mark一下。hadoop分布式系统搭建
用于测试,我用4台虚拟机搭建成了hadoop结构
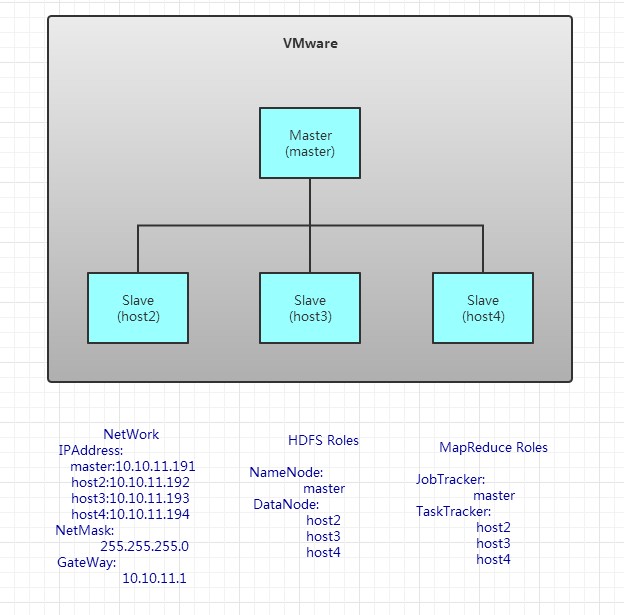
我用了两个台式机。一个xp系统,一个win7系统。每台电脑装两个虚拟机,要不然内存就满了。
1、安装虚拟机环境
Vmware,收费产品,占内存较大。
或
Oracle的VirtualBox,开源产品,占内存较小,但安装ubuntu过程中,重启会出错。
我选Vmware。
2、安装操作系统
Centos,红帽开源版,接近于生产环境。
Ubuntu,操作简单,方便,界面友好。
我选Ubuntu12.10.X 32位
3、安装一些常用的软件
在每台linux虚拟机上,安装:vim,ssh
sudo apt-get install vim
sudo apt-get install ssh
在客户端,也就是win7上,安装SecureCRT,Winscp或putty,这几个程序,都是依靠ssh服务来操作的,所以前提必须安装ssh服务。
service ssh status 查看ssh状态。如果关闭使用service ssh start开启服务。
SecureCRT,可以通过ssh远程访问linux虚拟机。
winSCP或putty,可以从win7向linux上传文件。
4、修改主机名和网络配置
主机名分别为:master,host2,host3,host4。
sudo vim /etc/hostname
网络配置,包括ip地址,子网掩码,DNS服务器。如上图所示。
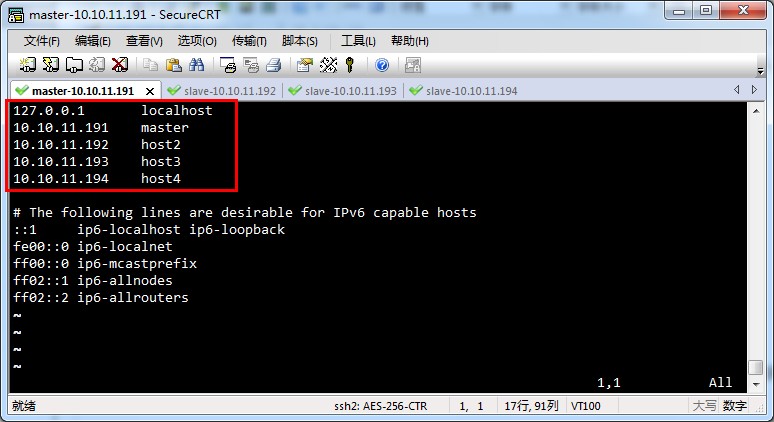
5、修改/etc/hosts文件。
修改每台电脑的hosts文件。
hosts文件和windows上的功能是一样的。存储主机名和ip地址的映射。
在每台linux上,sudo vim /etc/hosts 编写hosts文件。将主机名和ip地址的映射填写进去。编辑完后,结果如下:
6、配置ssh,实现无密码登陆
无密码登陆,效果也就是在master上,通过 ssh host2 或 ssh host3 或 ssh host4 就可以登陆到对方计算机上。而且不用输入密码。
四台虚拟机上,使用 ssh-keygen -t rsa 一路按回车就行了。
刚才都作甚了呢?主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。
打开~/.ssh 下面有三个文件
authorized_keys,已认证的keys
id_rsa,私钥
id_rsa.pub,公钥 三个文件。
下面就是关键的地方了,(我们要做ssh认证。进行下面操作前,可以先搜关于认证和加密区别以及各自的过程。)
①在master上将公钥放到authorized_keys里。命令:sudo cat id_rsa.pub >> authorized_keys
②将master上的authorized_keys放到其他linux的~/.ssh目录下。
命令:sudo scp authorized_keys hadoop@10.10.11.192:~/.ssh
sudo scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。
③修改authorized_keys权限,命令:chmod 644 authorized_keys
④测试是否成功
ssh host2 输入用户名密码,然后退出,再次ssh host2不用密码,直接进入系统。这就表示成功了。
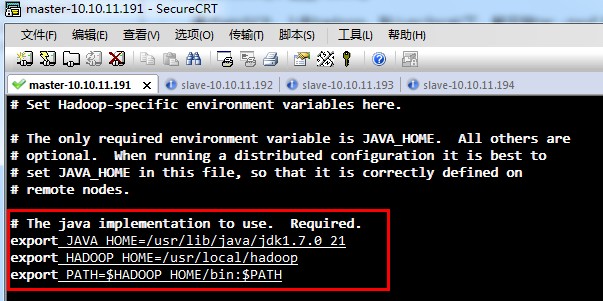
7、上传jdk,并配置环境变量。
通过winSCP将文件上传到linux中。将文件放到/usr/lib/java中,四个linux都要操作。
解压缩:tar -zxvf jdk1.7.0_21.tar
设置环境变量 sudo vim ~/.bashrc
在最下面添加:
export JAVA_HOME = /usr/lib/java/jdk1.7.0_21
export PATH = $JAVA_HOME/bin:$PATH
修改完后,用source ~/.bashrc让配置文件生效。
8、上传hadoop,配置hadoop
通过winSCP,上传hadoop,到/usr/local/下,解压缩tar -zxvf hadoop1.2.1.tar
再重命名一下,sudo rm hadoop1.2.1 hadoop
这样目录就变成/usr/local/hadoop
①修改环境变量,将hadoop加进去(最后四个linux都操作一次)
sudo vim ~/.bashrc
export HADOOP_HOME = /usr/local/hadoop
export PATH = $JAVA_HOme/bin:$HADOOP_HOME/bin:$PATH
修改完后,用source ~/.bashrc让配置文件生效。
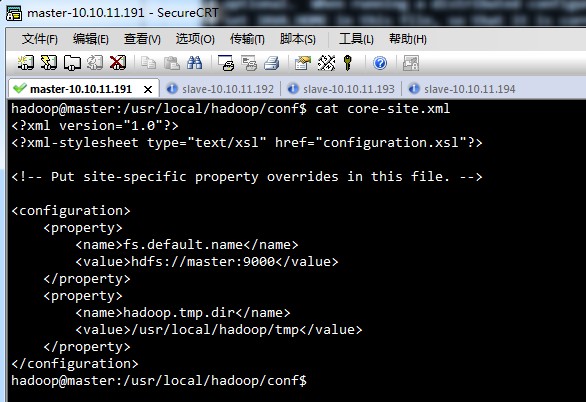
②修改/usr/local/hadoop/conf下配置文件
hadoop-env.sh,
core-site.xml,
hdfs-site.xml,
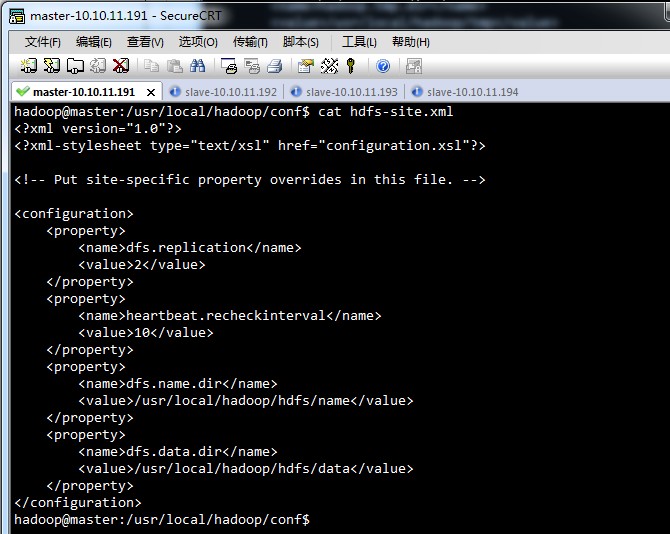
mapred-site.xml,

master,
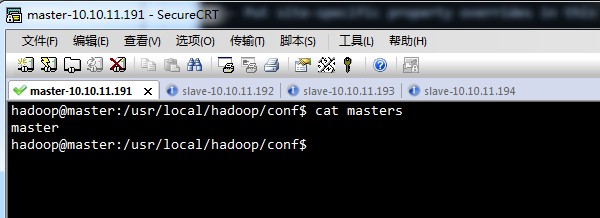
slave,

上面的hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml,master,slave几个文件,在四台linux中都是一样的。
配置完一台电脑后,可以将hadoop包,直接拷贝到其他电脑上。
③最后要记得,将hadoop的用户加进去,命令为
sudo chown -R hadoop@hadoop hadoop
sudo chown -R 用户名@用户组 目录名
④让hadoop配置生效
source hadoop-env.sh
⑤格式化namenode,只格式一次
hadoop namenode -format
⑥启动hadoop
切到/usr/local/hadoop/bin目录下,执行 start-all.sh启动所有程序
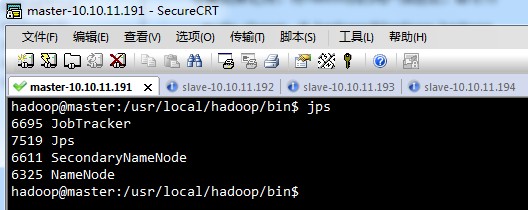
⑦查看进程,是否启动
jps
master,
host2,
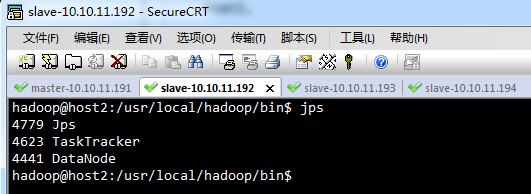
host3,host4,的显示结果,与host2相同。
点击此处-去我的博客园 http://www.cnblogs.com/laov/p/3421479.html
mark一下。hadoop分布式系统搭建的更多相关文章
- hadoop2.7.0分布式系统搭建(ubuntu14.04)
因为使用需要,在自己小本上建了四个虚拟机,打算搭建一个1+3的hadoop分布式系统. 环境:hadoop2.7.0+ubuntu14.04 (64位) 首先分别为搭建好的虚拟机的各主机重命名 方法: ...
- 本地+分布式Hadoop完整搭建过程
1 概述 Hadoop在大数据技术体系中极为重要,被誉为是改变世界的7个Java项目之一(剩下6个是Junit.Eclipse.Spring.Solr.HudsonAndJenkins.Android ...
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- 服务器Hadoop+Hive搭建
出于安全稳定考虑很多业务都需要服务器服务器Hadoop+Hive搭建,但经常有人问我,怎么去选择自己的配置最好,今天天气不错,我们一起来聊一下这个话题. Hadoop+Hive环境搭建 1虚拟机和系统 ...
- 通过hadoop + hive搭建离线式的分析系统之快速搭建一览
最近有个需求,需要整合所有店铺的数据做一个离线式分析系统,曾经都是按照店铺分库分表来给各自商家通过highchart多维度展示自家的店铺经营 数据,我们知道这是一个以店铺为维度的切分数据,非常适合目前 ...
- hadoop分布式搭建
1.新建三台机器,分别为: hadoop分布式搭建至少需要三台机器: master extension1 extension2 本文利用在VMware Workstation下安装Linux cent ...
- eclipse工具下hadoop环境搭建
eclipse工具下hadoop环境搭建: window10操作系统中搭建eclipse64开发系统,配置hadoop的eclipse插件,让eclipse可以查看Hdfs中的文件内容. ...
- Hadoop(分布式系统基础架构)---Hive与HBase区别
对于刚接触大数据的用户来说,要想区分Hive与HBase是有一定难度的.本文将尝试从其各自的定义.特点.限制.应用场景等角度来进行分析,以作抛砖引玉之用. Hive是什么? Apache Hive是 ...
随机推荐
- hihoCode r#1077 : RMQ问题再临-线段树
思路: 两种实现方法: (1)用链表(2)用数组. #include <bits/stdc++.h> using namespace std; int n, q, L, R, op, P, ...
- codevs 1146 ISBN号码
时间限制: 1 s 空间限制: 128000 KB 题目等级 : 白银 Silver 题目描述 Description 每一本正式出版的图书都有一个ISBN号码与之对应,ISBN码包括9位数字.1 ...
- 数据库_8_SQL基本操作——数据操作
SQL基本操作——数据操作 一.新增数据(两种方案) 方案1: 给全表字段插入数据,不需要指定字段列表,要求数据的值出现的顺序必须与表中设计的字段出现的顺序一致,凡是非数值数据,都需要使用引号(建议是 ...
- AppCrawler自动化遍历使用详解(版本2.1.0 )(转)
AppCrawle是自动遍历的app爬虫工具,最大的特点是灵活性,实现:对整个APP的所有可点击元素进行遍历点击. 优点: 1.支持android和iOS, 支持真机和模拟器 2.可通过配置来设定 ...
- WINDOWS-API:API函数大全
操作系统除了协调应用程序的执行.内存分配.系统资源管理外,同时也是一个很大的服务中心,调用这个服务中心的各种服务(每一种服务是一个函数),可以帮肋应用程序达到开启视窗.描绘图形.使用周边设备的目的,由 ...
- off-by-one&doublefree. 看雪10月ctf2017 TSRC 第四题赛后学习
off-by-one 0x00 发现漏洞 1.off-by-one 在massage函数中,如图所示,可以修改的字节数比原内存大小多了一个字节 2.悬挂指针 可以看到,在free堆块的时候,没有清空指 ...
- 浅谈倍增LCA
题目链接:https://www.luogu.org/problemnew/show/P3379 刚学了LCA,写篇blog加强理解. LCA(Least Common Ancestors),即最近公 ...
- shell脚本,如何监控mysql数据库。
[root@localhost wyb]# cat jkmysql #!/bin/bash status=`/etc/init.d/mysqld status|grep running|wc -l` ...
- javaEE(7)_自定义标签&JSTL标签(JSP Standard Tag Library)
一.自定义标签简介 1.自定义标签主要用于移除Jsp页面中的java代码,jsp禁止出现一行java脚本. 2.使用自定义标签移除jsp页面中的java代码,只需要完成以下两个步骤: •编写一个实现T ...
- 【数论】贝壳找房计数比赛&&祭facinv
震惊!阶乘逆元处理背后竟有如此玄机…… 题目描述 贝壳找房举办了一场计数比赛,比赛题目如下. 给一个字符串 s 和字符串 t,求出 s 的所有去重全排列中 t 出现的次数.比如aab的去重全排列为aa ...