STL源码剖析——算法#1 内存处理基本工具
我们在学习序列式容器时,我们经常会遇到这三个函数:uninitialized_copy、uninitialized_fill、uninitialized_fill_n。在那时我们只是仅仅知道这些函数的功能,至于它们是如何实现的,我们并没有深究。在这节,我们花点时间摘下这几个函数的面具,看看它们不为人知的那一面。
- uninitialized_copy

函数签名:
template <class InputIterator, class ForwardIterator>
inline ForwardIterator
uninitialized_copy(InputIterator first, InputIterator last,
ForwardIterator result)
该函数一般用于在内存配置与对象构造分离的情况,例如vector,vector一般配置比所需元素个数更大的空间,那么在备用空间中放入新元素,就是uninitialized_copy该做的事。换句话说,如果作为输出目的地的 [ result, result+(last-first) ) 范围内的每一个迭代器都指向未初始化的区域,则uninitialized_copy() 会使用复制构造函数,把来自 [ first, last ) 范围的每一个对象产生一份复制品,放进输出范围中。针对输入范围的每一个迭代器 i,该函数会调用construct(&*(result+(i-first)), *i),而construct内部将会使用placement new,产生*i的复制品,放置于输出范围的相对位置上。
源码:
template <class InputIterator, class ForwardIterator>
inline ForwardIterator
uninitialized_copy(InputIterator first, InputIterator last,
ForwardIterator result) {
return __uninitialized_copy(first, last, result, value_type(result));
// 以上,利用 value_type() 取出 first 的 value type.
}
在该函数内,获取了迭代器所指对象的类型,并把它传给下一级函数__uninitialized_copy,我们继续追根溯源,看看这个__uninitialized_copy又是什么来头:
template <class InputIterator, class ForwardIterator, class T>
inline ForwardIterator
__uninitialized_copy(InputIterator first, InputIterator last,
ForwardIterator result, T*) {
typedef typename __type_traits<T>::is_POD_type is_POD; //利用type_traits机制,判断迭代器所指类型是否是POD类型
return __uninitialized_copy_aux(first, last, result, is_POD());
// 以上,企图利用 is_POD() 所获得的结果,让编译器做重载推导
}
__uninitialized_copy获取迭代器所指类型is_POD信息,但究竟是不是POD类型,函数内并没做判断,而是交给编译器做判断(参数推导重载)。而什么是PDO类型?POD意指Plain Old Data,也就是基本类型或传统的C 结构体。POD类型的对象必然拥有平凡的 构造 /默认构造 /拷贝构造 /赋值构造函数。
如果是POD类型,会采用最有效率的复制手法,可是这仍不会在这一层函数出现,而是在copy函数里。
template <class InputIterator, class ForwardIterator>
inline ForwardIterator
__uninitialized_copy_aux(InputIterator first, InputIterator last,
ForwardIterator result,
__true_type) {
return copy(first, last, result); // 呼叫 STL 算法 copy()
}
STL基本算法之一——copy
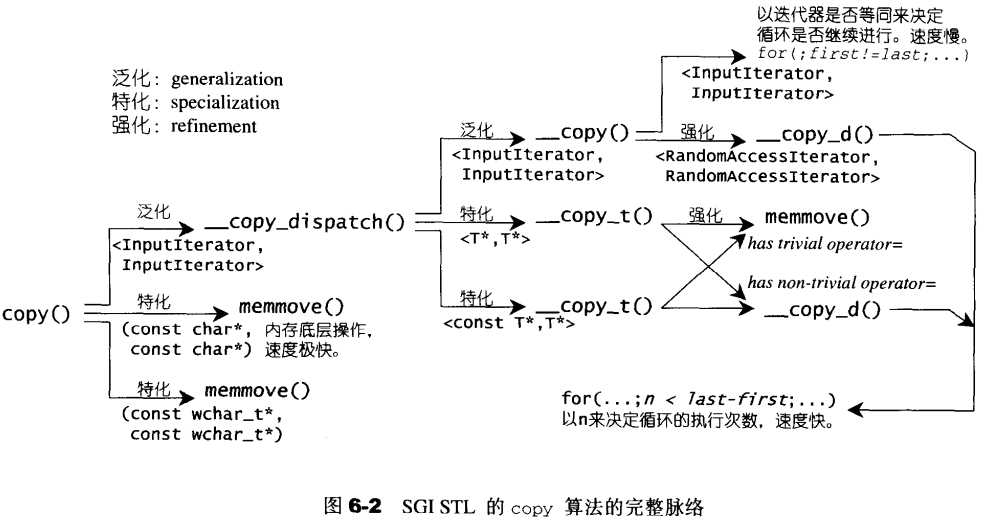
复制操作不外乎运用赋值运算符或者拷贝构造函数(copy用的是前者),但如果某些对象的类型是平凡的(trivial)的赋值运算符,则可以直接使用内存直接复制行为(如C函数memmove或memcoy),便能够节省大量时间。为此,copy算法用尽各种办法,包括函数重载、类型特性(type_traits)、偏特化等编程技艺,来提升复制的效率。
函数签名:
template <class InputIterator, class OutputIterator>
inline OutputIterator copy(InputIterator first, InputIterator last,
OutputIterator result)
该函数可将输入区间[ first, last ) 内的所有元素复制到输出区间 [ result, result+(last-first) ) 内,也就是说,它会执行赋值操作 *result = *first, *(result+1) = *(first+1),...以此类推。返回一个迭代器:result+(last-first)。copy函数对模板参数的要求非常宽松。输入区间可以是最低级的InputIterator,输出区间也是最低级的OuputIterator。这意味着,你可以使用该算法,将任何容器的任何一段区间的内容,复制到任何容器的任何一段区间上。能看到它的复制是向前推进的(之后还会学另外一种函数,是反向推进的)。
源码:上面那幅图是整个copy算法的脉络,配合它看源码能更容易理解
//完全泛化版本
template <class InputIterator, class OutputIterator>
inline OutputIterator copy(InputIterator first, InputIterator last,
OutputIterator result)
{
return __copy_dispatch<InputIterator, OutputIterator>()(first, last, result);
}
除了这个完全泛化版本,还提供两个特化版本,针对原生指针const char* 和 const wchar_t*,可以使用内存直接拷贝的操作:
inline char* copy(const char* first, const char* last, char* result) {
memmove(result, first, last - first);
return result + (last - first);
}
inline wchar_t* copy(const wchar_t* first, const wchar_t* last,
wchar_t* result) {
memmove(result, first, sizeof(wchar_t) * (last - first));
return result + (last - first);
}
为什么说memmove函数效率很高呢?因为该函数是直接按字节拷贝,简单地讲就是纯复制,不用考虑其他诸如构造、浅复制、深复制等因素,所以效率很高。所以如果允许的情况下,最好就就用这个函数和memcpy函数。至于memmove和memcpy有什么区别,搜一搜就有了。
copy函数的完全泛化版本调用了一个__copy_dispatch函数,这个函数有一个完全泛化版本和两个偏特化版本:
template <class InputIterator, class OutputIterator>
struct __copy_dispatch
{
//__copy_dispatch是一个结构体,但定义了operator()函数,即当使用__copy_dispatch(),调用的是__copy_dispatch()的函数对象
OutputIterator operator()(InputIterator first, InputIterator last,
OutputIterator result) {
return __copy(first, last, result, iterator_category(first)); //获取迭代器的类型,并根据编译器的参数推导机制选择合适的重载版本
}
};
而这两个偏特化版本针对的是模板参数为指针类型的,即传进来的是int*而非int这种情况:
template <class T>
struct __copy_dispatch<T*, T*>
{
T* operator()(T* first, T* last, T* result) {
typedef typename __type_traits<T>::has_trivial_assignment_operator t; //获取类型是否具有平凡的赋值运算符
return __copy_t(first, last, result, t());
}
}; template <class T>
struct __copy_dispatch<const T*, T*>
{
T* operator()(const T* first, const T* last, T* result) {
typedef typename __type_traits<T>::has_trivial_assignment_operator t;
return __copy_t(first, last, result, t());
}
};
这里兵分两路。首先__copy_dispatch的完全泛化版本会根据迭代器类型选择调用合适的__copy函数,为的是不同种类的迭代器所使用的循环条件不同,而效率也会不同。如果是最低级别的InputIterator,说明迭代器只具有逐次递增的功能,不具备随机访问的功能,所以在判断是否到达输入区间尾部这个问题上,需要每次递增后都要进行一次判断,效率较低:
template <class InputIterator, class OutputIterator>
inline OutputIterator __copy(InputIterator first, InputIterator last,
OutputIterator result, input_iterator_tag)
{
for (; first != last; ++result, ++first) //每轮循环开始前都要进行一次fisrt是否等于last的判断,效率慢
*result = *first;
return result;
}
如果是级别最高的Random Access Iterator,则具有了随机存取的能力,就可以利用它提供的operator-()计算出输出区间的大小n,然后以n决定循环的次数,这比两个迭代器作比较在效率上快多了。
template <class RandomAccessIterator, class OutputIterator>
inline OutputIterator
__copy(RandomAccessIterator first, RandomAccessIterator last,
OutputIterator result, random_access_iterator_tag)
{
return __copy_d(first, last, result, distance_type(first));
} template <class RandomAccessIterator, class OutputIterator, class Distance>
inline OutputIterator
__copy_d(RandomAccessIterator first, RandomAccessIterator last,
OutputIterator result, Distance*)
{
for (Distance n = last - first; n > ; --n, ++result, ++first) //Distance其实就是distance_type
*result = *first;
return result;
}
这是__copy_dispatch的完全泛化版本。现在回到兵分两路之前,__copy_dispatch具有两个偏特化版本,针对的是参数为原生指针类型和const原生指针类型,从这两个函数的主体中能看出,它想在“参数为原生指针类型”的前提下,探测其指针所指的类型是否具有平凡的赋值操作符。如果具有平凡的赋值运算符(即并无重载其赋值操作符),那么复制操作就可以不通过赋值操作符来进行,可以直接以组快速的内存对拷方式(memmove())完成。源码使用了我们之前学过的__type_traits<>编程技巧来侦测某个类型是否具有平凡的赋值操作符。
template <class T>
inline T* __copy_t(const T* first, const T* last, T* result, __true_type) {
//__true_type,拥有平凡赋值操作符(trivial assignment operator),使用内存对拷方式,效率最高
memmove(result, first, sizeof(T) * (last - first));
return result + (last - first);
} template <class T>
inline T* __copy_t(const T* first, const T* last, T* result, __false_type) {
//__false_type,拥有自定义的赋值操作符(non-trivial assignment operator),使用随机迭代器版本的复制操作
return __copy_d(first, last, result, (ptrdiff_t*));
}
至此,我们终于走到了uninitialized_copy的尽头,可谓是廓然开朗。
- uninitialized_fill

函数签名:
template <class ForwardIterator, class T>
inline void uninitialized_fill(ForwardIterator first, ForwardIterator last,
const T& x)
如果[ first, last ) 范围内每个迭代器都指向未初始化的内存,那么该函数会在该范围内产生x的复制品。换句话说,该函数会针对操作范围内的每个迭代器 i ,调用construct(&*i, x),在 i 所指之处产生x的复制品。
源码:
template <class ForwardIterator, class T>
inline void uninitialized_fill(ForwardIterator first, ForwardIterator last,
const T& x) {
__uninitialized_fill(first, last, x, value_type(first));
}
与uninitilized_copy一样,先获取迭代器所指的类型,然后再下一级函数中,判断其是否是POD类型:
template <class ForwardIterator, class T, class T1>
inline void __uninitialized_fill(ForwardIterator first, ForwardIterator last,
const T& x, T1*) {
typedef typename __type_traits<T1>::is_POD_type is_POD;
__uninitialized_fill_aux(first, last, x, is_POD());
}
再根据是否是POD类型,调用不同版本的__uninitialized_fill_aux。
如果是POD类型,则具有平凡的赋值操作符,就会进入到fill函数:
template <class ForwardIterator, class T>
inline void
__uninitialized_fill_aux(ForwardIterator first, ForwardIterator last,
const T& x, __true_type)
{
fill(first, last, x); // 呼叫 STL 算法 fill()
}
STL基本算法之二——fill()
fill函数就比copy简单多了,我们只会在类型为POD时才会调用该函数,所以该函数直接使用平凡的赋值操作符进行初值填写:
template <class ForwardIterator, class T>
void fill(ForwardIterator first, ForwardIterator last, const T& value) {
for (; first != last; ++first) // 遍历整个输入区间
*first = value;
}
如果不是POD类型,说明具有自己的赋值操作符,那么就不会使用赋值操作,而是直接在迭代器所指空间直接构造一个value:
template <class ForwardIterator, class T>
void
__uninitialized_fill_aux(ForwardIterator first, ForwardIterator last,
const T& x, __false_type)
{
ForwardIterator cur = first;
__STL_TRY{
for (; cur != last; ++cur)
construct(&*cur, x); // 必须一个一个构造,无法批量进行
}
__STL_UNWIND(destroy(first, cur));
}
- uninitialized_fill_n

函数签名:
template <class ForwardIterator, class Size, class T, class T1>
inline ForwardIterator __uninitialized_fill_n(ForwardIterator first, Size n,
const T& x, T1*)
如果[ first, first+n ),范围内的每一个迭代器都指向未初始化的空间,那么该函数会调用拷贝构造函数,在该范围内产生x的复制品。也就是说,对于[ first, first+n ),范围内的每个迭代器 i ,该函数会调用construct(&*i, x),在对应位置产生x的复制品。
源码:
template <class ForwardIterator, class Size, class T, class T1>
inline ForwardIterator __uninitialized_fill_n(ForwardIterator first, Size n,
const T& x, T1*) {
typedef typename __type_traits<T1>::is_POD_type is_POD;
return __uninitialized_fill_n_aux(first, n, x, is_POD());
}
有一说一,其实与上述两个函数类似,POD类型决定其使用什么样的复制手段,不是POD类型就直接构造,是就直接赋值。
template <class ForwardIterator, class Size, class T, class T1>
inline ForwardIterator __uninitialized_fill_n(ForwardIterator first, Size n,
const T& x, T1*) {
typedef typename __type_traits<T1>::is_POD_type is_POD;
return __uninitialized_fill_n_aux(first, n, x, is_POD());
}
不同的是,如果是POD类型,调用的是STL算法里面的fill_n函数:
template <class ForwardIterator, class Size, class T>
inline ForwardIterator
__uninitialized_fill_n_aux(ForwardIterator first, Size n,
const T& x, __true_type) {
return fill_n(first, n, x);
}
STL基本算法之三——fill_n()
将[ first, last ) 内的前n个元素改填新值,返回的迭代器指向被填入的最后一个元素的下一位置:
template <class OutputIterator, class Size, class T>
OutputIterator fill_n(OutputIterator first, Size n, const T& value) {
for (; n > ; --n, ++first) // 经过n个元素
*first = value; // 注意,assignment 是复写(overwrite)而不是安插(insert)
return first;
}
而对于非POD类型则采取最保险的做法:
template <class ForwardIterator, class Size, class T>
ForwardIterator
__uninitialized_fill_n_aux(ForwardIterator first, Size n,
const T& x, __false_type) {
ForwardIterator cur = first;
__STL_TRY{
for (; n > ; --n, ++cur)
construct(&*cur, x);
return cur;
}
__STL_UNWIND(destroy(first, cur));
}
STL源码剖析——算法#1 内存处理基本工具的更多相关文章
- STL源码剖析(算法)
STL中算法是基于迭代器来实现的. 有了容器中迭代器的实现(对operator*.operator++等的重载),STL中大部分算法实现就显得很简单了. 先看一例关于find算法的实现: templa ...
- (原创滴~)STL源码剖析读书总结1——GP和内存管理
读完侯捷先生的<STL源码剖析>,感觉真如他本人所说的"庖丁解牛,恢恢乎游刃有余",STL底层的实现一览无余,给人一种自己的C++水平又提升了一个level的幻觉,呵呵 ...
- STL"源码"剖析-重点知识总结
STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略多 :) 1.STL概述 STL提供六大组件,彼此可以组合 ...
- 【转载】STL"源码"剖析-重点知识总结
原文:STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点 ...
- STL"源码"剖析
STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略 ...
- 《STL源码剖析》相关面试题总结
原文链接:http://www.cnblogs.com/raichen/p/5817158.html 一.STL简介 STL提供六大组件,彼此可以组合套用: 容器容器就是各种数据结构,我就不多说,看看 ...
- STL源码剖析之序列式容器
最近由于找工作需要,准备深入学习一下STL源码,我看的是侯捷所著的<STL源码剖析>.之所以看这本书主要是由于我过去曾经接触过一些台湾人,我一直觉得台湾人非常不错(这里不涉及任何政治,仅限 ...
- 《STL源码剖析》读书笔记
转载:https://www.cnblogs.com/xiaoyi115/p/3721922.html 直接逼入正题. Standard Template Library简称STL.STL可分为容器( ...
- 面试题总结(三)、《STL源码剖析》相关面试题总结
声明:本文主要探讨与STL实现相关的面试题,主要参考侯捷的<STL源码剖析>,每一个知识点讨论力求简洁,便于记忆,但讨论深度有限,如要深入研究可点击参考链接,希望对正在找工作的同学有点帮助 ...
随机推荐
- codeforces B. A and B 找规律
Educational Codeforces Round 78 (Rated for Div. 2) 1278B - 6 B. A and B time limit per test 1 secon ...
- OOO的CSS
应ooo要求 寻找他手写一千年的css的继承人 html { background:#f7f7f7 url(images/bg-pattern.jpg) } body { margin:; paddi ...
- python格式化输出之format用法
format用法 相对基本格式化输出采用‘%’的方法,format()功能更强大,该函数把字符串当成一个模板,通过传入的参数进行格式化,并且使用大括号‘{}’作为特殊字符代替‘%’ 使用方法由两种:b ...
- Fluent Meshing生成interface
源视频链接: https://pan.baidu.com/s/1St4o-jB5KRfN5dLsvRe_vQ 提取码: 9rrr
- 帝国cms替换iwms幻灯图片问题
在管理标签模板中增加一个新模板 页面模板内容为:[!--empirenews.listtemp--]<!--list.var1-->[!--empirenews.listtemp--] 列 ...
- [Beta]Scrum Meeting#10
github 本次会议项目由PM召开,时间为5月15日晚上10点30分 时长15分钟 任务表格 人员 昨日工作 下一步工作 木鬼 撰写博客整理文档 撰写博客整理文档 swoip 为适应新功能调整布局前 ...
- window系统对应默认IE浏览器版本
- 【转】Android root检测方法总结
一 为什么要进行root检测?出于安全原因,我们的应用程序不建议在已经root的设备上运行,所以需要检测是否设备已经root,以提示用户若继续使用会存在风险. 二 root了会有什么风险?在Linux ...
- dubbo学习笔记(二)dubbo中的filter
转:https://www.cnblogs.com/cdfive2018/p/10219730.html dubbo框架提供了filter机制的扩展点(本文基于dubbo2.6.0版本). 扩展接口 ...
- Shared variable in python's multiprocessing
Shared variable in python's multiprocessing https://www.programcreek.com/python/example/58176/multip ...