通过/proc/cpuinfo判断CPU数量、Multicores、Multithreading、Hyper-threading
http://blog.sina.com.cn/s/blog_4a6151550100iowl.html
判断依据:
1.具有相同core id的cpu是同一个core的超线程。
2.具有相同physical id的cpu是同一颗cpu封装的线程或者cores。
英文版:
1.Physical id and core id are not necessarily consecutive but they are unique. Any cpu with the same core id are hyperthreads in the same core.
2.Any cpu with the same physical id are threads or cores in the same physical socket.
比如 cat /proc/cpuinfo 显示4个逻辑CPU,通过physical id,前面两个逻辑cpu的相同,后面两个的相同,则有两个物理CPU。前面两个的 core id相同,后面的两个core ID相同,说明这两个CPU都是单核。也就是说两个单核cpu,启用了超线程技术。
是否为超线程?
如果有两个逻辑CPU具有相同的”core id”,那么超线程是打开的。
其他特征:
目前intel新的多核心cpu都会在后面显示具体的型号数字,例如:
model name : Intel(R) Xeon(R) CPU X3230 @ 2.66GHz
说明是 Xeon 3230的cpu,而不显示型号的具体数字的,大部分都是奔腾的CPU
很多主机商都骗人,用奔腾的cpu,却说是多核心的CPU。
探针看到的数据:
类型:Intel(R) Xeon(TM) CPU 2.80GHz 缓存:1024 KB
类型:Intel(R) Xeon(TM) CPU 2.80GHz 缓存:1024 KB
类型:Intel(R) Xeon(TM) CPU 2.80GHz 缓存:1024 KB
类型:Intel(R) Xeon(TM) CPU 2.80GHz 缓存:1024 KB
没有具体的型号,缓存1M,一般都是奔腾系列的cpu,或者是intel假双核的cpu,具体要根据上面说的去判断。新的多核心cpu都能看到具体的型号。
另外多核心的xeon的CPU,一般主频都不高,达到2.8和3.0的只有很少的几个高端CPU型号,一般主机商不会用这么好的。
http://blog.csdn.net/carle2008/article/details/2709966
rpm i386 i586 i686 之间的区别
有的rpm包有分i386 i586 i686等不同版本,如:
abc-1.2.3-4.i386.rpm
abc-1.2.3-4.i586.rpm
abc-1.2.3-4.i686.rpm
它们有什么不同呢?
这里的i386 i586 i686指的是适用于intel i386、 i586、i686 兼容指令集的微处理器。一般来说,等级愈高的机器可接受较低等级的rpm文件。
i386—几乎所有的X86平台,不论是旧的pentum或者是新的pentum-IV与K7系统CPU,都可以正常工作,i指得是Intel兼容的CPU,至于386就是CPU的等级。
i586—就是586等级的计算机,包括pentum第一代MMX CPU,AMD的K5,K6系统CPU(socket7插脚)等CPU都是这个等级。
i686—pentum 2 以后的Intel系统CPU及K7以后等级的CPU都属于这个686等级。
你可以透过/proc/cpuinfo这个档案查询你的CPU等级。
/proc/cpuinfo
This virtual file identifies the type of processor used by your system. The following is an example of the output typical of /proc/cpuinfo:
processor : 0 vendor_id : GenuineIntel cpu family : 15 model : 2 model name : Intel(R) Xeon(TM) CPU 2.40GHz stepping : 7 cpu MHz : 2392.371 cache size : 512 KB physical id : 0 siblings : 2 runqueue : 0 fdiv_bug : no hlt_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 2 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm bogomips : 4771.02
· processor — Provides each processor with an identifying number. On systems that have one processor, only a 0 is present.
· cpu family — Austhoritatively identifies the type of processor in the system. For an Intel-based system, place the number in front of "86" to determine the value. This is particularly helpful for those attempting to identify the architecture of an older system such as a 586, 486, or 386. Because some RPM packages are compiled for each of these particular architectures, this value also helps users determine which packages to install.
· model name — Displays the common name of the processor, including its project name.
· cpu MHz — Shows the precise speed in megahertz for the processor to the thousandths decimal place.
· cache size — Displays the amount of level 2 memory cache available to the processor.
· siblings — Displays the number of sibling CPUs on the same physical CPU for architectures which use hyper-threading.
· flags — Defines a number of different qualities about the processor, such as the presence of a floating point unit (FPU) and the ability to process MMX instructions.
/proc/cpuinfo 文件包含系统上每个处理器的数据段落。/proc/cpuinfo 描述中有 6 个条目适用于多内核和超线程(HT)技术检查:processor, vendor id, physical id, siblings, core id 和 cpu cores。
processor 条目包括这一逻辑处理器的唯一标识符。
physical id 条目包括每个物理封装的唯一标识符。
core id 条目保存每个内核的唯一标识符。
siblings 条目列出了位于相同物理封装中的逻辑处理器的数量。
cpu cores 条目包含位于相同物理封装中的内核数量。
如果处理器为英特尔处理器,则 vendor id 条目中的字符串是 GenuineIntel。
1.拥有相同 physical id 的所有逻辑处理器共享同一个物理插座。每个 physical id 代表一个唯一的物理封装。
2.Siblings 表示位于这一物理封装上的逻辑处理器的数量。它们可能支持也可能不支持超线程(HT)技术。
3.每个 core id 均代表一个唯一的处理器内核。所有带有相同 core id 的逻辑处理器均位于同一个处理器内核上。
4.如果有一个以上逻辑处理器拥有相同的 core id 和 physical id,则说明系统支持超线程(HT)技术。
5.如果有两个或两个以上的逻辑处理器拥有相同的 physical id,但是 core id 不同,则说明这是一个多内核处理器。cpu cores 条目也可以表示是否支持多内核。
例如,如果系统包含两个物理封装,每个封装中又包含两个支持超线程(HT)技术的处理器内核,则 /proc/cpuinfo 文件将包含此数据。(注:数据并不在表格中。)
|
processor |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
physical id |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
|
core id |
0 |
2 |
1 |
3 |
0 |
2 |
1 |
3 |
|
siblings |
4 |
4 |
4 |
4 |
4 |
4 |
4 |
4 |
|
cpu cores |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
此例说明逻辑处理器 0 和 4 驻留在物理封装 0 的内核 0 上。这就表示逻辑处理器 0 和 4 支持超线程(HT)技术。相同的工作可用于封装 0 内核 1 上的逻辑处理器 2 和 6,封装 1 内核 2 上的逻辑处理器 1 和 5,以及封装 1 内核 3 上的逻辑处理器 3 和 7。此系统支持超线程(HT)技术,因为两个逻辑处理器共享同一个内核。有两种方式可以确定是否支持多内核。由于内核 0 和 1 存在于封装 0上,而内核 2 和 3 存在于封装 1 上,所以这是一个多内核系统。此外,cpu cores 条目为 2,也说明有两个内核驻留在物理封装中。这是一个多路系统,因为有两个封装。
值得注意的是 physical id 和 core id 的编号可能是也可能不是连续的。系统上有两个物理封装并不罕见,而且 physical id 等于 0 和 3
CPU ID
CPU ID是CPU生产厂家为识别不同类型的CPU,而为CPU制订的不同的单一的代码;不同厂家的CPU,其CPU ID定义也是不同的;如 “0F24”(Inter处理器)、“681H”(AMD处理器),根据这些数字代码即可判断CPU属于哪种类型,这就是一般意义上的CPU ID。
由 于计算机使用的是十六进制,因此CPU ID也是以十六进制表示的。Inter处理器的CPU ID一共包含四个数字,如“0F24”,从左至右分别表示 Type(类型)、Family(系列)、Mode(型号)和Stepping(步进编号)。从CPUID为“068X”的处理器开始,Inter另外增 加了Brand ID(品种标识)用来辅助应用程序识别CPU的类型,因此根据“068X”CPUID还不能正确判别Pentium和Celerom处理 器。必须配合Brand ID来进行细分。AMD处理器一般分为三位,如“681”,从左至右分别表示为Family(系列)、Mode(型号)和 Stepping(步进编号)。
Type(类型)
类型标识用来区别INTEL微处理器是用于由最终用户安装,还是由专业个人计算机系 统集成商、服务公司或制作商安装;数字“1”标识所测试的微处理器是用于由用户安装的;数字“0”标识所测试的微处理器是用于由专业个人计算机系统集成 商、服务公司或制作商安装的。我们通常使用的INTEL处理器类型标识都是“0”,“0F24”CPUID就属于这种类型。
Family(系列)
系 列标识可用来确定处理器属于那一代产品。如6系列的INTEL处理器包括Pentium Pro、Pentium II、Pentium II Xeon、Pentium III和Pentium III Xeon处理器。5系列(第五代)包括Pentium处理器和采用 MMX技术的Pentium处理器。AMD的6系列实际指有K7系列CPU,有DURON和ATHION两大类。最新一代的 INTEL Pentium 4系列处理器(包括相同核心的Celerom处理器)的系列值为“F”
Mode(型号)
型号标识可用来 确定处理器的制作技术以及属于该系列的第几代设计(或核心),型号与系列通常是相互配合使用的,用于确定计算机所安装的处理器是属于某系列处理器的哪种特 定类型。如可确定Celerom处理器是Coppermine还是Tualutin核心;Athlon XP处理器是Paiomino还是 Thorouhgbred核心。
Stepping(步进编号)
步进编号用来标识处理器的设计或制作版本,有助于控制和跟踪处理器的更 改,步进还可以让最终用户更具体地识别其系统安装的处理器版本,确定微处理器的内部设计或制作特性。步进编号就好比处理器的小版本号,如CPUID为 “686”和“686A”就好比WINZIP8.0和8.1的关系。步进编号和核心步进是密切联系的。如CPUID为“686”的Pentium III 处理器是cCO核心,而“686A”表示的是更新版本cD0核心。
Brand ID(品种标识)
INTEL从Coppermine核心的处理器开始引入Brand ID作为CPU的辅助识别手段。如我们通过Brand ID可以识别出处理器究竟是Celerom还是Pentium 4。
判断CPU是否64位,检查cpuinfo中的flags区段,看是否有lm标识。
Are the processors 64-bit?
A 64-bit processor will have lm ("long mode") in the flags section of cpuinfo. A 32-bit processor will not.
http://en.wikipedia.org/wiki/Multi-core
Multi-core processor
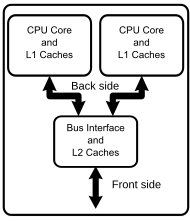

Diagram of a generic dual-core processor, with CPU-local level 1 caches, and a shared, on-die level 2 cache.

An Intel Core 2 Duo E6750 dual-core processor.

An AMD Athlon X2 6400+dual-core processor.
A multi-core processor is a single computing component with two or more independent actual central processing units (called "cores"), which are the units that read and execute program instructions.[1] The instructions are ordinary CPU instructions such as add, move data, and branch, but the multiple cores can run multiple instructions at the same time, increasing overall speed for programs amenable to parallel computing.[2] Manufacturers typically integrate the cores onto a single integrated circuit die (known as a chip multiprocessor or CMP), or onto multiple dies in a single chip package.
Processors were originally developed with only one core. A dual-core processor has two cores (e.g. AMD Phenom II X2, Intel Core Duo), a quad-core processor contains four cores (e.g. AMD Phenom II X4, Intel's quad-core processors, see i5, and i7 at Intel Core), a 6-core processor contains six cores (e.g. AMD Phenom II X6, Intel Core i7 Extreme Edition 980X), an 8-core processor contains eight cores (e.g. Intel Xeon E7-2820, AMD FX-8350), a 10-core processor contains ten cores (e.g. Intel Xeon E7-2850), a 12-core processor contains twelve cores. A multi-core processor implementsmultiprocessing in a single physical package. Designers may couple cores in a multi-core device tightly or loosely. For example, cores may or may not share caches, and they may implement message passing or shared memory inter-core communication methods. Common network topologies to interconnect cores include bus, ring, two-dimensional mesh, and crossbar. Homogeneous multi-core systems include only identical cores,heterogeneous multi-core systems have cores that are not identical. Just as with single-processor systems, cores in multi-core systems may implement architectures such as superscalar, VLIW, vector processing, SIMD, or multithreading.
Multi-core processors are widely used across many application domains including general-purpose, embedded, network, digital signal processing(DSP), and graphics.
The improvement in performance gained by the use of a multi-core processor depends very much on the software algorithms used and their implementation. In particular, possible gains are limited by the fraction of the software that can be run in parallel simultaneously on multiple cores; this effect is described byAmdahl's law. In the best case, so-called embarrassingly parallel problems may realize speedup factors near the number of cores, or even more if the problem is split up enough to fit within each core's cache(s), avoiding use of much slower main system memory. Most applications, however, are not accelerated so much unless programmers invest a prohibitive amount of effort in re-factoring the whole problem.[3] The parallelization of software is a significant ongoing topic of research.
http://en.wikipedia.org/wiki/Multithreading_(computer_architecture)
Multithreading (computer architecture)
Contents
Multithreading computer central processing units have hardware support to efficiently execute multiple threads. These are distinguished from multiprocessing systems (such as multi-coresystems) in that the threads have to share the resources of a single core: the computing units, the CPU caches and the translation lookaside buffer (TLB). Where multiprocessing systems include multiple complete processing units, multithreading aims to increase utilization of a single core by using thread-level as well as instruction-level parallelism. As the two techniques are complementary, they are sometimes combined in systems with multiple multithreading CPUs and in CPUs with multiple multithreading cores.
Overview[edit]
The multithreading paradigm has become more popular as efforts to further exploit instruction level parallelism have stalled since the late-1990s. This allowed the concept of throughput computing to re-emerge to prominence from the more specialized field of transaction processing:
- Even though it is very difficult to further speed up a single thread or single program, most computer systems are actually multi-tasking among multiple threads or programs.
- Techniques that would allow speedup of the overall system throughput of all tasks would be a meaningful performance gain.
The two major techniques for throughput computing are multiprocessing and multithreading.
Advantages[edit]
Some advantages include:
- If a thread gets a lot of cache misses, the other thread(s) can continue, taking advantage of the unused computing resources, which thus can lead to faster overall execution, as these resources would have been idle if only a single thread was executed.
- If a thread cannot use all the computing resources of the CPU (because instructions depend on each other's result), running another thread can avoid leaving these idle.
- If several threads work on the same set of data, they can actually share their cache, leading to better cache usage or synchronization on its values.
Disadvantages[edit]
Some criticisms of multithreading include:
- Multiple threads can interfere with each other when sharing hardware resources such as caches or translation lookaside buffers (TLBs).
- Execution times of a single thread are not improved but can be degraded, even when only one thread is executing. This is due to slower frequencies and/or additional pipeline stages that are necessary to accommodate thread-switching hardware.
- Hardware support for multithreading is more visible to software, thus requiring more changes to both application programs and operating systems than multiprocessing.
The mileage thus varies; Intel claims up to 30 percent improvement with its HyperThreading technology,[1] while a synthetic program just performing a loop of non-optimized dependent floating-point operations actually gains a 100 percent speed improvement when run in parallel. On the other hand, hand-tuned assembly language programs using MMX or Altivec extensions and performing data pre-fetches (as a good video encoder might), do not suffer from cache misses or idle computing resources. Such programs therefore do not benefit from hardware multithreading and can indeed see degraded performance due to contention for shared resources.
Hardware techniques used to support multithreading often parallel the software techniques used for computer multitasking of computer programs.
- Thread scheduling is also a major problem in multithreading.
Types of multithreading[edit]
Block multi-threading[edit]
Concept[edit]
The simplest type of multi-threading occurs when one thread runs until it is blocked by an event that normally would create a long latency stall. Such a stall might be a cache-miss that has to access off-chip memory, which might take hundreds of CPU cycles for the data to return. Instead of waiting for the stall to resolve, a threaded processor would switch execution to another thread that was ready to run. Only when the data for the previous thread had arrived, would the previous thread be placed back on the list of ready-to-run threads.
For example:
- Cycle i : instruction j from thread A is issued
- Cycle i+1: instruction j+1 from thread A is issued
- Cycle i+2: instruction j+2 from thread A is issued, load instruction which misses in all caches
- Cycle i+3: thread scheduler invoked, switches to thread B
- Cycle i+4: instruction k from thread B is issued
- Cycle i+5: instruction k+1 from thread B is issued
Conceptually, it is similar to cooperative multi-tasking used in real-time operating systems in which tasks voluntarily give up execution time when they need to wait upon some type of the event.
Terminology[edit]
This type of multi threading is known as Block or Cooperative or Coarse-grained multithreading.
Hardware cost[edit]
The goal of multi-threading hardware support is to allow quick switching between a blocked thread and another thread ready to run. To achieve this goal, the hardware cost is to replicate the program visible registers as well as some processor control registers (such as the program counter). Switching from one thread to another thread means the hardware switches from using one register set to another.
Such additional hardware has these benefits:
- The thread switch can be done in one CPU cycle.
- It appears to each thread that it is executing alone and not sharing any hardware resources with any other threads[dubious – discuss]. This minimizes the amount of software changes needed within the application as well as the operating system to support multithreading.
In order to switch efficiently between active threads, each active thread needs to have its own register set. For example, to quickly switch between two threads, the register hardware needs to be instantiated twice.
Examples[edit]
- Many families of microcontrollers and embedded processors have multiple register banks to allow quick context switching for interrupts. Such schemes can be considered a type of block multithreading among the user program thread and the interrupt threads.[citation needed]
Interleaved multi-threading[edit]
- Cycle i+1: an instruction from thread B is issued
- Cycle i+2: an instruction from thread C is issued
The purpose of interleaved multithreading is to remove all data dependency stalls from the execution pipeline. Since one thread is relatively independent from other threads, there's less chance of one instruction in one pipe stage needing an output from an older instruction in the pipeline.
Conceptually, it is similar to pre-emptive multi-tasking used in operating systems. One can make the analogy that the time-slice given to each active thread is one CPU cycle.
Terminology[edit]
This type of multithreading was first called Barrel processing, in which the staves of a barrel represent the pipeline stages and their executing threads. Interleaved or Pre-emptive or Fine-grained or time-sliced multithreading are more modern terminology.
Hardware costs[edit]
In addition to the hardware costs discussed in the Block type of multithreading, interleaved multithreading has an additional cost of each pipeline stage tracking the thread ID of the instruction it is processing. Also, since there are more threads being executed concurrently in the pipeline, shared resources such as caches and TLBs need to be larger to avoid thrashing between the different threads.
Simultaneous multi-threading[edit]
Concept[edit]
The most advanced type of multi-threading applies to superscalar processors. A normal superscalar processor issues multiple instructions from a single thread every CPU cycle. In Simultaneous Multi-threading (SMT), the superscalar processor can issue instructions from multiple threads every CPU cycle. Recognizing that any single thread has a limited amount ofinstruction level parallelism, this type of multithreading tries to exploit parallelism available across multiple threads to decrease the waste associated with unused issue slots.
For example:
- Cycle i : instructions j and j+1 from thread A; instruction k from thread B all simultaneously issued
- Cycle i+1: instruction j+2 from thread A; instruction k+1 from thread B; instruction m from thread C all simultaneously issued
- Cycle i+2: instruction j+3 from thread A; instructions m+1 and m+2 from thread C all simultaneously issued
Terminology[edit]
To distinguish the other types of multithreading from SMT, the term Temporal multithreading is used to denote when instructions from only one thread can be issued at a time.
Hardware costs[edit]
In addition to the hardware costs discussed for interleaved multithreading, SMT has the additional cost of each pipeline stage tracking the Thread ID of each instruction being processed. Again, shared resources such as caches and TLBs have to be sized for the large number of active threads being processed.
Examples[edit]
- DEC (later Compaq) EV8 (not completed)
- Intel Hyper-Threading
- IBM POWER5
- Sun Microsystems UltraSPARC T2
- MIPS MT
- CRAY XMT
Implementation specifics[edit]
A major area of research is the thread scheduler which must quickly choose among the list of ready-to-run threads to execute next as well as maintain the ready-to-run and stalled thread lists. An important sub-topic is the different thread priority schemes that can be used by the scheduler. The thread scheduler might be implemented totally in software, totally in hardware, or as a hardware/software combination.
Another area of research is what type of events should cause a thread switch - cache misses, inter-thread communication, DMA completion, etc.
If the multithreading scheme replicates all software visible state, include privileged control registers, TLBs, etc., then it enables virtual machines to be created for each thread. This allows each thread to run its own operating system on the same processor. On the other hand, if only user-mode state is saved, less hardware is required which would allow for more threads to be active at one time for the same die-area/cost.
See also[edit]
http://en.wikipedia.org/wiki/Super-threading
Super-threading
Super-threading (or time-slice multithreading) is a type of multithreading that enables different threads to be executed by a single processor without truly executing them at the same time.[1] This qualifies it as time-sliced or temporal multithreading rather than simultaneous multithreading (SMT). It is motivated by the observation that the processor's functional units are occasionally left idle while executing instructions from one thread due to long-latency events. Super-threading seeks to make use of the otherwise unused processor cycles by executing instructions from another thread until the previous thread is ready to resume execution.
While this approach enables better use of the processor's resources, further improvements to resource utilization can be realized through SMT, which allows the execution of instructions from multiple threads at the same time. Consider a two-way super-threaded processor with four functional units. If thread one issues three instructions, one functional unit remains unused. In an SMT processor, it is possible for thread two to issue an instruction to the remaining unit, attaining full utilization of processor resources.
http://en.wikipedia.org/wiki/Temporal_multithreading
Temporal multithreading
Variations[edit]Temporal multithreading is one of the two main forms of multithreading that can be implemented on computer processor hardware, the other being simultaneous multithreading. The distinguishing difference between the two forms is the maximum number of concurrent threads that can execute in any given pipeline stage in a given cycle. In temporal multithreading the number is one, while in simultaneous multithreading the number is greater than one.
There are many possible variations of temporal multithreading, but most can be classified into two sub-forms: coarse-grained and fine-grained.
- In coarse-grained temporal multithreading, the main processor pipeline contains only one thread at a time. The processor must effectively perform a rapid context switch before executing a different thread. This fast context switch is sometimes referred to as a thread switch. There may or may not be additional penalty cycles when switching.
- There are many possible variations of coarse-grained temporal multithreading, mainly concerning the algorithm that determines when thread switching occurs. This algorithm may be based on one or more of many different factors, including cycle counts, cache misses, and fairness.
- In fine-grained temporal multithreading, the main processor pipeline may contain multiple threads, with context switches effectively occurring between pipe stages (e.g. in the barrel processor). This form of multithreading can be more expensive than the coarse-grained forms because execution resources that span multiple pipe stages may have to deal with multiple threads. Also contributing to cost is the fact that this design cannot be optimized around the concept of a "background" thread — any of the concurrent threads implemented by the hardware might require its state to be read or written on any cycle.
Comparison to simultaneous multithreading[edit]
In any of its forms, temporal multithreading is similar in many ways to simultaneous multithreading. As in the simultaneous process, the hardware must store a complete set of states per concurrent thread implemented. The hardware must also preserve the illusion that a given thread has the processor resources to itself. Fairness algorithms must be included in both types of multithreading situations to prevent one thread from dominating processor time and/or resources.
Temporal multithreading has an advantage over simultaneous multithreading in that it causes lower processor heat output; however, it allows only one thread to be executed at a time.
http://en.wikipedia.org/wiki/Simultaneous_multithreading
Simultaneous multithreading
Simultaneous multithreading (SMT) is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading. SMT permits multiple independent threads of execution to better utilize the resources provided by modern processor architectures.
Contents
[hide]
Details[edit]
Multithreading is similar in concept to preemptive multitasking but is implemented at the thread level of execution in modern superscalar processors.
Simultaneous multithreading (SMT) is one of the two main implementations of multithreading, the other form being temporal multithreading. In temporal multithreading, only one thread of instructions can execute in any given pipeline stage at a time. In simultaneous multithreading, instructions from more than one thread can be executing in any given pipeline stage at a time. This is done without great changes to the basic processor architecture: the main additions needed are the ability to fetch instructions from multiple threads in a cycle, and a larger register file to hold data from multiple threads. The number of concurrent threads can be decided by the chip designers, but practical restrictions on chip complexity have limited the number to two for most SMT implementations.
Because the technique is really an efficiency solution and there is inevitable increased conflict on shared resources, measuring or agreeing on the effectiveness of the solution can be difficult. However, measured energy efficiency of SMT with parallel native and managed workloads on historical 130 nm to 32 nm Intel SMT (Hyper-Threading) implementations found that in 45 nm and 32 nm implementations, SMT is extremely energy efficient, even with inorder Atom processors [ASPLOS'11]. In modern systems, SMT effectively exploits concurrency with very little additional dynamic power. That is, even when performance gains are minimal the power consumption savings can be considerable.
Some researchers have shown that the extra threads can be used to proactively seed a shared resource like a cache, to improve the performance of another single thread, and claim this shows that SMT is not just an efficiency solution. Others use SMT to provide redundant computation, for some level of error detection and recovery.
However, in most current cases, SMT is about hiding memory latency, increasing efficiency, and increasing throughput of computations per amount of hardware used.
Taxonomy[edit]
In processor design, there are two ways to increase on-chip parallelism with less resource requirements: one is superscalar technique which tries to exploit instruction level parallelism (ILP); the other is multithreading approach exploiting thread level parallelism (TLP).
Superscalar means executing multiple instructions at the same time while chip-level multithreading (CMT) executes instructions from multiple threads within one processor chip at the same time. There are many ways to support more than one thread within a chip, namely:
- Interleaved multithreading: Interleaved issue of multiple instructions from different threads, also referred to as temporal multithreading. It can be further divided into fine-grain multithreading or coarse-grain multithreading depending on the frequency of interleaved issues. Fine-grain multithreading—such as in a barrel processor—issues instructions for different threads after every cycle, while coarse-grain multithreading only switches to issue instructions from another thread when the current executing thread causes some long latency events (like page fault etc.). Coarse-grain multithreading is more common for less context switch between threads. For example, Intel's Montecito processor uses coarse-grain multithreading, while Sun's UltraSPARC T1 uses fine-grain multithreading. For those processors that have only one pipeline per core, interleaved multithreading is the only possible way, because it can issue at most one instruction per cycle.
- Simultaneous multithreading (SMT): Issue multiple instructions from multiple threads in one cycle. The processor must be superscalar to do so.
- Chip-level multiprocessing (CMP or multicore): integrates two or more processors into one chip, each executing threads independently.
- Any combination of multithreaded/SMT/CMP.
The key factor to distinguish them is to look at how many instructions the processor can issue in one cycle and how many threads from which the instructions come. For example, Sun Microsystems' UltraSPARC T1 (known as "Niagara" until its November 14, 2005 release) is a multicore processor combined with fine-grain multithreading technique instead of simultaneous multithreading because each core can only issue one instruction at a time.
Historical implementations[edit]
While multithreading CPUs have been around since the 1950s, simultaneous multithreading was first researched by IBM in 1968 as part of the ACS-360 project.[1] The first major commercial microprocessor developed with SMT was the Alpha 21464 (EV8). This microprocessor was developed by DEC in coordination with Dean Tullsen of the University of California, San Diego, and Susan Eggers and Hank Levy of the University of Washington. The microprocessor was never released, since the Alpha line of microprocessors was discontinued shortly before HP acquired Compaq which had in turn acquired DEC. Dean Tullsen's work was also used to develop the Hyper-threading (Hyper-threading technology or HTT) versions of the Intel Pentium 4 microprocessors, such as the "Northwood" and "Prescott".
Modern commercial implementations[edit]
The Intel Pentium 4 was the first modern desktop processor to implement simultaneous multithreading, starting from the 3.06 GHz model released in 2002, and since introduced into a number of their processors. Intel calls the functionality Hyper-threading, and provides a basic two-thread SMT engine. Intel claims up to a 30% speed improvement compared against an otherwise identical, non-SMT Pentium 4. The performance improvement seen is very application-dependent; however, when running two programs that require full attention of the processor it can actually seem like one or both of the programs slows down slightly when Hyper-threading is turned on.[2] This is due to the replay system of the Pentium 4 tying up valuable execution resources, increasing contention for resources such as bandwidth, caches, TLBs, re-order buffer entries, equalizing the processor resources between the two programs which adds a varying amount of execution time. The Pentium 4 Prescott core gained a replay queue, which reduces execution time needed for the replay system. This is enough to completely overcome that performance hit.[3]
The latest[when?] MIPS architecture designs include an SMT system known as "MIPS MT".[4] MIPS MT provides for both heavyweight virtual processing elements and lighter-weight hardware microthreads. RMI, a Cupertino-based startup, is the first MIPS vendor to provide a processor SOC based on eight cores, each of which runs four threads. The threads can be run in fine-grain mode where a different thread can be executed each cycle. The threads can also be assigned priorities.
The IBM POWER5, announced in May 2004, comes as either a dual core dual-chip module (DCM), or quad-core or oct-core multi-chip module (MCM), with each core including a two-thread SMT engine. IBM's implementation is more sophisticated than the previous ones, because it can assign a different priority to the various threads, is more fine-grained, and the SMT engine can be turned on and off dynamically, to better execute those workloads where an SMT processor would not increase performance. This is IBM's second implementation of generally available hardware multithreading. In 2010, IBM released systems based on the POWER7 processor with eight cores with each having four Simultaneous Intelligent Threads. This switches the threading mode between one thread, two threads or four threads depending on the number of process threads being scheduled at the time. This optimizes the use of the core for minimum response time or maximum throughput.
IBM POWER8 has 8 intelligent simultaneous threads per core (SMT8).
Although many people reported that Sun Microsystems' UltraSPARC T1 (known as "Niagara" until its 14 November 2005 release) and the now defunct processor codenamed "Rock"(originally announced in 2005, but after many delays cancelled in 2009) are implementations of SPARC focused almost entirely on exploiting SMT and CMP techniques, Niagara is not actually using SMT. Sun refers to these combined approaches as "CMT", and the overall concept as "Throughput Computing". The Niagara has eight cores, but each core has only one pipeline, so actually it uses fine-grained multithreading. Unlike SMT, where instructions from multiple threads share the issue window each cycle, the processor uses a round robin policy to issue instructions from the next active thread each cycle. This makes it more similar to a barrel processor. Sun Microsystems' Rock processor is different, it has more complex cores that have more than one pipeline.
The Oracle Corporation Sparc T3 has eight fine-grained threads per core, Sparc T4, Sparc T5 and Sparc M5 have eight fine-grained threads per core of which two can be executed simultaneously.
Fujitsu Sparc64 VI has coarse-grained Vertical Multithreading(VMT)Sparc VII and newer have 2-way SMT.
Intel Itanium Montecito used coarse-grained multithreading and Tukwila and newer use 2-way SMT (with Dual-domain multithreading).
Intel Xeon Phi has 4-way SMT (with Time-multiplexed multithreading) with hardware based threads which cant be disabled unlike regular Hyperthreading.
The Intel Atom, released in 2008, is the first Intel product to feature 2-way SMT (marketed as Hyper-Threading) without supporting instruction reordering, speculative execution, or register renaming. Intel reintroduced Hyper-Threading with the Nehalem microarchitecture, after its absence on the Core microarchitecture.
AMD Bulldozer microarchitecture FlexFPU and Shared L2 cache are multithreaded but integer cores in module are single threaded, so it is only a partial SMT implementation.[5]
Disadvantages[edit]
Depending on the design & architecture of the processor, simultaneous multithreading can decrease performance if any of the shared resources are bottlenecks for performance.[6] Critics argue that it is a considerable burden to put on software developers that they have to test whether simultaneous multithreading is good or bad for their application in various situations and insert extra logic to turn it off if it decreases performance. Current operating systems lack convenient API calls for this purpose and for preventing processes with different priority from taking resources from each other.[7]
There is also a security concern with certain simultaneous multithreading implementations. Intel's hyperthreading implementation has a vulnerability through which it is possible for one application to steal a cryptographic key from another application running in the same processor by monitoring its cache use.[8]
http://en.wikipedia.org/wiki/Hyperthread
Hyper-threading


Intel's Hyper-Threading Technology scheme.
 |
This article's factual accuracy may be compromised due to out-of-date information. Please update this article to reflect recent events or newly available information. (June 2013) |
Hyper-threading (officially Hyper-Threading Technology or HT Technology, abbreviated HTT or HT) is Intel's proprietarysimultaneous multithreading (SMT) implementation used to improve parallelization of computations (doing multiple tasks at once) performed on PC microprocessors. It first appeared in February 2002 on Xeon server processors and in November 2002 on Pentium 4 desktop CPUs.[1] Later, Intel included this technology in Itanium, Atom, and Core 'i' Series CPUs, among others.
For each processor core that is physically present, the operating system addresses two virtual or logical cores, and shares the workload between them when possible. The main function of hyper-threading is to decrease the number of dependent instructions on the pipeline. It takes advantage of superscalar architecture (multiple instructions operating on separate data in parallel). They appear to the OS as two processors, thus the OS can schedule two processes at once. In addition two or more processes can use the same resources. If one process fails then the resources can be readily re-allocated.
Hyper-threading requires not only that the operating system supports SMT, but also that it be specifically optimized for HTT,[2] and Intel recommends disabling HTT when using operating systems that have not been optimized for this chip feature.
Contents
[hide]
Details[edit]

Intel Pentium 4 processor that incorporates Hyper-Threading Technology[3]
Hyper-threading works by duplicating certain sections of the processor— those that store the architectural state— but not duplicating the main execution resources. This allows a hyper-threading processor to appear as the usual "physical" processor and an extra "logical" processor to the host operating system (HTT-unaware operating systems see two "physical" processors), allowing the operating system to schedule two threads or processes simultaneously and appropriately. When execution resources would not be used by the current task in a processor without hyper-threading, and especially when the processor is stalled, a hyper-threading equipped processor can use those execution resources to execute another scheduled task. (The processor may stall due to a cache miss, branch misprediction, or data dependency.)
This technology is transparent to operating systems and programs. The minimum that is required to take advantage of hyper-threading issymmetric multiprocessing (SMP) support in the operating system, as the logical processors appear as standard separate processors.
It is possible to optimize operating system behavior on multi-processor hyper-threading capable systems. For example, consider an SMP system with two physical processors that are both hyper-threaded (for a total of four logical processors). If the operating system's thread scheduler is unaware of hyper-threading it will treat all four logical processors the same. If only two threads are eligible to run, it might choose to schedule those threads on the two logical processors that happen to belong to the same physical processor; that processor would become extremely busy while the other would idle, leading to poorer performance than is possible with better scheduling. This problem can be avoided by improving the scheduler to treat logical processors differently from physical processors; in a sense, this is a limited form of the scheduler changes that are required for NUMA systems.
History[edit]
Denelcor, Inc. introduced multi-threading with the HEP (Heterogeneous Element Processor) in 1982. The HEP pipeline could not hold multiple instructions that were independent because they belonged to different processes. Only one instruction from a given process was allowed to be present in the pipeline at any point in time. Should an instruction from a given process block in the pipe, instructions from the other processes would continue after the pipeline drained.
Intel implemented hyper-threading on an x86 architecture processor in 2002 with the Foster MP-based Xeon. It was also included on the 3.06 GHz Northwood-based Pentium 4 in the same year, and then remained as a feature in every Pentium 4 HT, Pentium 4 Extreme Edition and Pentium Extreme Edition processor since. Previous generations of Intel's processors based on the Core microarchitecture do not have Hyper-Threading, because the Core microarchitecture is a descendant of the P6 microarchitecture used in iterations of Pentium since the Pentium Pro through the Pentium III and the Celeron (Covington, Mendocino, Coppermine and Tualatin-based) and the Pentium II Xeon and Pentium III Xeon models.
Intel released the Nehalem (Core i7) in November 2008 in which hyper-threading made a return. The first generation Nehalem contained four cores and effectively scaled eight threads. Since then, both two- and six-core models have been released, scaling four and twelve threads respectively.[4]
The Intel Atom is an in-order processor with hyper-threading, for low power mobile PCs and low-price desktop PCs.[5]
The Itanium 9300 launched with eight threads per processor (two threads per core) through enhanced hyper-threading technology. Poulson, the next-generation Itanium, is scheduled to have additional hyper-threading enhancements.
The Intel Xeon 5500 server chips also utilize two-way hyper-threading.[6][7]
Performance claims[edit]
|
|
This section is outdated. Please update this article to reflect recent events or newly available information. (June 2013) |
The advantages of hyper-threading are listed as: improved support for multi-threaded code, allowing multiple threads to run simultaneously, improved reaction and response time.
According to Intel the first implementation only used 5% more die area than the comparable non-hyperthreaded processor, but the performance was 15–30% better.[8][9]
Intel claims up to a 30% performance improvement compared with an otherwise identical, non-simultaneous multithreading Pentium 4. Tom's Hardware states "In some cases a P4 running at 3.0 GHz with HT on can even beat a P4 running at 3.6 GHz with HT turned off."[10] Intel also claims significant performance improvements with a hyper-threading-enabled Pentium 4 processor in some artificial intelligence algorithms.
Overall the performance history of hyper-threading was a mixed one in the beginning. As one commentary on high performance computing from November 2002 notes:
Hyper-Threading can improve the performance of some MPI applications, but not all. Depending on the cluster configuration and, most importantly, the nature of the application running on the cluster, performance gains can vary or even be negative. The next step is to use performance tools to understand what areas contribute to performance gains and what areas contribute to performance degradation.[11]
As noted above performance improvement seen is very application-dependent; however, when running two programs that require full attention of the processor it can actually seem like one or both of the programs slows down slightly when Hyper-Threading Technology is turned on.[12] This is due to the replay system of the Pentium 4 tying up valuable execution resources, equalizing the processor resources between the two programs which adds a varying amount of execution time. The Pentium 4 and Xeon "Prescott core" gained a replay queue, which reduces execution time needed for the replay system. This is enough to completely overcome that performance hit.[13][14]
Drawbacks[edit]
When the first HT processors were released, many operating systems were not optimized for hyper-threading technology (e.g. Windows 2000 and Linux older than 2.4).[15]
In 2006, hyper-threading was criticised for energy-inefficiency. For example, specialist low-power CPU design company ARM stated simultaneous multithreading (SMT) can use up to 46% more power than ordinary dual-core designs. Furthermore, they claimed SMT increases cache thrashing by 42%, whereas dual core results in a 37% decrease.[16] Intel disputed this claim, stating hyper-threading is highly efficient because it uses resources that would otherwise be idle.
In 2010, ARM said it might include simultaneous multithreading in its chips in the future;[17] however this was rejected for their 2012 64 bit design.[18]
Security[edit]
In May 2005 Colin Percival demonstrated that on the Pentium 4, a malicious thread can use a timing attack to monitor the memory access patterns of another thread with which it shares a cache, allowing the theft of cryptographic information.[19] Potential solutions to this include the processor changing its cache eviction strategy, or the operating system preventing the simultaneous execution, on the same physical core, of threads with different privileges.[19]
通过/proc/cpuinfo判断CPU数量、Multicores、Multithreading、Hyper-threading的更多相关文章
- /proc/cpuinfo 查看cpu信息
/proc/cpuinfo 查看cpu信息 如类型.厂家.型号
- Linux CPU数量判断,通过/proc/cpuinfo.
Linux CPU数量判断,通过/proc/cpuinfo. 相同 physical id :决定一个物理处理器 如果“siblings”和“cpu cores”一致,则说明不支持超线程,或者超线程未 ...
- /proc/cpuinfo 文件分析(查看CPU信息)
/proc/cpuinfo文件分析 根据以下内容,我们则可以很方便的知道当前系统关于CPU.CPU的核数.CPU是否启用超线程等信息. <1>查询系统具有多少个逻辑核:cat /proc/ ...
- linux 下CPU数量、核心数量、是否支持超线程的判断
判断依据:1.具有相同core id的cpu是同一个core的超线程.2.具有相同physical id的cpu是同一颗cpu封装的线程或者cores. 英文版:1.Physical id and c ...
- 14、/proc/cpuinfo 文件(查看CPU信息)
转载http://www.cnblogs.com/itcomputer/p/4888438.html /proc/cpuinfo文件分析 根据以下内容,我们则可以很方便的知道当前系统关于CPU.CPU ...
- /proc/cpuinfo和/proc/meminfo来查看cpu信息与内存信息
#一般情况下使用root或者oracle用户查都可以. # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 --查 ...
- cat /proc/cpuinfo 引发的思考--CPU 物理封装-物理核心-逻辑核心-超线程之间关系
CPU的物理封装,一个物理封装使用独立的一个CPU物理插槽,共享电源和风扇: CPU物理核心:在一个物理封装中封装了多个独立CPU核心,每一个CPU核心都有自己独立的完整硬件单元. CPU逻辑核心:一 ...
- [转]linux /proc/cpuinfo 文件分析
在Linux系统中,提供了proc文件系统显示系统的软硬件信息.如果想了解系统中CPU的提供商和相关配置信息,则可以通过/proc/cpuinfo文件得到.本文章针对该文件进行简单的总结. 基于不同指 ...
- /proc/cpuinfo zz
/proc/cpuinfo文件分析 在Linux系统中,提供了proc文件系统显示系统的软硬件信息.如果想了解系统中CPU的提供商和相关配置信息,则可以通过/proc/cpuinfo文件得到.本文章针 ...
随机推荐
- bs4--官文--修改文档树
修改文档树 Beautiful Soup的强项是文档树的搜索,但同时也可以方便的修改文档树 修改tag的名称和属性 在 Attributes 的章节中已经介绍过这个功能,但是再看一遍也无妨. 重命名一 ...
- spring cache redis
一.使用开源包(spring-data-redis) 1.引入jar包 <dependency> <groupId>org.springframework.data& ...
- C# 反射总结
反射(Reflection)是.NET中的重要机制,通过放射,可以在运行时获得.NET中每一个类型(包括类.结构.委托.接口和枚举等)的成员,包括方法.属性.事件,以及构造函数等.还可以获得每个成员的 ...
- 【SaltStack】通过Master给Minion安装MySQL
一.IP信息说明 [Master] IP: 192.168.236.100 [Minion] IP: 192.168.236.101 二.配置SaltStack 关于SaltStack Master和 ...
- 关于加号传递到后端会变为空格的c#例子
参考博客:http://blog.csdn.net/nsdnresponsibility/article/details/50965262 以前在一次传递参数的情况中遇到,特此记录一下. 之前传递的参 ...
- 【21】外边距折叠(collapsing margins)
[21]外边距折叠(collapsing margins) 外边距合并指的是,当两个垂直外边距相遇时,它们将形成一个外边距. 合并后的外边距的高度等于两个发生合并的外边距的高度中的较大者. [注意]m ...
- hdu2255 奔小康赚大钱 KM 算法
参见这里 #include <iostream> #include <cstring> #include <cstdio> using namespace std; ...
- Laya list 居中
1.将list放在一个box中,去除box的宽高,设其锚点为0.5,0.5 2.将box的锚点放到目标位置 3.在list渲染后,设定box的宽度为list的宽度
- tomcat的安装和优化二
JAVA应用服务器weblogicwebsphere tomcat resin(百度,去哪网,搜狗,人人,互动百科)jboss resin官网:www.caucho.com jvm的调优: 1 JAM ...
- C++之字符串表达式求值
关于字符串表达式求值,应该是程序猿们机试或者面试时候常见问题之一,昨天参加国内某IT的机试,压轴便为此题,今天抽空对其进行了研究. 算术表达式中最常见的表示法形式有 中缀.前缀和 后缀表示法.中缀表示 ...