hive的分桶原理
套话之分桶的定义:
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。对于 hive 中每一个表、分区都可以进一步进行分桶。
列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。(网上其它定义更详细,有点绕,结合后面实例)
适用场景:数据抽样( sampling )、map-join
干货之分桶怎么分:
1.开启支持分桶
set hive.enforce.bucketing=true;
默认:false;设置为 true 之后,mr 运行时会根据 bucket 的个数自动分配 reduce task 个数。
(用户也可以通过 mapred.reduce.tasks 自己设置 reduce 任务个数,但分桶时不推荐使用)
注意:一次作业产生的桶(文件数量)和 reduce task 个数一致。
2.往分桶表中加载数据
insert into table bucket_table select columns from tbl;
insert overwrite table bucket_table select columns from tbl;
3.桶表 抽样
select * from bucket_table tablesample(bucket 1 out of 4 on columns);
TABLESAMPLE 语法:
TABLESAMPLE(BUCKET x OUT OF y)
x:表示从哪个 bucket 开始抽取数据
y:必须为该表总 bucket 数的倍数或因子
4.分桶实例(详解)
具体如下:
1.启动hive(远程一体化模式):①service iptables stop // ② service mysqld start // ③hive ---service metastore //④ hive(老套路)
2.准备:在node03节点的root/hivedata目录下 创建一个数据文件ft
①vim ft

1 zhang 12
2 lisi 34
3 wange 23
4 zhouyu 15
5 guoji 45
6 xiafen 48
7 yanggu 78
8 liuwu 41
9 zhuto 66
10 madan 71
11 sichua 89
注意:这里的数据间是用制表符'\t'来分隔的,后面在建表的时候要注意 terminated by '\t'; 不然导入表中的数据因为格式不符出现'null'
②在数据库heh.db中建表:
hive> CREATE TABLE ft( id INT, name STRING, age INT)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t';
OK
Time taken: 0.216 seconds
hive> load data local inpath'/root/hivedata/ft' into table ft;
Loading data to table hehe.ft
Table hehe.ft stats: [numFiles=1, totalSize=127]
OK
Time taken: 1.105 seconds
hive> select *from ft;
OK
1 zhang 12
2 lisi 34
3 wange 23
4 zhouyu 15
5 guoji 45
6 xiafen 48
7 yanggu 78
8 liuwu 41
9 zhuto 66
10 madan 71
11 sichua 89
NULL NULL NULL
Time taken: 0.229 seconds, Fetched: 12 row(s)
再创建一张分桶表fentong并把ft的数据插入到fentong:
hive> create table fentong(
> id int,
> name string,
> age int,)clustered by(age) into 4 buckets
> row format delimited fields terminated by ','; 创建一张表:它以字段age来划分成4个桶 插入数据:
hive> insert into table fentong select name,age from ft; ok! 现在分桶表中出现之前创建的数据:select * from fentong
③执行抽样: select id, name, age from fentong tablesample(bucket 1 out of 4 on age);
网上很多案例教程说的非常绕,一时很难离清楚,现分享如下通俗 易懂的教程:
怎么分:①在前面创建分桶表的时候有这样语句:age int,)clustered by(age) into 4 buckets 说明本案例是以年龄age来划分成4个桶;
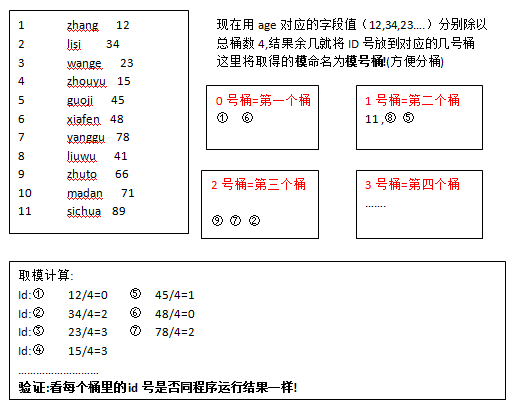
分桶的数据怎么分到四个桶:它是将表中对应的字段值(比如age)分别来除以桶的个数4,结果取余数(也就是取模),若余数为0就放到1号桶,余数为1就放到2号桶
余数为2就放到3号桶,余数为3就放到4号桶
②这句话怎么理解:select id, name, age from psnbucket tablesample(bucket 2 out of 4 on age);
它是说:将你的数据划分成4个桶,取四个桶中的第一个桶的数据
③运行程序
hive> select id, name, age from fentong tablesample(bucket 1 out of 4 on age);
OK
NULL NULL NULL
6 xiafen 48
1 zhang 12 hive> select id, name, age from fentong tablesample(bucket 2 out of 4 on age);
OK
11 sichua 89
8 liuwu 41
5 guoji 45 hive> select id, name, age from fentong tablesample(bucket 3 out of 4 on age);
OK
9 zhuto 66
7 yanggu 78
2 lisi 34
④推算过程:
hive的分桶原理的更多相关文章
- Hive的分桶表
[分桶概述] Hive表分区的实质是分目录(将超大表的数据按指定标准细分到指定目录),且分区的字段不属于Hive表中存在的字段:分桶的实质是分文件(将超大文件的数据按指定标准细分到分桶文件),且分桶的 ...
- Hive 的分桶 & Parquet 概念
分区 & 分桶 都是把数据划分成块.分区是粗粒度的划分,桶是细粒度的划分,这样做为了可以让查询发生在小范围的数据上以提高效率. 分区之后,分区列都成了文件目录,从而查询时定位到文件目录,子数据 ...
- hive,分桶,内外部表,分区
简单的word-count操作: [root@master test-map]# head -10 The_Man_of_Property.txt #先看看数据Preface“The Forsy ...
- hive的分桶
套话之分桶的定义: 分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储.对于 hive 中每一个表.分区都可以进一步进行分桶. 列的哈希值除以桶的个数来决定每条数据划分在哪个桶中.(网上其它定 ...
- hive学习笔记之五:分桶
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive 分区表和分桶表
1.创建分区表 hive> create table weather_list(year int,data int) partitioned by (createtime string,area ...
- Hive动态分区和分桶(八)
Hive动态分区和分桶 1.Hive动态分区 1.hive的动态分区介绍 hive的静态分区需要用户在插入数据的时候必须手动指定hive的分区字段值,但是这样的话会导致用户的操作复杂度提高,而且在 ...
- hive 分桶及抽样调查
1.分桶的概述 分区提供了一个隔离数据和优化查询的遍历方式.不是所有的数据集都可形成合力的分区 对于一张表或者分区,hive可以进一步组织成桶,也就是更为细粒度的数据范围 分区针对的是数据的存储路径( ...
- Hive SQL之分区表与分桶表
Hive sql是Hive 用户使用Hive的主要工具.Hive SQL是类似于ANSI SQL标准的SQL语言,但是两者有不完全相同.Hive SQL和Mysql的SQL方言最为接近,但是两者之间也 ...
随机推荐
- gitlab修改IP地址及仓库地址
将IP修改为192.168.10.100,操作方法 . 先修改本地的IP地址 vim /etc/sysconfig/network-scripts/ifcfg-eth0TYPE=EthernetBOO ...
- 玩转Spring--消失的事务@Transactional
消失的事务 端午节前,组内在讨论一个问题: 一个没有加@Transactional注解的方法,去调用一个加了@Transactional的方法,会不会产生事务? 文字苍白,还是用代码说话. 先写一个@ ...
- Spring Boot 之:Spring Boot Admin
client 连接都 admin 时报错: 2019-08-22 11:58:37.695 ERROR 55095 --- [nio-8000-exec-1] o.a.catalina.connect ...
- 为什么 JVM 不用 JIT 全程编译?
考虑到跨平台,所以无法使用AOT: 考虑到执行效率,所以无法全部使用JIT: 编译技术大约分为两种,一种AOT,只线下(offline)就将源代码编译成目标机器码,这是普遍用在系统程序语言中:另一种是 ...
- Wooden Signs Gym - 101128E (DP)
Problem E: Wooden Signs \[ Time Limit: 1 s \quad Memory Limit: 256 MiB \] 题意 给出一个\(n\),接下来\(n+1\)个数, ...
- [RN] React Native 使用 FlatList 和 ScrollView 的下拉刷新问题
React Native 使用 FlatList 和 ScrollView 实现 下拉刷新时,RefreshControl 控件不起作用, 后来经查明,原来 RefreshControl 要加在 Sc ...
- kafk设计要点
kafka的设计目标是高吞吐量,所以kafka自己设计了一套高性能但是不通用的协议,他是仿照AMQP( Advanced Message Queuing Protocol 高级消息队列协议)设计的 ...
- send 和recv小结
不论是客户还是服务器应用程序都用send函数来向TCP连接的另一端发送数据. 不论是客户还是服务器应用程序都用recv函数从TCP连接的另一端接收数据. #include <sys/socket ...
- 为什么学习JavaScript设计模式,因为它是核心
那么什么是设计模式呢?当我们在玩游戏的时候,我们会去追求如何最快地通过,去追求获得已什么高效率的操作获得最好的奖品:下班回家,我们打开手机app查询最便捷的路线去坐车:叫外卖时候,也会找附近最近又实惠 ...
- 06-图2 Saving James Bond - Easy Version (25 分)
This time let us consider the situation in the movie "Live and Let Die" in which James Bon ...