2019-7-16 import / from...import... 模块的调用
模块调用的总结:如果你是pycharm打开文件,会自动帮你把文件根目录加到system.path中,你要调用模块直接以根目录为基准开始找。1.假如你要调用和文件根目录为同级的文件,你直接import 模块名。2.如果你要调用的模块在文件夹下,用from ... import ...的方式来找。
假如你的项目不是根目录的话,你可以通过sys.path.append(r'你的项目文件根目录') 比如下面的例子demo就是项目根目录
- demo
- -dir
- --md.py
- -run.py
- #第一种:
- 执行文件是md.py,被导入文件是run.py.现在我们是基于文件根目录来调用。因为run.py是直接在demo文件夹下,所以我们在md.py文件中写 import run 就是调用run模块了。
- #第二种:
- 执行文件是run.py,被导入文件是md.py。md.py在dir的文件夹下面,所以在run.py中写
- from dir import md 就是调用dir下面的md模块了。
一、模块
什么是模块:
模块:就是一系列功能的结合体
模块的三种来源:
1.内置的(python解释器自带的)
2.第三方的(别人写的,这个需要下载)
3.自定义的(你自己写的)
模块的四种表现形式:
1.使用python编写的py文件(也就意味着py文件也可以称之为模块:一个py文件也可以称之为一个模块)
2.已被编译为共享库或DLL的C或C++扩展(了解)
3.把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py文件,该文件夹称之为包)
4.使用C编写并连接到python解释器的内置模块
为什么要用模块:
1.用别人写好的模块(内置的,第三方的):典型的拿来主义,极大的提高开发效率
2.使用自己写的模块(自定义的):当程序比较庞大时候,你的项目不可能只在一个py文件中,可以把经常需要调用的方法写到一个单独的文件中,其他文件需要直接以模块的形式导过去调用即可。
如何使用模块:
注意:一定要区分哪个是执行文件,哪个是被导入文件(这个很重要)
二、import 导入模块的方法
两个文件在同级目录的情况下
有这样两个py文件:run.py(执行文件),md.py(被导入文件)
run.py文件(执行文件)
- import md
md.py文件(被导入文件)
- money = 1000
- def read1():
- print('md',money)
- def read2():
- print('md模块')
- read1()
- def change():
- global money
- money = 0
运行流程:这个是简单的两个文件在同级目录下调用,步骤在右边。
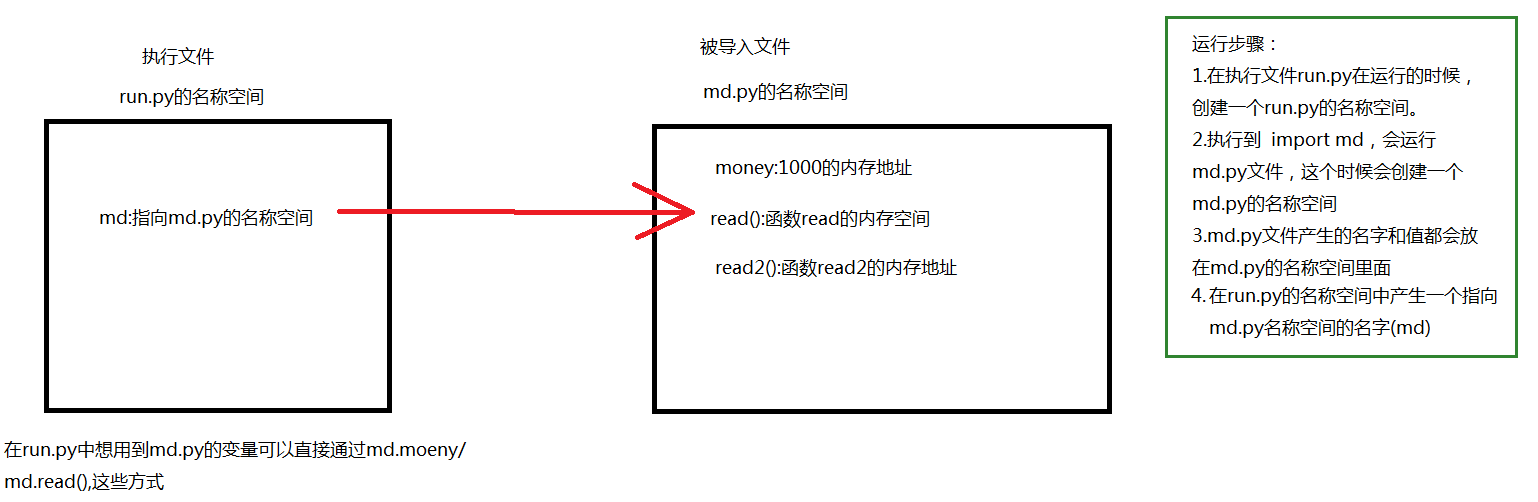
使用import导入模块 访问模块名称空间中的名字统一用:模块名. 名字
多次导入不会执行模块文件,会沿用第一次导入的成果(重点)
特点:
1.指名道姓的访问模块中的名字 永远不会与执行文件中的名字起冲突
2.你如果想访问模块中的名字 必须用模块名.名字的方式
当几个模块没有联系的时候 应该分多次导入。只要当几个模块有相同部分或者属于一个模块,就可以写在一行导入,通常导入模块会写在文件的开头。
当模块名字比较复杂的情况下 可以给该模块名取别名: import tsettttttttt as test 导入的模块名很长我们用as取一个别名,调用直接写test
三、from...import...导入模块的方法
在同级目录下进行操作
两个文件 run1.py(执行文件) md1.py(被导入文件)
run.py(执行文件)
- from md1 import money,read1,read2,change
- money = '我是执行代码里面的money'
- print(money)
md1(被导入文件)
- money = 1000
- def read1():
- print('md',money)
- def read2():
- print('md模块')
- read1()
- def change():
- global money
- money = 0
运行流程和import模块导入的流程一样:
1.先创建run1.py的名称空间
2.创建md1.py的名称空间
3.md1.py产生的名字和值都会放在md1.py的名称空间中
4.在run1.py的名称空间中产生一个指向md1.py名称空间的名字
在执行文件中使用了 from ... import ...之后,可以直接使用变量名了,不用再模块名.名字
但是 from...import..句式这种用法也有缺点:
在访问模块中的名字可能会与当前执行文件中的名字起冲突,比如:
你在执行文件中已经写了 from md1 import money (这个是调用md1.py文件中的money)
但是如果你还在下面写 mongey = '执行代码中的money',这个时候打印money出的结果就是 '执行代码中的money',把md1中的money值覆盖了。
补充:from md1 import * #一次性将md1模块中的名字全部加载出来,这个不推荐使用,而且你根本不知道 到底哪些名字可以用。
四、循环导入问题
三个文件:run.py(执行文件)、m1.py(被导入文件1)、m2.py(被导入文件2)
run.py(执行文件)
- import m1
m1.py(被导入文件1)
- print('正在导入m1')
- from m2 import y # 首次导入m2
- x = 'm1'
m2.py(被导入文件2)
- print('正在导入m2')
- from m1 import x # 第二次导m1
- y = 'm2'
m1,m2文件循环调用,运行流程:
1.先运行run.py,会产生run.py和m1.py的名称空间
2.执行import m1会运行m1.py文件,执行from m2 import y 生成m2.py名称空间
3.在m2.py文件中执行from m1 import x,但是模块m1已经运行过了模块文件,这次不会再导入,而是沿用上一次的m1,上一次的m1里面没有x,这里import不了x,所以这里报错,x未定义。
解决方法:
1.将导入模块文件的句式写在最下面。
m1.py文件
- print('正在导入m1')
- x = 'm1'
- from m2 import y # 首次导入m2
m2.py文件
- print('正在导入m2')
- y = 'm2'
- from m1 import x # 第二次导m1
运行流程:前面的流程是一样的,到第一次运行m1模块文件,会把x = 'm1'的值放在m1.py的名称空间中。再执行from m2 import y,运行m2.py文件,y = 'm2'的值放在m2.py名称空间中。再执行from m1 import x,因为之前已经运行过m1模块文件,所以这次是沿用之前的,因为在之前的m1.py名称空间中已经有x,所以这个就找的到,不会报错。m2中也有y,再次调用还是沿用之前的,也可以找到。
2.在函数内导入模块
把导入模块文件也在函数中
五、__name__的用法
1.当文件被当做执行文件执行的时候__name__打印的结果是__main__
2.当文件被当做模块导入的时候__name__打印的是模块名(没有后缀)
test1.py (执行文件:因为里面有import调用其他文件)
- def index1():
- print('index1')
- def index2():
- print('index2')
- import test
- print(__name__)
- #结果
test
__main__
test2.py (被导入文件)
- print(__name__)
六、模块的查找顺序
1.先在内存中找 (想要的模块先加载一遍,在内存中有一块内存空间 用先定义之后删除的方法举例子)
2.在内置中找 (内置模块time,假如设置一个time.py文件 ,在执行文件中import time 运行的结果是时间戳,说明先去内置中找模块)
3.在sys.path中找(类似于环境变量很多的路径) 是一个大列表,里面放了一堆文件路径,第一个路径永远是执行文件所在的文件夹
查找模块路径以执行文件所在的文件夹为准:(这个查找路径就是文件开头写的import/ from...import...)
第一种导入:基于当前执行文件所在文件夹路径下依次往下找
- demo
- -dir
- --md.py
- -run.py
- #如果run.py是执行文件,md.py是被导入文件,怎么调用??
- 我们找这个执行文件是在demo文件夹下,所以我们应该基于demo文件夹下开始找
- from dir import md 就找到了md模块
第二次导入:直接将你需要导入的那个模块所在的文件夹路径添加到system path中
(特别重要,这节课将的模块调用就可以用下面这一句话来概括)
将项目名所在的路径添加到system.path中,如果你是pycharm打开,pycharm会自动将顶级目录路径(就是项目文件的根目录)添加到system.path中,也就是说如果你是pycharm打开的文件就直接站在项目的根目录下调用模块,如果你不是pycharmd打开的文件你就把文件根目录加到system.path中,这样也能变成成文件根目录下面找了。
七、模块的绝对导入和相对导入
绝对导入必须依据执行文件所在的文件夹路径为准
1.绝对导入无论在执行文件中还是被导入文件中都适用
相对导入:
. 代表当前路径的文件夹
.. 代表上一级路径的文件夹
... 代表的是上上一级路径文件夹
注意:相对导入不能在执行文件中使用
相对导入只能在被导入的模块中使用,使用相对导入,就不需要考虑
执行文件到底是谁,只需要知道模块与模块之间的路径关系
八、软件开发规范
- 项目名
- bin文件夹
- start.py项目启动文件
- conf文件夹
- settings.py项目配置文件
- core文件
- src.py项目核心逻辑文件
- db文件夹
- 数据库文件
- lib文件夹
- common.py项目所用到的公共的功能
- log文件夹
- log.log项目的日志文件
- readme文本文件 介绍项目
2019-7-16 import / from...import... 模块的调用的更多相关文章
- python初步学习-import和datetime模块
模块 一个完整大型的python程序是由模块和包的形式组织起来的,可见模块在python中的重要性.模块是一种组织型式,它许多有关联(关系)的代码组织放到单独的独立文件中.简单的说,可以把模块理解为一 ...
- 模块的语法 import ,from...import....
------------------------积极的人在每一次忧患中都看到一个机会, 而消极的人则在每个机会都看到某种忧患 1. 认识模块 模块可以认为是一个py文件. 模块实际上是我们的py文件运 ...
- Python import语句导入模块语法[转]
Python import语句导入模块语法 社区推荐:掘金是国内最活跃的技术社区,我们每日有优质Python开发实例分享,海量python开源库推送.来掘金,和更多懂技术的小伙伴交流. pytho ...
- Python-学习-import语句导入模块
简单的学习一下调用外部的模块文件. 在Python中,模块是一种组织形式,它将彼此有关系的Pyrhon 代码组织到一个个独立的文件当中,模块可以包含可执行代码,函数,和类或者是这些东西的组合. 当我们 ...
- import方法引入模块详解
在python用import或者from...import或者from...import...as...来导入相应的模块,作用和使用方法与C语言的include头文件类似.其实就是引入某些成熟的函数库 ...
- Python进阶(八)----模块,import , from import 和 `__name__`的使用
Python进阶(八)----模块,import , from import 和 __name__的使用 一丶模块的初识 #### 什么是模块: # 模块就是一个py文件(这个模块存放很多相似的功能, ...
- import、from 模块 import*、reload
import 模块名.from 模块名 import* 均为导入模块,前者调用模块中函数或者变量时需要添加引用,即模块名.调用函数或者变量名 具体用法见下 https://jingyan.baidu. ...
- Python——import与reload模块的区别
原创声明:本文系博主原创文章,转载或引用请注明出处. 1. 语法不同 import sys reload('sys') 2. 导入特性不同 import 和reload都可以对同一个模块多次加载, ...
- Python之import方法引入模块详解
在python用import或者from-import或者from-import-as-来导入相应的模块,作用和使用方法与C语言的include头文件类似.其实就是引入某些成熟的函数库和成熟的方法,避 ...
随机推荐
- ent facebook 开源的golang orm 框架
ent 是facebook 开源的golang orm 框架,简单强大,具有提下特性 schema 即代码 方便的图遍历 静态类型以及显示api 多种存储引擎支持(当前是mysql,sqlite,以及 ...
- 为什么vue组件中的data不是一个对象而是一个函数
如果两个实例引用同一个对象,当其中一个实例的属性发生改变时,另一个实例属性也随之改变,只有当两个实例拥有自己的作用域时,才不会相互干扰. 这是因为JavaScript的特性所导致,在component ...
- 洛谷p2672推销员题解
日常扯废话: 话说题解里的思路都写得真的是很奈斯啊 但是 代码看不懂确实让人头疼(可能是我太弱了) 就像题解里的第一篇题解代码简洁但是属实看不明白 趁着学姐刚给我讲了知识还热乎赶紧给泥萌说说哈 正文: ...
- P3386 【模板】二分图匹配(匈牙利算法)
题目背景 二分图 题目描述 给定一个二分图,结点个数分别为n,m,边数为e,求二分图最大匹配数 输入输出格式 输入格式: 第一行,n,m,e 第二至e+1行,每行两个正整数u,v,表示u,v有一条连边 ...
- 洛谷P4735题解
若想要深入学习可持久化0-1Trie树,传送门. Description: 给定数列 \(\{a_n\}\) ,支持两种操作: 在数列尾添加一个数 \(x\) ,数列长度变成 \(n+1\) ; 给定 ...
- javaScript之DOM,BOM
javaScript之BOM / DOM: BOM(Browser Object Model)是指浏览器对象模型,它使 JavaScript 有能力与浏览器进行"对话". DOM ...
- NSGA-II算法学习
什么是支配: 支配就是统治,在各方面都优于其余个体 如个体i支配个体j,就说明个体i在所有目标函数的表现上都不差于个体j,并且至少在一个目标上优于个体j: 什么是非支配: 非支配就是个体在种群中是最优 ...
- Leetcode:2. 两数相加
题目描述: 给出两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字. 如果,我们将这两个数相加起来,则会返回一个新的链表来 ...
- 解决'maven lifecycle mapping not converted'的问题
基于maven的项目,使用各种maven plugin来完成开发中的各种工作,例如编译代码,打包,部署等等… 每个plugin包含许多的goal,用来做特定的事情.典型的基于java的maven项目就 ...
- visual studio 2019 企业版下载
由于visual studio从2017开始就是网络下载安装,所以网速慢的朋友安装上就存在时间感,所以笔者在百度云上提供了visual studio 2019的下载包.需要的朋友自己下载安装.不过,2 ...