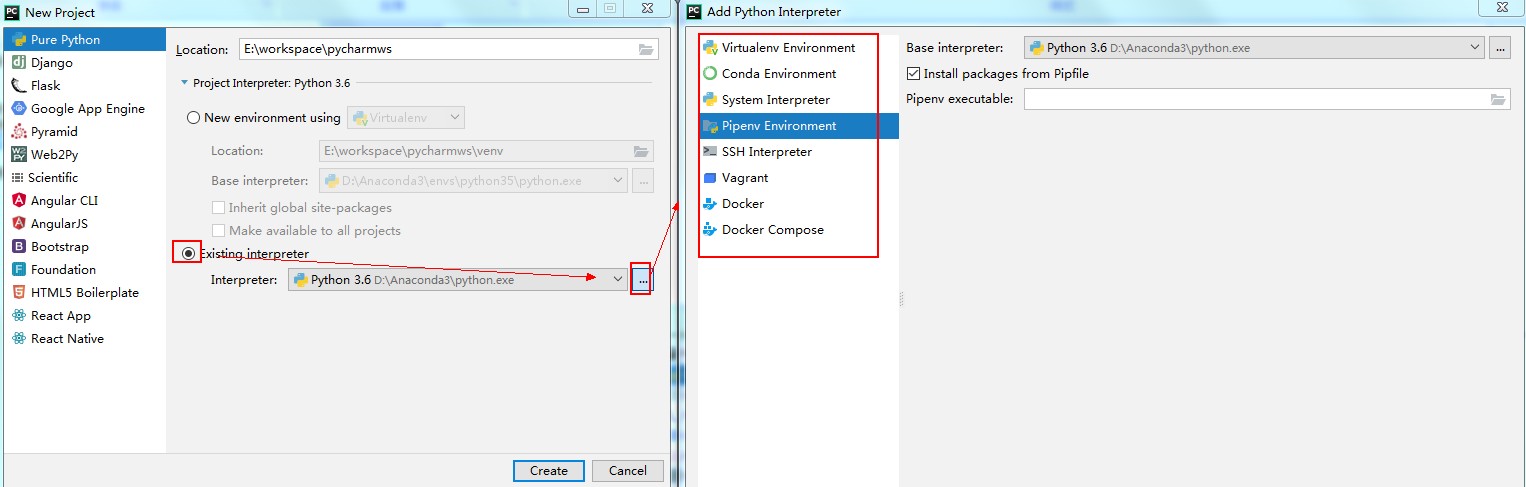
(2)配置python对spark的依赖包
选中项目,然后选择点击File->Settings…->点击 Project:xxx:->Project Structure


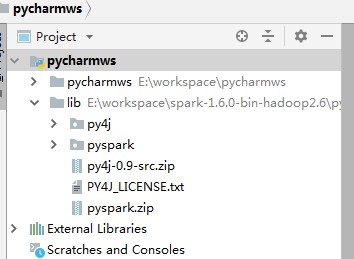
(3)配置SPAKR_HOME,否则报错:KeyError: 'SPARK_HOME'
方式一:设置某个python文件运行变量


方式二:设置所有文件默认运行变量

方式三:配置系统环境变量SPAKR_HOME,设置后需要重启PyCharm
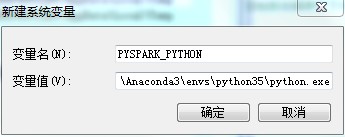
(4)配置PYSPARK_PYTHON
配置spark使用的python版本,否则有可能报错

方式一:代码中设置
import os
os.environ["PYSPARK_PYTHON"] = "D:\\Anaconda3\\envs\\python35\\python.exe"
方式二:设置PyCharm运行变量

方式三:设置操作系统环境变量 需要重启PyCharm
(5)设置 python代码模板
File->Setting->File and Code Templates

PyCharm中的文件模版变量:
${PROJECT_NAME} - 当前的项目名
${NAME} - 在文件创建过程中,新文件对话框的命名
${USER} - 当前的登录用户
${DATE} - 现在的系统日期
${TIME} - 现在的系统时间
${YEAR} - 当前年份
${MONTH} - 当前月份
${DAY} - 当前月份中的第几日
${HOUR} - 现在的小时
${MINUTE} - 现在的分钟
${PRODUCT_NAME} - IDE创建文件的名称
${MONTH_NAME_SHORT} - 月份的前三个字母缩写
${MONTH_NAME_FULL} - 完整的月份名
注意:
jdk、Anaconda、python、Spark的安装路径中不能有空格和中文。
【机器学习之一】python开发spark环境搭建的更多相关文章
- Python开发:环境搭建(python3、PyCharm)
Python开发:环境搭建(python3.PyCharm) python3版本安装 PyCharm使用(完全图解(最新经典))
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- 学习Spark——环境搭建(Mac版)
大数据情结 还记得上次跳槽期间,与很多猎头都有聊过,其中有一个猎头告诉我,整个IT跳槽都比较频繁,但是相对来说,做大数据的比较"懒"一些,不太愿意动.后来在一篇文中中也证实了这一观 ...
- Python之Django环境搭建(MAC+pycharm+Django++postgreSQL)
Python之Django环境搭建(MAC+pycharm+Django++postgreSQL) 转载请注明地址:http://www.cnblogs.com/funnyzpc/p/7828614. ...
- Python介绍及环境搭建
摘自http://www.cnblogs.com/sanzangTst/p/7278337.html Python零基础学习系列之二--Python介绍及环境搭建 1-1.Python简介: Py ...
- 【nginx,apache】thinkphp ,laravel,yii2开发运行环境搭建
缘由 经常会有人问xx框架怎么配置运行环境,这里我就给贴出吉祥三宝(Yii2,Laravel5,Thinkphp5 )的Nginx和Apache的配置,供大家参考 Nginx Yii2 server ...
- 基于Python的Appium环境搭建合集
自动化一直是测试圈中的热聊,也是大家追求的技术方向.在测试中,往往回归测试也是测试人员的“痛点”.对于迭代慢.变更少的功能,就能用上自动化来替代人工回归,减轻工作量. 问题 在分享环境搭建之前,先抛出 ...
- python+Eclipse+pydev环境搭建
python+Eclipse+pydev环境搭建 本文重点介绍使用Eclipse+pydev插件来写Python代码, 以及在Mac上配置Eclipse+Pydev 和Windows配置Ecli ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
随机推荐
- npm run build打包时修改的路径
- Optimal Marks SPOJ - OPTM(最小割)
传送门 论文<最小割模型在信息学竞赛中的应用>原题 二进制不同位上互不影响,那么就按位跑网络流 每一位上,确定的点值为1的与S连一条容量为INF的有向边.为0的与T连一条容量为INF的有向 ...
- Centos 7 命令行版虚拟机安装
使用VMware创建虚拟机 点击下一步 点击下一步 下一步 选择你要安装的虚拟机是哪种操作系统 选择虚拟机的安装位置 选择处理器 自定义内存 选择网络 下一步 下一步 下一步就可以 自定义磁盘容量 然 ...
- BZOJ1113 海报PLA1(单调栈入门题)
一,自己思考下 1,先自己思考下 N个矩形,排成一排,现在希望用尽量少的海报去cover住它们. 2,不懂. 着实不懂. 3,分析下,最优性问题对吧,然后就每什么想法了.. 虽然肯定和单调栈和单调队列 ...
- area标签的使用,图片中某一个部分可以点击跳转,太阳系中点击某个行星查看具体信息
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- snmp-get
使用mibbroser可以连接到监控主机,可以获取主机mib信息 使用walk出的oid就可以获取到对应的值, 使用 -O fn 可以将返回的字符创形式的键改为数字型oid oid还有一种字符串的形式 ...
- Switch ……case语句
Switch(变量){ case 1: 如果变量和1的值相同,执行该处代码 break; case 2: 如果变量和2的值相同,执行该处代码 break; case 3: 如果变量和3的值相同,执行该 ...
- GoCN每日新闻(2019-10-02)
GoCN每日新闻(2019-10-02) GoCN每日新闻(2019-10-02) 1. Golang中基于Gin和Casbin的web使用方式 https://dev.to/maxwellhertz ...
- 平安寿险Java面试-社招-四面(2019/08)
个人情况 2017年毕业,普通本科,计算机科学与技术专业,毕业后在一个二三线小城市从事Java开发,2年Java开发经验.做过分布式开发,没有高并发的处理经验,平时做To G的项目居多.写下面经是希望 ...
- Alibaba Nacos:搭建Nacos平台
1.下载安装包 https://github.com/alibaba/nacos/releases 往下翻,找到压缩包下载. 2.解压 tar -xvf nacos-server-$version.t ...