Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0
公司平台的分布式文件系统基于Hadoop HDFS技术构建,为开发人员学习及后续项目中Hadoop HDFS相关操作提供技术参考特编写此文档。本文档描述了Linux单机环境下Hadoop HDFS伪分布式集群的安装步骤及基本操作,包括:Hadoop HDFS的安装、配置、基本操作等内容。
参考文档
《Hadoop: Setting up a Single Node Cluster.》
http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/SingleCluster.html
HDFS说明
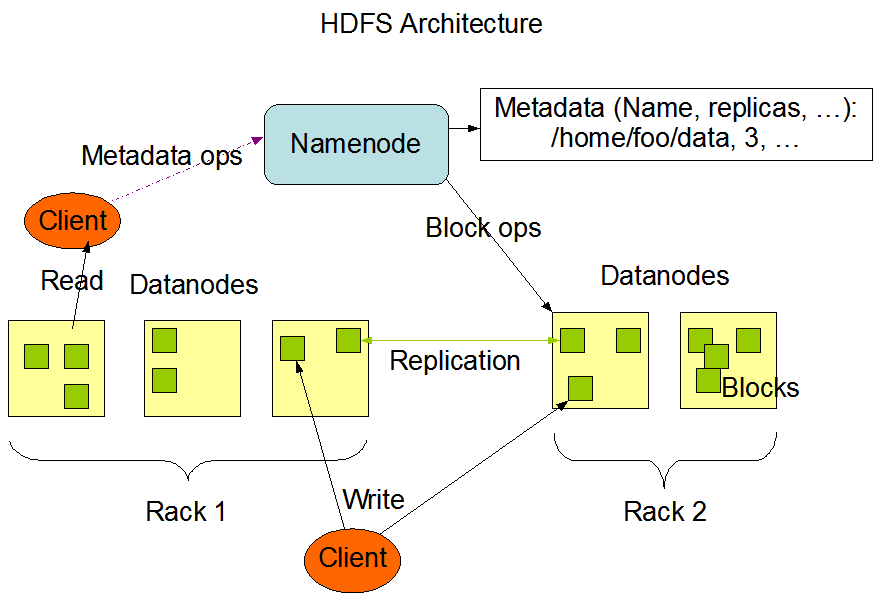

服务器规划
正常的Hadoop集群环境最少需要3台以上的服务器组合,而且要保持一半以上的服务器存活量。
而目前客户方只提供了一台服务器,那就只能安装伪分布式集群环境,即namenode、datanode和secondarynamenode均存放在一台机器上。
服务器信息:
地址:10.36.161.153
用户:root
JDK安装目录:/ZIP_HDFS_DATAS/jdk1.7.0_80
HDFS安装目录:/ZIP_HDFS_DATAS/hadoop-2.7.3
HDFS数据目录:/ZIP_HDFS_DATAS/hadoop-2.7.3/data
配置hosts
在/etc/hosts配置文件中配置服务器IP和主机名之间的映射关系;
如:10.36.161.153 hdfs iZ88rvassw1Z
其中中间的hdfs是一个伪主机名,因为hadoop对主机的命名很挑剔,不能太长或有一些特殊字符,因此在真正的主机名之前添加一个简单的、短的主机名骗一骗hadoop。
创建用户
hadoop可以以root用户安装和运行,也可以使用普通用户安装和运行。
本次安装没有特殊要求使用普通用户安装,则在root用户下执行。
如果需要在普通用户下安装及运行则使用如下命令创建用户和修改密码:
useradd -m vHADOOP-1
passwd vHADOOP-1
上传安装介质
通过SFTP等工具将JDK和Hadoop的安装介质上传至服务器;
本次安装使用的版本如下:
jdk-7u80-linux-x64.tar.gz
hadoop-2.7.3.tar.gz
JDK下载地址:
http://www.oracle.com/technetwork/java/javase/archive-139210.html
Hadoop下载地址(是不是很贴心?):
http://hadoop.apache.org/releases.html
安装JDK并配置环境变量
在用户根目录(如:/root/)下执行如下命令:
vi .bash_profile
添加如下内容:
export JAVA_HOME=/ZIP_HDFS_DATAS/jdk1.7.0_80
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存退出。
之后执行如下命令生效最新环境变量配置:
source .bash_profile
安装HDFS
Hadoop HDFS单机安装比较简单,解压安装介质即可完成安装。
解压命令:tar zxvf hadoop-2.7.3.tar.gz
备注:按照服务器规划章节中本次解压在/ZIP_HDFS_DATAS/hadoop-2.7.3目录。
因为数据目录和hadoop安装在同一个目录中,需要手动创建数据文件夹:
cd /ZIP_HDFS_DATAS/hadoop-2.7.3
mkdir -p data/tmp
修改HDFS配置
Hadoop的配置文件统一放置在<HADOOP_HOME>/etc/hadoop/目录下。
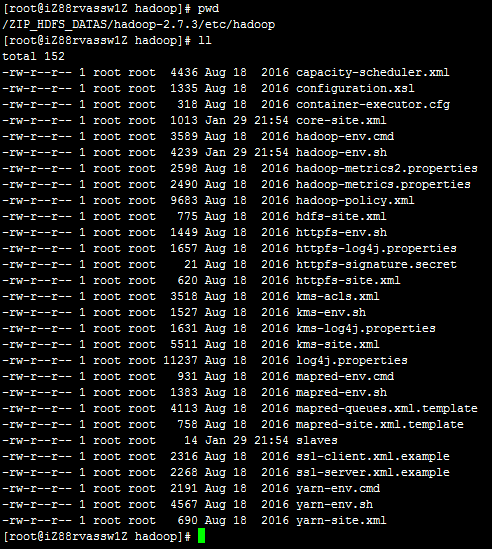
这里面包含了很多配置文件,跟HDFS相关的配置文件包括:
- core-site.xml
- slaves
另外还需要配置Hadoop的启动脚本,引入JDK变量:
- hadoop-env.sh
- core-site.xml
core-site.xml配置文件是对HDFS的基本配置。
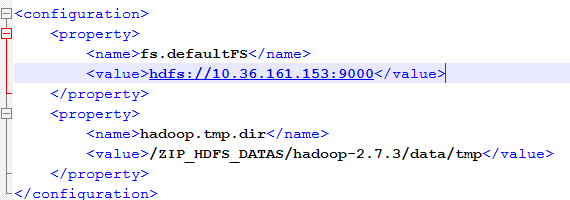
使用了默认的“fs.defaultFS”方式存储文件,其中IP为HDFS所在服务器的IP地址;
数据目录存储在指定的目录中;
- slaves
slaves指定了集群有哪些节点,目前只有一台只指向本机IP即可。
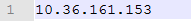
- hadoop-env.sh

配置SSH免密登录
为避免每次启动或停止Hadoop都需要输入密码,执行如下命令进行SSH免密登录:
ssh-keygen -t rsa
一路回车即可。
格式化NameNode
就像新买的硬盘需要格式化一样,新建好的HDFS也需要对NameNode进行格式化。
目录:<HADOOP_HOME>/bin
命令:./hdfs namenode -format
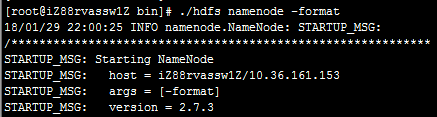
一长串的日志输出后,在最后找到如下内容:

当看到“... has been successfully formatted.”字样时代表格式化成功,如果格式化错误,请详细查看输出日志。
启动HDFS
命令目录:<HADOOP_HOME>/sbin/
执行命令:./start-dfs.sh
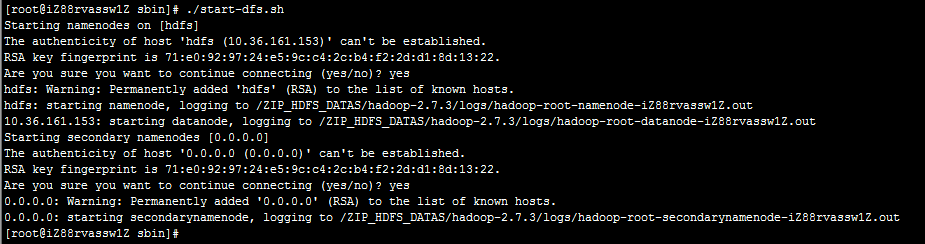
因为配置了SSH免密登录,因此不需要再次输入密码,另外,启动过程中输出了相关角色的日志路径,如果启动时发生错误,请查阅日志内容。
验证HDFS
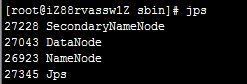
启动完成后,通过执行jps命令查看所有角色的进程是否都存在。
执行命令:jps
输出结果:应当包含NameNode、DataNode、SecondaryNameNode三个进程。
访问Hadoop控制台
Hadoop提供了一个Web控制台用于查看Hadoop的管理,访问地址如下:
HDFS启停命令
HDFS服务器启停命令目录:<HADOOP_HOME>/sbin
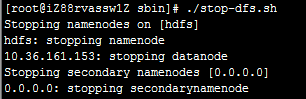
启动HDFS:./start-dfs.sh
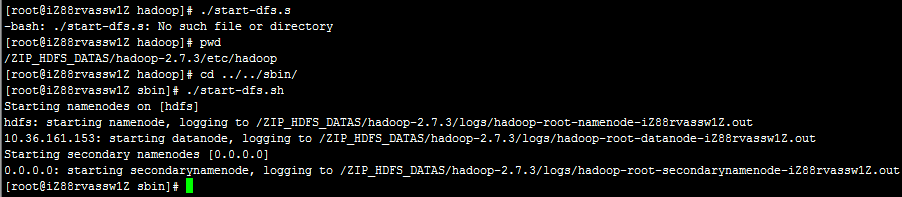
停止HDFS:./stop-dfs.sh
HDFS日志查看
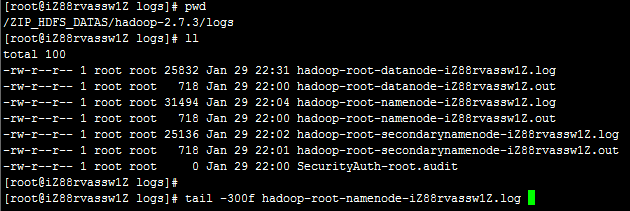
HDFS的日志文件文件位于<Hadoop_Home>/logs/目录下;
日志文件按照不同namenode、datanode和secondarynamenode角色进行了文件区分。每种角色的日志包括了out和log结尾的文件,查看日志时请查看以log结尾的日志文件。
查看namenode日志:
tail -300f hadoop-root-namenode-iZ88rvassw1Z.log
查看datanode日志:
tail -300f hadoop-root-datanode-iZ88rvassw1Z.log
查看secondarynamenode日志:
tail -300f hadoop-root-secondarynamenode-iZ88rvassw1Z.log
HDFS基本操作
HDFS基本操作命令的目录在<HADOOP_HOME>/bin
主要通过hdfs命令进行操作;
基本语法
./hdfs dfs -命令 目录或者文件名
eg: ./hdfs dfs -ls /datas
以上命令是列出HDFS中“/datas”目录下的所有文件。
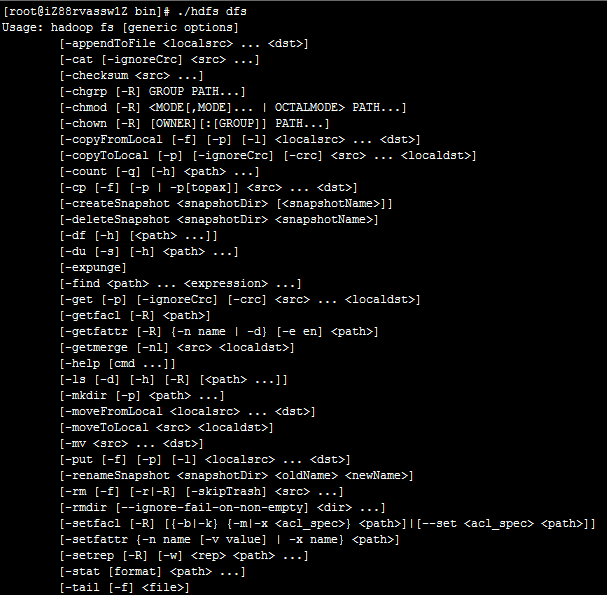
命令说明
直接在命令行输入:./hdfs dfs即可打印命令帮助。
可以看到,对HDFS的操作和Linux环境下对文件的操作命令基本相同。
基本操作
查看目录
./hdfs dfs -ls 目录名称
上传文件
./hdfs dfs -put 本地文件路名 HDFS文件路径
下载文件
./hdfs dfs -get HDFS文件路径 本地文件路名
移动文件
./hdfs dfs -mv 原路径 目标路径
删除文件
./hdfs dfs -rm 文件路径
删除目录
./hdfs dfs -rmdir 目录路径
修改权限
./hdfs dfs -chmod 权限 文件或目录路径
备注:其余命令请参考帮助信息接口。
Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0的更多相关文章
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- kafka2.9.2的伪分布式集群安装和demo(java api)测试
目录: 一.什么是kafka? 二.kafka的官方网站在哪里? 三.在哪里下载?需要哪些组件的支持? 四.如何安装? 五.FAQ 六.扩展阅读 一.什么是kafka? kafka是LinkedI ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- zookeeper伪分布式集群安装
1.安装3个zookeeper 1.1创建集群安装的目录 1.2配置一个完整的服务 这里不做详细说明,参考我之前写的 zookeeper单节点安装 进行配置即可,此处直接复制之前单节点到集群目录 创建 ...
- (转)CentOS7.4环境下搭建--Gluster分布式集群存储
原文:https://blog.csdn.net/qq_39591494/article/details/79853038 环境如下:OS:Centos7.4x86_64IP地址如下: Daasban ...
- 大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念: Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoo ...
随机推荐
- Android网络编程(三)Volley使用方法全解析
相关文章 Android网络编程(一)HTTP协议原理 Android网络编程(二)HttpClient与HttpURLConnection 前言 Volley想必许多人都用过,为了建立网络编程的知识 ...
- gnu-ucos 增加 bmp 位图显示
昨天又下了点功夫弄了个在tft屏幕上显示bmp位图的. 我选择的是24位tft真彩測显示方式所以也要选择真彩色位图.网上给出的16位位图数组无法使用.在csdn上下载了2个制作工具,一个是c代码的,一 ...
- 设置清除html5页面缓存
设置清除html5页面缓存 html5端设置 meta 标签: <meta http-equiv="Pragma" content="no-cache" ...
- VS2010打开高版本VS解决方案
http://blog.csdn.net/backspace110/article/details/62111273 Microsoft Visual Studio Solution File, Fo ...
- Codefoces 791D. Bear and Tree Jumps 树形DP
D. Bear and Tree Jumps A tree is an undirected connected graph without cycles. The distance betwee ...
- linux driver开发
1 开发linux driver时的调试思路 基本上是打印调试,原因很简单,方便.或者使用工具挂住cpu.
- Synthesizing Images of Humans in Unseen Poses
Synthesizing Images of Humans in Unseen Poses balakg/posewarp-cvpr2018 https://github.com/balakg/pos ...
- http://www.freetds.org/userguide/what.htm
FreeTDS is re-implementation of C libraries originally marketed by Sybase and Microsoft SQL Server. ...
- 计算机学院大学生程序设计竞赛(2015’11)1005 ACM组队安排
1005 ACM组队安排 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Pro ...
- easyui表格格线错位
现象:如果easyui表格中存在后渲染的linkbutton,则可能会导致表格固定列的格线与内容列的格线不一致,出现这种情况的原因是在表格的onLoadSuccess事件中渲染linkbutton时, ...